生物审编组织管理模式及证据源质量控制和评价*
2020-06-03凌鋆超李祯祺张国庆
苏 燕 凌鋆超 李祯祺 张国庆 徐 萍
(中国科学院上海生命科学信息中心/中国科学院上海营养与健康研究所/中国科学院上海生命科学研究院 上海 200031)(中国科学院计算生物学重点实验室/中国科学院马普学会计算生物学伙伴研究所生物医学大数据中心/中国科学院上海营养与健康研究所/中国科学院上海生命科学研究院 上海 200031)中国科学院上海生命科学信息中心/中国科学院上海营养与健康研究所/中国科学院上海生命科学研究院 上海 200031)(中国科学院计算生物学重点实验室/中国科学院马普学会计算生物学伙伴研究所生物医学大数据中心/中国科学院上海营养与健康研究所/中国科学院上海生命科学研究院 上海 200031)(中国科学院上海生命科学信息中心/中国科学院上海营养与健康研究所/中国科学院上海生命科学研究院 上海 200031)
1 引言
随着生物医学研究的飞速发展,生物医学数据呈现指数级增长。如何将海量异构数据收集整理成规范统一、高质量、可高效利用的知识成为亟待解决的问题。生物审编作为提升数据价值的重要方式,已经被国际大型公共和商业生物医学数据库广泛使用。国际生物审编学会将生物审编定义为:将生物相关信息转化集成到数据库或数据资源中,同时整合科学文献和大数据集,准确全面地描述生物知识,便于科研人员获取相关信息以及利用计算机进行数据分析,包括从杂乱数据集中提取和组织生物学和临床数据,录入到一个用户友好的数据库中。生物审编的发展历程,见图1。经审编的数据一方面成为科研人员重要的参考资源,另一方面已被大规模用于文本挖掘或信息学分析,如生物信息学、神经信息学、卫生信息学等[1]。
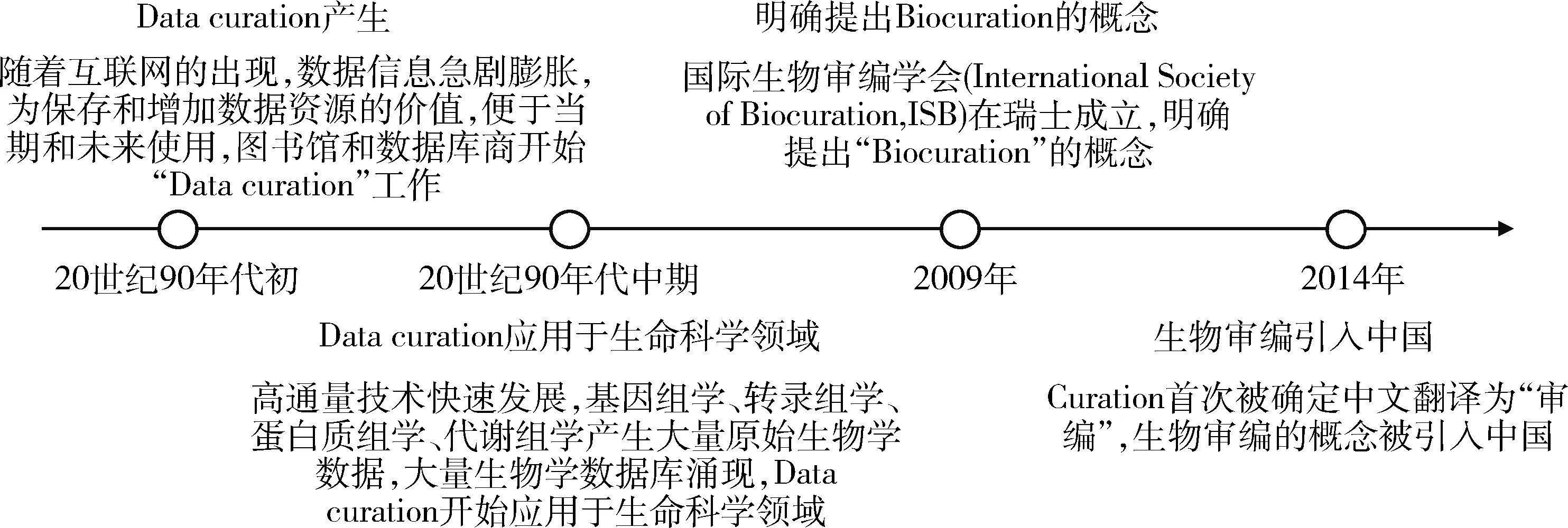
图1 生物审编发展历程
2017年3月欧洲药品监管机构负责人组织(Heads of Medicines Agencies,HMA)和药品管理局(European Medicines Agencies,EMA)成立大数据联合工作组,针对基因组学、蛋白质组学、临床试验等数据的标准化、质量、共享、连接、分析、监管等提出建议。2018年6月美国国立卫生研究院(National Institutes of Health,NIH)发布《数据科学战略计划》,旨在对生物医药研究产生的海量数据进行存储和管理并进行标准化建设和数据公开。
2 国内外生物审编工作开展现状
2.1 国际数据库广泛开展
