基于深度学习的番茄叶部病害识别模型
2020-06-01许冠芝王泽民李成强
许冠芝,王泽民,李成强
(西安工程大学电子信息学院,西安710600)
1 引言
2017年我国发布了《新一代人工智能发展规划》,其中包含了人工智能在智慧农业领域的应用,如使用农业信息大数据智能决策分析系统,建立完善一体化的智能农业信息监测系统等[1]。以人工智能技术解决传统农业问题是当前的研究热点。在此拟采用人工智能技术中的深度学习方法解决番茄叶部病害识别问题。番茄在我国栽种面积广泛,是当今食用量最多的果蔬之一,但番茄叶病一直制约着番茄产量和质量的提升。番茄叶部病害类型的诊断对番茄病害的防治就显得尤为关键。及早对番茄叶部病害进行识别防治,能最大化降低病害对番茄造成的经济损失,具有重要的理论和实际意义[2]。
传统对于番茄叶部病害的识别主要依赖农民或者专家下农田亲自检查,依靠经验进行诊断。这种方法非常不便捷且诊断结果具有很强的主观性[3]。近年来,对于农作物病害诊断逐渐发展为利用计算机技术对植物病害图片进行识别。文献[4]提出了一种利用统计方法,通过番茄叶片不同病害颜色、形状等特征不同来确定番茄病害的方法。该方法对颜色特征的提取依赖较大,某几种识别率较高,而某些病害则出现较高误诊。文献[5]提出了一种基于光谱反射特性的番茄叶片早疫病病害识别方法,该方法在某一波段内识别率较高,具有极大的局限性。文献[6]提出一种利用遗传算法从图像纹理、颜色、形状等多个特征中选取稳定性及分类能力强的特征用于病害识别的方法,该方法依赖于人工对特征的选取,具有很强的主观性。文献[7]提出一种基于神经网络的水稻二化螟虫害的识别方法,该方法使用的样本较少,增大实验样本可以提高对二化螟虫的识别率。
综上所述,现有方法大多是基于对病害的特征提取,不同病害对应不同的颜色、形状特征,不具有通用性。人工方式特征提取对专家经验要求较高。图片的质量又对结果影响较大。针对此类问题,拟采用深度学习方法,建立番茄叶部病害识别模型。
深度学习是人工智能领域最前沿的研究方向之一。深度学习技术已成功应用于语音识别[8-9],图像识别[10-11],自然语言处理[12-13]等领域。主要有深度置信网络(Deep Belief Networks,DBN)[14],循环神经网络(Recurrent Neural Network,RNN)[15],生成式对抗网络(Generative Adversarial Networks,GAN)[16]和卷积神经网络(Convolutional Neural Networks,CNN)[17]等。因卷积神经网络对图片特征提取效果最好,故在此采用卷积神经网络网络构建病害识别模型。
2 相关算法介绍
2.1 卷积神经网络
