一种支持稀疏卷积的深度神经网络加速器的设计
2020-06-10周国飞
周国飞
(上海齐感电子信息科技有限公司 上海市 200120)
1 概述
自从2012年AlexNet算法发布以来,深度神经网络技术(Deep Neural Networking)在图像识别、语音处理、自然语言处理(NLP)等非结构化数据处理领域和广告分类、搜索优化等结构化数据处理领域都得到了广泛应用。 深度神经网络算法对于硬件算力的需求也在近几年以每月翻番的速度递增,远远超过了芯片摩尔定律的增长速度[1]。本文针对深度神经网络的计算需求,定制设计一种新型的深度神经网络加速器(Deep Neural Networking Accelerator,简称DNNA),提高深度神经网络的计算效率,提高神经网络输入数据的复用率,可集成在SoC芯片上实现低功耗边缘推理。
深度神经网络的算法特征:
(1)包含多层卷积运算和矩阵数据的后处理计算;
(2)模型参数的数据量大,各层卷积有数十到数千个输入通道(Input Channel)和输出通道(即权重核数);
(3)卷积计算是多重循环的乘法和加法运算,输入数据按不同维度被重复参与计算;
(4)卷积计算具备稀疏性,即通过训练得到的模型权重可能包含很多的零值。
针对上述算法特征,本文DNNA的优化设计一是对不同尺寸参数的卷积计算做动态适配,优化计算的并行度;二是对稀疏卷积可以节省零值权重的计算时间,均衡非零权重的算力,提高计算单元的利用率。
2 DNNA的数据流设计
深度神经网络的核心计算负担主要在于网络中的多层卷积计算,每一层卷积是三维输入特征(Input Feature Map,简称IFM)与四维卷积权重计算得到三维输出特征向量(Output Feature Map,简称OFM)。
本文DNNA需要将参与计算的输入数据通过DMA从片外DRAM载入到全局缓存、再缓存到IFM和权重的寄存器缓存、然后由乘法和加法器(MAC)阵列取到数据和完成计算。为了提高深度神经网络的计算能效,首先对卷积计算的并行方式,数据流动层次给出定量分析,该设计过程也被称为DNNA的数据流设计。
卷积计算的各个变量定义如表1所示。
在神经网络加速器的一个时钟周期内,通过组合逻辑电路的乘法和加法器(MAC)可以得到的相乘和累加的结果,这是卷积计算的一个原子操作。如果没有并行计算,则一个原子操作只能完成一次乘法和一次加法运算。神经网络加速器的MAC阵列做并行计算,一个原子操作最多完成的乘法和累加次数等于NNA的MAC单元总数[3] [4]。本文DNNA根据卷积权重的尺寸特征,可以动态配置为二维并行卷积计算或者三维并行卷积计算。
