基于数据挖掘判别用电类别异常的分析与研究
2020-06-08金昌铉朱宇龙马博刘森黎晚晴陈玲娜
金昌铉,朱宇龙,马博,刘森,黎晚晴,陈玲娜
基于数据挖掘判别用电类别异常的分析与研究
金昌铉1,朱宇龙1,马博1,刘森1,黎晚晴2,陈玲娜2
(1.中国南方电网有限责任公司,广东 广州 510000;2.南方电网数字电网研究院有限公司,广东 广州 510000)
随着电网企业全面实现智能电表全覆盖和低压集抄全覆盖,产生了海量实时的计量数据,这些数据通过分析挖掘技术,可在辅助电网规划、电网运行状态监控、负荷预测等方面发挥价值。然而,利用传统的统计分析挖掘技术,较难处理如此海量的计量数据,也无法识别异常数据蕴藏的企业经营风险问题,因此,有必要引入大数据分析挖掘技术,运用分类预测算法进行异常分析,有效识别电网高价值用户的用电类别异常。对电网企业用户如高耗能行业用户、一般工商业用户、大工业用户以及居民用户的用电数据进行深入研究,从宏观和微观角度分别对用电行为数据进行特征提取和行为分析,刻画出不同用电类别用户的负荷曲线,归纳用电行为特征,运用有效监督的数据挖掘算法构建用电类别异常识别模型,并和用户档案中的用电类别数据进行核对,找出异常数据,辅助识别电能计算装置使用异常、用户档案信息错乱和电费收取错误等异常。
用电行为;数据挖掘;日负荷曲线;决策树算法
1 引言
随着智能电网的普及,电力自动化数据日渐增多,如何从这些海量的数据中挖掘出其隐藏的价值便显得尤为重要。整个社会的用电量是无法估量的,用电的时间段、用电高峰的电力负荷、用电的需求这些都处于时时变化的状态。大数据时代的到来,已推进了新兴技术的突破,其中,分布式分析挖掘计算引擎Spark也带给了人们挖掘海量数据的可能性,而数据的背后通常也隐藏了事物发展的潜在规律,用电数据也不例外。运用分类预测算法,从海量数据中挖掘出不同类别用户的用电行为规律,是本文研究的核心内容。
通过阅读大量的文献发现,当前对用电用户的研究大多集中在运用用户基本信息和客户服务数据构建标签的用户画像相关的技术,但因数据质量问题,用户标签和其用电行为标签未能完全匹配。
本研究运用大数据挖掘技术对电力客户进行用电特征的分类分析,将得到的用户分类与原始分类指标作对比,找出用电类别异常的用户,辅助电网企业追回损失,也加深对客户的了解,便于针对不同的用户群制订服务策略,实现精准客户服务。
2 大数据挖掘算法
大数据挖掘是当今社会研究的热点问题,所谓数据挖掘,是指从大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。通常分为有监督学习算法和无监督学习算法。其中,无监督学习算法是对没有分类标记的训练样本识别其结构性知识,比如聚类分析。而有监督学习算法,是事先对具有标记(分类)信息的训练样本进行学习,再对样本外的数据进行分类预测,也称分类算法。常见的分类算法有决策树、神经网络、支撑向量机和贝叶斯等,不同的分类算法,由于原理的不同,存在各自的优缺点和适合的应用场景,各个算法的优缺点如表1所示。
表1 各个算法的优缺点
