基于RFID的围术期术后康复行为检测
2020-06-06魏大顺张德林董瑞国
魏大顺,张德林,董瑞国
(1.徐州医科大学 医学信息学院,江苏 徐州 221000;2.徐州医科大学附属医院,江苏 徐州 221000)
0 引言
由于医疗报销等问题,在围术期过程中医生要控制、缩短平均住院日,术后如果没有较严重并发症,一般要求病人尽快出院;但是患者又担心康复不彻底;而国家又没有相关的出院技术标准,因此在患者各项生理指标正常的情况下,我们提出一种以病人术后活动指标作为一种检测是否可以出院的方法。通过患者腕带标签,局域网内的接收器检测这些标签,并向位置软体传递即时位置状态等资料,具体如图1所示。FP-growth作为一种有效的关联规则挖掘算法已经被用于许多领域,许多学者也针对不同的应用场景或者算法本身进行了许多改进。如基于节点表的FP-growth算法改进[1]、基于FP-tree的快速构建算法[2]和无项头的FP-growth[3]算法。但在医疗应用场景下这些算法都很难发挥他们的优势,特别是在处理RFID所产生的事务数据,这主要是由于其高维度性、高无用性、高冗余性等特性导致[4]。例如基于节点表的FP-growth算法通过新增的节点表和频繁模式树两者中共通的项,从而进行频繁项集挖掘,然而当数据维度越高,两者中共通的项则越多,挖掘效率因此也就越低下;基于FP-growth的快速构建算法通过动态调整各项的顺序从而减少数据库访问频度,但是医疗数据具有高无用性以及高冗余性,因此若利用此方法处理医疗数据将会消耗大量的内存;无项头的FP-growth算法虽然可以精简生成的关联规则,但是生成的关联规则中依然还会存在大量的冗余规则。在实际应用场景中,医疗人员更多的是希望在他们已有的专业判断下,进一步从某些关键因素进行确认患者是否达到出院标准,比如患者在术后的行动时间与行动距离是否存在关联性、活动范围与术后时间是否存在关联性。若使用原始FP-growth或者目前已有的改进算法去解决这一需求,不仅无法针对性的进行关联挖掘,而且会找出许多无用的关联规则[5],而这必然会严重影响挖掘效率,降低挖掘质量。本文针对此种应用场景,以胸外科数据为作为实验数据,提出了一种改进的FP-growth算法。该算法首先通过计算数据集中各属性的条件信息熵[6]进行约减;创建FP-Tree,根据判断分支中是否含有决策项以及项重要度大小进行相应的剪枝。该算法从整体上缩减了事务数据库的规模,对FP-tree进行了横向和纵向剪枝压缩,从而简化了最终频繁项集的挖掘,提高了挖掘效率,降低了算法运行所需内存与CPU。实验结果表明,本文改进方法在可接受的精度范围内,挖掘效率高于已有主要挖掘算法。
