可重构纹理贴图加速器设计
2020-06-10杨博文马龙
杨博文 马龙
(西安邮电大学电子工程学院 陕西省西安市 710121)
GPU(Graphics Processing Unit,图形处理单元)在桌面与各类嵌入式系统中应用极其广泛,从空间曲线到复杂分形、从三维几何到真实感图形、从单帧画面到物理模拟与实时游戏等,桌面与嵌入式系统对高性能图形渲染的需求日益紧迫[1]。纹理贴图作为GPU中的关键模块,是将纹理空间中的纹理像素映射到屏幕空间中像素的过程[2],在真实感图形处理中发挥着重要的作用。纹理贴图作为真实感图像绘制的重要部分,在时间关键的应用场合,如游戏、模拟应用中,当前帧和后续帧的渲染结果之间往往存在空间连贯性和图像连贯性等相关性,因此当前帧渲染时的瓶颈流水级往往也是后续帧渲染的瓶颈,在众多的纹理贴图算法中,面向不同的渲染场景时,也具有不同的效率[3]。目前,基于统一着色器架构的GPU在纹理贴图中只采用一种或一类算法,无法根据实际需求实现算法的自主切换,不能发挥最优性能。因此,面向不同渲染场景需要纹理单元支持纹理贴图算法灵活加载与自主调整以发挥纹理单元的最优性能显得尤为重要。可重构计算体系结构将传统处理器的高灵活性与专用集成电路的高处理效率相结合[4],在性能、功耗和功能灵活性等芯片的关键指标之间具有更好的平衡[5],这为GPU中纹理贴图不同算法之间的可切换提供了研究思路。
1 纹理贴图加速器设计
1.1 总体方案
根据对算法的分析和上节可重构结构的设计,本节对可重构纹理贴图加速器进行了总体方案设计,将不同算法指令存储在外部指令存储中通过访问外部存储的方式将程序下发到各个PE中运行,将初始化纹理贴图算法设置为双线性滤波算法,在可重构阵列处理元PE中实现。纹理贴图加速器总体设计方案如图1所示。将其分为四个模块,包括性能状态数据监测模块、主控制器模块、外部指令存储模块以及层次化配置网络HRM模块。图中每个PEG中包含4×4个PE。
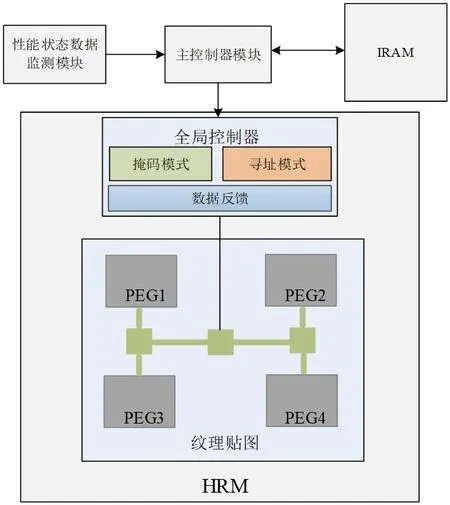