生物审编已在国际大型公共和商业生物医学数据库广泛使用,成为数据/知识抽取和标准化管理重要方式。公共大型生物医学数据库,如美国国立生物技术信息中心(National Center of Biotechnology Information,NCBI)开发的基因变异数据库ClinGen,欧洲生物信息研究所(European Bioinformatics Institute,EBI)开发的蛋白质相互作用数据库IntAct,生物学通路数据库Reactome,生物相关的化学实体数据库ChEBI,基因本体、线虫模式生物数据库WormBase,西班牙国家生物技术中心开发的蛋白质相互作用数据库iHOP等均采用审编方式提升数据附加值。同时经过审编的高质量数据的商业价值已经引起企业关注,如GeneGo、IPA和Pathway Studio等商业数据库通过自然语言处理技术从文档中提取信息和知识,聘请专业人士进行判读,提升数据价值,保证知识的可靠性。但这些商业软件核心数据保密且使用价格昂贵,在生物医学数据方面形成垄断。
2.2 国内刚刚起步
我国在生物审编领域研究几乎处于空白状态,目前仅有中国科学院北京基因组研究所[2]、中国医学科学院医学信息研究所[3]等机构对生物审编进行了探索性研究。随着大数据时代的到来以及我国自主开发意识的增强,国内各类生物医学知识库构建相继开展。尤其是2016年国家开始密集布局重大慢病、精准医学等领域的重点研发计划,依托这些计划搭建国家级生物医学知识库,旨在打破国际垄断,保护数据安全。
3 生物审编工作当前面临的主要挑战与建议
3.1 概述
虽然国际上已研发出PubTator等自动审编工具,在一定程度上提高了生物审编效率[4],但受限于生物知识和文本的复杂性,目前审编工作仍以专业人员人工解读为主。生物审编是一项大体量、高耗时工作[5],需要投入大量的人力和财力资源[6],其开展和持续目前主要面临两方面挑战。一是国际尚无统一、规范的生物审编组织管理模式,以保障审编工作的质量和效率,审编人员的能力素养和个人偏好等因素容易引发审编质量和效率的差异。二是生物审编的数据来源于不同文本,其质量参差不齐,直接影响审编后生成知识的可信度,同时也给其开展造成一定困难。如何解决上述问题,实现审编过程的高质和高效管理成为其开展和持续运行的关键。
3.2 审编组织管理模式
3.2.1 国际 目前尚无统一、规范的生物审编组织管理模式。国际上的数据库建设机构主要采用成立联盟、与协会合作、与期刊合作、开放式群体审编等组织模式,根据自身资源和优势设计适应性管理模式。国内外生物审编组织管理模式,见图2。国际分子交换联盟(International Molecular Exchange,IMEx)成员包括UniProt、IntAct等16家数据库,其审编模式是联盟成员承诺认领数量不等的期刊进行审编。为减少审编人员个体差异造成的审编质量和效率差异,IMEx联盟安排审编人员进行跨库交叉培训,促进不同机构间的审编人员交流,缩小机构以及人员间的审编差异。IMEx联盟编制了面向蛋白质互作审编的IMEx审编规则(IMEx Curation Rules),对证据源、审编字段、更新方式等作了详细规定[7]。线虫模式生物数据库WormBase通过与美国遗传学会(Genetics Society of America,GSA)和达特茅斯期刊服务机构合作获取全文资源,引导作者自行审编。