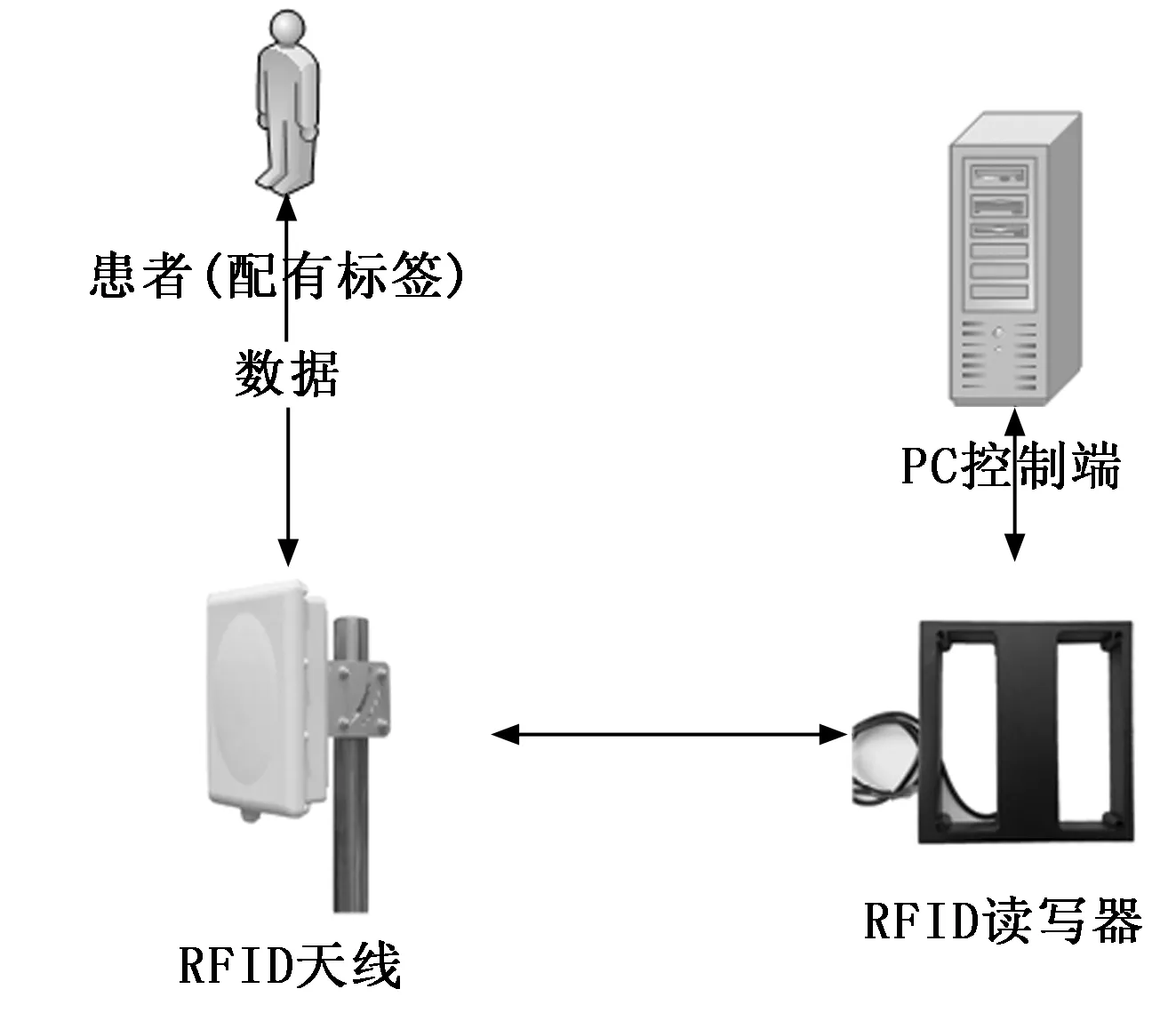
图1 患者活动RFID射频识别
1 基础知识
本节介绍本文所需的基本知识,主要是RFID以及FP-growth算法。
1.1 基本定义
定义1:RFID,无线射频识别即射频识别技术(radio frequency identification,RFID),是自动识别技术的一种,通过无线射频方式进行非接触双向数据通信,利用无线射频方式对记录媒体(电子标签或射频卡)进行读写,从而达到识别目标和数据交换的目的。
定义2:FP-growth,FP-Growth算法采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。
定义3:支持度,确定规则可以用于给定数据集的频繁程度,公式如下:
(1)
其中:N是事务的总数,X,Y为对应的属性。
1.2 FP-gowth算法流程
输入:事务数据库(transaction database,TD);最小支持度(minimum support,MinSup)[2]。
输出:频繁模式的完全集。
1)对TD中的事务进行逐条遍历,统计每项支持度,并且以集合F表示,并且按照支持度大小重新排列,最终得到频繁项表L。
2)再一次对数据库TD进行扫描,按照L中的顺序对TD进行重新排序,得到TD′;
3)创建频繁挖掘树FP-tree,其中根节点为root,默认值为空,将步骤2)得到的TD'中的数据按照顺序插入FP-tree中,若数据节点第一次在FP-tree中出现,则新建节点,并计数1,若待插入的节点已经存在于FP-tree中,则原计数加1,同时令项头表为步骤1)中得到的L,且链头为项头,连接内容相同的项;
4)对项集L中的项逆序挖掘频繁项集。
2 对FP-growth算法的改进
FP-growth算法在处理事务库时无法对无用属性的筛选以及对特定关联的挖掘,从而导致挖掘速度缓慢以及影响挖掘质量。因此,本文提出了一种改进的验证式挖掘算法—IEFP-growth(Information Entropy FP-growth)算法。通过对FP-growth挖掘前的属性约减和FP-tree创建过程中的剪枝来进行优化。该算法首先通过计算数据集中各属性的条件信息熵[7]进行约减;在原算法扫描数据库生成频繁一项集的基础上,创建FP-Tree,根据判断分支中是否含有决策项以及项重要度IT(Item importance)大小进行相应的剪枝,若不含决策项则进行剪枝,若含决策项且所在分支中含有项重要度大于重要度阈值的项则保留,否则进行剪枝。该算法首先从整体上缩减了事务数据库的规模,其次对FP-tree进行了横向压缩,进而提高了整体挖掘速度与质量。
