基于双向循环神经网络的语音识别算法
2020-06-08葛言碌张澎孙杰陈宇
葛言碌 张澎 孙杰 陈宇
摘要:由于传统语音识别算法识别耗时长且准确率低,该文提出了一种基于双向循环神经网络来进行语音识别的方法。循环神经网络能够进行记忆,是一种特殊的神经网络,它在NLP领域取得了很大的成功。相比于单向神经循环网络,双向循环神经网络在识别的正确率上有着更大的优势。实验证明,相比于单独的SGMM,DNN等语音识别算法,双向循环神经网络算法对语音识别的错误率更低,对语音识别的研究具有重大意义。
关键词:语音识别;双向循环神经网络;深度神经网络;递归神经网络
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2020)10-0193-03
语音识别是指通过信息技术将语音这一音频转化成文字。如今互联网急速发展,语音识别也是人工智能方面炙手可热的一个重要研究分支,在近些年来也在不断地进步发展。在现实应用的过程中,语音识别经常与翻译,交流,声控等实际应用相结合,提供一个通过语音实现人与机器之间的自由交互方法。
1933年,西班牙的神经生物学家Rafael Lorente de N6发现了大脑皮层的解剖结构允许刺激在神经回路中循环传递,他因这一发现提出了反响回路假设。在此之后,美国学者JohnHopfield基于Little的神经数学模型使用二元节点提出了有结合存储能力的神经网络——Hopfield神经网络。接着MichaelI.Jordan基于Hopfield网络结合存储这一概念,在分布式并行处理的理论下建立了新的循环神经网络——Jordan网络。1991年,Sepp Hochreiter发现了循环神经网络有长期依赖这一问题,为解决这个问题,引入了大量优化理论,并且还衍生了很多改进后的算法,其中双向循环神经网络就是其中比较典型的一个。循环神经网络刚诞生就被用于语音识别这一功能上,但它的表现不佳。因此在二十世纪90年代的早期,有学者曾经尝试把SRN与其他的概率模型,如隐马尔可夫模型结合来提升其功能。双向循环神经网络提出后循环神经网络对自然语言的处理能力得到了显著提高。怛在20世纪90年代,由于当时的时代背景,基于循环神经网络的相关技术成果并没有得到大规模的推广被人使用。在进入21世纪以后,伴随深度学习方法的逐渐成熟与被人接受,对数据计算能力的显著提升与各中特征学习技术的不断出现,结构复杂但实用性很强的双向循环神经网络逐渐在自然语言处理的相关问题中崭露头角,并逐渐成为语音识别方面的一个重要算法。
本文主要应用的是,以双向循环神经网络为核心,与动态规划,深度神经网络,快速傅里叶变换等算法相结合对语音进行识别。实验表明,采用以双向循环神经网络为核心的算法能够使语音识别的错误率更低,实用性更强。
1基本理论
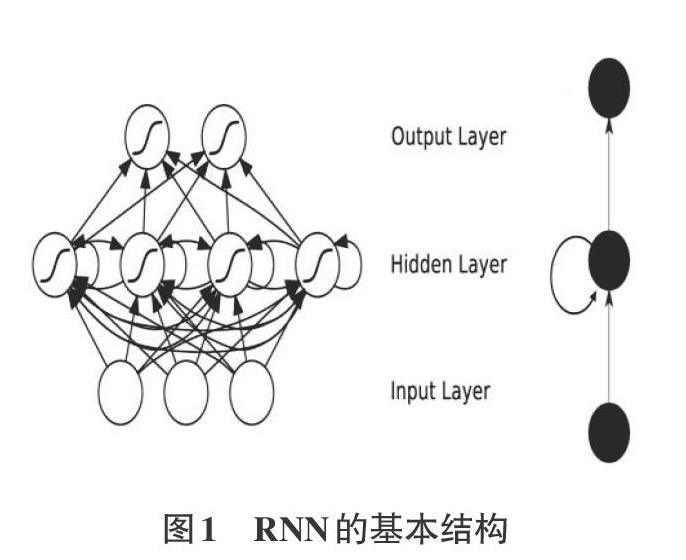
1.1循环神经网络(RNN)