2010年作者反馈率约40%,其中75%的作者进行了较为详细的注释。IBM人工智能系统Watson的审编过程管理中设计了4类职位:团队领导、数据专家、内容审编人员和领域专家。团队领导负责管理和监督Watson审编项目,启动新的任务工作;数据专家负责查找与收集相关符合目的、范围、标准的内容,利用计算机技术进行内容分类;内容审编人员负责指导数据专家收集内容、审编收集的内容、指导领域专家对审编内容进行分类和改进;领域专家利用专业知识对收集的内容进行质量控制,评估内容的有效性、准确性和价值。通路数据库IPA聘请500名博士开展审编工作,通过多轮审编进行质控。
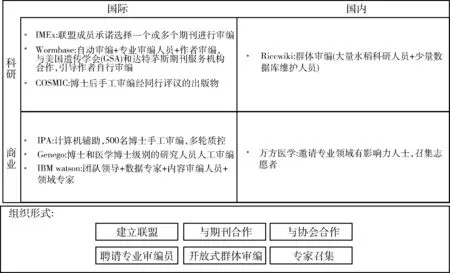
图2 国内外生物审编组织管理模式
3.2.2 国内 中科院北京基因组所开发的RiceWiki数据库采用开放式群体审编的模式。开放式群体审编不同于作者审编和聘用专业审编员审编,其审编员范围广泛,线上协作审编的方式不受时间、地域限制,为审编工作的大规模开展提供可能。但也存在审编员个体差异大以致于审编质量和效率参差不齐的问题。RiceWiki利用AuthorReward评分明确审编人员的贡献程度,该系统从一定程度上对审编人员进行评价但并未从根本上解决人员造成的审编质量和效率差异问题[8]。此外国内的商业数据库也开始尝试通过审编构建知识库,如万方基于其文献资源优势构建万方医学知识库,其组织模式为邀请专业领域内有影响力人士,由其召集志愿者进行审编。国家重点研发计划“疾病研究精准医学知识库”项目设计了基于文本挖掘的自动与人工结合、数量与质量并重的审编模式,见图3。
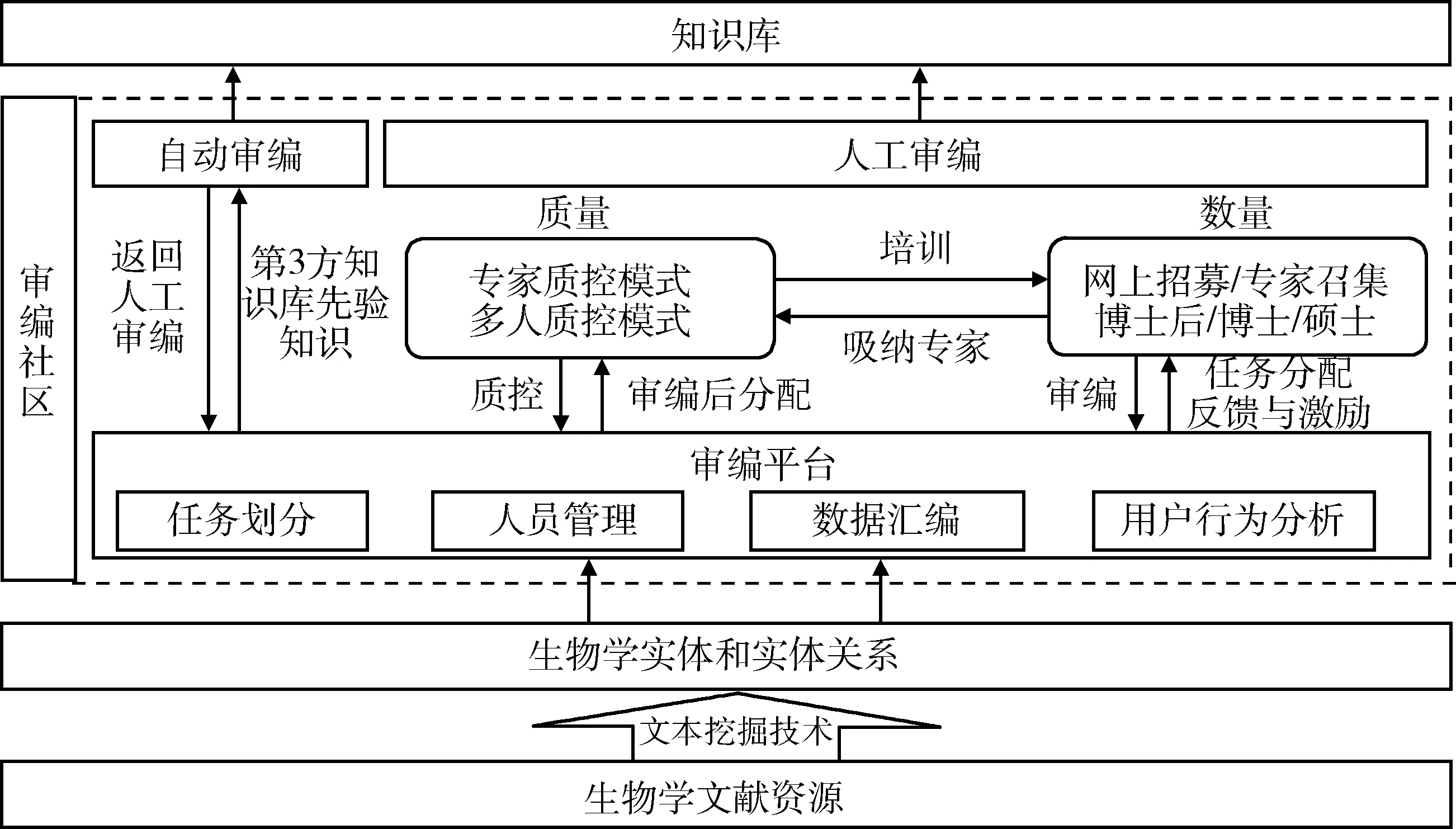
图3 自动与人工结合、数量与质量并重的审编模式
文本挖掘生成的生物学实体和实体关系数据汇集到审编平台,首先比照第3方数据库的先验知识进行自动审编,与第3方数据库匹配的直接输出到知识库,不匹配的返回审编平台进行人工审编。在审编数量控制上采用网上招募或者专家召集博士后、博硕士研究生的模式,保障对审编员数量的需求,同时对审编结果进行一定的反馈和激励。在质量控制上通过专家质控、多人质控模式,不合格的审编条目返回审编平台重新进行任务分配。同时组织专家对审编人员进行线上/线下培训,将审编质量较高的人员吸纳为审编专家。
3.3 证据源质量控制和评价
生物医学领域的文本数量飞速增长,文本中研究结果的可信度不高,低质量的文本往往造成审编信息冗余甚至错误。同时在文本中信息的呈现形式极大影响生物数据的识别和审编速度[9]。生物审编的证据来源于不同文本,其质量参差不齐,从根本上影响了审编后生成知识的可信度。因此一方面需要对证据源加以一定控制,保障基于审编的数据库质量,另一方面需要对审编生成的数据进行可信度评价,帮助数据库用户快速识别入库数据的可信度。目前许多数据库都采取一定措施从证据源角度进行审编质量控制。