剪枝依据性质:
1)支持度大的项并不一定和决策项具有关联;
2)支持度大于MinSup且重要度大于或等于IT的项一定和决策项具有一定程度的关联。
2.1 IEFP-growth的算法流程
输入:TD;MinSup;IT。
输出:含决策属性的频繁模式集
1)对TD-事务数据库进行属性约减得到TD′;
(1)计算TD中除决策属性[8]外每个属性相对于决策属性的条件信息熵,例如D相对于C的:

(2)
其中:D是决策属性,C是条件属性,U为论域,Xi,Yj分别是某一属性的属性集合。
(2)计算条件属性集C中相对于决策属性集D的主属性Cr,并令P=Cr,B=C-Cr;
(3)计算条件信息熵H(D|P),转步骤(6);
(4)对i=1…n,bi∈B中的每个属性计算条件熵H(D|P∪bi),求:
SGF(bi,P,D)=H(D│P)-H(D|P∪bi)
(3)
得到属性bi相对于决策属性的重要度SGF;
(5)找出属性bi,该bi可以让SGF取得最大值,然后在P的后面追加bi,并且去掉使SGF为0的bi;
(6)如果H(D|P)=H(D|C),则转步骤(7,否则转步骤(4);
(7)依次判断p中每个属性是否可以去掉,判断顺序是从p尾开始,p头结束。假如a在coreC(D)中,则从a往前都不可约,算法结束;否则a是可约减的,于是把a从A中删除。
(8)得到处理之后的TD′
2)第一次扫描TD′,除去小于MinSup的项,得到频繁一项集L;
3)再次遍历TD′,重新排列TD′,排序规则以L中各项的支持度为度量进行降序排序,得到TD″;
4)建立FP-tree根节点,值为null,将TD″中的事务依次插入,若分支中不含决策项则进行剪枝,若含决策项且所在分支中含有项重要度-SGF大于重要度阈值IT的项则保留,否则进行剪枝;若节点不存在,则新建并计数并置1,若节点存在,则计数加1;
5)对创建好的FP-tree进行频繁项集的挖掘。
(1)获取头指针表中每一个元素的条件模式基;
(2)按照步骤1)至步骤4)的建树步骤,对上一步骤获得条件模式基建立条件FP树;
(3)重复以上步骤,获取条件模式基并构建条件FP树,直至无法构建条件FP树为止;
2.2 算法详解
(1)以表1简易患者活动事务数据库-TD为例。
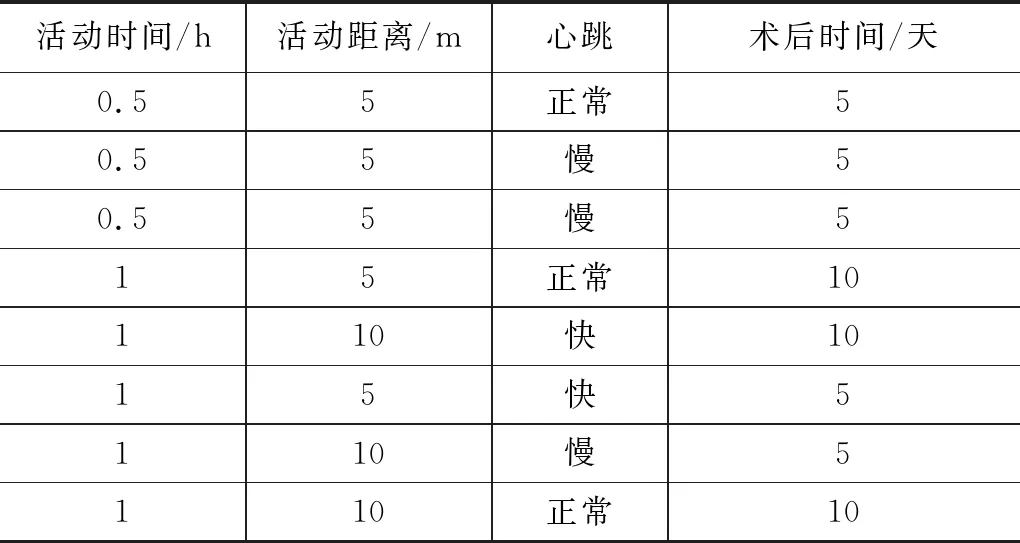
表1 患者活动事务数据库TD
为使得RFID数据信息满足挖掘要求,将活动时间、活动距离等数据以范围表示。
计算各属性重要度SGF:
H(D|C)=0.5
H(D|P)=1
SGF(活动时间,P,D)=H(D|)-H(D|半小时,)=0.049
