一种基于特征点对齐的假脸检测框架*
2020-06-08刘贤刚郝春亮
刘贤刚,范 博,郝春亮
(中国电子技术标准化研究院,北京 100007)
0 引 言
Deepfake 是一种深度图像生成网络的衍生技术,它将深度学习与假脸合成技术相结合,可以通过变换人脸制造假脸图像或视频。2017 年Deepfake技术席卷全球,虽然遭到全网封禁,但这项技术仍然在不断的更新进化,越来越多的假脸视频出现在国内外各大视频网站上。近期随着技术门槛的不断降低,普通用户也能够做出非常逼真的假脸效果。假脸视频的泛滥,引起人们对于新闻媒体真实性的担忧。此外,各类换脸软件也存在隐私泄露的风险。由此所引发的人脸安全危机,引起了人们的广泛关注。2019 年国信办印发的《网络音视频信息服务管理规定》中,4 次提及深度学习,并针对AI 造假视频进行规定。面向Deepfake 技术的假脸检测方法成为产业界和学术界的关注热点。
1 背景及相关研究
近年来,国内外发表了许多针对假脸检测的研究,尤其是针对Deepfake 的检测方法。各方法的思路、使用技术互有差异。
2017 年,Zhang 等人[1]用栅格划分或者SURF提取关键点描述子,用K-means 方法生成特征,通过SVM、随机森林、MLP 等分类器进行2 分类。在自己建立的基于LFW 的假脸数据集中达到92%的准确率。Zhou 等人[2]提出了一种双流网络结构来捕获篡改伪迹证据和局部噪声残差证据的方法,其中一个分支流是基于CNN 的人脸分类器,另一个是基于隐藏特征的三元组分支流。
2018 年,Güera 等人[3]提出端到端的假脸检测系统,通过预训练的InceptionV3 模型以及LSTM网络计算真伪概率;该团队从网站上收集300 个Deepfake 视频,在不到2 秒的视频(以每秒24 帧的速度采样40 帧的视频)的情况下,这个系统可以准确地分析该片段是否为深度伪造,准确率达97%。Li 等人[4]研究发现,Deepfake 合成视频的训练样本很少有闭眼的数据,因此可以通过检测视频人脸的眨眼频率来判别假脸;结合LSTM 单元以及二分类的交叉熵损失函数训练CNN 网络。在真实视频中检测到34:1/min 眨眼频率,但在虚假视频中只有 3.4/min blinks,可以为区分假脸视频提供依据。
2019 年,Nguyen 等人[5]提出多任务学习的方式用于检测和分割处理过的面部图像和视频。Sabir等人[6]借鉴行为识别领域,利用时间信息处理视频的方法,在FaceForensics++ 数据集上达到较好的检测水平。Li 等[7]人根据Deepfake 假脸生成的原理,通过制造伪影的方式生成大量假脸数据集,使用多种网络模型进行假脸检测,取得了较好的检测效果。Yang 等[8]人研究发现Deepfake 生成的假脸从2D 面部图像估计三维头部姿态(比如头的方向和位置)时与真实人脸之间会存在误差;该团队进行实验来证明了这一现象并且将这种特征用SVM 分类器进行假脸分类。Gu 等[9]人提出了针对重要人物的专用假脸检测技术;该团队认为人在说话时面部表情和头部运动有独特的模式,称为软生物特征,但是Deepfake 生成的假脸不会有这种特定的模式,同时考虑演讲文本内容对说话风格和表情的影响,用不同的文本进行实验平均AUC 达到了0.91。Hassan等人[10]提出一种使用区块链的解决方案和通用框架,以追踪和跟踪数字内容的来源和历史到其原始来源,防止造假;该方案专注于视频内容,并认为其框架通用于其他形式的数字内容。
虽然上述方法取得了较好的效果,但在实际应用过程中还存在诸多问题。如:使用算法复杂度高,计算开销大,图像的处理速度慢;LSTM 在对视频帧处理时,读取的是整张图像,背景噪声影响较大,并且如果图片中包含多张人脸时,容易出现误判。另外假脸生成技术在不断更新,有些算法的针对性较强,对新出现的假脸数据检测精度大幅下降。
本文针对以上问题,提出了一种基于人脸特征点对齐的假脸检测框架,其主要特点如下:
(1)使用对齐后的人脸区域特征进行假脸判别,减少噪声影响,降低计算复杂度;
(2)能够同时满足单张图片中单人脸,与多人脸的假脸判别;
(3)对不同网络结构有较好兼容性;
(4)针对不同技术生成假脸的检测有一定的通用性。
2 基于特征点对齐的假脸检测框架
本文提出一种基于特征点对齐的假脸检测方法,该框架指定的总体流程如图1 所示。该流程首先从图片或视频帧中进行人脸检测,获取关键特征点,并根据关键特征点进行人脸对齐,然后使用卷积神经网络进行人脸特征提取,最后进行假脸判别。该框架的主要特点是使用特征点对齐加强假脸识别流程的兼容性和准确性。