卷积神经网络一般由输入层、卷积层、池化层、全连接层和输出层构成[18]。卷积层主要作用为对输入数据进行特征提取。用一个合适大小的矩阵(卷积核)对输入进行扫描,提取出输入图像的特征。卷积过程可以下式来表示:

式中,h表示输出,x为输入。输入包含A个通道,即有A副图像x1,x2,...,xA,相应的扫描矩阵即为w1,w2,...,wA,偏置为b。
池化层主要作用是对输入的特征进行进一步的提取,可以简化网络的复杂度,又能保留主要特征。以下为常用的两种池化操作计算公式:
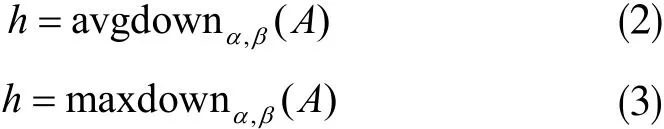
式(2)为平均池化公式,式(3)为最大池化公式,其中h为输出,A为输入,采样块大小皆为α×β。
全连接层的主要作用是将卷积和池化提取的局部特征重新通过权值矩阵全卷积为完整的特征,因为应用到了所有局部特征,所以叫全连接。输出层的作用就是最后对特征进行分类识别,输出结果。
2.2 PCA算法
经全连接层提取的特征维度较高、计算量大、训练耗时,需要对高维特征进行数据降维处理。PCA是一种用于数据降维的算法,中文名为主成分分析法[19],主要思想是对数据进行线性变换,将任意数据变换到新的坐标系中,保留数据中对方差影响最大的特征。为了得到包含最大差异性的主成分方向,需要计算数据矩阵的协方差,然后得到协方差矩阵特征向量,选择特征值最大的K个特征所对应的的特征向量组成的矩阵。这样就可以将数据装换到新空间,实现降维。
样本均值、样本方差、协方差计算公式依次如下所示:

2.3 Softmax损失函数及其改进
2.3.1 Softmax函数与中心损失函数
Softmax函数用于解决多分类问题,是Logistic函数的推广[20],适合于此处的番茄多种叶病识别。该函数会判断输入属于某一个类别的概率,如果最大,这个类就输出1;其他类输出值接近0。由此可知该算法类间互斥,某个输入只能属于一个类。Softmax损失函数如下式:

其中,y(i)表示病害标签,W是模型参数,x(i)是训练样本特征向量。k为病害类别数目,m为样本大小。
在实际应用中,当提取的特征不足以用来对类别进行强分类时,经常会出现类内距离大于类间距离的情况发生,对最终的分类识别结果影响较大。在此问题上,Wen[21]等提出了中心损失函数。对于一个卷积神经网络来说,每次可计算出多个特征中心,同时根据特征值与其对于中心的距离计算损失函数。该函数可用下式表示:
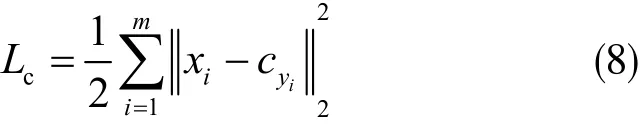
其中,cyi是第yi个类的特征中心。xi是第i张图片的特征值。类内变化可用下式表示:

由式(9)可知,特征中心cyi随深度特征的变化而变化。Lc相对于cyi的更新计算公式如下式所示:
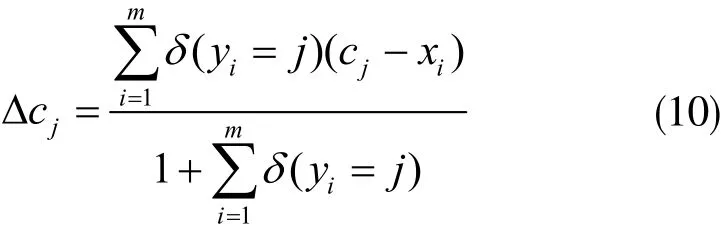
其中,当条件yi=j满足时,δ(yi=j)值为1,不满足时值为0。当训练集规模较大时,需要以小批量的方式进行中心值的更新以解决一次性无法将所有中心获取的问题。