SGF(心跳,P,D)=H(D|)-H(D|快,)=0
SGF(活动距离P,D)=H(D|)-H(D|5米以内,)=0.311 278
根据属性重要度SGF进行属性约减得到表2。
(2)再次遍历TD′,重新排列TD′,排序规则以L中各项的支持度为度量进行降序排序,得到TD″;
(3)在TD″的基础上生成FP-tree,并且对根节点初始化,其中根节点名称为root,默认值为空。按照频繁树生

表2 约减后数据库TD′
成规则,将TD″中事务逐条压缩到频繁树中。若需验证活动时间与活动距离是否存在关联规则,则待插入的分支中不含有“活动时间”属性,则舍弃该分支,若待插入分支中含有“活动时间”属性且所在分支中含有项重要度大于重要度阈值IT的项则保留,否则进行剪枝;若节点不存在,则新建并计数并置1,若节点已经在FP-tree中出现,则相应的计数加1。
(4)利用项头表和频繁模式树递归挖掘频繁项集。
3 实验与结果
本节通过将IEFP-growth算法与当前效果较好的基于节点表的FP-growth算法以及原始FP-growth算法进行实验对比,对比分析本文所提出的IEFP算法的挖掘效果;最后将挖掘结果与其对应的生理指标进行对比,证明所提方法具有一定的临床可行性。
综上所述,现阶段,我国各大高中学校管理人员已经有效地认知到分层教学模式对于提升学生学习水平的重要性,并且在这种意识的引导下,正在积极开展化学分层教学活动,但是由于起步时间较晚,该种教学模式的教学成效并不显著,因此相关的教职人员必须要将工作重心放到高中化学分层教学模式实施措施的研究上,结合实际情况,制订出具有针对性的措施,以此来实现既定教学目标。
3.1 实验环境
软件环境:pycharm编辑器;硬件环境:Intel(R)Core(TM)i5-7300HQCPU@ 2.50GHz,内存为8G,64位Window10操作系统;
3.2 实验一
随机选取10 000条实验数据,事务数据事务中项的频繁项集支持度大多在0.04%到0.18%之间,分别测试FP-growth、基于节点表优化的FP-growth和IEFP-growth算法在不同支持度下的消耗时间以及经过差分隐私后的IEFP-tree的挖掘时间对比。详细数据内容见表3。

表3 不同算法运行时间对比图
由表3可知,第一列是最小支持度,第二列、第三列和第四列分别是FP-growth算法、基于节点表优化的FP-growth算法和IEFP-growth算法执行时间,并且IEFP-growth在各支持度下的消耗时间都低于FP-growth原始算法和基于节点表的FP-growth算法所需要的时间。