图1:纹理贴图加速器总体方案
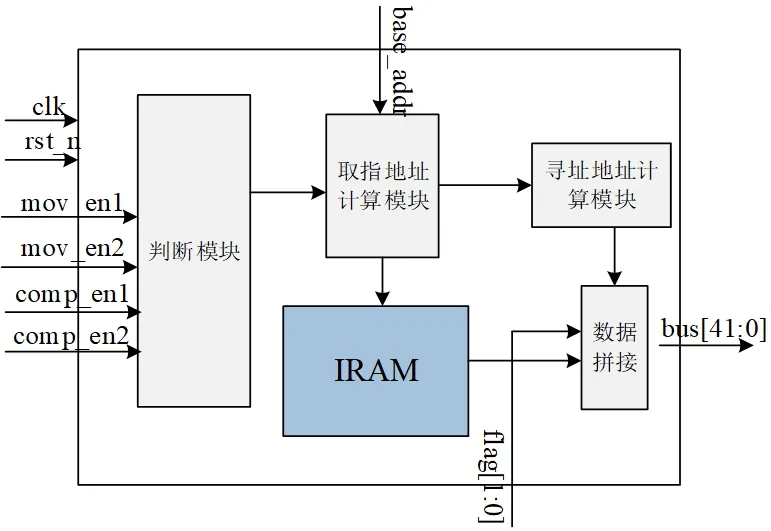
图2:主控制器模块电路框图
性能状态数据监测模块主要通过多个计数器对像素染色器内各级流水不同操作进行统计;IRAM是外部指令存储模块;主控制器模块通过对上一级发送过来的性能数据进行综合权衡,判断在该渲染场景下应该选择哪种纹理贴图算法。为了提升纹理贴图加速器并行度,提高GPU渲染速度,本文采用4个阵列处理器簇同时对像素进行处理,因此,在该模块中将下发指令方式设置为多播模式,同时配置掩码信息以及对目的PE地址的寻址信息。
1.2 主控制器设计
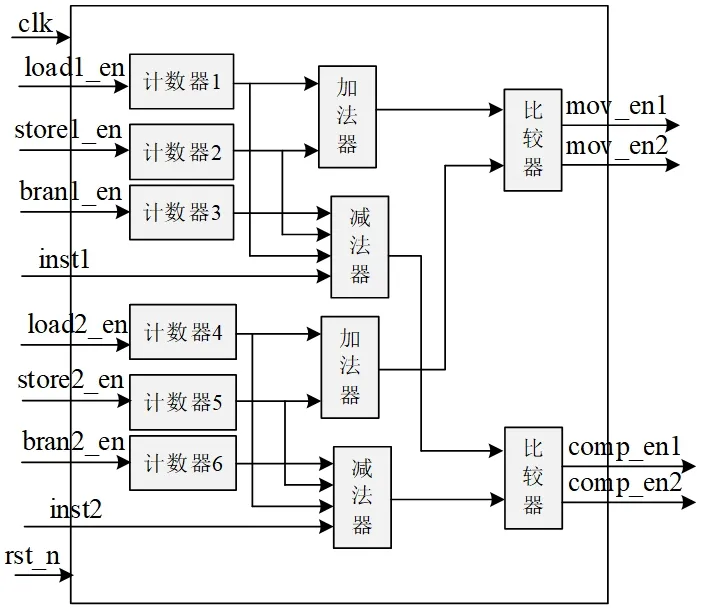
图3:性能状态数据监测模块电路图
主控制器模块通过对性能状态数据监测模块传送过来的性能状态信息进行综合权衡,判断并选择当前情况下应该选择哪种算法。如图2所示,可以根据以下方式进行判断:当像素处理器在数据移动量占用更大的比重时,在当前场景下,为了节约资源,降低成本,应该选择具有更少数据移动的算法,即双线性滤波算法,在这种情况下,根据取指基地址base_addr计算双线性滤波算法在外部指令存储IRAM的首地址,对该算法指令进行调用;当像素处理器在计算量占用更大的比重时,为了减少计算复杂度,提升像素渲染性能,应该选择具有更少计算量的纹理贴图算法,即最近邻点采样算法,通过基地址base_addr计算该算法在IRAM中的首地址;当像素处理器在数据移动量和计算量同时占更大比重时,由于数据移动的成本远远高于计算操作,因此,选择数据移动量更少的算法操作指令;同时,为了综合渲染质量因素,当像素处理器在数据移动和计算量都占更小比重时,选择MipMap结合线性滤波算法,通过基地址base_addr计算该算法在IRAM中的首地址。从IRAM中取出指令后,与目的PE寻址地址以及模式选择标志位进行拼接,得到数据总线bus,并将数据总线传入层次化配置网络HRM的全局控制模块,将操作指令下发到各个PE中。