循环神经网络是神经网络结构中的一种,它是类比于我们的认知而产生的一种观点。由于人的认知受过去的经历影响,循环神经网络和深度神经网络。卷积神经网络卷积神经网络不同的是:它不只考虑上一时刻的输入,而且赋予了网络对前面的内容的一种“记忆”功能。
RNN的提出是由于研究发现一个序列在某一时刻的输出与之前的输出有不可分割的关系,所以叫作循环神经网络。其具体表现在网络会对之前的有关信息储存并将其应用于当前输出的相关计算中,简而言之就是隐藏层之间的节点是有连接的。
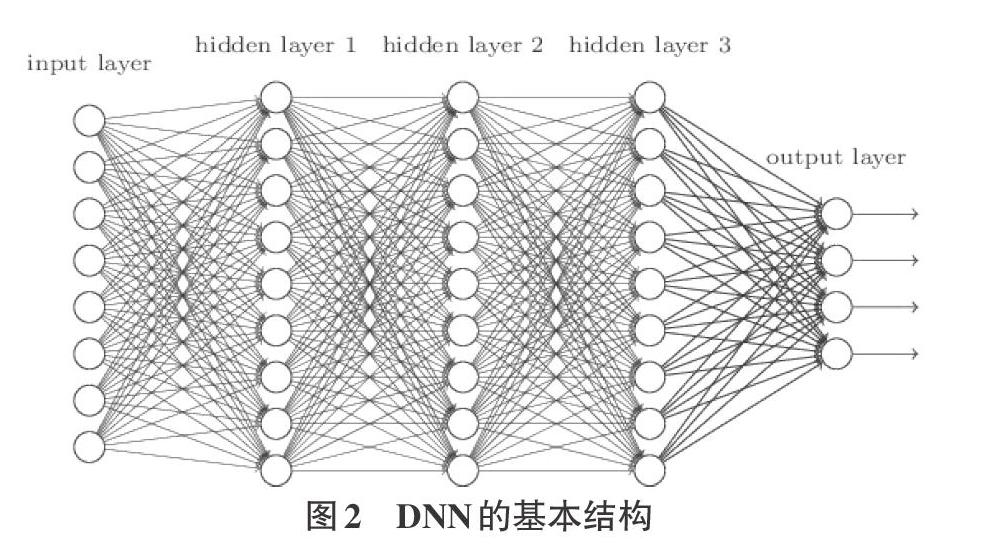
1.2深度神经网络(DNN)
神经网络技术诞生在20世纪50-60年代,在那时它叫感光机。它分为三部分:输入层,隐藏层,输出层。在输入层有已经转换成特征向量的输入信号,然后它会在隐藏层中经过处理,处理完后再傳人输出层,在输出层得到分类结果。但是因为它对比较复杂的函数处理起来较显无力,深度神经网络也就应运而生。在众多层中第一层是输入层,负责特征向量的输入,其他的除了最后一层,中间的若干层都是隐藏层,而最后一层是输出层。所以DNN也可以理解为是一种有许多隐藏层的神经网络。
DNN值中,层层间都是连接的,每一层的每一个神经元都与和这一层相邻的层直接相连。深度神经网络看似非常复杂,但是以单元的角度来看其实也都是由若干个重复的部分组成的。
DNN与大多数传统意义上的机器学习算法并不一样,它不需要人工干预就可以进行自动特征提取,在对没有标记的数据进行训练时,深层网络中的各个节点层抽取样本的输入来自动学习特征。深度神经网络处理和学习大量没有标记的数据的能力相比较于之前的其他各个算法还是有很显著的优势的。但与此同时,也有一定的缺陷,DNN在训练模型时相比于传统方法要耗费更长的时间,随之而来的成本也比传统方法更高。
1.3梅尔频率倒谱系数(MFCC)
为了让电脑识别我们的音频数据,我们首先要将音频数据从时域转到频域,这让才能够提取特征,而MFCC是语音识别中广泛使用的特征。
对于一段音频文件我们将其分为很多帧,每帧经过快速傅里叶变换得到一个频谱,频谱能够反映信号频率与能量间的关系。在具体绘图时,我们对各谱线的振幅都做了对数计算,是为了使振幅较低的成分相对振幅较高的部分更加明显,这就是对数振幅谱,这类频谱图更便于观察在低振幅噪声中的周期信号。语音有比较常用的频率,也就是重要频率,我们称这样的频率形成的峰为共振峰,这类峰也可以看作一种辨识符号,通过它我们可以来区分声音,这也是我们要将其提取的原因。这样我们可以得到一段语音的频谱,但人的听觉只能听到少数频率的声音,对于很多频率的声音我们是听不到的。梅尔频率分析就是由于人在这一方面的特点而产生的,实验证明了人只能听见在坐标轴上并不连续的某些频率。并且不同频率密度不同。大致满足低频密集高频稀疏这一特点。MFCC通过这一点将我们日常中的音频转化成为特征向量,每一个向量就可以代替某一帧,作为其特征。
1.4双向循环神经网络
