基于多尺度特征的图像描述生成模型
2020-05-30周星光靳华中徐雨东李晴晴
周星光, 靳华中, 徐雨东, 李晴晴, 胡 满
(湖北工业大学计算机学院, 湖北 武汉 430068)
随着深度学习的出现,计算能力的提升,人工智能技术得到了飞速发展。图像描述生成涉及计算机视觉和自然语言翻译技术,目的是将图像视觉信息和语言文字信息联系起来,经过对图像视觉信息的特征提取,自动生成关于图像内容的语言描述。图像描述生成对于计算机实现快速检索和分析图像数据具有非常重要的意义。自动生成准确的图像描述文字存在着诸多挑战和困难,是目前人工智能领域研究的难点和热点。
现有主流的图像描述生成模型通常采用编码器--解码器结构,其中编码器用来提取图像特征,解码器作为语言模型用来生成描述性语言。近年来,依靠深度学习的快速发展,特别是卷积神经网络[1](Convolution Neural Network,CNN)计算机视觉领域已经取得了诸多颠覆性成果,其中发展迅猛的目标检测与识别技术在ImageNet,MSCOCO等公开的数据集上面都取得了突破性的进展。计算机视觉利用CNN提取图像特征特性。相对于传统的图像特征提取方法,CNN可以更好地提取图像特征。
自然语言处理是研究如何使机器“读”和“说”,是实现人和机器之间用人类使用的自然语言进行更加有效沟通的关键技术。自然语言的飞速发展带来了人机交互形式的改革与创新。近年来,自然语言处理领域也在进行着飞速的发展。例如,在斯坦福大学发起的文本理解挑战赛(Stanford Question Answering Dataset,SquAD)中,微软亚洲研究院提交的模型在精准匹配指标上首次超越人类的水平,IBM在自然对话环境中的语言识别错误率达到了接近人类的水平,基于神经网络的机器翻译的准确率和速度都实现显著的提升。
图像描述生成技术具有非常广阔的实际应用场景。图像描述生成可以应用到图像检索、机器人问答、辅助儿童教育及导盲等多个方面,对图像描述生成的研究具有重要的现实意义。图像描述生成对于人工智能的发展同样具有重要的作用,相当于建立了计算机视觉和自然语言处理的桥梁。
1 相关工作
对于一张图片,图像描述生成方法能够让计算机自动地生成描述图片内容的语句。根据图像描述生成模型的不同,图像描述的方法主要分为三类:第一类是基于模板[2]方法,首先对图片中的物体、场景等信息进行识别,然后将对应的词汇填入到句子模板中。该方法生成的句子较为呆板,形式较为单一,准确率不高;第二类是基于检索[3-4]的方法,首先在训练数据库中检索和测试样本相似的图像,在将检索到的图像描述转移到待测试图像上,进而生成图像描述。该方法严重依赖训练数据库中的图像,无法生成比较新颖的图像描述内容。第三类是基于深度学习的方法,卷积神经网络作为编码器提取图像特征,循环神经网络(Recurrent Neural Network,RNN[5])作为解码器生成图像描述。通过将二者优势结合形成端对端的方法,共同指导图像的描述生成。该方法能够生成描述更加准确的句子。基于深度学习的图像描述生成研究以来,Mao等在文献[6]中提出的多模态循环神经网络( multimodal RNN,m-RNN)的方法广泛应用。m-RNN将图像描述的工作分成两个任务:利用CNN提取图像特征,RNN建立语言生成模型将图像特征转化成文本信息。m-RNN中CNN使用AlexNet[7]网络结构,RNN使用两层嵌入层将文本信息编码成One-hot向量表示,然后输入到循环层中,最后通过Softmax层得到输出。虽然m-RNN将CNN作为编码器引入到图像描述任务中,但因RNN网络结构限制,对于较长的网络系列易出现梯度消息的问题。Vinvals等[8]使用长短期记忆网络LSTM代替一般的RNN,并且使用带有批标准层的CNN提取图像特征,图像描述准确率和速度均有提升。
从注意力模型命名方式看,很明显借鉴了人类的注意力机制。视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要关注的目标区域,也就是注意力焦点,然后对注意力焦点区域投入更多注意力资源,以获得更多所需要关注目标的细节信息,而抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高质量信息的方法,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率和准确性。深度学习中的注意力机制从本质上和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选取出对当前任务目标更关键的信息。文献[9]将文献[10]注意力机制引入到图像描述生成,提出hard-attention与soft-attention模型,提高了模型的性能。文献[11]使用基于注意力的翻译模型,可以并行训练模型,提升了翻译性能。文献[12]提出了一种自上而下和自下而上相结合的注意力机制,提升了模型在视觉问答和图像描述生成的性能。
尺度是计算机视觉与图像处理领域的一个非常重要概念。任何一个视觉问题的答案都依赖于其所在的尺度。Lin等[13]将多尺度图像作为输入,产生了不同尺度的特征图,提高了语义分割的精度。文献[14-15]的图像表示方法可以在突出对象内容的同时刻画对象特征之间的空间关系,但是都没有考虑到不同尺度下物体的意义。文献[16-17]提出的空间金字塔池化方法,此方法通过不同尺度bin的采样,将局部特征进行聚合,bin越大采样的范围越广,因此可以为图像表示提供不同尺度的空间信息。
生成图像描述句子的准确率主要受以下两个方面的影响:一是对图片中的物体及场景特征提取能力;二是对物体间相互关系等信息的提取。以上的文献都是基于CNN提取图像特征,但是CNN决定了提取特征尺度单一,提取的图像特征处理较为单一,没有考虑到提取的图像特征利用不充分的问题。本文提出在图像编码阶段,编码器随着网络的深度不断加深,图像特征层的尺度在不断减小,提取不同层的特征作为多尺度特征,融合不同层的特征得到多尺度特征,获得更丰富的图像特征。将多尺度融合特征和CNN最后一层的特征输入到循环神经网络中;在图像解码阶段,利用自适应注意力机制LSTM语言模型生成描述语句。
2 基于多尺度特征的图像描述生成模型
2.1 本文模型结构
本文采用编码器-解码器的图像描述生成模型结构,其中编码器利用卷积神经网络(VGG19)来提取图像特征信息,解码器利用循环神经网络(LSTM)生成描述性语言。本文提出改进后的模型总体结构见图1。
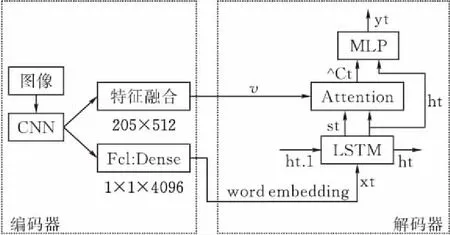
图 1 总体结构
2.2 基于多尺度图像特征提取的编码器
一幅图像中,只有在一定的尺度范围内,一个物体才有意义。例如,要观察一棵树,所选取的尺度应该是“米”级,重点关注树的形状而忽略树叶;如果要观察树叶,所选取的尺度应该是“厘米”,重点关注树叶而忽略树的形状;如果需要观察树叶的细胞结构,恐怕就需要“毫米”甚至“微米”级是必须的。图像中存在不同尺寸大小的对象目标,需要不同的尺度来提取图像特征。
本文基于VGG19提取不同层的特征图,从而提取到不同尺度的图像特征图进行特征融合,以增强对图像中不同尺度信息的提取。随着层数的增加,CNN提取的图像特征具有更好的高层语义信息,因而选择提取靠近最后层的特征层。提取Block5_conv2层的14X14X512的特征向量和Block5-pool层的7X7X512特征向量,将这两层提取到的特征向量进行Concat,得到不同尺度融合特征向量。最后提取FC1层的1X1X4096特征向量。基于VGG19的不同层特征图提取的结构见图2。将已训练好的包含4096维的特征和205X512不同层融合的特征作为图像描述模型的输入,导入到循环神经网络进行解码。
本文的模型关注图像的全局信息和多尺度融合信息,因而将卷积神经网络提取的4096维向量作为图像的全局特征,但是4096维的高维数据构成的特征在向量空间中表示,易造成数据稀疏的风险,因而对4096维向量进行降维处理。在模型的卷积神经网络输出阶段分别将4096维向量和205x512维向量映射到和文本相同的256维空间中。
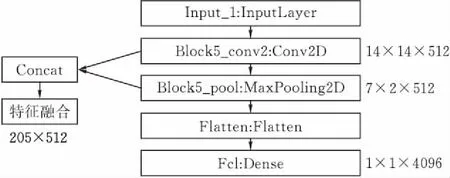
图 2 基于VGG19多尺度特征提取
2.3 基于自适应注意力LSTM的图像描述生成的解码阶段
使用CNN+LSTM网络进行图像内容描述的过程是一种编码-解码的过程。编码是使用CNN将图像映射为向量表示的过程,而解码是根据图像的特征,使用LSTM将特征转换为描述性语句的过程。
给定图像I和其对应的图像描述语句X。首先使用CNN提取图像特征v(I)。图像描述语句X={x1,x2,…,xL},xt是语句中单词的表达形式,表示为1-of-V(one-hot),其中,V是训练字典库大小。在模型训练过程中,训练的目的是使图像特征与描述语义句子之间的映射关系最大化,即
(1)
其中,θ为模型参数,该参数是网络自学习的。由于每个图像的语义描述语句是由一系列单词组成,因此可以使用链式法则将其分解为
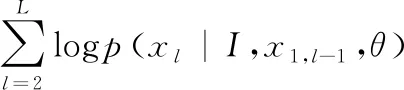
(2)
可以使用LSTM求得t1时刻生成单词的概率分布,即
pt+1=s(ht)
(3)
ht=L(Wxt,Uht-1,μCv)
(4)
其中,s(·)为softmax函数;L(·)表示为LSTM网络;ht为LSTM的隐藏层状态;W,U,C为模型自学习的参数矩阵;xt,ht-1分别为LSTM当前时刻的输入和上一时刻的隐藏层状态。
自适应注意力机制的主要功能是模型在生成句子描述时,模型可以自动选择关注图像的全局特征(4096)还是关注图像多尺度融合特征。自适应注意力在原有的LSTM基础上增加了两个公式:
gt=σ(Wxxt+Whht-1)
(5)
st=gt⊙tanh(mt)
(6)
其中xt是LSTM的输入,mt是memory cell。这里的gt叫‘哨兵’门,公式形式类似于LSTM中的输入门、遗忘门、输出门,决定了模型到底关注图像还是 visual sentinel;而st公式的构造与LSTM中的ht=ot⊙tanh(ct)类似。
(7)
(8)

