基于通道注意力机制的视频人体行为识别
2020-06-10解怀奇乐红兵
解怀奇 乐红兵
(江南大学 江苏省无锡市 214122)
1 引言
随着网络带宽和硬件存储空间的大幅增加,互联网用户的通信方式从文字、语音和图像的形式不断升级,逐渐使用以短视频和直播为媒介的新的通信方式。现今从大量的移动设备和监控装置中产生了越来越多的视频信息,视频数据的爆炸式生成、发布和传播,已经成为当前大数据时代信息的重要组成部分,也促使学术界和工业界非常重视对视频的理解和分析,如何将设备产生的海量数据加以合理应用具有重要的研究价值。当前计算机视觉领域中,除了对图像分类、目标检测、目标跟踪等基本任务的研究以外,对于视频中的人体行为识别这个方向的研究越来越受到国内外的重视。视频中的人体行为识别任务[1]是理解视频中人体的动作和行为,通过深度学习中的卷积神经网络提取特征,对视频中连续帧的时空信息进行分析和处理,进一步识别并理解视频中的人体行为和动作。
本文在3D卷积神经网络行为识别模型的基础上,提出了一种融合通道注意力机制的3D残差网络结构,将2D的残差网络应用到3D的行为识别任务中,采用了改进的残差网络结构并融合了通道注意力机制。首先在kinetics数据集上进行模型预训练,然后在UCF-101和HMDB-51数据集上的对该网络结构的准确度进行验证分别取得了94%和71.4%的精度。
2 相关工作
2.1 注意力机制
行为识别的主要任务是识别人体的相关的动作区域,这里引入了一种通道注意力机制,能够增强网络对信息特征的敏感度[2],可以使输出的每个卷积模块更好地利用区域以外的上下文信息,尤其能够减轻较低网络层次上感受野尺寸较小而无法获得更多人体行为信息的情况。
通道注意力机制分为3个部分:压缩模块、激励模块和注意力模块[3]。压缩模块通过使用全局平均池化,并把每个通道内的所有特征值求和再压缩从而将全局的空间信息挤压成一个通道特征图,使该特征图统计的信息能够表现全局的特征信息,该模块的具体计算如公式(1)所示,其中H和W代表特征图的高和宽,c代表特征图的通道数量,uc残差模块的特征值。
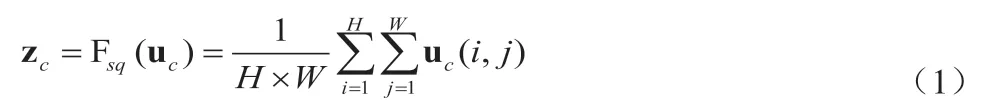
激励模块为了降低模型的复杂度并且增强模型的泛化能力,采用ReLU和Sigmoid激活函数共同组成,为了更加全面捕获通道之间的相关性,通过两个1×1卷积核卷积得到两个权重参数W1和W2,训练这两个参数得到一个通道域的激励权重,并且使用一个简易的门机制,具体如公式(2)所示,σ和δ分别代表ReLU和Sigmoid激活函数。
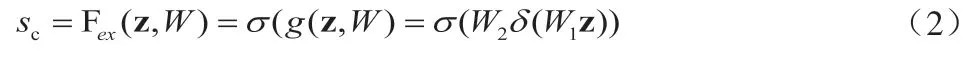
注意力模块在不同的通道域上得到的激励权重与原残差模块特征值进行融合,即通过增强对关键通道上的注意力增加通道域中人体运动的特征权重,进而从模型中获得更准确的关键信息,具体如公式(3)所示:

2.2 基于残差的3D卷积网络
近些年来,Resnet在图像分类中作出突出的贡献[4],该方法引入了一种新的直连通道机制,通过这种直连的方式解决了深层网络结构中梯度消失和梯度爆炸的问题,除了输出层计算的图像特征值外,还可以将之前网络计算的特征值进行融合输出,即添加了上一个网络输出的残差。Resnet网络避免了传统卷积神经网络信息传递的丢失和损耗的情况,进而保护了图像特征信息的完整性[5]。
改进的ResNeXt残差网络使用Resnet网络并借鉴Inception网络中的转换合并机制,改变了残差模块的拓扑结构,将3×3×3的卷积模块进行分组展开,这样在减少参数复杂度的情况下有效提高了识别的准确率,本文将最新的ResNeXt网络结构引入到行为识别任务中,并且使用融合通道注意力机制的3D卷积核对视频信息特征进行提取,分组转换计算如公式(4)所示,C为残差模块数目,G为分组组数,wi和xi分别为分组卷积核中的权重和特征值。

将3D残差模型进行优化,并且与通道注意力机制融合,构建SE-ResNeXt模块,即整个网络模型中的各个残差模块输出的特征值融合压缩激励的通道注意力机制,从而搭建了完整的基于通道注意力机制的3D残差网络,然后通过softmax模块将输入特征进行分类,并使用交叉熵函数计算模型损失,最后通过反向传播迭代更新网络参数。
