基于NL2SQL的智能问答系统研究与应用
2020-06-07张立新于海亮张栋栋张珊珊郑勇峰
张立新 于海亮 张栋栋 张珊珊 郑勇峰


摘要:该文提出了将NL2SQL技术在应用到企业业务应用中,采用的软件架构、针对业务复杂度模型建模方法、基于知识图谱技术的模型预训练和SQL生成时多表关联生成模型。在软件架构方面,提出了基于虚机机器人引擎的总体架构,和基于Master/Dispatch/Worker线程模型的主题机器人的高并发处理模型;针对企业复杂的业务领域,采用业务主题模型对主题机器人处理的业务进行建模和设置;通过知识图谱技术,实现了对NL2SQL需要处理的数据表的预训练,提出了基于子图查询技术的SQL生成模型。
关键词:人工智能;NL2SQL;知识图谱;语义识别
中图分类号: TP182 文獻标识码:A
文章编号:1009-3044(2020)35-0083-04
开放科学(资源服务)标识码(OSID):
Research and Application of Intelligent Question-Answer System Based on NL2SQL
ZHANG Li-xin1, YU Hai-liang1, ZHANG Dong-dong1,2, ZHANG Shan-shan1, ZHENG Yong-feng1
(1.State Grid Information Communication Co., Ltd & China-Power Information Technology Co., Ltd, Beijing 100192,China; 2. State Grid Information and Communication Industry Group, Beijing 100031,China)
Abstract: This paper proposes a method that apply NL2SQL technology to enterprise business applications. Key techniques used in this approach include using software architecture building the model for business complexity, model pre-training based on knowledge graph technology and generating a SQL model on associated multiple tables. In terms of software architecture, the overall architecture based on virtual machine robot engine and the high-concurrency processing based on Master/Dispatch/Worker thread model are proposed. According to the complex business domain, the business subject model is used to build and set up handled by the subject robot. Through knowledge graph technology, the pre-training of data table is realized, and the model of SQL generating based on subgraph Matching is proposed.