算法优点缺点 决策树①不需要任何领域知识;②不需要参数假设;③适合维度较多的数据;④简单、易用、容易理解;⑤执行效率高;⑥可同时处理数值型和字符型字段①当训练样本失衡时,信息增益偏向于那些具有更多数值的特征;②容易出现过拟合现象;③常忽略字段间的相关性;④不支持在线学习 神经网络①分类准确率高;②并行处理能力强;③分布式存储和学习能力强;④鲁棒性较强,不易受噪声影响①需要大量参数;②结果难以解释;③训练时间过长 支持向量机①可以解决小样本下机器学习的问题;②提高泛化性能;③可以解决高维、非线性问题;④可以超高维文本分类问题;⑤避免神经网络结构选择和局部极小的问题①对缺失数据敏感;②内存消耗大,难以解释;③运行和调参较为麻烦 贝叶斯①所需估计的参数少,对于缺失数据不敏;②有着坚实的数学基础以及稳定的分类效率①需要假设字段间相互独立;②需要知道先验概率;③分类决策存在错误率
3 用电数据集与数据清洗
3.1 数据集
基于企业大数据中心,读取企业营销自动化积累的电量数据,选择参与模型训练的数据,主要包括计量点表、运行电能表、运行电能表日冻结电能量表、运行电能表日负荷极值表和用户信息表等。其中运行电能表日冻结电能量表记录
的是电能表总正向有功以及峰、平、谷各时间段的正向有功,用来说明用户固定时间段的用电量;运行电能表日负荷极值表用于记录电能表功率、电压和电流等信息。
经筛选抽取后的数据基础表结构如表2所示。
表2 数据基础表结构
数据表构建指标数据类型指标说明 用电量计量点编号VARCHAR2(20)计量点的唯一编号 用户编号VARCHAR2(20)用电客户的唯一编号 用电时间Date包含日期和时分秒 最大功率Number(8,3)一天内最大的有功功率,即一天内最大负荷 平均功率Number(8,3)一天内有功功率平均值 用电客户用户编号VARCHAR2(20)用电客户的唯一编号 负荷性质代码VARCHAR2(8)负荷的重要程度分类 用电类别代码VARCHAR2(8)定义客户用电基本属性分类及代码,又称用电类别 电压等级代码VARCHAR2(8)用电客户受电点的电压等级 行业分类代码VARCHAR2(8)用电客户的行业分类代码 用户类别代码VARCHAR2(8)用户一种常用的分类方式,方便用户的管理 高耗能行业类别代码VARCHAR2(8)依据国家最新的高耗能行业划分 用电性质VARCHAR2(8)用电性质 用户状态代码VARCHAR2(8)用电客户的状态说明 客户分群标志VARCHAR2(8)客户重要性分类类型(客户分群代码) 运行容量Number(15,4)用电客户正在使用的合同容量 行政区域代码VARCHAR2(8)用电客户所在地址的行政区划代码 城乡代码VARCHAR2(8)用电客户所在地址的城乡代码 计量点计量点编号VARCHAR2(20)计量点的唯一编号 用户编号VARCHAR2(20)用电客户的唯一编号 计量方式代码VARCHAR2(8)主计量方式 计量点电压等级代码VARCHAR2(8)标明计量点的计量电压等级 计量装置分类代码VARCHAR2(8)计量装置分类主要根据用电量进行区分 计量点状态代码VARCHAR2(8)标明计量点的当前状态 计量点类别代码VARCHAR2(8)计量点类别代码 计量点用途代码VARCHAR2(8)定义计量点的主要用途 计量点位置代码VARCHAR2(8)标明计量点所属的具体位置 接线方式代码VARCHAR2(8)计量点接线方式 用电容量Number(15,4)计量点用电容量 计量点类型代码VARCHAR2(8)计量点类型代码 运行电能表标识VARCHAR2(16)运行电能表的唯一标识