肿瘤突变信息数据库COSMIC采用经同行评议的出版物为证据源。线虫模式生物数据库WormBase证据源筛选主要依赖审编人员的主观判断,后台系统首先利用Perl脚本在PubMed数据库中对关键词“elegans”进行检索,检索获得的文献再通过人工判读摘要或全文,分析文献信息数量和质量进而决定是否采纳该证据源。WormBase数据库每年审编文献量约1 200篇[10]。此外ClinGen数据库针对提交数据的实验室发布数据质量标准,仅收录满足特定要求的实验室数据[11]。在可信度评价方面ClinGen、CIViC等都已建立证据分级评价模型,为数据库用户提供直观的可信度展示。ClinGen根据试验方法、试验材料、分析方法等因素对证据进行分级[12]。肿瘤基因变异数据库CIViC数据库分别建立证据评级和可信度评级两种评价模式。证据评级赋予共识/指南、临床试验、个案报道、试验模型等证据由高到低的分级,可信度评级则根据期刊影响、研究规模、再现性等因素进行分级[13]。国际分子交换联盟面向蛋白质互作关系设计证据评分模型,利用MIscore工具对审编获得的蛋白之间的相互作用进行可靠性评价,评分因素包括文献数量、实验方法类型和相互作用类型[14]。
3.4 我国发展生物审编相关建议
在审编工作组织管理方面我国已发展一批具有国际影响力的生物医学期刊,包括《细胞研究》(CellResearch)、《分子细胞生物学报》(JournalofMolecularCellBiology)等,发挥政府、学术团体、期刊的联动能力,组织引导作者在投稿过程中共享数据和开展审编是发展我国自有生物医学数据/知识库的直接、有效途径。同时通过重大专项等形式持续支持生物医学数据/知识库建设,招募和培育专业审编人才,规模化开展审编工作是发展我国自有生物医学数据/知识库的必由之路。在审编工作的质量和效率控制方面,利用计算机技术辅助审编已成为提高审编效率的重要方式,应积极推动生物医学本体构建、异构数据整合、文本挖掘等研究,支持和引导国内生物医学信息系统采用统一通用的数据标准,打破数据孤岛,通过自动或半自动审编技术和工具提高审编效率。探索生物审编过程管理机制,制定标准、规范的审编流程,保障生物审编工作的科学开展,推进审编质量和效率的双重提升。
4 结语
生物数据已被视为重要的国家战略资源,美、欧、日等国家在20世纪就已经布局数据的收集、存储、审编和利用,美国NCBI、欧洲EBI等数据中心以及GeneGo、IPA和Pathway Studio等商业数据库已对生物数据形成垄断。近年来我国高度重视生物数据资源的开发和利用,中科院北京基因组研究所生命与健康大数据中心、中科院上海生科院生物医学大数据中心、北科生物国家生物医学大数据产业园等多个生物大数据中心、集群、平台也相继建成。但我国在生物审编方面刚刚起步,生物数据缺乏有效积累与管理,面临严峻的数据资源风险,亟需探索生物审编工作的支持和激励机制,充分挖掘数据资源,打破数据垄断,保障科研、临床对数据资源的需求。