Key words: artificial intelligence (AI); NL2SQL; knowledge graph; semantic recognition
国家电网公司信息化建设历经SG-186、SG-ERP和SG-ERP2.0等三个阶段的建设,在输电、变电、配电以及人资、财务、物资等领域积累了海量的结构化数据,随着公司数据中台建设的深入推广,对各个业务领域数据的价值挖掘和应用,逐渐成为电力物联网建设的重要内容。但是随企业业务的深入推广和发展,各级业务部门需要跨专业了解公司整体运行情况以及其他部门的业务发展状况,存在着各层级业务人员在需要在不同业务系统中查找、汇总所需数据信息的要求,面临数据查询困难、数据汇总不符合要求、获取数据迟缓等诸多问题。
随着近几年人工智能技术的迅猛发展,语音识别技术、语义识别技术日趋成熟,为NL2SQL(Natural Language to SQL)技术在信息系统中的应用提供了前提条件。NL2SQL解决通过自然语言自由查询数据库的问题,解决了非该业务领域的用户也可以按需查询数据库,降低了对业务人员的要求,降低人机交互的距离和门槛。
1 NL2SQL研究现状
1.1 NL2SQL的历史与现状
早在20世纪中后期,已提出通过自然语言直接访问数据库中存储数据的应用(Natural Language Interfaces to Databases,NLIDB),通过对问句的句式语法分析,回答关于从阿波罗任务中带回的月岩的地质学分析问题。受限于当时技术发展,系统语言的支持上限以及对于语言的理解上限不明确、语言上逻辑和含义的歧义、生僻字的出现等,都极大限制了该领域的发展。2016年,Ghosal等人提出了一个系统,能够很好地处理多表简单查询。2017年,Google开发了Analyza系统,以自然语言为人机交互的接口的系统,支持用户用自然语言做数据探索与数据分析。2018年,Utama, Prasetya等人开发了DBPal工具,面向数据库的端到端的自然语言接口 [1]。
3.2 NL2SQL 在企业级业务中的应用
NL2SQL通过自然语言查询业务数据库中的数据,查询结果通过报表展示;在该场景的实现过程中,涉及中文语音识别技术、语义识别技术、SQL生成技术,本文重点分析讨论上述技术集成形成企业级应用,需解决的问题如下:
1)单击此处输入文字。企业级软件特性和系统工程化问题。目前语音识别、语义识别、语义合成、SQL语句构造和智能报表生成技术仅仅是解决了各种领域中的关键问题,NL2SQL智能查询系统需要将各类技术集成在一起,形成一个功能完备的系统 [2],解决人工智能系统前期投入人工工作量的问题,降低系统使用门槛;
2)SQL脚本构造支持多表关联。在目前公开的数据集中,对多表关联支持率不高,在企业级应用中,多表关联查询是很普遍的需求,需解决SQL脚本构造时支持多表关联的需求;
3)业务的复杂化问题。在企业中,存在多类业务,比如:物资、规划、营销、财务等,需要解决多业务的配置问题。
本文提出基于NL2SQL的企业级软件应用架构,解决NL2SQL智能查询系统的企业级特性和等工程化问题;提出基于图技术解决SQL脚本构造支持多表关联问题;提出基于主题的业务模型,解决复杂业务领域问题。
2 软件架构设计
2.1 目标、需求和约束
技术框架和组件的堆砌和集成并不能形成一套完备的、可用的企业级信息化软件系统;需要一个完整可靠的系统架构机制将技术框架和组件有机地组合起来形成一个可靠、健壮的软件架构,作为企业级软件的骨架,满足系统的功能性、非功能性和工程化需求。对企业级软件而言,满足功能需求,只达到了系统的最低要求,在复杂的生产环境中,需要满足其非功能性需求和工程化需求保证系统在生产中“可用”和“易用”。