图1 假脸检测总体流程
2.1 人脸检测
人脸检测采用MTCNN[11]网络,MTCNN 是一个多任务网络,通过网络级联的方式,能够同时输出人脸框坐标,和人脸关键特征点坐标。
根据检测到的特征点坐标,与标准脸特征点的坐标关系,计算出相似变换矩阵,然后使用相似变换矩阵对整张人脸图片进行相似变换,将人脸对齐到一个统一尺寸的图像上,并将人脸区域扣取出来。相似变换是对原图像做等距变换和均匀缩放,角度、平行性和垂直性不发生变换。相似变换矩阵公式如下:
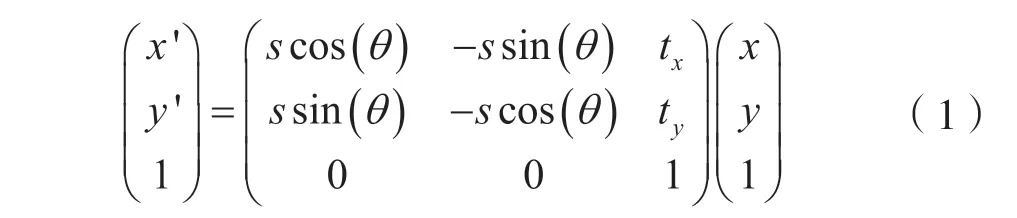
通过相似变换,可以使图像的特征分布趋于一致,但又不会改变像素间的平行关系,更容易发现真脸与假脸之间的差异。通过人脸检测,可以只对人脸区域进行处理,减少了背景噪声的影响。
2.2 人脸特征提取网络
在进行人脸特征提取时,为了能够得到更好的特征表达,本文参考了现有的经典网络结构,综合考虑了算法模型的复杂度、执行效率、以及在Imagenet 上的分类精度,选用了不同的骨干网络(backbone)网络进行对比,研究不同算法模型在假脸检测中的表现。
(1)ResNet:该网络带有Shortcut Connection机制[12],很好的解决了随着网络结构加深而导致的梯度消散问题,从而使得能够构建更深的神经网络,以获得更好的性能。
(2)Inception ResNet:谷歌公司在Inception网络的基础上,结合残差结构发布的网络,在 ILSVRC 图像分类基准上取得了较高准确率。
(3)Densenet:参考ResNet 的结构,同样使用跨层连接,减轻了训练过程中的梯度消散,同时大量的特征被复用,使用少量的卷积核就可以生成大量的特征,所以模型的尺寸也比较小,在imagenet 上达到相同精度时,其参数量和计算量可降为ResNet 的一半。
(4)ResNext:ResNet 的升级版,用平行堆叠相同拓扑结构的blocks 代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了。
面向上述4 个经典backbone 网络,本文选取了ResNet50、densenet121、Inception ResNet v2、和ResNext50,使用4 种网络分别对本文所提出的假脸检测效果进行实验验证。4 种模型的参数量如表1所示。本文在DFDC 数据集上,对上述4 种算法模型进行了对比实验。
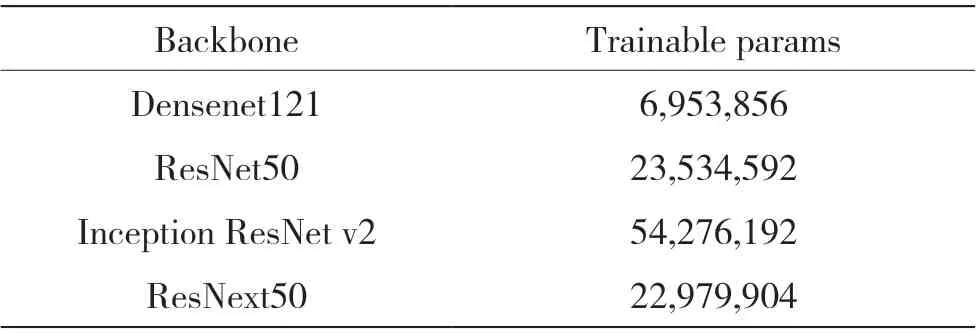
表1 网络参数对比
由于ResNet 网络广泛的应用基础,为了进一步检验算法模型对不同技术生成的假脸图像的检测能力,本文使用ResNet50 在多种数据集上进行了训练和模型测试。为了提升图像的处理效率,还对ResNet50 进行了裁剪尝试,使用了其中的部分残差结构。新模型在CPU 上的单帧处理时长为100ms左右。裁剪后的网络结构如表2 所示。