1.3 性能状态数据监测模块设计
性能状态数据监测模块主要完成GPU绘制管线中像素染色器和纹理贴图加速器中的数据移动量和计算量性能状态的实时监测,该模块设计电路图如图3所示。通过6个计数器统计像素染色器和纹理贴图加速器的不同操作,计数器1、2、3分别对像素染色器加载指令、存储指令以及分支指令进行统计,inst1为像素染色器执行的总指令数;计数器4、5、6分别对纹理贴图加速器加载指令、存储指令以及分支指令进行统计,inst2为纹理贴图加速器执行的总指令数,当对当前像素渲染完成后,计数器停止工作。将统计的结果采用公式通过加法器和减法器分别计算得到像素处理器和纹理贴图加速器的数据移动量和计算量,并对其进行比较将结果输出送至主控制器模块。
2 测试验证
2.1 功能仿真
为了验证本文所设计的可重构纹理贴图加速器功能正确性,本节通过给出两组不同功能的测试激励,对所设计的电路进行功能仿真验证,仿真波形如图4所示。在第一组输入激励中,采用初始化双线性滤波算法进行纹理贴图,计算结果如图5中红色数字框1所在位置,在第二组输入激励中,采用最近邻点采样算法,结果为图中红色数字框2所在位置。因此可知,对于可重构纹理贴图加速器仿真结果符合算法理论计算结果,功能正确。
2.2 基于FPGA的测试方案
本文采用软硬件协同验证方法对可重构纹理贴图加速器进行FPGA验证,该验证平台由软件系统和硬件系统构成,如图5所示。软件系统的功能主要包含三个部分:
(1)基于OpenGL测试程序的编写;
(2)对OpenGL测试程序进行翻译;
(3)命令驱动程序的调用。
硬件系统包含PowerPC、PCI总线和可重构图形处理器原型系统三个部分。具体验证方法如下:
本文通过在一个立方体上进行纹理贴图来验证可重构纹理贴图加速器的正确性,具体测试方案为:使用OpenGL命令序列定义一个二维图像,设置纹理的参数和纹理函数,指定一个二维纹理,开启二维纹理,指定立方体六个面的顶点、纹理、法向量以及颜色坐标,将逆时针方向设为多边形的正