3.2 数据清洗
数据清洗是发现并纠正错误数据的第一道程序,包括检查数据一致性、处理无效数据和缺失值等,数据清洗的目的是为了得到高质量的建模输入数据,而分类算法通常要求输入数据进行归一化等方法处理,以便提高数据挖掘算法的执行效率。同时,由于数据挖掘算法往往只能对单一的数据表进行分析,因此就需要将相关数据整合成一个“宽表”,这个表每行都是代表一个用电户,每列代表与用电户用电性质潜在相关的影响因素,最后一列“用电性质”为分类算法的目标列。相关数据整合成的“宽表”如表3所示。
4 用电类别异常识别
4.1 模型变量选择
4.1.1 特征选择
为了缩小选择范围,提高模型的性能,需要对数据清洗后得到的“宽表”进行特征选择,即字段筛选,通常采用以下几种方式:根据数据的特征质量,过滤掉数据质量很差的字段;计算剩余的输入字段对目标“用电性质”的重要性,选取一些对用目标字段影响较大的字段,减少数据挖掘算法的计算量,提高执行效率。
4.1.2 样本数据选取
通常一个电网公司的用电户数据量达千万级别,如果在模型训练阶段就将所有的用电户数据参与建模,则会出现算法执行时间过长,甚至细微的参数调整都会带来重复执行的需求;另一方面,大工业用户、一般工商业用户、居民用户的本身体量也不属于一个数量等级,容易导致样本失衡的问题。因此使用抽样技术,分别选取不同类别的典型用户数据参与模型训练,可以有效提高算法执行效率。本文选取10个典型行业的计量点在当前年的所有特征指标及其组合指标,分析用户的用电行为,既能保证样本的抽样覆盖,也能避免遗漏用户的季节性用电特征。
表3 相关数据整合成的“宽表”
构建指标数据类型指标说明 用户编号VARCHAR2(20)用电客户的唯一编号 用电日期Date数据时间 年份VARCHAR2(8)数据年份 月份VARCHAR2(8)数据月份 星期VARCHAR2(20)判断数据日期是星期几 是否节假日VARCHAR2(20)判断当天是不是节假日 正向有功总Number(15,4)全天总用电量 正向9_12Number(15,4)一天时间段(09:00—12:00)用电量 正向14_17Number(15,4)一天时间段(14:00—17:00)用电量 正向19_22Number(15,4)一天时间段(19:00—22:00)用电量 正向2_5Number(15,4)一天时间段(02:00—05:00)用电量 最大功率Number(8,3)一天内最大的有功功率,即一天内最大负荷 平均功率Number(8,3)一天内有功功率平均值 负荷性质代码VARCHAR2(8)负荷的重要程度分类 用电类别代码VARCHAR2(8)定义客户用电基本属性分类及代码,又称用电类别 电压等级代码VARCHAR2(8)用电客户受电点的电压等级 行业分类代码VARCHAR2(8)用电客户的行业分类代码 用户类别代码VARCHAR2(8)用户一种常用的分类方式,方便用户的管理 高耗能行业类别代码VARCHAR2(8)依据国家最新的高耗能行业划分 