一种自适应谐波叠加的复调音乐主旋律提取新方法
2020-06-03何甜田何培宇陈杰梅
何甜田, 何培宇, 陈杰梅
(四川大学电子信息学院, 成都 610065)
1 引 言
随着近年来数字音乐产业的不断发展,人们对获取音乐信息的需求也与日俱增.旋律是音乐的灵魂和基础,可以表达出音乐的情感意义.旋律通常是指一个单音的基频序列[1],但是大多数音乐中,同一时刻的声音通常来自多个不同声源,此类音乐称之为复调音乐.主旋律提取的目的就是在复调音乐中自动地判别出主导声源的人声或者器乐的旋律.它可以广泛地应用于哼唱识别、语音合成[2]、内容推荐[3]、制作医疗音乐[4]等.
主旋律提取问题的提出起源于上世纪九十年代,在2004年Goto[5]首次提出了对复调音乐的主旋律提取方法.他提出计算信号的短时幅度谱,并用加权混合模型对其进行建模,然后计算每帧中具有最大期望概率的基频,构成主旋律.Salamon[6]提出了能量映射叠加与构建音高轮廓线的方法,将线性频域转换到了音乐适用的对数域,使得音高提取更加精准.Ono等人[7]提出了一种谐波与击打声源分离算法(Harmonic Percussive Source Separation, HPSS),该算法可以分离在时间上平滑连续的和弦分量和在频率上平滑连续的冲击分量.上述算法虽然各有优点,但大多依赖能量谱的准确性,且无法准确区分人声与伴奏.
因此,本文采用了谐波与击打声源分离作为预处理,将分离后的声源作为输入.自适应改变压缩因子的值,对谐波进行叠加,在达到最小稳定方差时构建显著度函数进行多基频估计,构建基频片段.然后通过对训练集提取声学特征,生成随机森林模型[8].检测人声存在段映射到基频片段上,选取显著度最大频率作为主旋律.实验结果表明,在高信噪比情况下整体准确率有显著提升.
2 相关乐理基础介绍
2.1 基频与谐波
一般的声音都是由发音体发出的一系列频率、振幅各不相同的振动复合而成的.这些振动中有一个频率最低的振动,由它发出的音就是基音,基音的频率称为基频.谐波存在于基频的整数倍处,也会有较大的能量.正是不同的谐波分布导致了相同基频的不同发声体的具体音色不同.
2.2 十二平均律
十二平均律是世界上通用的一种音乐定律方法,它将一个八度的音按照频率等比例地分成十二等份,每一等份称为一个半音.前后两个半音间的频率倍数关系满足:
(1)
为了方便计算,本文将所有频率值转换为十二平均律中的音阶.目前国际标准音是A4,转换为物理频率是440 Hz,对应的midi音符是69.一个半音又定义为100音分,文中均以音分为最小单位.具体转换方式如下.
(2)
2.3 音乐数据集及评价标准
2.3.1 音乐数据集 本文实验中使用的音乐数据集是来自国际音乐信息检索评测比赛中主旋律提取专用的MIR-1K数据集.该数据集专为歌声分离研究而设计,包含有1 000首歌曲片段,还包含手动记录的半音音高、有声帧、无声帧、歌词等.歌曲由非专业的8位女性和11位男性演唱.因此本文所针对的均为主导旋律为人声的提取.
2.3.2 评价标准 评价标准旨在全面体现主旋律提取算法的性能,主要分为以下5个指标.
(1) 人声召回率(Voicing Recall Rate, VRR):提取序列中人声帧占标签序列中人声帧的比例.
(2) 人声虚警率(Voicing False Alarm Rate, VFAR): 提取序列中将非人声帧误判为人声帧的比例.
(3) 音高准确率(Raw Pitch Accuracy, RPA): 标签序列中人声帧的音高与相应帧的提取序列逐帧比较,音高差值小于50音分则为正确.
(4) 音色准确率(Raw Chroma Accuracy, RCA): 计算方法与RPA大致相同,对比时忽略八度错误.
(5) 总体正确率(Overall Accuracy, OA): 提取序列与标签序列所有帧逐帧比较,音高差值小于50音分则为正确.
3 主旋律提取
本节主要详细介绍了主旋律提取每一步骤的具体过程,其主要流程如图1所示.