图2绘制了FP-growth、基于节点表的FP-growth算法和IEFP-growth在最小支持度变化下各自挖掘时间的变化及对比情况。

图2 不同算法在不同支持度下的执行时间对比图
由图2可以看出,随着支持度的缩小,IEEP-growth算法相比于FP-growth算法以及基于节点表的FP-growth算法在相同支持度下所需时间更少,且随着支持度的减小,所需时间增长速率缓慢,且支持度范围在0.04~0.08之间,IEEP-growth消耗时间的增长速率明显低于其他两种算法,这表明支持度越小,IEFP-growth比原始FP-Growth、基于节点表的FP-growth挖掘能力越显著。
3.3 实验二
在不同事务量的情况下分别测试FP-growth、基于节点表优化的nodetable-FP-growth和IEFP-growth算法,统计在不同事务量下的内存消耗情况[9]。详细数据见表4。

表4 不同算法所需内存对比
由表4可知,第一列是事务量,第二列、第三列和第四列分别是FP-growth算法、基于节点表的FP-growth算法以及IEFP-growth算法在不同事务量情况下内存利用率占比,并且IEFP-growth算法在各事务量情况下,特别是事务量越大的情况下,所需要的内存相对于其他两种算法都相对较少。
图3绘制了FP-growth算法、基于节点表的FP-growth算法、以及经过差分隐私保护的IEFP-tree算法在不同事务量变化下下各自内存利用率的柱状对比图。
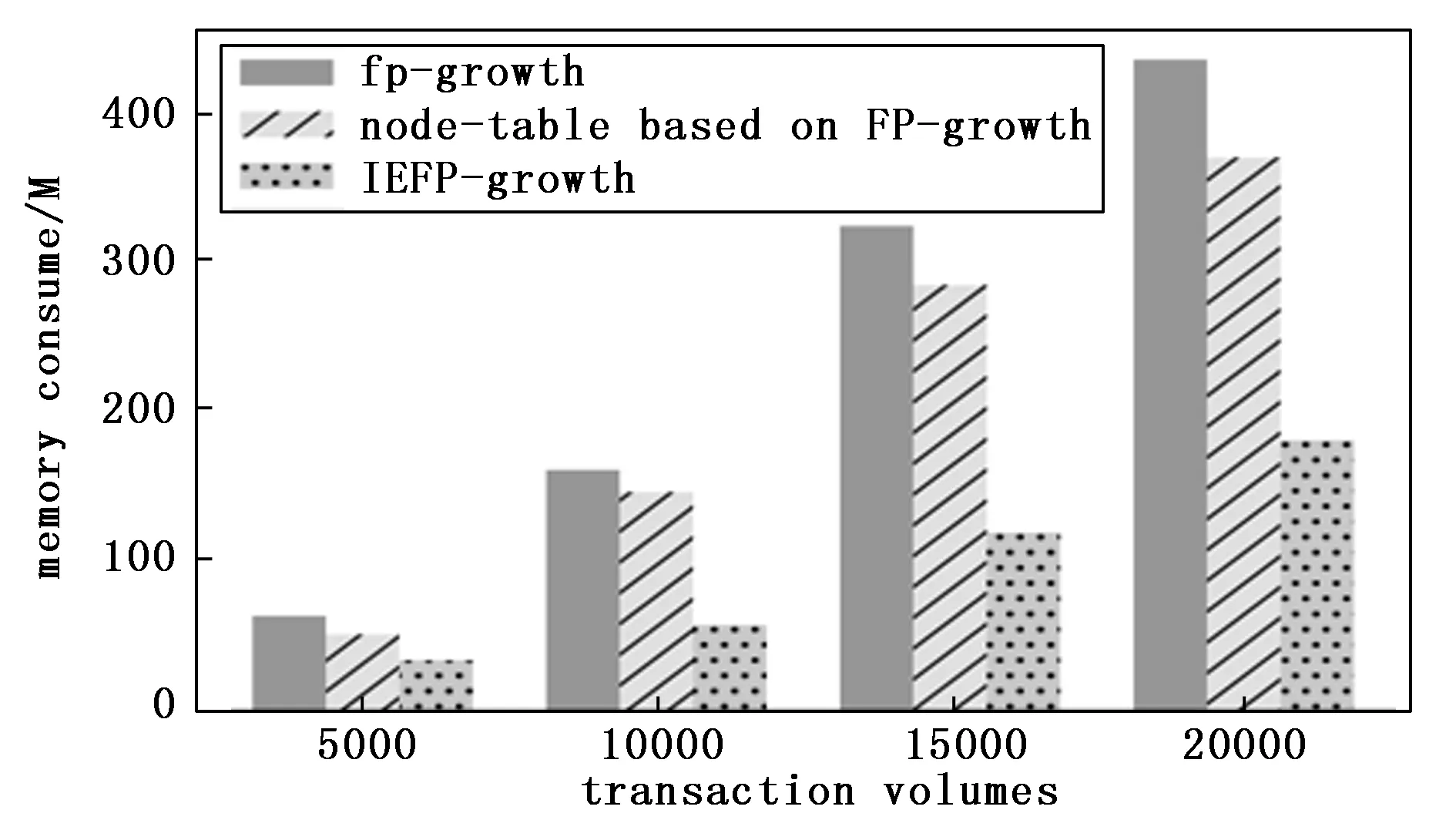
图3 不同算法在不同事务量下所需内存图
3.4 实验三
在不同事务量的情况下进行FP-growth、基于节点表优化的FP-growth、IEFP-growth挖掘,统计在不同事务量情况下的CPU使用情况[10]。详细数据见表5。
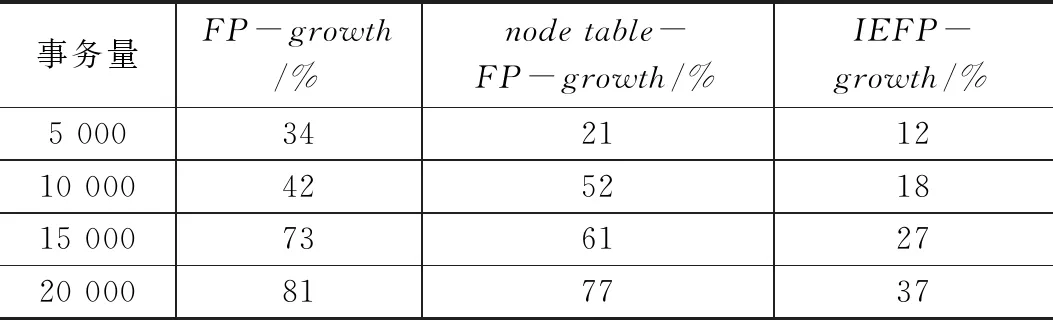
表5 不同算法所需CPU对比
如表5所示,第一列是事务量,第二列、第三列和第四列分别是FP-growth、基于节点表的FP-growth和IEFP-growth算法CPU利用率占比,并且IEFP-growth算法在各事务量情况下,特别是事务量越大的情况下,所需要的CPU相对于其他两种算法都相对较少。
图4绘制了FP-growth、IEFP-growth、基于节点表优化的FP-growth以及经过差分隐私保护的IEFP-tree算法在不同事务量变化下各自CPU利用率的变化。

图4 不同算法CPU变化图
从图4可以看出,IEFP-growth算法所需CPU比FP-growth算法和基于节点表的FP-growth算法所需CPU少,且事务量越大,所需CPU差距越明显。