2.3.2 改进的softmax函数
由前一节的论述可知,为了增大类间距离的同时减小类间距离,将softmax损失函数与中心损失函数结合起来,作为联合监督函数。联合监督函数代替原来的只含softmax函数作为输出层的分类函数。联合函数如下式所示:
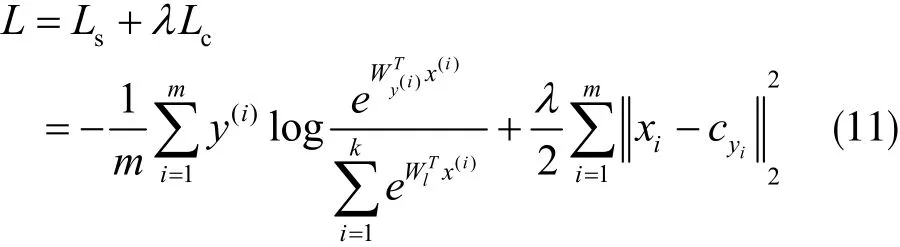
其中,λ是用来平衡两个损失的参数。合适的λ可以大大提高特征识别能力。由式(11)可知,当λ为0时,该函数即为softmax函数。
3 算法设计
基于深度学习的番茄叶片病害图像识别算法设计一个卷积神经网络用于对输入的病害图像进行特征学习提取,对提取的病害特征进行PCA降维,最后利用改进的softmax函数进行病害分类。总体框架如图1所示。

图1 算法总体框架图
图中,输入是番茄叶部病害图片,数据预处理是对输入的图片进行标准化和归一化。核心点在于CNN网络模型的构建,以及建立基于改进的softmax函数番茄叶部病害识别模型。在此将深度学习技术应用于传统农业病害识别问题,引入PCA降维算法并改进softmax函数,以提高番茄叶部病害识别的准确度。
3.1 基于CNN模型的新算法
如前所述,组成卷积神经网络由输入层、卷积层、池化层、全连接层和输出层构成。在此,根据数据集大小及番茄病害特点,设计一个七层CNN神经网络,其模型如图2所示。
此CNN模型共有七层(只计算卷积层和全连接层)。网络的主要参数如下:
1)输入为256×256×3的RGB图像;
2)全部卷积层和全连接层激活函数都为Relu(Relu函数在输入大于0直接输入该值,输入小于等于0时,输出0);
3)卷积层 C1,卷积核大小为 6×6×3,设置 64 个卷积核,步长(stride)为 2,Padding=same(此处用padding来解决图像边界信息发挥较少问题,方法是进行零填充),输出为 126×126×64;
4)池化层 S1,采样区域为 3×3,步长为 2,采样方式为最大采样,输入为C1的输出,输出为63×63×64;
5)卷积层 C2,卷积核大小为 3×3×64,设置 128个卷积核,步长为2,Padding=same,输入为S1的输出,输出为 31×31×128;
6)池化层 S2,采样区域为 3×3,步长为 2,采样方式为最大采样,输入为C2的输出,输出为15×15×128;
7)卷积层C3,卷积核大小为3×3×128,设置256个卷积核,步长为1,Padding=same,输入为S2的输出,输出为 15×15×256;
8)池化层 S3,采样区域为 3×3,步长为 1,采样方式为最大采样,输入为C3的输出,输出为7×7×256;
9)卷积层C4,卷积核大小为3×3×256,设置384个卷积核,步长为1,Padding=same,输入为S3的输出,输出为 7×7×384;