(9)
本文选择VGG19最后一层卷积层的特征(1x1x4096)与word embedding拼接在一起成为LSTM的输入,多尺度的融合特征作为attention部分。
3 实验结果与分析
3.1 数据集与实验环境
本文数据集采用MSCOCO2014019数据集。数据集中包含了图像中所包含物体的类别、物体的轮廓坐标、边界框坐标以及对该图像内容的描述,其中每张图像的描述均至少有5种。本文的训练集、验证集、测试集,分别包含113287、5000和5000张图像。
实验环境为Win10环境下安装tensorflow 1.60深度学习框架,配置32 G内存 AMD Ryzen 5 2600X Six-Core Processor 3.6GHz CPU,NVIDIA2070 GPU,NVIDIACUDA9.0和cuDNN7.5深度学习库加速模型训练和测试,Python环境为Python3.7。
本文在图像编码阶段使用VGG19提取最后一层的全局信息(1×1×4096),将提取后Block5_conv2与Block5-pool的特征进行融合得到多尺度图像特征。在编码阶段,采用自适应注意力机制LSTM网络生成自然语言。在模型训练阶段,采用Adam优化算法和Dropout方法,将LSTM中的单元按照一定的概率进行屏蔽来防止过拟合,实验中Dropout设置为0.5,学习率为0.01,batch大小为128。
3.2 评价指标与实验结果
现有的图像描述生成的评测标准包括人工主观抽检评价和客观量化评分。主观评价即人工观测输出图像,评定图像描述的质量。目前最普遍的客观量化评分方法包括:BLEU[18]、ROUGE_L、METEOR[19]、CIDEr[20]。本文实验也采用BLEU, METEOR,CIDEr进行评价。
针对上面的三个评价标准,在MSCOCO数据集上分别评估BLEU,METEOR,CIDEr,评估结果见表1。