由于普通的循环神经网络在很多方面有缺陷,因此提出了双向循环神经网络这一概念。因为很多具体的事情是需要结合未来的数据才能得到答案的,而单向循环神经网络只关心与过去的数据,它并不能实现这一效果。BRNN是又两个循环神经网络相反方向合并而成,并且这两个相反方向的单向循环神经网络都会和输出层直接相接触。所以为了结合未来数据增添了反向循环神经网络,两个方向的网络结合到一起形成BRNN在过去与未来共同基础下决定输出的治愈后答案,使我们最后得到的结果更加的准确。
双向循环神经网络的具体结构由向前和向后层共同连接输出层。对于双向循环神经网络它的隐含层,向前推算跟单向的循环神经网络是一样的。对于任何一个时间t,它的输入會同时提供给两个方向相反的单向循环神经网络,输出也将由这两个单向循环神经网络共同来决定。这种共同决定的方式也注定着带来优势和劣势。优势是兼顾全局必定能使他做出正确决策的概率将会提高,而劣势则是每次输出他的判断其实会变得很复杂,相应的也会付出更多的时间与成本了。
2实验过程及结果
2.1实验过程
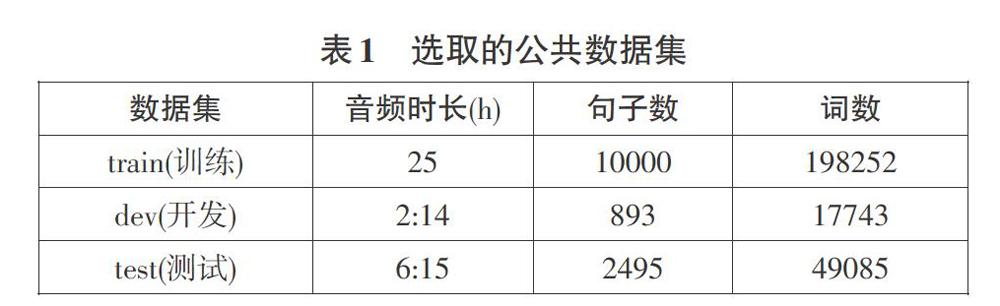
本实验采用的公共数据集是清华大学中文语料库THCHS-30,这个数据集包含一个时长25小时共包含10000句子近20万词的训练集,一个时长2小时14分893个句子一万七千多词的开发集与一个6小时15分2495个句子近5万词的测试集。
选择完数据集后,采用上文提到的流程进行语音识别,通过基于双向循环神经网络的语音识别方法对其进行训练和测试并得到实验结果。其实验流程具体如下图:
2.2实验结果
在具体的实验中,我们首先用快速傅里叶变换对所选的样本进行特征提取,接下来用双向循环神经网络对提取出来的MFCC特征数据进行训练和测试。
由于单独的一个方法的错误率并不能体现我们的算法是否具有优势,所以为了确认这一点,所以我还同时分别做了以DNN和RNN为核心的算法对测试集来测试并进行对比。经过试验,得到了下表的错误率对比。
通过观察由我们实际实验得到的结果表2,我们可以发现单向循环神经网络RNN的错误率是要低于比较传统的DNN的,这也体现循环神经网络在语音识别中是能起到一定的作用的。而且BRNN的错误率明显低于RNN的错误率,说明双向循环神经网络在语音识别中的准确性是要显著比单向循环神经网络要高的。这一点也体现了语音识别方面当前语音对应的文字跟之后的语音是有很大关系的,结合之后的语音可以很明显地提高语音识别的正确率。
3结论
本文采用基于双向循环神经网络的语音识别方法对模型进行训练。首先和传统的语音识别方法一样我们先用FFT辅助提取出MFCC并加以识别,识别得到一个特征向量将它转换为文字并输出。基于双向循环神经网络的语音识别方法在语音识别的精确度角度来看,在一定程度上提高了语音识别的准确率。但与此同时在实验中也发现了这个算法的一些缺陷,就是它在训练时间上显著要比传统算法与单向循环神经网络要长,这可能会造成在开发中需要更多的成本。但无论在测试还是在实际应用时都具有很好的表现,具有很大的应用价值。