基于Diou-Yolov3的车型检测
2020-06-10王乃洲金连文赵清利梁添才
王乃洲 金连文 赵清利 梁添才
(1.华南理工大学 广东省广州市 510640 2.广电智能安全研究院 广东省广州市 510656)
随着我国城镇化的加速发展,城市人口流动频繁,交通拥挤,安全监管难度大等问题日益严峻。为解决城市发展难题,智慧城市建设已成为当今世界城市发展不可逆转的历史潮流。近几年,在政策的引导下,城市安全主动防控体系的建设如火如荼,其核心在于人、车的管控:通过智能监控设备,实现人、车的实时检测、跟踪与识别,将非结构化的视频数据转化为人和机器可理解的结构化、半结构化数据,并进一步转化为警务实战所需的情报数据,从而视频数据向信息化、情报化的方向的转化,达到视频感知世界的智慧应用。
实际应用中,车型检测易受尺寸、光照、角度、遮挡等因素影响。评价车型检测效果的一个重要的性能指标是mAP(mean Average Precision)。如何提高检测模型mAP成为车型检测的一项重要研究内容。
传统的检测方法,主要采用边缘特征、 形状特征、统计特征或者变换特征等图像的各类静态特征来描述车辆等目标,其中,代表性的特征包括Haar小波特征[1]、HOG 特征[2]、Edgelet特征[3]等。随着深度学习技术的发展以及GPU等智能硬件性能的提升,基于卷积神经网络(CNN)特征提取方法在目标检测方面取得了重大突破,主流方法可大致分为two-stage和one-stage两类方法。Two-stage方法主要是指基于Region Proposal的算法,如R-CNN[4]、Fast-R-CNN[5]、Faster-R-CNN[6]等,该类算法首先在图片上生成若干个Region Proposal,然后,通过CNN在Region Proposal上进行候选框分类和回归。目前,该类方法精度最高,但检测速度慢,实际应用中无法达到实时效果;one-stage方法使用一个CNN直接预测不同目标的类别与位置,属于End-to-End方法,如工程中常用的SSD[7]、YOLO系列[8,10,11]等。
本文基于Diou loss[9]提出两种基于Yolov3[10]框架的车型检测方法。Diou考虑了预测框与ground-truth中心之间的距离,有效规避了IoU loss存在的收敛速度慢,特定情况下回归精度低等问题,在不增加模型大小以及推理速度的情况下,提升车型检测精度。最后,通过实验证明所提技术的有效性。
1 Yolov3目标检测原理
Yolov3在Yolov1和Yolov2[11]上作了较大的改进:
(1)采用Darknet-53的前52层作为基础网络,其中,Darknet-53较ResNet-152精度不变的情况下,速度上有明显的提升;
(2)提出分级预测策略,具体地,通过三级预测,改进了小目标的检测效果,如图1, 2 所示。三级预测依次针对大、中、小三类目标进行检测,以第一级为例,针对大目标检测,输出feature map大小为13×13,(以输入图片大小416×416为例,32倍下采样结果),每个cell分配三个anchor box,共九个。对于之后两级检测,利用Up Sampling并Concatenate基础网络中的相应的feature map实现对中、小目标检测,其中,anchor box可通过训练样本聚类获得(注:通过实验发现,以聚类获得anchor box训练效果可能欠佳,可通过对部分anchor依AP结果进行微调)。将为定值,若二者不相交时,IoU loss 恒为0,如图4(a)所示。此时,从IoU loss计算结果,无法看出优化方向,从而影响检测效果。 在2020年AAAI大会上,Zheng等人[9]提出了Diou loss (Distance IoU loss):
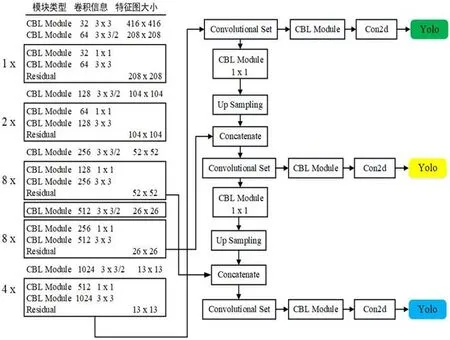
图1:Yolov3网络结构图

图2:Convolutional Set网络结构图
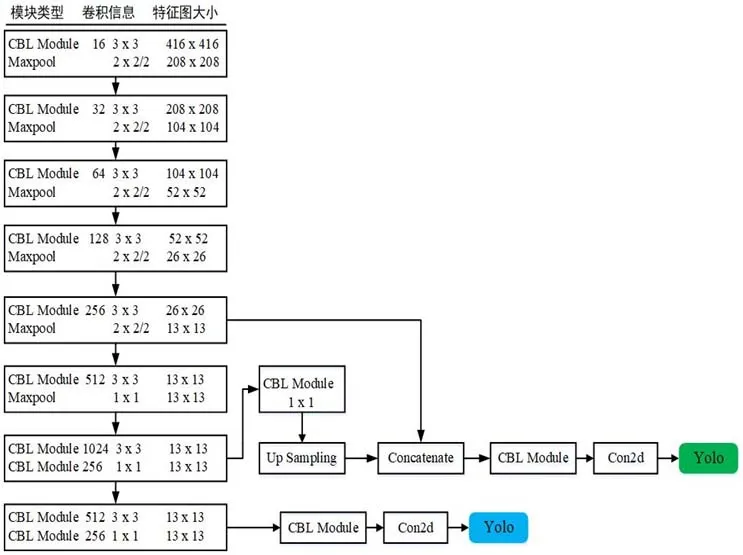
图3:Tiny Yolov3网络结构图