3 本文方法
3.1 SE-ResNeXt整体网络结构
本文中提出的SE-ResNeXt整体网络结构如图1所示,包括5种卷积层,1个全连接层,以及一个对视频中的动作和行为进行分类的Softmax层。第一层卷积层是由7×7×7的3D卷积核组成,第2至第5层卷积层均是由ResNeXt3D卷积模块组成,每一个卷积层后都有一个归一化层和ReLU激活层,这4个层的通道数依次为64,128,256,512。与普通的3D卷积不同,该卷积模块采用ResNeXt3D模块,可以使用更深层次的网络对其深度特征信息进行提取,在每个ResNeXt3D残差模块的基础上融合基于通道注意力机制的SE模块,在利用3D卷积将时间和空间维度进行卷积的同时,增加通道注意力机制增强连续视频帧之间的依赖关系,池化层采用的具体方法为最大值池化,池化的卷积核大小为2×2×2,并且在第1,3,4,5层卷积核中均进行步长为2的时空下采样,最后的全连接层输出为512维向量。

图1:基于通道注意力机制的SE-ResNeXt网络结构
在研究通道注意力机制对视频行为识别准确度基础上,同时进行了网络结构的深度以及视频输入帧数对模型结果影响的实验。在SE-ResNeXt的基础上,探究不同的网络深度对行为识别的影响。实验不改变基础模型结构,通过改变不同SE-ResNeXt中模块的数量从而改变模型的深度,通过这种方式可以更加直观的探究出该模块的数量和网络深度对实验准确度的影响,能够取得更好的代表性并且进行更加精确的对比实验。
3.2 视频数据处理
为了提升数据的性能以及训练模型的泛化性,实验对视频中的内容进行空间处理[6],首先将视频切成连续帧,选取一个特定位置对视频帧进行统一采样,从而产生一组训练样本,如果输入视频的帧数少于16帧,对其进行初始帧循环插入以满足输入视频16帧的要求。数据增强方面,对视频帧进行10次裁剪,从其左上角开始,对其中一定规格的帧进行裁剪,并用同样的方法对其左下、右上、右下和中间部分进行裁剪,将得到的帧做水平镜像处理。同时为了使模型有更好的鲁棒性,实验还对视频帧进行了多尺度空间裁剪[7],裁剪的尺寸的比例分别为
3.3 网络训练
本文采用momentum动量随机梯度下降方法训练神经网络。在训练过程中,使用交叉熵损失函数进行反向传播权重的梯度,在训练参数设置中,权重衰减为0.001,动量参数为0.9,batch_size为32,学习率策略最初设定为1e-4,输入视频采用滑动窗口生成输入非重叠连续视频帧,保证每个视频都至少有一个特征信息进行训练,将输入片段送入神经网络评估所有视频帧片段的类别分数,最终将视频帧片段的平均准确率作为视频行为识别的准确度依据。
该实验对SE-ResNeXt18,34,50,101多个网络进行训练,训练过程中使用16个非重叠连续视频帧作为输入,并对SEResNeXt50和SE-ResNeXt101的视频帧输入数量增加至64帧,对比进行观察实验。
4 实验结果与分析
4.1 视频实验数据和结果分析
在对UCF-101和HMDB-51数据集进行行为识别的实验中,深度学习编程框架使pytorch0.4.0,平台系统为ubuntu16.04,CPU为i7 8700K,内存32G,并且使用1080Ti显卡进行并行计算。UCF-101数据集包括101个行为类别,总共含有13320个人体行为视频片段,平均每个视频片段时间为7s,在数据集划分方面,将70%的视频行为片段作为训练集,30%的视频行为片段作为测试集。HMDB-51数据集包括51个行为类别,总共含有6766个人体动作行为视频片段,每个视频片段平均时间为3秒。HMDB-51数据集将70%的视频行为片段作为训练集,剩余30%作为测试集。UCF-101和HMDB-51都同时去除了不包含动作行为的视频片段,从而更加准确地识别人体行为。
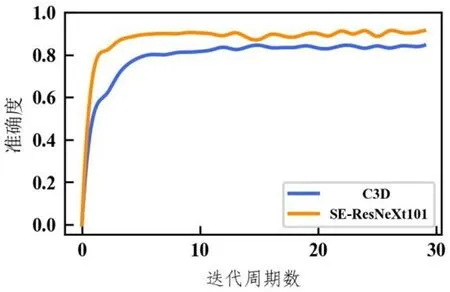
