在医疗保险信息化建设中应用大数据分析的研究
2020-06-06王为光
王为光
(苏州工业园区社会保险基金和公积金管理中心,江苏 苏州 215000)
0 引言
随着信息技术的发展,大数据已经成为新时代的热点,并被给予“未来新石油”的评价[1-3]。对大数据的开发利用已成为国际竞争及国家整体实力的重要体现,世界各国先后制定和实施了大数据相关的战略计划,我国于2015年提出了大数据发展战略[4-6],随着信息技术的迅速发展,基于大数据技术的数据开发利用已经成为各个行业在市场竞争中的重要因素,甚至成为国家整体实力的重要体现。在医疗领域仍旧如此,各区域医疗保险信息系统内存在着大量的数据,这些庞大的医疗保险数据在不经过梳理、分析、再整理、重构等处理的情况下,很难直接用于医保管理,加大医保工作人员的工作量,造成很大的资源浪费[7-10]。依据国家“大数据”发展战略要求,利用大数据对医保基金进行风险防控已经成为目前科技发展的重点,通过将大数据分析技术应用到医疗保险行业,能够有效降低医保基金运行风险,有利于解决医保险欺诈、过度医疗等问题,最终实现医保基金的可持续发展[5,11-12]。
因此, 如何利用好这些医保大数据、探究大数据在医疗保险信息化建设中的应用具有十分重要的意义[13-14]。本研究以苏州工业园区医疗保险特病结算数据为基础,对数据进行梳理、分析、清洗、重构,运用系统建模大数据技术,利用预测模型、数理模型进行数学建模,分析影响特病支出费用的发展趋势以及影响支出的关键因素,提高了数据的处理能力。
1 大数据应用方案设计
本研究通过以文苏州工业园区社会保险基金和公积金管理中心(以下简称“中心”)医疗保险特病支出数据为基础,对大数据的应用进行说明、分析借助于大数据分析挖掘技术助力医保平台特病数据监控与费用控制,为医保基金的可持续发展及医疗保险政策的制定、执行、完善提供依据。如图1所示。