图1 主旋律提取流程图Fig.1 Melody extraction flow chart
3.1 预处理
由于数据集的流行歌曲均为高度混叠的复调音乐,我们很难从中判别出单一的主旋律.为了降低伴奏带来的影响,文中采用了文献[7]提到的HPSS算法进行预处理.对于以人声为主旋律的音乐,能有效地筛除掉音乐中平缓的和弦伴奏与节奏感强的击打伴奏,从而增强人声主旋律信号.
3.2 多基频估计
3.2.1 传统谐波和方法 谐波理论认为人对声信号的感知是由基频及其一系列谐波共同组成.在频谱上也可以观察到在信号基频的整数倍处有明显的能量增强,总体呈现梳状结构.根据这些特点,Hermes等人[9]提出了谐波和方法.
(1) 将信号降采样后进行短时傅里叶变换(STFT),得到其频谱S(f,t);
(2) 计算谐波和:
(3)
其中,h为压缩因子,取0.84,作用是使高阶谐波对基频产生的影响更小;N为最大谐波次数,表示在最大谐波频率范围内出现基频倍数谐波的次数;H(f0,t)为频率在t时刻f0点处的分谐波叠加谱,也称为显著度函数.在理想范围内取分谐波谱能量最大的频率点作为t时刻的基频.
3.2.2 自适应谐波叠加方法 经过实验表明,直接由谐波和方法得到的基频序列容易出现半频或倍频错误.造成该错误主要有两点原因:(1) 是叠加的压缩因子h或谐波叠加次数N取值不当.当压缩因子h取值过大或者谐波叠加次数N过多,低频处能量就会过大,容易出现半频错误;反之则出现倍频错误;(2) 是某一频段处存在较强的伴奏或者噪声.尽管预处理可以去除部分伴奏和噪声,但残余部分仍会造成基频判别不准确,直接选取能量最大频率点判定基频存在一定误差.
因此,本文提出了一种自适应谐波叠加的方法,根据基频序列的方差特征及其变化趋势自适应改变压缩因子h.给定h一个初始值为零,根据式(3)计算整体频谱显著度,选取显著度最大频率点作为当前帧基频值,计算所有帧基频序列的方差.改变h的值,若当方差第一次趋于稳定且前后差值小于设定阈值后,则选定此时的h为该歌曲谐波叠加的压缩因子.计算过程如下.
fk=f0|Hk=max(Hk)
(4)
(5)
(6)
(7)
其中,k为h的迭代次数,M为该歌曲所有帧数;μk为第k次迭代中所有帧的基频序列均值;σk2为第k次迭代中所有帧的基频序列方差.步长α设置为0.1,阈值q设置为0.03.
实验表明,大于5倍的谐波乘压缩因子后不会对显著函数造成太大影响,且5倍以内的谐波和基本包含了所有需要的谐波信息.因此,将谐波叠加次数N的值固定为5,节约计算成本.同时基频的选择不再局限于最大能量频率点.通过分谐波叠加得到整个频谱的显著度函数,在理想基频范围100~500 Hz内选出多个候选频率,作为后续处理的输入.
以歌曲Ani_3_03.wav为例,图2展示了其自适应谐波叠加的显著函数,颜色越亮处说明该频率显著度越高.

图2 Ani_3_03.wav的显著函数Fig.2 The saliency function of Ani_3_03.wav
3.3 多音高跟踪
3.3.1 选择候选基频 在选取候选基频之前,首先对显著度函数进行处理,只保留峰值点及其邻近两点频率分量,目的是减少非峰值点的干扰,滤除环境噪声.本文将所有峰值点归为候选基频和补充基频两类.计算所有峰值点显著度的均值μ和标准差σ,公式如下.
(8)
(9)
其中,P为该帧峰值点的个数.将显著度高于μ-τσ的峰值点归为候选基频,其余峰值点归为补充基频.实验表示,τ取0.9时效果最好.
3.3.2 构建基频片段 Justin Salamon在文献[5]中提到了构建基频片段的方法.
(1) 前后向搜索候选基频,使得一个基频点仅属于一个基频片段,且在时间上连续传递,在频率上平滑变化.
(2) 对所有基频片段的特征进行分类提取,滤除能量、标准差较小的基频片段.
本文在此基础上还计算了能熵比特征[10],并滤除能熵比较小的基频片段.谱熵反应了声源在频域幅值分布的“无序性”,对于噪声和和弦伴奏谱熵较大,能量较小.计算公式如下.
(10)
(11)
(12)
(13)
其中,E(n)为基频片段的能量;prob(n)为每个频率分量的归一化谱概率密度函数;H(n)为基频片段的谱熵.以歌曲Ani_3_03.wav为例,图3展示了通过上述方法构建的基频片段.
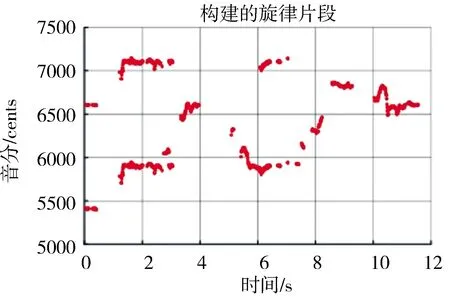
图3 Ani_3_03.wav的基频片段Fig.3 The fundamental frequency segment of Ani_3_03.wav
3.3.3 八度错误检测 八度错误是指将音高错判为高八度或者低八度的音阶.对于基频片段,检测及纠正八度错误的步骤如下.
(1) 寻找时间上重合且音高差值在一个八度(1200音分)左右的两条基频片段;
(2) 按照所有基频片段的能量加权计算每个时间帧的平均音高P0;
(3) 逐帧计算两条八度错误对音高与P0的差值,删除差值较大的基频片段.
得到正确基频片段后,按照显著度从大到小排序,每帧取一个基频值,组合得到完整的基频序列.以歌曲Ani_3_03.wav为例,图4展示了通过滤除八度错误片段后得到的主旋律序列.
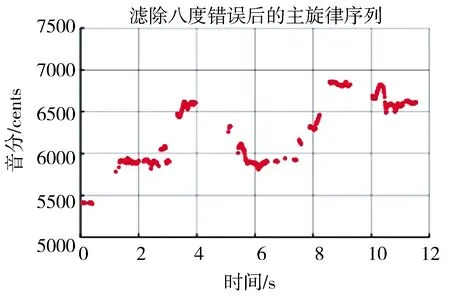
图4 Ani_3_03.wav滤除八度错误后的主旋律序列
Fig.4 The melody sequence of Ani_3_03.wav after eliminating eight-degree errors
3.4 实验结果及分析
本章实验采用MIR1K数据集,随机标记500首歌曲标记为测试集,另500首歌曲将在后续实验标记为训练集使用.测试歌曲由主旋律与伴奏以0 dB的信噪比进行混合,分别计算使用传统谐波和方法与使用自适应谐波叠加方法在测试集上提取主旋律,结果指标参数如表1所示.
表1 传统谐波和方法与自适应谐波叠加方法对比
Tab.1 Comparison of traditional harmonic sum method and adaptive harmonic superposition method