图2:该模型与C3D模型在UCF-101验证集上的准确度曲线
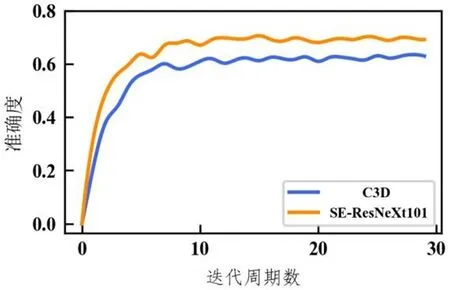
图3:该模型与C3D模型在HMDB-51验证集上的准确度曲线
本文使用kinetics预训练模型对UCF-101和HMDB-51数据集进行迁移学习,图2为SE-ResNeXt-101和C3D网络模型在UCF-101数据验证集上进行实验的平均准确度曲线,观察不同网络模型的对比图可以得出,本文提出的网络模型相比原始的C3D模型在数据训练中可以提前2至3个周期达到最高的准确度,并且相比原始模型收敛速度更快,而且从最终准确度也比原始模型高出5个百分点左右,所以使用SE-ResNeXt网络能有效地对UCF-101数据集中的人体行为进行识别,并且有了一定的提升。图3为SEResNeXt-101和C3D网络模型在HMDB-51数据验证集上进行实验的平均准确度曲线,和在UCF-101数据集上相比大致相同,本文提出模型相比原始C3D提前1至2个周期达到最高的精确度,同时相比原始C3D模型也有着更快的模型收敛速度和更高的精度,但是由于HMDB-51数据集视频内容的不同来源和复杂性的问题,训练过程中准确度波动较大,但多次训练过后依旧保持相对稳定的状态,通过两个数据集的对比验证,更进一步证明了模型的鲁棒性和有效性。

表1:在UCF-101和HMDB-51验证集的精确度
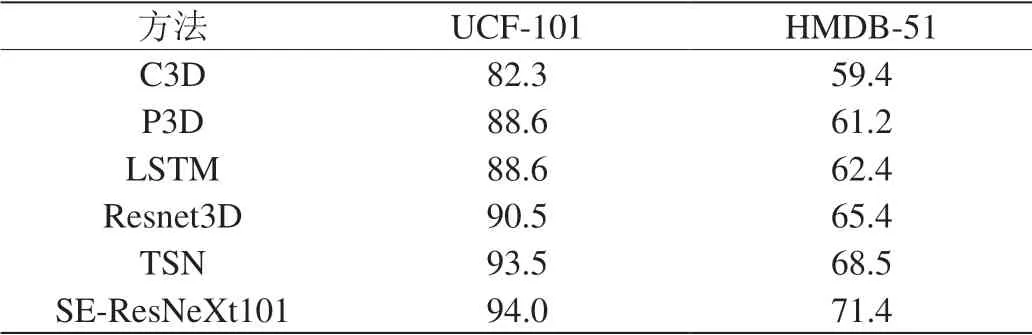
表2:在UCF-101和HMDB-51验证集的精确度
4.2 不同网络模型深度对实验的影响
本节对该模型不同深度的实验对比分析,由表1可知,在16帧视频输入的SE-ResNeXt模型中,SE-ResNeXt101在UCF-101和HMDB-51数据集上取得了最高的精度。从SE-ResNeXt18,34,50,101得出的实验数据对比中,可以观察出随着模型网络层数的加深,行为识别任务的精确度越来越高,同样是16帧的行为输入,发现SE-ResNeXt模型中数据的精度依次增加,实验结果表明增加网络层数,增强了网络模型的表征能力。
通过对数据集的观察与分析发现,在UCF-101和HMDB-51数据集中有一些数据集中出现行为过短的现象,比如射箭,射击等瞬时行为,16帧的数据有时候难以捕捉到这类行为,在16帧视频行为输入的基础上,增加了输入时间的片段,将16帧增加到64帧的输入,并对数据集中未达到64帧的行为视频片段与初始帧循环连接。实验表明,增加视频帧输入的数量能够对模型的准确度进行一定的提升。缺点是增加了数据预处理的时间,网络模型的运算量也更加复杂。
4.3 与相关模型对比
如表2将提出的SE-ResNeXt网络模型与其他行为识别模型进行对比,选取了SE-ResNeXt101与其他实验结果进行对比,观察得出在UCF-101和HMDB-51数据集上,SE-ResNeXt网络模型相比以前的单流网络模型如C3D[8]、P3D[9]、LSTM[10]和Resnet3D[11]达到的实验精度更高,并且和时空双流的TSN[12]相比,SE-ResNeXt在UCF-101和HMDB-51上得到了更好的精确度,但是节省了RGB视频帧转换为光流的时间成本,说明深度的SE-ResNeXt可以在该数据集上有更好的泛化性,用融合通道注意力机制的3D残差模块的网络结构取得了和更为复杂模型的相似实验精度,在证明SE-ResNeXt模块的有效性的同时,也证明了深度卷积网络模型在行为识别任务中取得了良好的性能。
5 总结
本文主要针对单流行为识别模型进行训练研究,在当前主流的行为识别数据集上,通过使用时空3D卷积核取得有效的提升。对各个通道进行加权融合,增加通道之间的依赖性,从而使构建的SE-ResNeXt网络模型有着更强的表征能力,并且本实验中通过不同数量的残差模块构建了不同层数的网络结构,实验表明随着网络层数的加深,模型参数的不断优化,能够有效地提升行为识别任务的准确度,对当前视频识别技术领域如智能安防监控、人机交互和视频标注等领域有着很高的工程应用和学术价值。