图1 大数据应用框架结构示意图
在本研究设计中,其总体思路是:选择园区的12种特病样本数据,该疾病为尿毒症、白内障、再生障碍性贫血、血友病、恶性肿瘤康复期、冠心病合并心肌梗死、癫痫、强直性脊柱炎、系统性红斑狼疮、类风湿性关节炎、恶性肿瘤放化疗、重症精神病等。首先将这些数据进行梳理、分析、清洗等处理,再利用大数据分析模型,进行数学建模,根据限额、限额以内的报销比例,超限额报销比例,申请人数四个影响维度,调整数理模型参数,对下一年度的特病支出费用做出预测。
通常,医疗保险信息化平台为分为不同层次的几个平台,比如数据库、数据存储平台、大数据计算、处理平台、业务应用平台、展示层等。医疗大数据被存储在数据库中,在信息化平台中,数据存储中心为基于Hadoop平台的大型Hbase数据库,hadoop分布式大数据平台能够提供数据提取、存储和计算服务,其具有结构化的数据和非结构化的数据,非结构化的数据被存储在Hadoop平台中的HDFS文件系统中。在Hadoop平台中的各种大数据可以实现分布式存储、超融合VS分布式、删重和压缩以及整合分析等功能。
在数据计算之前通常要进行数据预处理,数据预处理主要包含数据梳理、数据抽取、数据清洗、数据转换和数据简约等。在进行数据处理中,对已有的数据资源进行梳理,确定需要的有效的业务数据范围,从核心业务数据库oracle中抽取需要的原始目标业务数据,然后对原始数据在抽取时进行第一次数据粗清洗工作,清洗后的数据存入大数据平台的hive数据仓库中,然后对hive仓库中的数据进行二次清洗,形成满足要求的有效的高质量数据,二次清理后的数据存放在hive数据库中,对第一次存储的数据进行清除整理。数据清理之后,采用数据挖掘算法或者随机矩阵模型对清洗后的数据进行计算、处理,然后通过展示页面向用户显示数据。
2 关键技术设计
2.1 大数据处理技术
在诸如尿毒症、白内障、再生障碍性贫血、血友病、恶性肿瘤康复期、冠心病合并心肌梗死、癫痫、强直性脊柱炎等多种医疗数据被输入到信息化平台时,需要对大数据进行预处理,在本研究设计中,采用移动平均模型(MA)或者指数平滑模型进行数据处理。
移动平均(MovingAverage)就是使用前N期的历史数据进行序列的预测,即把前N期的历史数据的平均值作为下一期的预测值,其基本原理是通过消除时间序列中的周期变动和不规则波动的影响,以便呈现出时间序列的总体发展趋势(即趋势线),然后根据趋势线分析序列的长期趋势,其原理示意图如图2所示。
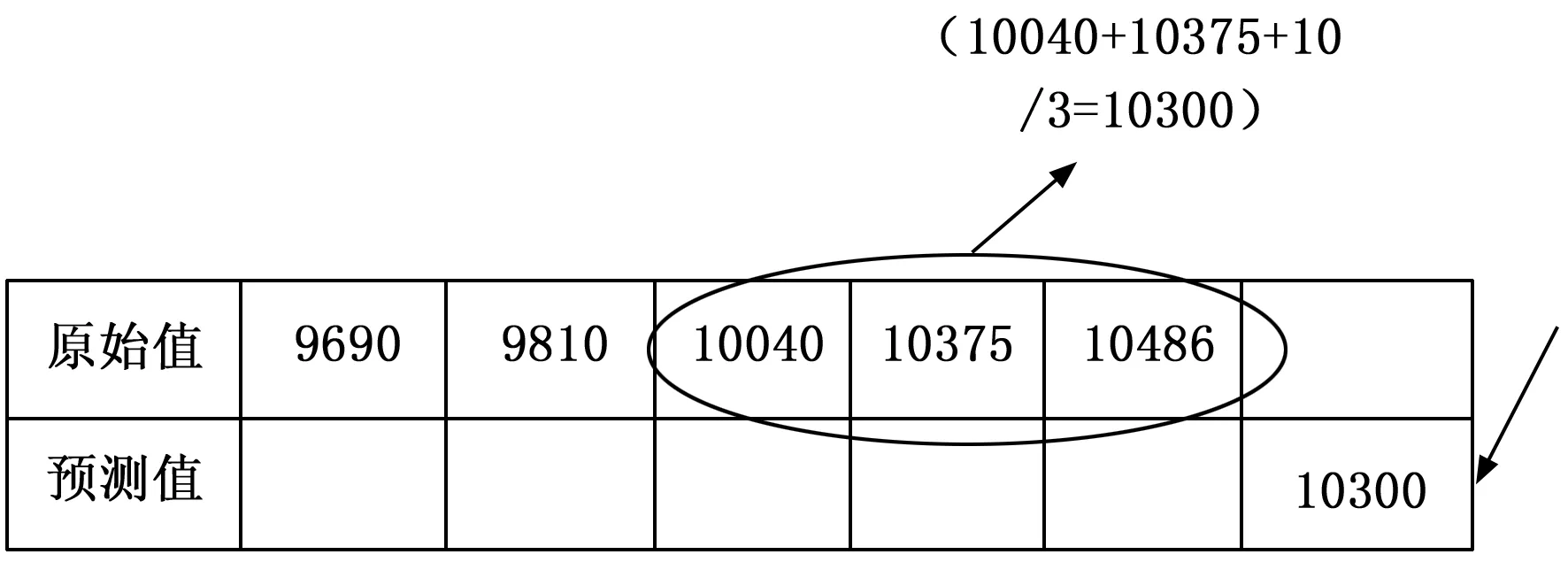
图2 移动平均大数据预处理原理示意图
上述为一次移动平均计算值,利用上述理论的效果如图3所示。

图3 移动平均大数据预处理效果示意图
通过该方法,可操作性、解释性比较强,易于工程化的实现,移动平均法能够有效地消除预测中的随机噪声。
在使用指数平滑模型时,指数平均(exponential smoothing,也叫exponential weighted moving average),这种平均方法的重要特征就是,Yt与之前产生的所有信号有关,并且距离越近的信号所占权重越大。根据所选时间特征分为如下类型:一阶指数平滑、二阶指数平滑、Holt-Winters指数平滑模型等,采用该模型优点:精度较高,易于工程化的实施,python,R均有相关包实现,调用接口简单易用,由数据异常导致的报错较少。
2.2 数据处理方法
2.2.1 随机矩阵理论处理方法
随机矩阵理论是通过统计、分析医疗数据的能谱和本征态,得出实际测量中的随机程度,进而揭示不同医疗实际数据所蕴含的整体关联的事件特征。下面构建随机矩阵理论模型对医疗数据的相关性进行计算。
假设医疗保险相关性评估矩阵模型为:

(1)
其中:
(2)
(3)
在上式中,对人体的健康造成重大伤害的疾病(诸如尿毒症、白内障、再生障碍性贫血、血友病、恶性肿瘤康复期、冠心病合并心肌梗死、癫痫、强直性脊柱炎等)有M种,数据集合为:{P1,P2,P3……PM},人体疾病的数据有N种,数据集合为:{Q1,Q2,Q3……QN}, 在评估时间窗区间范围内,连续测试T次,其中将对人体健康造成重大伤害的影响的数据构建为矩阵D1,其中集合数据元素Pij为第i个疾病在j疾病等级下进行测量的疾病大数据。
在运算中,为了统一计算的方便,对评估矩阵模型D进行标准化。标准化公式为:
(4)
定义xi=(xi1,xi2,xi3……xiT), 假设标准化后的矩阵为D3,则D3=(yij)(M+N)*T,其中:
μ(yi)=0
(5)
σ2(yi)=1
(6)
其中:yi=(yi1,yi2,yi3……yiT)T, 1≤i≤M+N。
再次引入公式:
式(7)
其中:
Dstd=[w1,w1,w1……wM+N]T
(8)
该公式的运算过程为基于标准化后的矩阵D3而进行的,由于D3矩阵在计算中为非Hermitian矩阵,该矩阵的奇异值等同矩阵为:
(9)
在式(8)中,U为Haar酉矩阵,在运算中容易出现多个矩阵,假设有N个任意的非标准Hermitian矩阵D3,则存在N个奇异值等同矩阵。为了计算方便,按1个奇异值计算,这时Du可以表示为:
(10)
基于上述模型的建立,将上述建立的数据模型应用到引起人体疾病影响因素的评估上,观察人体中隐藏的外在参数对人体健康影响情况。在本研究设计的方案中,忽略数据输入的步骤,直接从医疗保险信息化平台中的数据存储中心中提取数据,然后进行下一步的操作。即按照标准化后的标准化公式(见式4)来计算,根据式(9)求出奇异值等同矩阵,根据式(10)求出奇异值计算,最后根据式(8)求出Dstd的值。公式在此不做重复描述,根据上文列出的公式,分别输入采样数据,求出各个公式的值。
然后利用随机矩阵模型分析大数据,当计算出标准化矩阵积Dstd的特征值分布时,便可评估疾病对人体健康造成的影响,Dstd越大,影响量越大。由于D1表示的医疗疾病数据集合为严重影响人体健康,数据集合{P1,P2,P3……PM}中表示不同的参数,造成人体健康重大疾病的数据集合为{Q1,Q2,Q3……QN}中也表示不同的集合,因此在实际应用时,根据选择数据类型而构建矩阵。
2.2.2 数据挖掘算法模型
在对大数据进行处理时,首先将数据按照一定的属性分类,本研究基于数据挖掘算法实现智能大数据的分类。数据挖掘算法包含很多种算法,比如关联算法、回归分析、聚类算法、异常检测等,其中每种算法又包括多个算法,比如分类算法包括诸如决策树算法、贝叶斯算法、神经网络、支持向量机等算法,聚类分析算法包括诸如k-means SOM神经网络、FCM聚类算法等的算法。在本研究设计中,选择使用决策树算法中的ID3算法构建决策树,实现对数据的分类。
假设表1为给定的数据集为D,根据最大信息增益选择最优特征生成极小熵决策树,计算各特征A1、A2、A3、A4、A5对数据D的信息增益,如表1所示。表1中的D1和D2,D3分别表示在各个特征中取值为1、2和3的样本子集,根据上文涉及的公式计算统计在表1中的数据可得:
H(D)=-8/15*log2(8/15)—7/15*log2(7/15)=0.996 8;
g(D,A1)=H(D)-[8/15*H(D1)+7/15*H(D2)]=0.288 0;
g(D,A2)=H(D)-[5/15*H(D1)+4/15*H(D2)+6/15*H(D3)]=0.139 8;
g(D,A3)=H(D)-[3/15*H(D1)+12/15*H(D2)]=0.029 2;
g(D,A4)=H(D)-[7/15*H(D1)+8/15*H(D2)]=0.288 0;
g(D,A5)=H(D)-[6/15*H(D1)+4/15*H(D2)+5/15*H(D3)]=0.413 1;
根据上面的计算结果,特征A5的信息增益最大,所以选择A5为根节点。根据A5的取值将样本分成3个结合,S1={2,3,6,8,12,13},S2={1,5,7,14},S3={4,9,10,11,15},其中集合S2已全部属于同一个类,不需要再分,已成为叶子节点。采用类似的方法可确定其它根节点和叶子节点。