对于NL2SQL技术而言,其包括的语音识别、语义识别、SQL脚本构造、SQL脚本执行和报表自动展示等技术已经成熟,系统的目标设计一套企业级NL2SQL智能查询系统[3]。
企业级NL2SQL智能查询系统核心功能需求为:自然语言问答和报表智能展示功能,支持企业的多个业务域。
2.2 总体功能结构设计
NL2SQL智能查询系统提供包括问答服务、语音识别引擎、语义识别引擎、SQL脚本构造引擎、SQL脚本执行引擎、答案合成(语义合成)引擎、答案报表展示等功能,以及答案反馈和评估、业务主题配置、模型自动化训练评估等运营和配置功能[4]。如图1。
用户通过PC端以浏览器方式访问,提出文本格式问题,比如“2019年北京市电力公司售电量是多少?”;或者通过移动端直接语音方式提问。
NL2SQL智能查询系统接收到请求,提交给语义识别引擎进行语义理解,预测用户问题的所属的业务主题,生成JSON格式的语法树。
SQL脚本构造引擎,解析语法树,是否满足语法要求,解析要点包括:Select节点、From节点、Where节点是否存在,不满足要求,直接返回用户,该问题答案不存在[5]。
系统核心架构设计以虚拟机器人为核心元素,每个虚拟机器人独立提供问答服务,每个虚拟机器人对应一个业务主题,由机器人实例管理引擎负责管理虚拟机器人,每个机器人实例引擎包含一个到多个机器人实例。机器人实例管理引擎架构如图2。
系统启动后,机器人实例管理引擎,根据系统配置的机器人类型,启动机器人实例;在系统配置中,为每一个主题配置一个机器人,机器实例的名称为:“XX主题机器人实例”,用户第一次交互问答时,机器人实例引擎的请求分发组件,分析用户问答语义,为该用户自动分配一个机器人实例,如果请求分发组件不能识别出主题,则列出相关的主题由用户选择,“会话记录管理”组件管理所有的活动的会话记录,记录当前用户和机器人实例的映射和问答交互历史;当用户第二次提交问题时,“请求分发组件”直接将用户的交互信息提交给该主题的机器人实例。
在系统实现上,在Master/Slave线程模型进行扩展,提出Master/Dispatch/Worker的线程模型,Master线程职责保持不变为请求接收线程,接收到请求后分发给Dispatch线程,该线程基于线程池Dispathc Pool,负责识别请求中的主题,将请求按照主题分发给主题机器人线程,机器人线程。1)调用语义识别引擎进行语义识别[6];2)生成SQL语法树,构造SQL;3)委托SQL执行引擎查询数据;4)返回結果。
2.3 基于原生云的技术架构
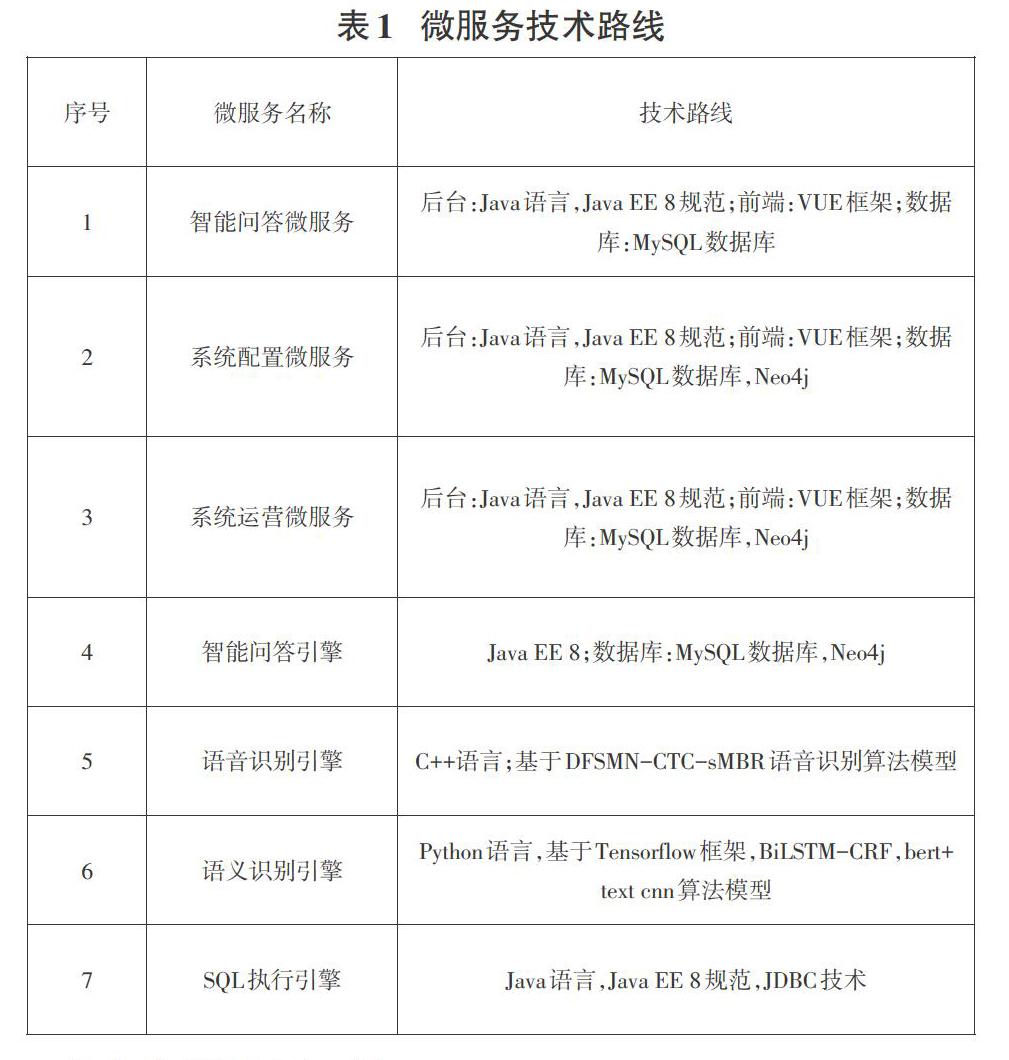
系统实现采用云架构,即系统由多个微服务构成,每个微服务独立的部署在docker容器中,保证了系统易发布、易部署,具有高可靠性和高峰阶段的弹性伸缩提供高性能[7]。在NL2SQL智能查询系统中,基于微服务架构,不同的功能采用了不同的技术栈,均封装为独立的微服务,见表1。
3 业务主题模型设计
NL2SQL智能查询系统在系统应用中,涉及多个业务领域,比如:物资、规划、营销、财务等,按照业务分主题,业务域或者问题业务范围为主题,比如:财务主题、销售年度月报主题等;每个主题关联主题词库、词典库、业务指标配置信息、业务数据库的数据源定义和智能报表模型。