表1 不同模型在MSCOCO数据集上的得分
从评价结果来看,本文模型的各个指标均优于Google NIC , mRNN, Hard-Attentiom和VGG-LSTM模型。
3.3 结果分析
在测试结果中,图3a、3b和图3d中,本文模型相对于Google NIC、mRNN和VGG-LSTM,模型更好的提取到目标特征信息;在图3c中,本文模型更好提取到图像背景信息,生成较为完整、准确的图像描述语句。从评价结果和测试结果来看,本文模型在各个评价指标上都有一定的提高,表明本文提出的模型对图像描述生成任务的有效性,同样表明本文多尺度融合特征更好的提取到图像信息。在图像编码阶段使用VGG19提取不同层的特征,得到不同尺度下图像中物体图像特征,融合得到多尺度融合特征,获取更丰富的图像信息以增强循环神经网络输入端的信息量。在图像描述生成阶段,语言描述模型自适应选择关注多尺度融合特征还是全局特征,从而生成更加完整、准确的句子。本文模型增加多尺度融合信息,可以更好地识别图中的对象,但是比较复杂的场景还没法达到较为准确的结果。

(a)(Google NIC) a motorcy parked on the ground(our model) a motorcycle is parked on the ground

(b)(mRNN) Man is throwing frisbee in grassy(our model) a man is throwing a frisbee in a grassy

(c)(Hard attention) man playing frisbee in a field(our model) a man playing frisbbee in a field at night

(d)(VGG-LSTM) dock tower in front of a building(our model) a dock tower in front of a building图 3 测试结果
4 结束语
本文采用编码器—解码器结构的图像描述生成方法。针对现有图像描述生成中卷积神经网络提取单一尺度图像特征的不足,图像信息利用不充分,造成文字对图片内容描述的不够准确、语义较模糊。本文改进现有模型对图像特征的编码形式,提出了基于VGG19网络提取不同层的特征进行融合得到多尺度特征,获取更丰富的图像信息。在解码器阶段,基于自适应注意力机制LSTM网络生成图像描述语句。本文提出的模型在MSCOCO数据集上进行模型训练和测试,实验结果表明:本文模型很好融合了CNN不同层的特征,获取更丰富的图像信息,增强了语言模型输入的信息,自适应注意力LSTM网络模型生成更准确完整,更有意义的图像描述语句。