二维并行卷积计算是在IFM输入通道和权重核数的两个维度上并行,两个并行维度相互独立,且并行计算没有切割IFM表面(Hi*Wi),因此二维并行卷积并不受卷积步长(Stride)或者卷积核的空洞(Dilation)的影响。但二维并行卷积的MAC利用率依赖于IFM输入通道。当稀疏卷积的情况,每个IFM输入通道的都可能有零值权重的存在,所以会影响MAC利用率。

表1:卷积参数说明
三维并行卷积计算是在IFM输入通道C、OFM表面(Ho*Wo)和权重核数Kn三个维度上并行,且只采用Dual-MAC设计,并行计算两个IFM输入通道[2]。所以一是适合于对输入通道较小的卷积计算场景,如DNN网络的图像输入层;二是适用于稀疏卷积的情况。
本文DNNA计算的MAC阵列为8行16列Dual-MAC,即共计256个MAC单元。每个MAC单元完成8bit乘法和相应的累加计算。一次卷积计算总的乘法计算个数需遍历卷积权重的四个维度和OFM的两个维度,一个单位周期内有256个MAC并行计算。
综上可得:二维并行卷积的乘法计算数如式(1)所示;三维并行卷积的计算时钟周期数如式(2)所示。下式中均设OFM表面(Ho*Wo)足够大。
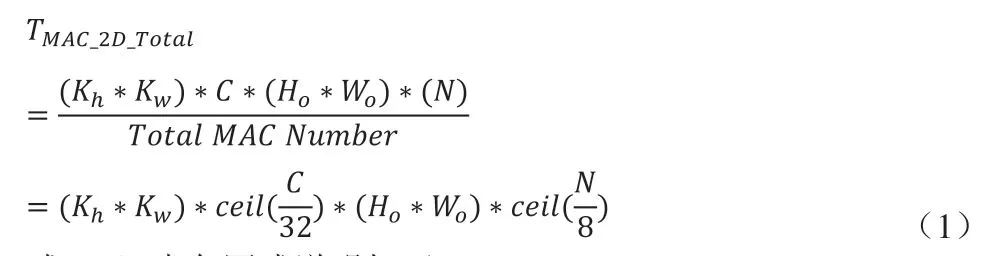
式(1)中各因式说明如下:
(1)(Kh*Kw)是遍历输入权重一个表面的循环。
(3)Ho*Wo是遍历OFM一个表面的循环。
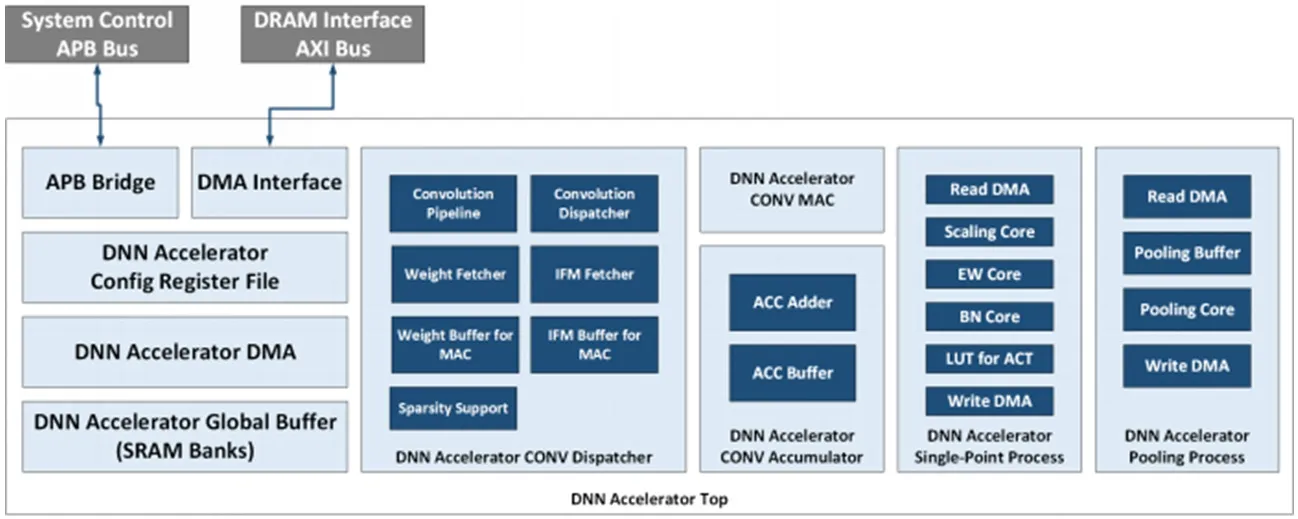
图1:DNNA的顶层模块框图
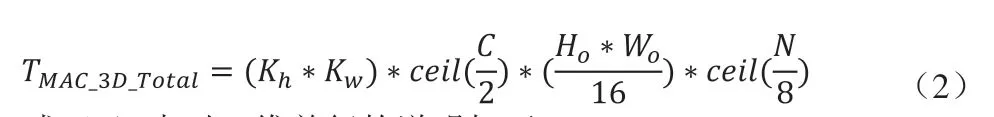
式(2)中对三维并行的说明如下:
3 DNNA的架构设计
前述两种并行数据流各有适用场景,本文DNNA通过寄存器配置,硬件模块中以最合适的并行方式完成计算。本文DNNA硬件模块的设计框图如图1所示,主要模块描述如下:
(1)APB接口及配置寄存器文件作为软硬件接口。
(2)专用DMA接口访问外部DRAM存储的卷积权重和IFM输入数据。
(3)片上SRAM构成全局缓存(Global Buffer),全局缓存可动态划分存储空间,存放IFM、权重、权重配置信息、寄存器配置信息等。
(4)CONV Dispatcher作为中控模块,实现卷积计算的数据流控制和流水线控制。
(5)IFM Buffer和Weight Buffer是从全局缓存到MAC阵列的寄存器缓存,分别存储IFM数据和权重数据。
(6)计算模块:MAC阵列、累加器和缓存、单点数据的后处理模块、池化处理模块。