方法VRR/%VFAR/%RPA/%RCA/%OA/%传统谐波和81.6340.7964.0364.3661.52自适应谐波叠加78.0134.3664.2864.8763.63
观察结果可以发现,自适应谐波叠加方法构造的显著函数为后续主旋律提取结果的准确性带来了有效的提升.但是总体人声召回率较低、虚警率较高导致了整体准确率不佳.因为数据集中歌曲演唱者是非专业的,并且演唱环境较为嘈杂,人声的能量不够突出,就显著度而言并不占优势,所以在能量筛选的过程中容易出现误判.因此在后续章节中讨论了人声检测的重要性.
4 人声检测
4.1 声学特征提取
4.1.1 Mel频率倒谱系数及其MSDC系数 人对声音的听觉感知是非线性的,人耳就是一个特殊的滤波器组,在低频段分布较密,在高频段分布稀疏.学者根据人耳的特性设计了Mel滤波器组来模拟耳蜗模型,并提出了Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)[11].
实验中采用的是24阶的Mel滤波器组,取2~14位系数构成MFCC特征.同时取当前帧MFCC系数与上一帧MFCC系数的差值,加上原始的13位MFCC系数组成MSDC特征,该特征不仅仅局限于当前帧,具有一定的动态性.
4.1.2 对数频域能量系数 对数频域能量系数(Log Frequency Power Coefficient, LFPC)[12]取50~8000 Hz范围划分成12个对数域上等距的子带,代表了子带上能量的分布情况.计算公式如下.
(14)
其中,Xt2(k)是第t帧第k个频率分量的能量;Bm是第m个子带的频率范围;Nm是该子带内所有频率分量的个数.
4.1.3 线性预测系数 在人声中占据大部分能量的都是浊音,而浊音的产生可以等效为单位脉冲序列激励声道管,该过程为线性时不变系统.一个浊音的采样值可以通过过去若干浊音采样值的线性组合来逼近,在取得最小均方误差时,能够决定唯一的一组线性预测系数(Linear Prediction Coefficient,LPC)[13].该特征反应了人声前后时间点的关联性.
4.1.4 频谱对比度特征 频谱对比度特征(Spectrum Contrast Features, SCF)[14]将频谱划分为6个对数域上等距的子带,计录每个子带内能量峰谷值及其差值.谱峰主要对应谐波分量,谱谷主要对应非谐波分量和噪声,该特征反应了谐波与非谐波分量的分布情况.
(15)
(16)
其中,xk为频谱按照能量降序排列;x′k为频谱按照能量升序排列;α为宽度因子,取值为0.02,表示峰谷值是取附近几点的平均值而定,目的是防止毛刺干扰等.
4.1.5 频谱形状特征 频谱形状特征(Spectrum Shape Features, SSF)是通过每帧频谱的形状反应频率分量及能量分布的总体概况.Geoffroy Peeters在文献[15]中提到可以将频谱形状特征作为判别是否存在人声的依据,并且提出了8种特征共同作为一组频谱形状特征向量,包括:谱质心、散度、偏度、峭度、衰减度、滚降频率、谱平坦度、谱突出度.
4.2 随机森林
上世纪八十年代Breiman等人发明分类树的算法,实现数据进行分类或回归.2001年Bierman又把分类树组合成随机森林,即有放回地随机采集多个训练样本,生成多个分类树,每个分类结果都由多个分类树共同投票决定.比起其他常见的分类方法,如GMM分类器、SVM[16]分类器等,随机森林采集部分样本和抽取部分特征寻找最优解,不容易陷入过拟合,对数据适应能力强,且实现简单.本文通过利用随机森林模型对上述特征进行学习,然后对信号进行分类.
根据3.4节实验分类完成的MIR1K数据集,将已标记的500首训练集中的歌曲及对应的人声标签送入模型进行训练.每棵决策树通过有放回地选取不同部分特征进行判决,对照人工标注结果训练模型.训练完成后将另500首歌曲送入模型,综合多棵决策树判决结果给出该帧是否属于人声帧的比例,并与人工标注结果进行对比.
4.3 实验结果及分析
4.3.1 人声特征分类结果 本实验的目的是验证随机森林模型对不同人声特征组合分类结果的正确性.实验中树的数量N取100.表2展示了不同特征组合情况下的人声检测分类结果.最优的特征组合为MSDC+LFPC,正确率达到了83.28%.
表2 不同特征组合下人声检测的结果
Tab.2 The results of voice detection with different feature combinations

