利用分布式爬虫对中华民间故事的资源整合
2020-06-10赵鹏程严轶轩范巡礼
赵鹏程 严轶轩 范巡礼
(西北大学信息科学与技术学院 陕西省西安市 710127)
1 项目背景与项目步骤
如今网上资源鱼龙混杂,资源分布太广,并且重复率十分高。一般普通用户所采用的的搜索引擎大多为百度,必应等,如果利用传统的搜索引擎进行民间故事的索引,会发现搜索结果繁多且杂,且网页大多含有广告等无关信息。普通人想要进行这方面的搜索会十分困难,而当我们的青少年儿童想要进行搜索时则更加容易受到众多广告以及不明网页的误导。
项目步骤首先从初始网页集合开始,分析网页布局并提取故事内容,然后设计分布式结构,将爬取内容进行分类,最后进行可视化展示。
2 分析网页布局提取故事内容
网页被HTML使用标记标签来进行描述,WEB浏览器读取相应HTML文档并且最终用网页的形式来展示给用户。以chrome浏览器为例,打开某故事网站,右键审查元素,发现其部分网页布局如图1所示。
发现大部分正文包含在标签内,我们可以借此定位全网页的标签,然后直接爬取其标签内容,也有部分网页布局更加复杂,这时候需要借助HTML中的其他属性来进行定位(class,name等)。本项目采用python,借助scrapy这种通用的爬虫框架,此处使用xpath在页面中查找元素为例,提取div块当中class名称为ic的标签内容存储到lists列表变量当中:lists = response.xpath(".//div[@class = 'ic']//@href").extract()
爬取获得的数据还需要进行去除冗余的处理,按照上面的方法,实际上已经只提取了正文的主要部分,去除了大部分数据,然后对数据进行正则匹配等操作,主要去除空格和多余的空行。
3 分布式的设计
基于scrapy框架,首先由spider生成相应网络的请求,通过调度器scheduler将请求发送给下载器downloader,下载器获取相应的网络数据之后返回消息response给spiders,最终由spiders将数据放在item容器里。其中scrapy engine负责整个框架所有组件数据流的流通,并且控制相应的动作[1],架构图如图2所示。

图1
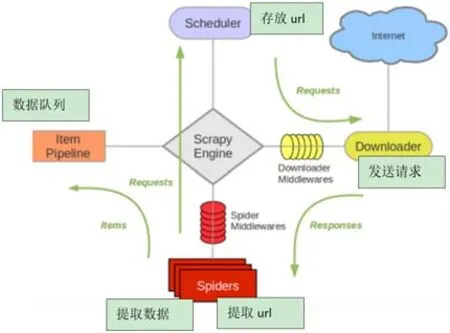
图2
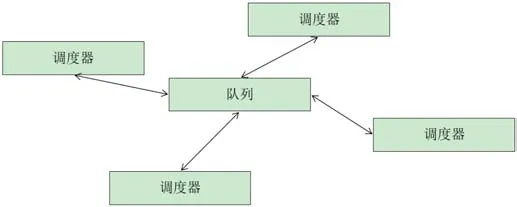
图3
在此基础上,我们将redis数据库与scrapy相结合进而进一步实现分布式的思想,scrapy-redis的思路便是在原本的基础上建立一个队列,spiders生成请求之后直接将网络请求发送给redis队列,最后经过调度器scheduler将队列中的请求提取出来。从而我们可以建立多个调度器,每个调度器都可以从redis当中提取相应的请求(同时也可以存入请求),进一步实现了利用多服务器分布爬取的目的[2],分布式爬虫架构图如图3所示。
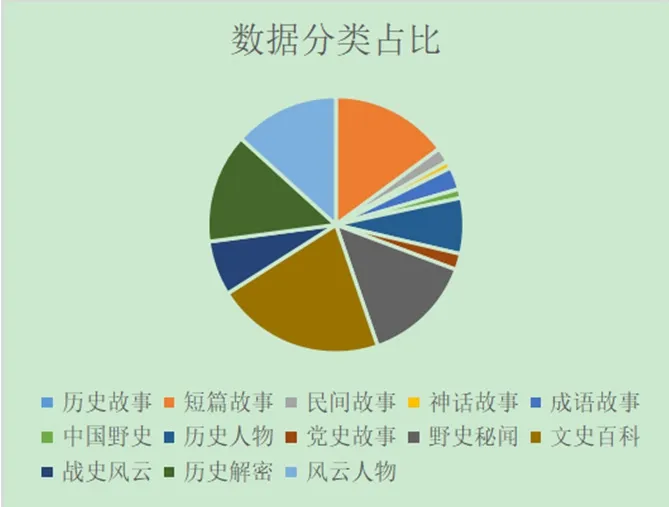
图4
4 数据分类
我们总计爬取了42847篇民间故事,并且根据目标网站的内容分成了十三类:“历史故事”、“短篇故事”、“民间故事”、“神话故事”、“成语故事”、“中国野史”、“党史故事”、“历史人物”、“野史秘闻”、“文史百科”、“战史风云”、“历史解密”和“风云人物”。统计出每个类别的数据如图4所示。
并且在每个分类中,统计出频率最高的词源绘制成为图谱词云(图5)。

图5
图6
5 可视化展示
租赁服务器搭建网站,建立一个简洁的搜索系统,由于数据量较多,并且未来可能会爬取更多的数据,在存储与搜索方面使用ElasticSearch框架检索相关数据并且返回统计结果。其设计理念即在lucene的基础上,通过倒排索引的方式进行快速查询。前段技术栈采用常见的HTML、JS等语言。设计效果如图6所示。
6 项目总结
本文叙述了分布式爬虫的基本原理和爬取策略,展示了项目的基本流程,对数据进行了分析和可视化处理,搭建了相应的检索工具以便用户使用。
虽然项目总体进展良好,但是也存在一些问题,例如许多网站有校验码限制了爬虫的效率,再者就是爬虫的效率依旧需要提高,对于校验码问题,可以使用机器学习进行图像识别进行自动校验,针对爬虫效率可以设计更加优化的算法以及增加从机的数量。