本文DNNA的层次化存储设计为配置寄存器、DMA和全局缓存三部分,其中完成数据流动态配置和流水线控制的CONV Dispatcher设计如图2所示。对计算数据流的动态配置说明如下:
(1)对深度神经网络的各层卷积,由寄存器配置各自对应的并行数据流。
(2)将一层卷积层分解为多个独立算子,如卷积、池化、激活函数、矩阵点的算术运算等,将一个独立算子可再分解为DNNA操作和参数数据。该过程由DMA和寄存器配置协同完成。
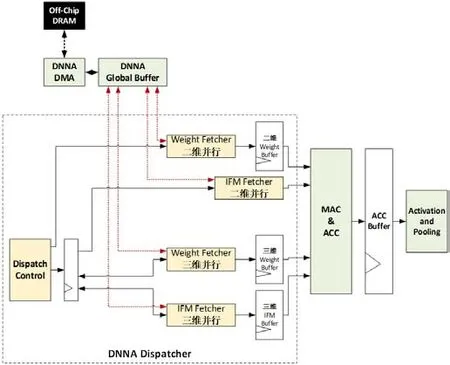
图2:CONV Dispatcher设计框图
(3)DMA可以自动从读取IFM、权重和寄存器配置参数三种数据并放入全局缓存,寄存器配置参数决定计算过程。
(4)二维并行和三维并行的数据流分别有独立的Fetcher模块和寄存器缓存,根据数据特征自动读入数据,并且分配到各个MAC输入端。
(5)全过程流水线控制,硬件自动完成。
4 优化对稀疏卷积的实现
4.1 均衡稀疏卷积的MAC算力
对于包含了大量零值权重的稀疏卷积,一是不计算零值,节省计算时间;二是零值权重在权重核可能呈不均匀分布上分布不均匀,需要对权重核数据做预处理,并均衡算力,提高MAC阵列的利用率。本文DNNA采用软硬件协同方式,实现如下:
(1)软件工具链对训练后并量化的卷积权重进行压缩,去掉零值。
(2)再将非零值权重按照如下顺序紧密排序:
(a)连续2个输入通道。
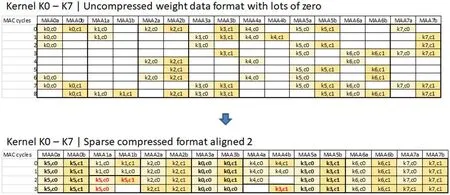
图3:稀疏卷积的权重压缩和排序
(b)连续8个权重核。
(c)权重行方向Kw。
(d)权重列方向Kh。
(3)然后均衡每2个输入通道和8个权重核上的非零值权重。
(4)经过上述压缩和排序的预处理后的权重,输入到本文DNNA硬件,Dispatcher模块控制对非零值权重的算力均衡。
(5)本文DNNA对权重核数Kn的并行数为8,因此对应于(Kh*Kw)*2*8的权重数据量的乘法计算,MAC阵列共享IFM输入数据。
(6)MAC之间的均衡了算力的MAC中间结果(Partial Sum)有Accumulator Buffer进行缓存。
以一个尺寸为(Kh*Kw)*2*8=3*3*2*8的权重数据块为例,压缩和排序的预处理效果如图3所示。图中空白格表示零值。
4.2 优化缓存的数据带宽和数据复用
要使16*2*8的MAC阵列要达到100%的利用率,所需IFM和权重的数据带宽需求(数据量/时钟周期)如表2所示。
