基于机器学习的入侵检测技术研究与实现
2020-06-08张海燕李根源辜建锐林开荣
张海燕 李根源 辜建锐 林开荣

摘要:目前大多数入侵检测系统都是基于一个特定的预定义模式(特征值)来匹配已知的攻击功能。基于特征值的方法的主要局限性在于它不识别新的攻击,甚至不识别已知漏洞中的微小变化。该文基于机器学习技术,采用k-means聚类算法和支持向量机分类算法,能够自动构造正常分组有效载荷的分布并检测其偏差。实验表明,机器学习算法比大多数使用的开源snort系统有更高的检测精度。
关键词:入侵检测;机器学习;分类算法;k-means聚类
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)10-0215-03
1入侵检测系统
入侵检测系统(ids)用于检测网络攻击者。图1所示的入侵检测系统(ids)结构用于检测主要通过网络试图闯入计算机系统的攻擊者。即使防火墙可以检测到未经授权的用户访问网络,但当计算机用户或网络管理允许对系统(如web服务器)进行开放式访问时,它也无法防止入侵企图。攻击或黑客的企图可能导致探测和拒绝服务(DoS)攻击。
在入侵检测系统(ids)中,目标是检测网络上某个特定的行为是否是异常行为。异常检测需要标记特征。在整个网络入侵检测工作领域中,异常检测的不同阶段所使用的术语存在着一定的差异。对网络检测系统的各个阶段以及在各个阶段中使用的术语的定义进行了一些定义。
观察:单个数据单元。在网络系统的入侵中,数据单元可以是网络包、特定状态服务器或特定时间的计算机。
特征:特定类型的信息。观测通常有许多特点。在网络入侵检测系统中,特征可以包括目标IP地址、包长度和网络的时间戳。
数据集:观察的集合,每个观察都包含每个特征的值。通常,数据集用矩阵表示,其中行表示观测值,列表示要素。
预处理:异常检测工具对数据集进行的操作,假定预处理对实验结果没有影响。
监督方法:利用已标识的数据训练系统,使其能够识别新数据的方法。标记的训练示例可以是以前系统过程的系统输出,也可以是手动添加标记。
无监督方法:不需要使用已经识别的数据来训练系统,它可以识别新的数据。
聚类:基于相似性的群体观察。通常,无监督群集:在生成组后选择组标签。根据相似性将观察结果分组。
大多数人侵检测系统的研究论文都提出了不同的入侵检测算法,如自适应共振理论、神经网络、统计概率分布和盲分类等。大多数算法使用kdd99作为数据集来验证其入侵检测性能。kdd99数据集是一个已有20年历史的数据集,具有41个复杂的特征。本文研究的是当前在真实环境中获取的在线数据集。对收集到的网络数据进行预处理,得到只有13个特征(bitl9数据集)。bitl9数据集的特征数小于kdd99数据集。将正常的网络数据和网络攻击分为dos和probe两类,以减少计算处理时间,分析网络数据,保护网络安全。此外,在实验中,使用已知攻击和未知攻击来测试我们的ids。
2机器学习算法
2.1k一均值聚类算法
k-means聚类的目的是利用最小二乘法对数据进行分类。目的是将n个观测值分成k个簇,每个簇都属于类别最近的群。即,k-means聚类是一种基于属性/特征将对象分类或分组为k个组的算法。k是正整数。聚类主要是计算每个数据到每个组中心距离的平方值,找出最小距离是最近的组。
2.2支持向量机分类算法