10)池化层 S4,采样区域为 3×3,步长为 1,采样方式为最大采样,输入为C4的输出,输出为3×3×384;

图2 CNN结构模型图
11)全连接层F1,使用了4096个神经元;
12)全连接层F2,F3神经元个数由PCA降维之后决定;
13)输出层,采用改进的softmax函数,输出类别为10类病害类型和健康类型共11种类别。
3.2 PCA降维与联合函数结构设计
至此,得到了一个基本的神经网络结构,全连接层F1得到一个4096维度特征,经PCA对高维特征进行降维。再通过改进的softmax函数进行病害种类识别。结构模型图如图3所示。
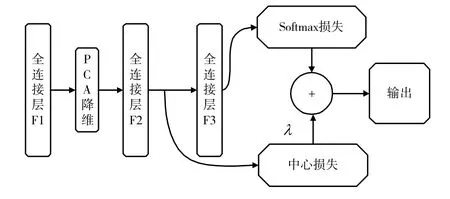
图3 PCA与联合函数结构模型图
图3所示结构是对图2全连接层F1之后的改进。图2是本提取方法的基本结构,但在池化层S4之后使用的是3个全连接层。提取的番茄病害特征维度较高且会出现类内距离大于类间距离情况,故图3在图2的基础上,在全连接层F1之后加入了PCA对特征进行降维。全连接层F2与F3采用softmax损失和中心损失联合函数对特征进行分类,以提高分类准确性。
3.3 算法步骤
以上述网络结构为基础,构建完整CNN网络,对于PCA降维部分,在全连接层F1之后增加一层PCA降维层,在实验时分别验证不加入PCA降维,以及加入PCA降维之后。不同特征维度对识别精确度的影响。
对于全连接层F2及F3的softmax与中心损失联合监督算法部分,将算法的输入抽象为:训练数据集{xi},分别初始化池化层和损失层参数θc、W及同时输入参数:λ和学习率μt,其中迭代的次数t初始化为0。输出则抽象为输出参数θc。联合监督的病害识别算法步骤可归纳如下:
Step1:判断是否收敛,不收敛则跳向step2;
Step2:迭代次数t=t+1;
Step3:根据公式(11)计算联合损失L;
Step5:利用梯度下降法公式更新参数W,cj,θc;
Step6:判断是否收敛,如果收敛则迭代结束,否则从step1开始循环执行。
4 实验与结果分析
4.1 仿真目标与步骤
在算法设计完成的基础上,通过实验验证番茄叶部病害识别算法的准确度和鲁棒性。实验需要分别验证病害特征维度对精确度的影响,以及改进的softmax函数对精确度的影响。
验证病害特征维度对准确度的影响的方法:首先使用原softmax函数,通过改变PCA降维维度,测试在softmax函数不改进的情况下,不同维度与准确度之间的关系,并根据结果得到最佳维度。
验证改进的softmax函数对精确度影响的方法:由前一步得到了PCA降维的最佳维度,然后将该维度固定,测试改进的softmax函数中的参数λ对识别准确度的影响,以确定最佳λ。