表2 裁剪后的残差网络
2.3 二分类交叉熵损失函数
进行假脸判别时,本文使用了二分类交叉熵损失函数:
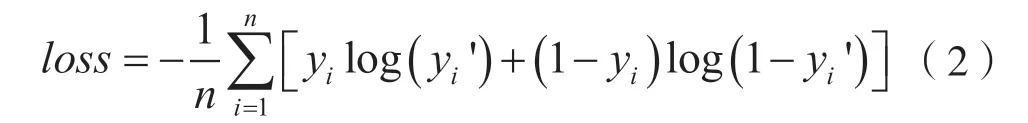
上式中,n为被预测的样本的个数;yi´为判别为fake 的置信度;yi为样本的真实label,当被判别样本为fake 时其值为1,否则为0。
3 实 验
3.1 实验设置
本文设计两组试验,一组为对不同backbone 网络的支持试验,测试本文所提出框架对前文4 种主流backbone 网络的支持。第二组为对不同Deepfake技术适用性试验,测试本文所提出框架面向不同DeepFake 技术生成的假脸数据时的检测效果。
试验过程中,模型训练用的硬件环境主要配置为,Tesla PH402 双内核显卡,32G 显存、2*14 核/28 线程 Xeon E5-2680 CPU、192G 内存。深度学习环境为TensorFlow1.13.1、cuda9.0、cudnn7.0.4。
3.2 实验数据
(1)对不同backbone 网络的支持试验
作为算法模型对比的基线,本文选用了DFDC数据集,该数据集包含99 992 个伪造视频,19154个非伪造视频。在保证非伪造和伪造样本均衡的前提下,通过人脸检测,获取到224x224 的人脸样本,建立训练集、验证集和测试集,各数据集的样本数量如表3 所示。

表3 数据集样本数量
由于该数据集存在严重的样本不均衡问题,因此在进行数据集划分时,充分考虑了正、负样本的数据配比,保证了最终人脸数据的比例均衡。
(2)对不同Deepfake 技术适用性试验
使用FaceForensics++[13]的数据集,将视频中的每帧图像单独提取,进行人脸检测和对齐。将处理后的数据分为训练集、验证集、和测试集。考虑到样本均衡,每种数据的数量分别如表4 所示。
3.3 实验结果
(1)Backbone 对比实验
实验1,模型训练初始学习速率为0.00001,使用Adam 损失优化器,共完成20 个周期的迭代。经过测试,在0.5 阈值下,4 种网络模型在DFDC 数据集上的实验测试结果如表5 所示。
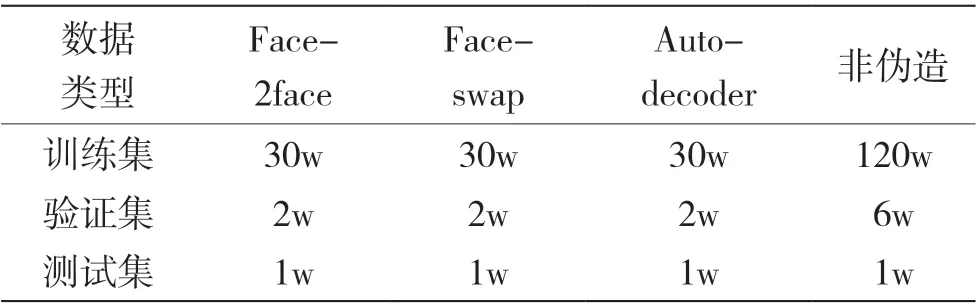
表4 数据集样本数量

表5 DFDC 数据集上试验结果
由结果可知,本文提出的框架在4 种试验设置下都获得了较好的检测准确度。同时,实验结果充分体现了各网络的特点,例如Inception 网络的超参数设定的针对性比较强,当应用在新的数据集上时扩展性不好,因此Inception ResNet v2 的表现相对较弱;其它三种网络可移植性较好,其效果也相对教好。
(2)对主流Deepfake 技术的检测实验
使用ResNet50 模型同样训练20 个epoch,在多种数据集上的测试精度如表6 所示。

表6 多种来源检测结果
从结果可以看出,本文所述框架可以对不同开源的Deepfake 图像进行假脸判别。
4 结 语
本文提出了一种基于特征点对齐的针对Deepfake 进行假脸检测的检测框架。实验证明,该框架对不同网络结构有较好兼容性,同时对不同Deepfake 技术生成假脸的检测有一定的通用性。