支持向量机(SVM)分类算法是一套相关的有监督学习方法,主要用于数据分析和模式识别等常用的分类和回归分析方法。该方法根据分类器的结构和特性而变化。最常见的支持向量机是使用线性分类器来预测两个可能类别之间每个输入的成员类。更准确的定义是支持向量机构造一个超平面或超平面集,将所有输入分类到高空间甚至无限空间。最接近分类边界的值称为支持向量。支持向量机的目标是最大化超平面与支持向量之间的边界。
2.3评价标准
在本文中,ids的检测性能基于以下值:
ids的总检测率(dnl:指ids能够正确检测dos攻击、prob攻击和正常网络数据的百分比。
ids的正常网络数据检测率fdrn):ids能够正确检测正常网络数据的百分比。
ids的dos攻击检测率(drd):ids能够正确检测dos攻击数据的百分比。
入侵检测系统的prob攻击检测率(drp):指入侵检测系统能够正确检测prob攻击网络数据的百分比。
3实验结果
在实验中,将bitl9数据集分成三组,即训练数据集和两个测试数据集。在已知攻击类型的第一次实验中,训练数据有7100条记录,包括2700条dos记录、2700条探测记录和2700条正常记录。另一方面,测试数据器有5100条记录,包括1700条DOS记录、1700条探针记录和1700条正常记录。在第二个未知攻击类型的实验中,使用与第一个实验相同的训练数据集,但是测试数据集不同。它有三种未知攻击类型,每种攻击类型有1500个攻击记录,共有4500个记录。
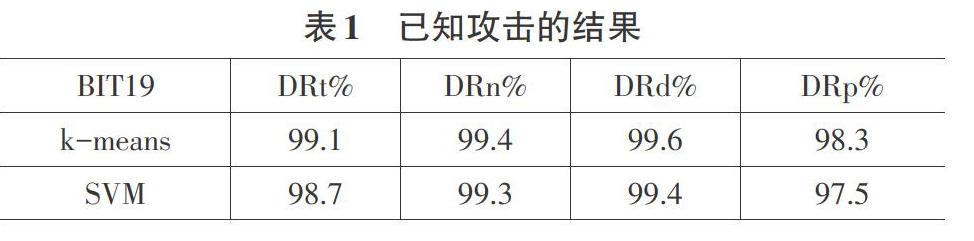
3.1已知攻击的实验结果
利用BITl9训练集进行训练后,第一次实验结果见表1。k-mean聚类算法和支持向量机分类算法也提供了类似的非常好的结果。
示图尺寸一般为(宽*高):75mm*50mm.黑白绘图,请确保图表中文字清晰。
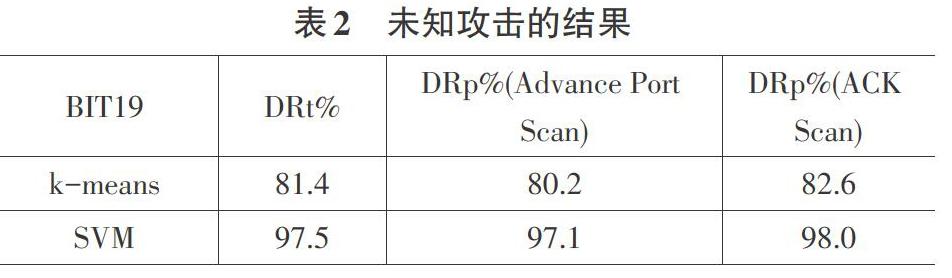
3.2未知攻击的实验结果
在第二个实验(未知攻击)中,研究了两种未知攻击类型,即预先端口扫描和ack扫描。在这种情况下,使用k均值聚类和支持向量机的入侵检测模型对两种攻击类型的数据没有先验知识。这些测试结果如表2所示,支持向量机技术在检测两种未知攻击类型时具有很高的检测精度,ACK扫描的总检测率为97.5%,ACK扫描的总检测率为98%以上,进位端口扫描的总检测率为97.1%。另一方面,k均值聚类在检测未知攻击时可以检测到较低的检测精度。
4结论
本文在bitl9数据集的基础上,研究了两种不同的机器学习技术:k均值聚类算法和支持向量机分类算法。从第一次对已知攻击类型的实验来看,两种技术的检测率都高于98%。在对未知攻击类型进行实验时,支持向量机技术的检测率与第一次实验相同,总检测率为97%,而k均值聚类的检测率平均下降到80%左右。
该框架的主要优点是利用无监督机器学习技术检测网络流量中的未知攻击。我们提出的框架是基于(a)将来自网络包的字节流嵌入到由一些预定义语言引起的高维向量空间中,(b)使用字节序列之间的相似性度量来构造一个正常活动的模型。使用该建议框架的主要优点是能够可靠地检测以前不可见的漏洞,而无须对系统进行培训——这是由于当前漏洞相对于传统的基于签名的网络入侵检测系统的可变性造成的。由于近年来变异性的增加,框架变得非常重要。