主题词词库:包括该主题域特定的主题词,通过主题词标识一个业务主题,语义识别时主题来确定业务域;每个用户、部门设置默认主题。词典包括:分词词典、近义词词典和特殊词词典;特殊词词典是指该领域有固有含义的词。 业务指标配置包括:指标定义、维度定义、计算公司、数据表和表间关系。
4 NL2SQL引擎关键技术实现方法
NL2SQL智能查询系统属于人工智能类的业务应用系统。本文采用基于知识图谱技术提供对主题业务数据的自动化训练和对多表关联的SQL脚本的生成。
4.1 基于业务数据库表元数据的模型预训练
在NL2SL智能查询系统运行之前,需要针对具体的业务表进行预训练,训练的目标为语言模型能够识别业务表中的表名和字段名[8]。在业务系统的建设中,对于表和字段的说明以注释的形式存在数据库中,本次的目标就是1)识别表名、列名;2)通过对注释分析建立实体和表名和列名的实体链接;3)识别表之间的关系;4)根据注释生成NL2SQL训练集。
识别过程包括三个阶段:第一阶段,识别表名、列名,建立训练集;第二阶段,通过外接识别实体(表)之间的关系,建立表关联的训练集;第三阶段,将识别出的实体、属性导入图数据库,根据图数据库表、列的关系,生成NL2SQL的训练集。过程如图3。
第一阶段将结构化数据库表、表字段等注释作为中文文本语料,通过专业词典和近义词等词库,对文本语料做中文分词,提取并构建特征向量,通过模型训练自动识别实体和实体关系,对于数据源涉及的具有相同标识的实体进行记录,人工参与实现实体对齐和共指消歧,实现同一实体的融合;将识别出的实体和关系导入到专业词典库中。
在第二阶段通过实体的主键和外键的自动识别与匹配,结合主外键的注释,识别表之间的关系,将关系实体导入专业词典,同时建立表关联的训练样本集合测试样本集[9]。
4.2 基于知识图谱的多表关联SQL生成设计
在实际的业务场景中,存在多种多样的数据指标及维度相关的查询,为满足复杂的业务场景需求,采用基于知识图谱的子图匹配算法,对指标定义、事实表以及指标对应的维度进行灵活的子图配置,通过SQL生成引擎,最终生成目标查询的SQL语句[10]。图6是基于图技术的多表关联设计的查询执行过程。
多表关联SQL的生成,基于子图查询技术,首先对数据库表进行知识图谱的建模[11],本体(节点)要求包括:1)一个关系表对应一个节点;2)一个查询目标对应一个节点;3)一个查询条件定义一个节点;4)聚合函数对应一个节点;关系(边)定义为:条件、目标、包含关系等[12]。
5 系统运行及验证
系统预训练阶段,将目标数据库的表名、列名作为实体,实体分为:表实体、指标实体和维度实体,生成知识图谱[14],导入到数据库中,见图4。
其次,用户提出问题,语义识别模型度问题进行预测,预测槽位包括“Select $G1,$G2 From $T2 ,$T1 Where $C1=$V1 and $C2=$V2”,表实体为$T1、$T2,指标实体为$G1,$G2,维度实体为$C1,$C2,$V1、$V2。在上图中,售电量代表的是一个指标,它拥有自己的属性,公司、年度代表的是维度实体,CW_SDL代表的是事实表实体[15]。
系统针对问题“2019年6月北京市售电量和利润总额”给出的答案包括两个部分:1)直接答案:将SQL模型查询的数值结果与问句进行封装,给出问题的直接答案,即文本型答案:2019年6月,机构:北京,售电量:51,880.82万千瓦时,利润总额: 359.1亿元 ;2)关联答案:根据SQL查询模型的条件表达式即维度实体进行查询,展示与用户提问问题关联维度的答案,即图表答案。