观察两次准确度的变化,验证本模型对番茄叶部病害识别准确度提升的作用,并与当前通常使用的其他番茄叶病识别算法比较,验证本算法的优越性。
4.2 数据来源及数据预处理
数据来源为:选取国外知名农作物人工智能研究机构CrowdAI网站所提供的番茄叶部病害图片。另有部分图片数据来自我国农业网站,如安徽省农业科学院情报研究所网站所提供的番茄病害图片。
从数据集中选取了我国最常见的10类病害图片,每类病害共选取600张图片,加上正常番茄叶部图片共11类,6600张图片。这10类病害具体为番茄早疫病、番茄晚疫病、番茄叶霉病、番茄斑枯病、番茄花叶病、番茄棒孢菌病、番茄灰叶斑病、番茄细菌性斑点、番茄二斑叶螨病、番茄黄化曲叶病。将图库随机划分为训练集和测试集,训练集占总图库3/4,测试集为1/4。图4给出了正常蕃茄叶片及部分患病叶片图片。

图4 数据集部分图片
再对数据进行预处理。原图分辨率大小不一,需要统一处理为256×256像素,以.jpg格式保存。使用谷歌tensorflow深度学习框架中提供的tf.image.resize_images函数调整图像大小。此外还需对图像进行归一化处理。归一化并不会改变图像原有的信息,而是将图像像素值取值范围从0~255转化为0~1之间,以方便卷积神经网络对图像的处理。此处使用最大最小归一法对,公式如下所示:
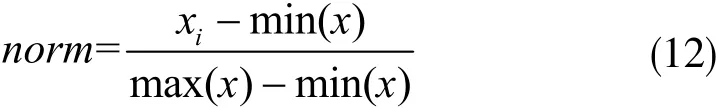
其中,xi表示图像的像素点值。max()与min()分别表示最大、最小函数。
4.3 实验过程分析
4.3.1 PCA降维
采用图2结构所示的卷积神经网络F1层输出的病害特征有4096维,特征维度较大,计算和训练用时过长,降维可以去除冗余特征解决多重共线性问题。为了找到合适的特征维度既能去除冗余,又能拥有较好的识别精度,采用PCA算法对4096维的特征进行降维。经过多次实验得到精确度与特征维度曲线图如图5。从图中可以看出,数据维度降低过程中,精确度呈非线性变化,在降低到64维时精确度达到最优;而低于16维时精确度急剧降低,从4096降到64维过程中精确度稳步上升。这表明卷积神经网络提取的特征含有一定的冗余信息。去除这部分冗余,精确度便得到改善。而数据维度低于16维时,由于过度降维,去除了有用信息,导致精确度急剧下降。
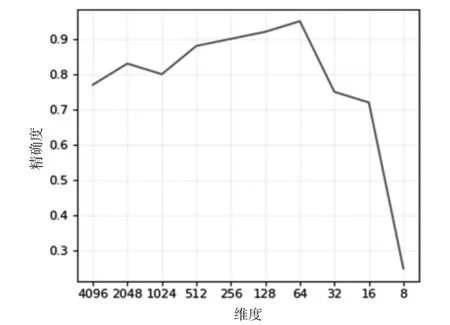
图5 精确度与特征维度曲线图
4.3.2参数λ对分类结果的影响
合适的λ值可用来平衡联合函数,加强网络对特征的分类能力。由于识别精度同时还受学习率的影响,首先固定学习率为0.5,改变λ值,测试不同λ值对识别精度的影响。测试结果如图6所示。由图可知,当λ为0时,为单纯只有softmax算法,识别精度没有联合函数高,当λ取0.003时,识别精度最高,能比softmax改进之前精度提高2.5%左右。这也说明,一个合适的参数对于联合函数是非常重要的。对于参数λ值的选取,目前只能通过多次实验的方法确定。