面,剔除背面,采用填充绘图模式(默认的),开启深度测试,初始化深度为0.4,将深度范围设置为(0.1,0.8);深度测试比较函数的参数设为GL_GREATER,开启alpha测试,将比较函数设为GL_LESS,参考值设为1.0,设置视图变换,将目标观察点设为1.5,1.5,1.7,指向原点,以y轴的正方向为朝上方向。
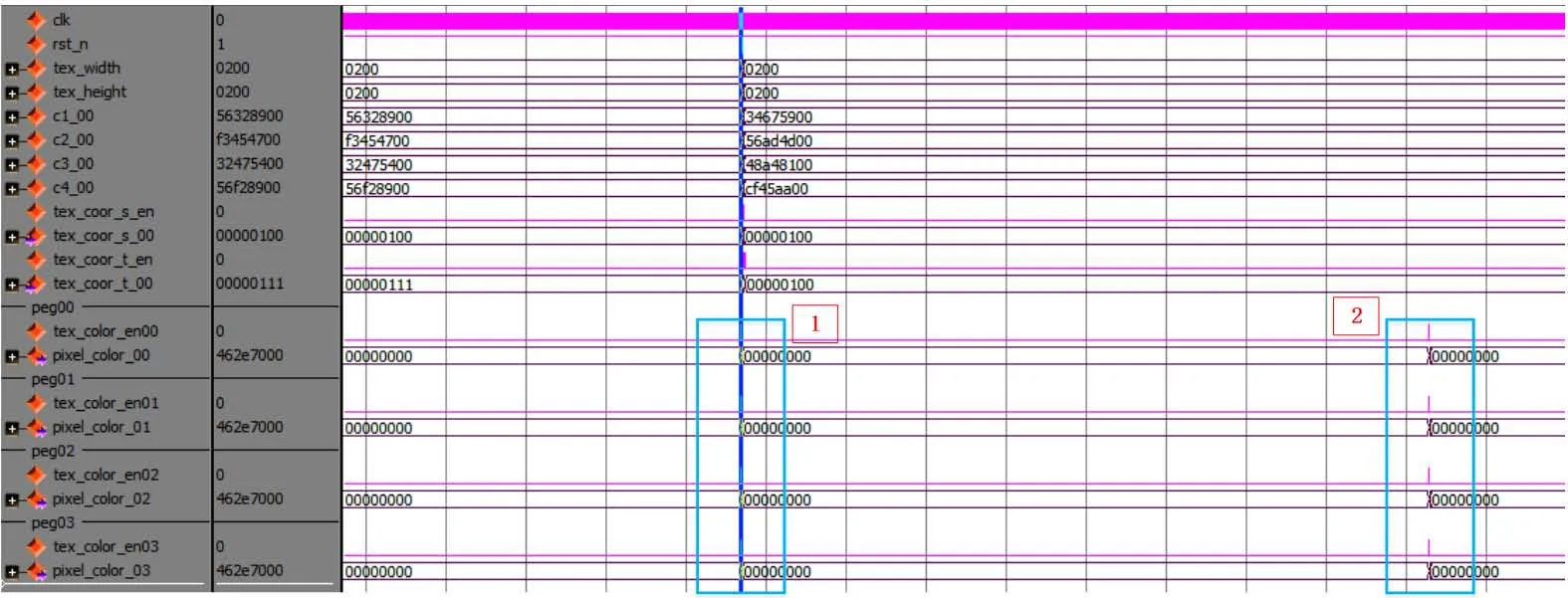
图4:纹理贴图算法可重构仿真验证
2.3 FPGA综合结果
本文将设计的可重构纹理贴图加速器在Xilinx公司的Virtex6系列芯片XC6VLX550T开发板上进行FPGA测试,其中芯片资源占用情况如表1所示,综合频率为112.45MHz。
根据上一节提出的可重构纹理贴图加速器原型系统验证方案,本文在XC6VLX550T开发板上进行FPGA原型验证,表明所设计的加速器能够正确完成渲染流水线中纹理贴图功能。
3 结论
本文在基于可重构处理器的纹理贴图算法映射实现的基础上,对纹理贴图不同算法动态可重构进行了需求分析和可行性分析。然后提出动态可重构纹理贴图加速器的整体设计方案,可通过性能状态数据监测、主控制器、外部指令存储以及层次化配置网络HRM等模块进行实现,并对其中关键模块进行了设计。同时,在该结构下,提出3种算法在阵列处理器中的动态可重构映射方案并给出具体实现过程。最后对提出的动态可重构纹理贴图加速器进行功能仿真并通过仿真验证。同时采用软硬件协同的验证方法给出纹理贴图加速器的硬件FPGA验证方案,并在Virtex6系列芯片XC6VLX550T开发板上进行FPGA测试与性能分析.在电路结构方面,本文与其他两个实现方式比较,采用可重构设计,在纹理贴图算法能够自主切换上具有更高的灵活性。
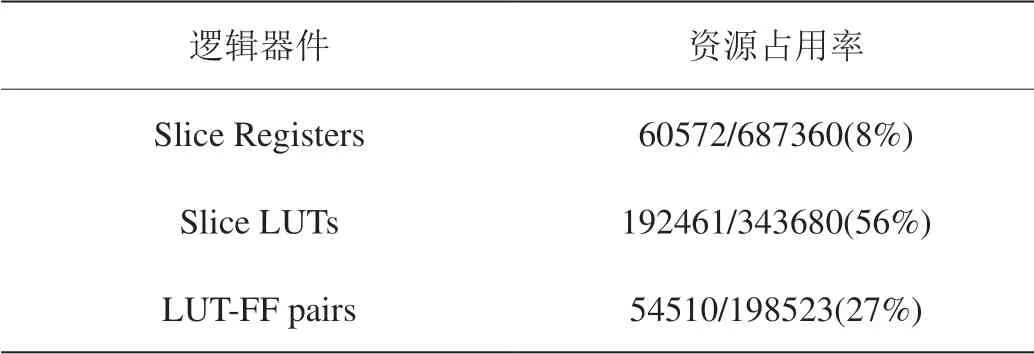
表1:纹理贴图加速器资源占用情况
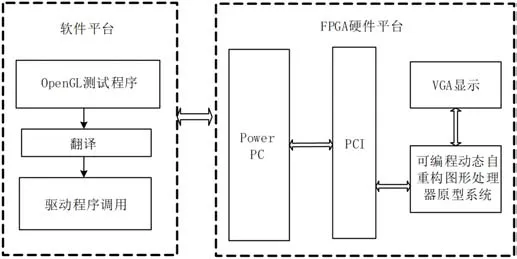
图5:原型系统验证平台