用户状态代码VARCHAR2(8)用电客户的状态说明 客户分群标志VARCHAR2(8)客户重要性分类类型(客户分群代码) 运行容量Number(15,4)用电客户正在使用的合同容量 行政区域代码VARCHAR2(8)用电客户所在地址的行政区划代码 城乡代码VARCHAR2(8)用电客户所在地址的城乡代码 计量方式代码VARCHAR2(8)主计量方式 计量点电压等级代码VARCHAR2(8)标明计量点的计量电压等级 计量装置分类代码VARCHAR2(8)计量装置分类主要根据用电量进行区分 计量点状态代码VARCHAR2(8)标明计量点的当前状态 计量点类别代码VARCHAR2(8)计量点类别代码 计量点用途代码VARCHAR2(8)定义计量点的主要用途 计量点位置代码VARCHAR2(8)标明计量点所属的具体位置 接线方式代码VARCHAR2(8)计量点接线方式 用电容量Number(15,4)计量点用电容量 计量点类型代码VARCHAR2(8)计量点类型代码 用电性质VARCHAR2(8)用电性质
4.1.3 最终模型分析指标
将负荷波动特性指标、时间指标、分类指标排列组合得出最终用于模型分析的各项指标,具体指标如表4所示。
4.2 模型构建
采用70%的数据作为训练数据,分别采用决策树、神经网络、支撑向量机、朴素贝叶斯等算法建立了模型,并用剩余30%数据进行了测试。
各算法建模参数和测试结果如图1所示。神经网络建模参数如图2所示。支撑向量机建模参数如图3所示。朴素贝叶斯建模参数如图4所示。
4.3 模型结果
主要选取了总体正确分类率、Kappa统计量这两个评估指标作为模型评估参数,各算法建立的模型测试结果如表5所示。从结果看,神经网络算法得到的模型准确率最高,其次是决策树算法。
考虑到业务实际情况,除了需要知道哪些企业用电性质申报存在欺诈,还需要了解对方具有什么用电特征,因此相比神经网络为黑盒模型,决策树模型可以得到显性的业务规则,因此最终选择决策树模型作为最终的模型。通过决策树算法对用电数据进行分析建模,最终得到如图5所示的用电性质识别模型,决策树的根节点到每个叶子结点形成的路径就对应一条用电性质决策规则。
例如,图5深色的路径就表示“19:00—22:00用电占比小于18%,且09:00—12:00用电占比小于12.25%,且最大功率大于582 W,则100%是工商业用电”。
5 业务应用分析
基于此模型,对辖区内目前登记为“居民生活”用电性质的所有企业进行了分析,如表6所示。
表4 模型分析的各项指标
数据表构建指标数据类型 用电类别分析表计量点编号VARCHAR2(20) 一月工作日正向有功总Number(15,4) 一月周末正向有功总Number(15,4) 一月工作日峰总比Number(4,3) 一月周末峰总比Number(4,3) 一月工作日平总比Number(4,3) 一月周末平总比Number(4,3) 一月工作日谷总比Number(4,3) 一月周末谷总比Number(4,3) 一月工作日最大功率Number(8,3) 一月周末最大功率Number(8,3) 一月工作日负荷率Number(4,3) 一月周末负荷率Number(4,3) …… 