表1 样本数据
利用上述数据集构建决策树如图4所示。

图4 决策树示意图
通过数据挖掘算法建立分类模型,使得多个不同类型的医疗保险数据库根据用户需求输出不同的目标数据,缩短用户利用数据的时间,提高了数据处理效率。
3 方案实验及分析
本研究选择了苏州工业园区2012年度至2017年度医疗保险特病参保人员医疗结算数据作为研究对象,涉及12个病种,约5万人员,1 400万人次的结算数据。包括了特病人员的基本信息、就医结算信息等。选取的数据样本为12种特病分别为尿毒症、白内障、再生障碍性贫血、血友病、恶性肿瘤康复期、冠心病合并心肌梗死、癫痫、强直性脊柱炎、系统性红斑狼疮、类风湿性关节炎、恶性肿瘤放化疗、重症精神病。在试验时,将上述数据输入到基于Matpower的IEEE-118节点的仿真系统系统中,假设矩阵D1=80*150,D2=400*500,根据公式Dstd=[w1,w1,w1……wM+N]T进行计算,其中D1分别为癫痫、强直性脊柱炎、系统性红斑狼疮等疾病数据构成的矩阵。在实施例时间,D1构成5个矩阵,D2为影响人体健康的参数,其数据样本见表2所示。

表2 数据试验表
在该步骤中,主要将处理后的医疗数据输入到建立好的数据模型中,输出用户需要的数据。对处理后的数据进行T次采样,构建状态数据矩阵。即构建以下数据以数值的方式表示,比如将:
转换成:
同时将:
转换成:
由于矩阵的规模和篇幅的限制,在此仅仅做示例性说明,不再将矩阵按其真实规模展开。根据上述数据,应用上文提供的公式,将计算结果绘成曲线图,如下文所述。
在图5中,以尿毒症对人体因素造成重大影响程度进行分析、判断,其影响的曲线图如图5所示。
在图6中,以白内障对人体因素造成重大影响程度进行分析、判断,其影响的曲线图如图6所示。
在图7中,以尿毒症对人体因素造成重大影响程度进行分析、判断,其影响的曲线图如图7所示。
在图8中,以恶性肿瘤对人体因素造成重大影响程度进行分析、判断,其影响的曲线图如图8所示。

图5 影响人体病理参数为尿毒症的曲线图 图6 影响人体病理参数为白内障的曲线图

图7 影响人体病理参数为血友病的曲线图 图8 影响人体病理参数为恶性肿瘤的曲线图
因此,通过随机矩阵理论都可以逼真地获取医疗数据。通过随机矩阵理论也可以对医疗数据进行关联性评估。通过上述试验,随机矩阵理论在医疗保险信息化平台大数据处理方面具有明显的直观显示。
4 结束语
本研究通过在医疗保险信息化建设平台中使用大数据处理算法,不仅有利于用户从各种不同的数据库中找到合适的最佳数据,也将极大地影响医疗保险基金的收支平衡和可持续发展,大数据技术还可以辅助相关决策的制定,比如参保险群体分析、参保对象年龄分析、医保基金收支分析、大病费用补助分析,有效降低医疗保险基金风险。大数据技术对医疗保险管理具有决策支持、便民服务、风险管控、商保拓展等重要意义。