问答系统一般以用户为导向,从答案角度评价其性能,因此需要构建问题+正确答案的测试集对系统进行测试,将问答系统给出的结果与测试集中的标准答案进行比对,从而判断其答案的正确性。为了测试系统运行的实际效果,准备了两个业务主题域的数据进行测试集的构建。分别为经营主题数据和疫情主题数据,经营主题数据测试用例为400个,疫情主题数据测试用例为112个。使用共计512个用例对系统进行交叉测试验证,测试样例如表2所示。
实验采用实例召回率(IR)、实例准确率(IP)和F-Measure(IF)对问答系统进行评测,测试的结果为实例召回率91.21%,实例准确率95.70%,F-Measure(IF)93.10%。测试错误的用例主要出现在类似“2019年北京平均电价”这种类型的问题,由于“平均”本身是个聚合函数,而“平均电价”是经营主题域中的一个指标类型,问答系统在解析的过程中难以区分实际的业务场景,需要进一步根据实际业务场景确定问答系统解析的规则,使该类问题进行正确解析。
6 结论
基于NL2SQL技术的智能语音查询系统,总体技术路线采用原生云技术,其核心智能问答引擎采用虚拟机器人架构,每个主题机器人实例采用Master/Dispatch/Worker的线程模型,满足了系统并发性、可靠性的要求;通过基于知识图谱技术的预训练模型,解决系统启动前人工训练工作量的问题;通过基于图技术,解决了SQL生成时的多表关联问题,并构建测试集对系统实际运行的效果进行测试,实例准确率可达95.70%,能够达到实际业务场景应用的需求。
参考文献:
[1] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008: 122-129.
[2] Douglas Schmidt, Michael Stal, Hans Rohnert,等. 面向模式的软件架构 卷2[M].北京: 人民邮电出版社, 2014: 253-344.
[3] 刘译璟,徐林杰,代其锋.基于自然语言处理和深度学习的NL2SQL技术及其在BI增强分析中的应用[J].中国信息化,2019(11):62-67.
[4] 孟明明,张坤,论兵,等.一种面向知识图谱问答的语义查询扩展方法[J].计算机工程,2019,45(9):276-283,290.
[5] 吳谋硕. 问答式信息检索查询优化技术研究[J]. 信息与电脑(理论版), 2014(11): 38.
[6] 关胜, 罗一鸣. 基于多级图的自适应智能客服算法框架研究[J]. 计算机产品与流通, 2020(8): 221.
[7] 佘维,杨晓宇,田钊,等. 基于用户偏好的电力资源去中心化配置方法[D].哈尔滨: 哈尔滨工业大学, 2014: 16-18.
[8] 杨梦琴.语义驱动的数据查询与智能可视化研究[D].重庆:重庆大学,2018:7-9.
[9] 李兆兆.基于语义理解的智能问答系统关键技术研究[D].西安:西安邮电大学,2019:7-9.
[10] 黄魏龙.基于深度学习的医药知识图谱问答系统构建研究[D].武汉:华中科技大学,2019:18-22.
[11] 张心洁,王建.基于语义分析的D5000遥信信息生成与校核方法[J].中国电力,2019,52(5):134-141.
[12] 王凤林.受限域问答式自然语言数据库查询研究[D].昆明:昆明理工大学,2010:11-14.
[13] 张涛,贾真,李天瑞,等.基于知识库的开放领域问答系统[J].智能系统学报,2018,13(4):557-563.
[14] 王瑛, 何启涛. 智能问答系统研究[J]. 电子技术与软件工程, 2019(5): 174-175.
[15] 李舟军,李水华.基于Web的问答系统综述[J].计算机科学,2017,44(6):1-7,42.
【通联编辑:唐一东】