十二月工作日正向有功总Number(15,4) 十二月周末正向有功总Number(15,4) 十二月工作日峰总比Number(4,3) 十二月周末峰总比Number(4,3) 十二月工作日平总比Number(4,3) 十二月周末平总比Number(4,3) 十二月工作日谷总比Number(4,3) 十二月周末谷总比Number(4,3) 十二月工作日最大功率Number(8,3) 十二月周末最大功率Number(8,3) 十二月工作日负荷率Number(4,3) 十二月周末负荷率Number(4,3) 负荷性质VARCHAR2(8) 电压等级VARCHAR2(8) 行业分类VARCHAR2(8) 用户类别VARCHAR2(8) 高耗能行业类别VARCHAR2(8) 电源类型VARCHAR2(8) 行政区域VARCHAR2(8) 城乡代码VARCHAR2(8) 计量方式VARCHAR2(8) 计量点电压等级VARCHAR2(8) 接线方式VARCHAR2(8) 用电容量Number(15,4) 计量点类型VARCHAR2(8) 用电类别VARCHAR2(8)

图1 决策树建模参数

图2 神经网络建模参数
图3 支撑向量机建模参数

图4 朴素贝叶斯建模参数
表5 模型结果
模型评估指标算法 决策树神经网络支撑向量机朴素贝叶斯 窗体顶端正确分类率/(%)窗体底端98.8198.83窗体顶端94.05窗体底端窗体顶端93.45窗体底端 Kappa统计量0.968 8窗体底端0.9690.837 7窗体底端0.838 9
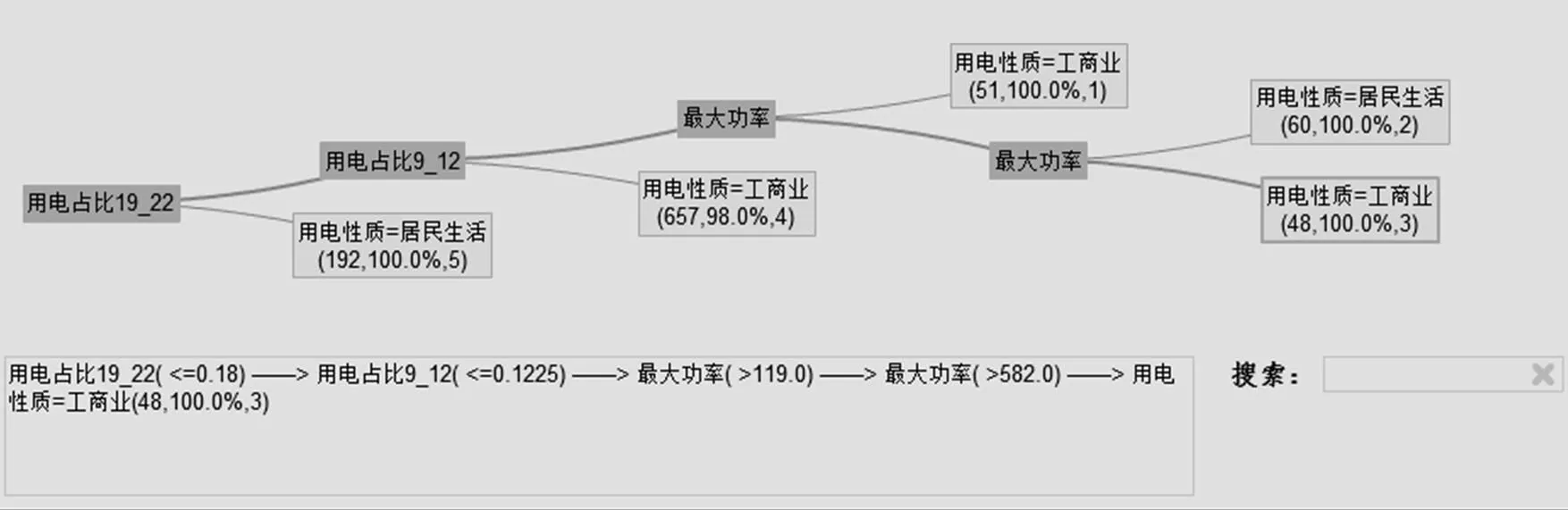
图5 用电性质识别决策数模型
发现存在部分企业被识别为“工商业”用电性质,并且这些企业具有显著的工商业企业用电特征,因此被纳入审计调查的范围,并追回了大量经济损失,在审计工作中发挥了重要的作用。
此模型为电力行业基于数据挖掘技术进行精细化管理提供了有效的示范,后期将进一步利用数据挖掘技术推动电网运营管理的精细化和智能化发展。
表6 “居民生活”用电性质分析表
用户编号年份月份星期是否节假日平均功率最大功率用电占比9_12用电占比14_17用电占比19_22用电占比2_5当前用电性质预测用电性质 87316201901星期一否2113550.2460.2220.1340.010居民生活工商业 52141201806星期二否2404090.2470.2450.1390.014居民生活工商业 6632201903星期三否1832550.2270.2340.1370.019居民生活工商业
[1]高琳琳.基于数据挖掘的短期负荷预测[D].南昌:南昌大学,2014.
[2]陆园园,王成然.基于电力负荷模式分类的短期电力负荷预测[J].中国高新技术企业,2014(1):69-70.
[3]董莉丽.基于大数据挖掘的客户用电行为分析[J].黑龙江科技信息,2016(4):45.
[4]高旭旭.基于深度学习的分类预测算法研究及实现[D].北京:北京邮电大学,2019.
2095-6835(2020)10-0014-04
TM715
A
10.15913/j.cnki.kjycx.2020.10.005
〔编辑:张思楠〕