表1:检测数据集类别描述
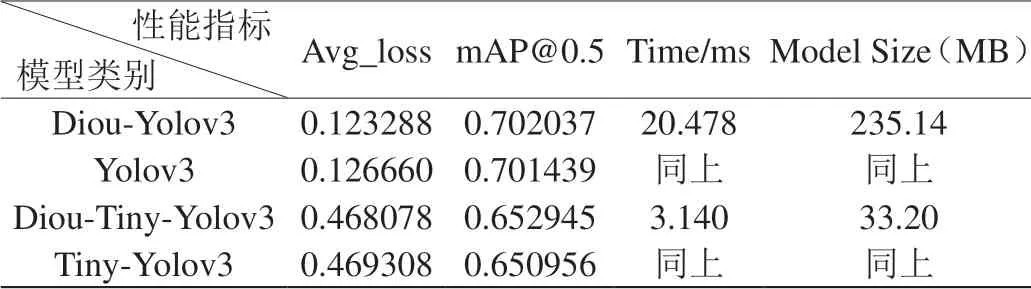
表2:四种模型性能测试结果对比

在获得预测框bbox, Yolov3利用NMS(非最大化抑制)来过滤掉多余的预测框。在此过程中,对于获得最大分数预测框M,我们采用Diou-NMS进行多余预测框过滤:

图4:IoU与Diou示意图

图5:车型检测数据集样例
Yolov3重点提升的是目标检测精度,尤其是小目标,而速度上略有下降。Tiny-Yolov3,是Yolov3的替代方案,如图3所示。Tiny-Yolov3速度较Yolov3有极大的提升,一方面,其对骨架网络进行了瘦身;另一方面,采用了两级预测策略。mAP精度指标较Yolov3有明显下降,在实际应用中,可通过场景需求选择模型种类。
2 基于Diou改进的Yolov3
Yolov3是一种End-to-End目标检测算法,其Loss函数由三部分组成:坐标误差项,IoU误差项和分类误差项。IoU即是预测框bbox与ground-truth之间的交并比,如下式所示:

则,IoU loss 可表示为:LIoU=1-IoU。由IoU及IoU loss 定义可以看出,当预测框bbox与ground-truth呈现包含关系时,IoU loss

其中,ε是阈值,训练与测试过程中均取为0.5,si分类得分。
3 实验结果与分析
3.1 实验数据集简介
实验数据来源于路边、岔口等摄像机实际采集的视频数据。将视频数据按帧抽取,并通过labelImg进行手工标注,共获得29847张标注好的图像,如图5所示,其中2985张图像作为测试集,其他26862图像作为训练集,测试集与训练集图像数量之比约为1:9。各类车型名称与标签名称如表1所示。
在实际系统中,检测模块主要用于目标定位于初分类,因此,这里将容易混淆的车型进行了合并,如:Car, MPV, SUV统一用Car表示。
3.2 实验结果与分析
本文中,模型训练与测试在Ubuntu16.0.4环境下进行,所使用的服务器安装有4块NVIDIA GTX 1080Ti显卡。采用Darknet[11]框架进行训练,网络的训练参数设置如下:采用Multistep学习策略,初始学习率为 0.001,max_batches设为12万次,steps=30000,60000,80000,10000, decay为0.0005,训练时batch size为32,测试时batch size为1,采用SGD学习策略,momentum为0.9。
实验比较了四种网络模型,分别为:Diou-Yolov3, Yolov3, Diou-Tiny-Yolov3和Tiny-Yolov3,实验结果如图6及表2所示。从实验结果可以看出,Diou-Yolov3以及Diou-Tiny-Yolov3分别较Yolov3以及Tiny-Yolov3在Map都略有提示,分别提升0.06和0.2个百分点,而在平均精度avg_loss上也略有减小,分别减小了0.34和0.13个百分点。重要的是,Diou的引入并不会增加模型大小以及推理速度,是一种有效的提升模型性能的改进方案。图7中对Diou-Yolov3和Diou-Tiny-Yolov3进行了验证,可以看出,实测效果达到了预期目标。
4 结束语
本文研究了基于Diou-Yolov3及Diou-Tiny-Yolov3的车型检测方法。该方法考虑了预测框与ground-truth中心之间的距离,有效规避了IoU loss存在的缺点,在不增加模型大小以及推理速度的情况下,提升了车型检测精度。

图6:检测模型训练曲线
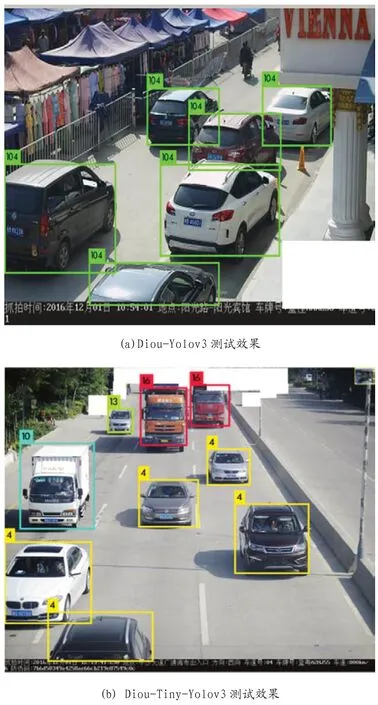
图7:模型测试效果展示