3.5 实验四
实验选取10 000条事务数据,分别利用FP-growth算法、基于节点表的FP-growth算法以及IEFP-growth算法进行关联规则挖掘,对挖掘得到的频繁模式集分析其中含有决策属性-活动时间的构成比[11],如图5所示。

图5 不同算法挖掘结果中频繁项集构成比图
从图5可以发现,IEFP-growth挖掘得到的频繁项集中决策项占据了绝大部分,其中少部分不是决策属性主要是在剪枝过程中由于重要度以及支持度等因素被减去,也就是说假设的关联关系中存在少部分非关联规则,而由FP-growth和基于节点表的FP-growth算法挖掘得到的频繁项集中与决策属性有关的频繁项只占了很小的一部分。因此IEFP-growth算法可以很好地进行针对性的挖掘,对临床具有一定的价值。
3.6 实验五
为了证明本文所提方法具有一定的临床指导意义,从电子病历系统中提取100位患者阑尾炎患者术后不同时间内白细胞数量平均值,如图6所示,以及术后的活动距离平均值,如图7所示。

图6 术后白细胞变化

图7 术后患者活动距离平均值
从图6我们可以看出在天数为0时即未进行手术情况下,白细胞的数量达到了25 000/L以上,此时病人阑尾已经发生坏死、穿孔等症状,但术后随着时间的推移,白细胞数量逐渐下降,在第6天之后白细胞数量已经趋近于正常水平,且在第八天之后患者办理了出院,因此没有了数据;从图7我们可以看出,患者的活动距离随着术后时间的推移逐步增加,结合图6与图7我们可以发现患者的活动距离与白细胞数量在术后一定时间内具有一定的关联性,而这也符合挖掘结果,因此利用RFID获取的患者活动距离来挖掘数据间的关系并判断是否达康复行为具有一定的临床指导意义。
4 结语
本文通过挖掘RFID采集的患者活动信息数据,为医疗人员提供患者术后出院参考。
针对FP-growth算法在进行频繁模式挖掘过程中,RFID采集的患者数据无关属性过多以及无法进行目的性的挖掘从而引起挖掘效率和质量低下的问题,提出一种验证式挖掘算法——IEFP-growth算法。在对数据库属性约减的基础上,根据判断FP-tree分支中是否含有决策项以及项重要度大小进行相应的横向和纵向剪枝压缩,简化最终频繁项集的挖掘,提高了挖掘效率和质量,降低了算法运行所需内存和CPU。实验结果表明了IEFP-growth算法在时间效率、内存与CPU利用率以及挖掘质量上较传统FP-growth算法都有所改进;并且通过对比分析患者术后白细胞与活动距离的变化趋势,发现白细胞变化与活动距离在一定时间内具有一定的关联,证明该算法在临床检测上具有可行性与实用性[12-18]。