如表2所示,二维并行计算所需权重带宽是IFM带宽的8倍。本文DNNA采用流水线控制,在每次乘法操作前预取256 Bytes的权重数据。预取的权重数据复用至少8个时钟周期。在当前权重复用期间,流水线控制从全局缓存预取下一组256 Bytes的权重数据。所优化的二维并行卷积数据流如式(3)所示,总的卷积计算周期数不变,且未额外增加读取片上缓存时间,也未额外增加片上缓存的带宽。

表2:MAC阵列的数据带宽
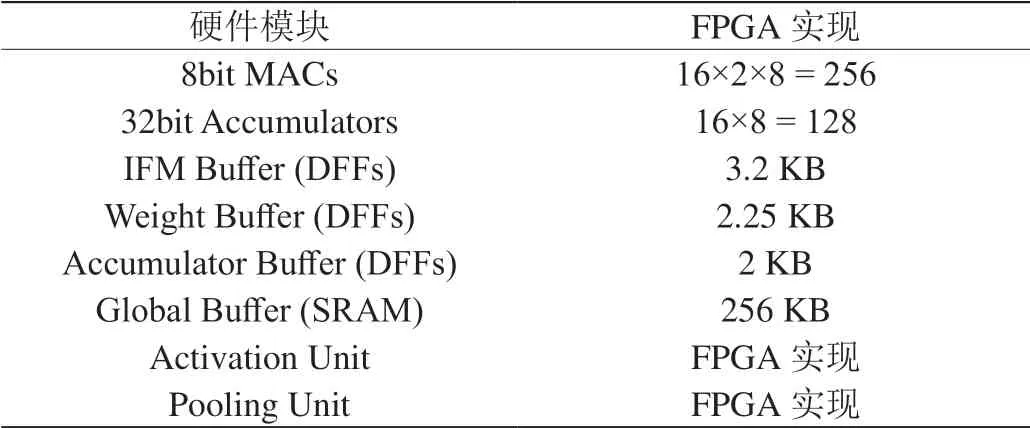
表3:FPGA硬件实现

表4:本文DNNA支持的神经网络算子
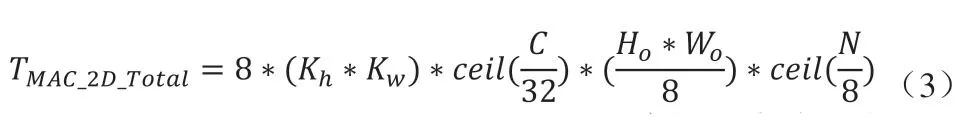
如表2所示,三维并行计算所需IFM数据带宽大于权重,且因Stride或Dilation,需要从片上缓存的不同地址读取IFM数据。本文DNNA每次计算需载入寄存器缓存的最小权重数据量为(Kh*Kw)*2*8。可以配置寄存器使本文DNNA预取两个权重数据块,同时预取对应的IFM数据,复用IFM数据完成16个权重核对应的OFM部分和,所优化的三维并行卷积数据流如式(4)所示。

5 FPGA实现
本文DNNA基于Verilog HDL语言完成RTL设计,且均可综合RTL代码。RTL设计完成后,验证设计的仿真方式为:随机生成不同卷积尺寸的weight.bin,ifm.bin和配置寄存器的配置文件,并且同时生成用于比对的正确OFM数据golden.bin,通过VCS工具仿真和收集该DNNA的计算结果,与golden.hex比对一致。
仿真确认的RTL,在Xilinx Zynq-7000 FPGA上实现。FPGA实现的硬件模块配置如表3所示。该FPGA实现需要27000 LUTs。
所实现的FPGA DNNA,可以完成如表4所示的神经网络计算。
用本文DNNA对3×3和5×5尺寸的稀疏权重核进行卷积计算,其中零值权重的分布完全随机。优化的稀疏卷积计算的提升效率如图4所示。图中稀疏率是零值权重占总权重数的百分比,节省的计算时间与未优化的计算时间的百分比,按每种尺寸、每种稀疏率随机迭代计算后,再求平均得到。根据图中稀疏优化节省的时间对比,可见对于(Kh*Kw)权重尺寸越大,稀疏优化效果越明显。且该优化设计的效果正相关于稀疏率,与输入通道和权重核数相对独立。
6 结论
本文针对深度神经网络的卷积计算特征进行量化分析和DNNA的数据流设计,根据数据流进行DNNA架构设计,并为了提高MAC阵列利用率和节省片上SRAM带宽所进行专门优化。进一步说明本文DNNA的硬件实现,RTL仿真和FPGA实现工作,通过对稀疏卷积节省的计算时间验证本文DNNA设计。下一步工作是将本文DNNA为作为神经网络专用处理器(DSA),集成到SoC异构架构中,配合各种外设接口和输入设备,实现深度神经网络的多种应用。