特征组合VRR/%VFAR/%OA/%MFCC91.3950.2779.92MSDC92.0151.5479.97LFPC90.7840.6082.03LPC92.5276.8272.13SSF92.1165.1675.22SCF88.8844.4379.64MFCC+LPC92.8151.0480.61MFCC+LFPC91.7439.3983.12MSDC+LFPC91.2137.3583.28MFCC+SCF91.4444.8481.44MFCC+SCF+LFPC91.6638.7083.22
4.3.2 映射主旋律提取结果 将第三节用自适应谐波叠加提取到的主旋律序列,通过MSDC+LFPC特征组合得到的随机森林模型,对每一帧信号进行人声检测分类.根据分类结果将人声帧提取的主旋律保留,非人声帧的主旋律置零.若人声帧提取的主旋律为零,则提取显著函数中该帧能量最大的频率分量补充到主旋律中.
表3是映射主旋律序列的结果.相比第三章实验结果,总体准确率由63.63%提升到了73.25%,召回率明显提升,但虚警率还是较高.原因是在训练集中人声帧数量远大于非人声帧,生成的随机森林模型分类结果更倾向于人声帧.为了降低虚警率,我们在之前的映射结果基础上再进行过滤和平滑处理,主要包括过滤能量较小点、删除频率突变点和补充频率缺失点.
表3 人声检测直接映射主旋律序列结果
Tab.3 Melody sequences results of voice detection by direct mapping

VRR/%VFAR/%RPA/%RCA/%OA/%91.2037.2677.0777.2373.25
图5是歌曲Ani_3_03.wav最终提取序列与标签序列对比结果.为了方便比较,图中将标签序列人为降低了500音分呈现.从图中不难看出,提取的主旋律序列与标签序列基本一致,表明了提出方法的有效性.表4展示了数据集所有音乐主旋律最终提取结果,并与2018年MIREX主旋律提取的算法KN3[17]、LS1[18]进行对比.实验分别采用主旋律与伴奏声以0、 -5、 5 dB三种不同信噪比情况进行混合提取.
在0 dB情况下经过平滑过滤后的总体正确率从73.25%提升到了76.20%.通过结合机器学习的方法,将声学特征运用到了人声检测,能有效地减小虚警率.在高信噪比的条件下,人声与伴奏的特征差异更加明显,有助于分类结果的准确性.此时的虚警率达到最低7.09%,总体准确率达到最高85.04%.

图5 Ani_3_03.wav的提取旋律与标签序列对比Fig.5 Comparison of melodyextracted from Ani_3_03.wav and label sequences

表4 本文方法与其它方法结果对比
5 结 论
主旋律提取是音乐信号处理的一大重要分支.本文提出了一种自适应谐波叠加方法构建显著函数,并从中得到候选基频组成了基频片段.对多种声学特征组合进行分析,结合了随机森林模型进行人声检测.实验表明在高信噪比情况下主导旋律为人声的音乐集上取得更好效果.因此,本文的主旋律提取方法对后续旋律发展、音乐分类、音乐合成等具有一定的借鉴意义.