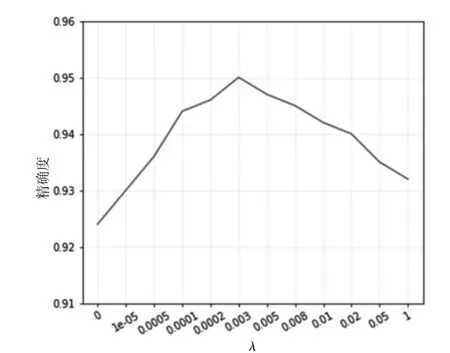
图6 参数λ与识别精确度关系图
学习率对识别精度也有一定影响,故此还进行了学习率对识别精度影响的测试实验,当参数λ固定选取0.003时,测试不同的学习率对识别精度的影响。根据前人研究经验,学习率取值范围限定为[0.001,1]。学习率与精确度关系曲线见图7。依据分析,学习率最佳选择为0.5。
4.4 对比实验
所提出的方法在CrowdAI提供的数据源上获得了较好的识别效果。每类番茄叶部病害的具体识别结果如表1所示。
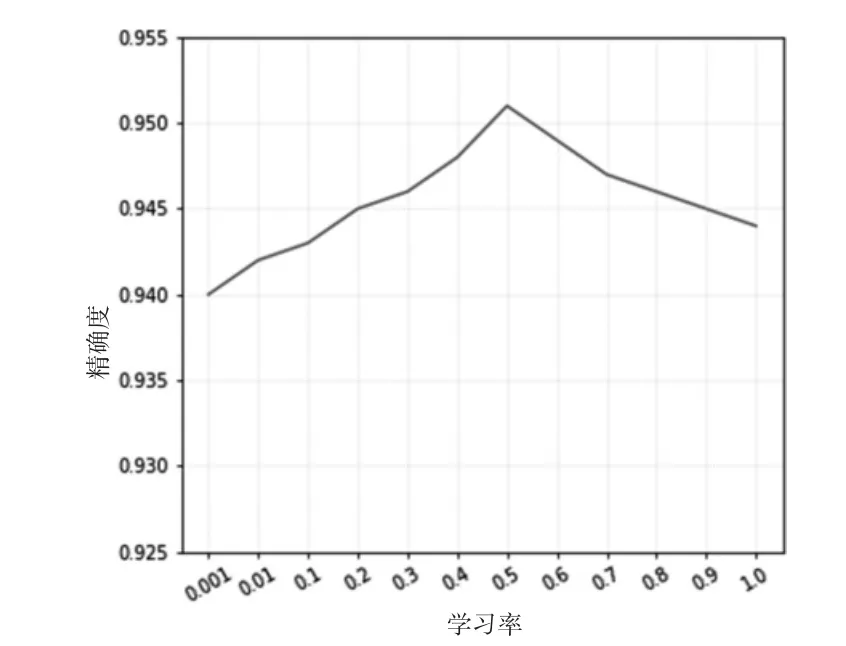
图7 学习率与识别精确度关系图
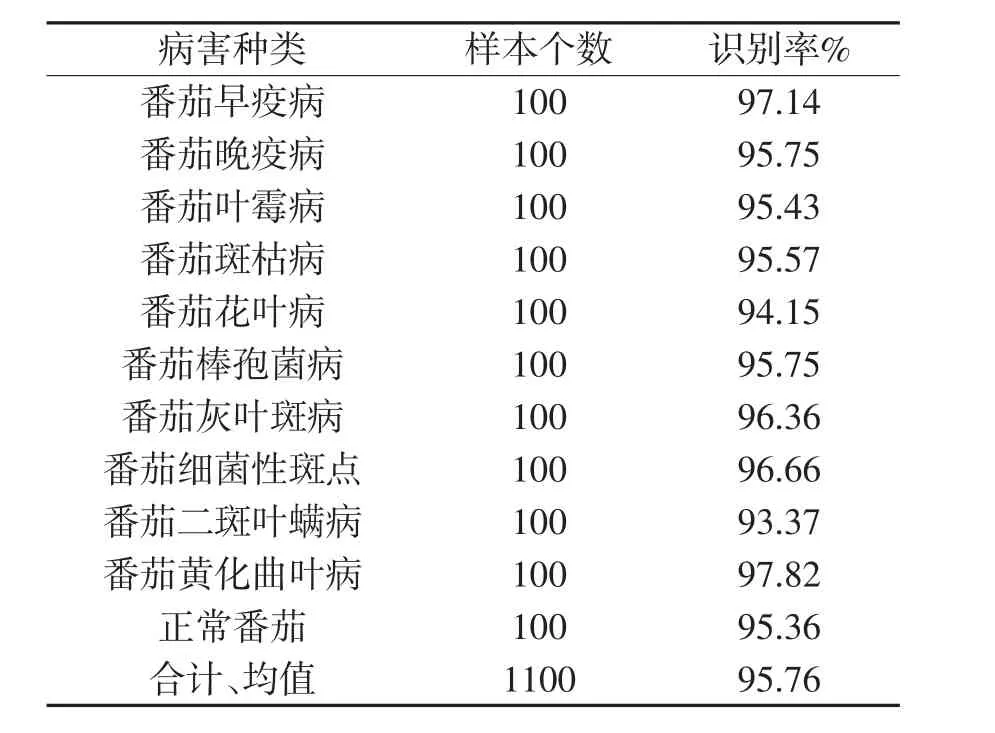
表1 常见番茄叶部病害识别结果
从表1可知,所提出的番茄叶部病害模型识别率较高,综合识别率能够达到95%。为进一步说明所提模型的有效性和优越性,将本方法与目前在农业病害中常用的识别算法精确度进行性能对比,结果如表2所示。

表2 算法结果对比
从表2可以看出,所提出的基于深度学习的番茄叶部病害识别方法在识别精确度上优于传统的识别算法;SVM+CNN算法采用了传统机器学习分类算法SVM及CNN网络的结合,并未对特征进行降维及对softmax损失改进,本文方法比SVM+CNN方法准确率提高了8.2%;GA-BP算法采用的是一种人工对病害特征选取的算法,相比而言,本文采用深度学习算法具有对特征自动提取的优点,本算法比GA-BP方法准确率提高4%;LSM-H算法适用于轮廓比较明显的待识别物体,经过Hought变换及最小二乘法得到最终识别结果,准确率较高,但是局限性较大本文算法比LSM-H方法准确率提高了0.8%;FCNN-H是快速归一化互相关函数与霍夫变换结合的一种传统识别算法,识别准确率较低,本算法比FCNN-HT方法准确率提高了9%。
通过与同类的深度学习算法以及传统机器学习算法的对比,可见本模型对番茄病害识具有更高识别精确度及更强的识别通用性。通用性是指本方法能识别番茄10种常见叶子病害,通过增加样本数据,能够做到识别更多的病害种类。而传统机器算法通常只针对一种或一类进行识别。
5 结束语
提出了一种基于深度学习的番茄叶部病害识别算法模型,设计了一个七层卷积神经网络,使用PCA降维算法并对softmax函数进行改进。该模型在CrowdAI所提供的数据集上的实验结果表明:PCA对维度的降低能够提高识别精确度,减少训练时间,softmax联合函数能够一定程度增大类间距离的同时减小类内距离,提高CNN对病害特征的识别能力。实验结果表明该模型对番茄10类病害综合识别率达到95.7%,验证了模型的有效性。
