基于大数据的金融风险预警系统的研究
2020-05-25卢民荣甘健胜
卢民荣,甘健胜
(1.福建江夏学院 会计学院,福建 福州 350108;2.福建省社科研究基地财务与会计研究中心,福建 福州 350108)
一、引 言
自1999年国际货币基金组织和世界银行启动“金融部门评估计划”(FSAP)开始,宏观经济指标(如GDP、利率等)为各国和各地区建立金融风险预警系统做了基础支撑。从经济宏观指数上看,我国2000年至2010年间GDP增速都在10%左右,2011年至今虽有所回落但也都保持在6%左右,而且宏观经济景气指数如预警指数、一致指数、先行指数等也都处于比较理想的状态。然而从金融股市的宏观指数上看,美国股市从6469低点上涨至26616高点,历时九年时间,涨了四倍,而我国创业板指数,从585点上涨至4037点,涨了七倍仅历时三年时间,其中代表中国A股的主板市场(上证指数,代码000001),从2014年下半年启动以来,累计最大涨幅翻了一倍,但历时不到一年时间,从而在经济与金融宏观指数存在不协调、不一致现象。[1]经历2017年、2018年连续两年稳态后,2019年各种事件影响着全球各大指数,引起一系列经济连锁反应。
2008年股灾、2015年股灾、2016年P2P平台跑路潮等金融风险大事件引致资本市场大幅波动问题仍然十分明显,而且在相关监管政策不断出台的背景下未能有效缓解,给我国经济社会带来了一定的负面影响。从金融微观上看,股市振幅(变化幅度)与时间的关系也表明我国上市资本金融市场机制仍然不够成熟,2017年8月14日“301 调查”、2018年3月23日发起的“贸易战”等事件,在接下来的三个月时间,我国A股上证指数从3300点跌至2800点以下,跌幅近20%且仍呈下跌趋势,其中影响最大的企业中兴通讯接近10个跌停,跌幅近60%。虽然2019年有所缓和,但近年来数据表明我国的金融机制仍需要进一步健全。[2]当前我国A股正处于纳入MSCI新兴市场指数初期和金融贸易风险过渡期,同时还受2020年突发新型冠状病毒肺炎疫情的影响(如开市第一天股票大面积跌停),也会增加我国的金融风险,因此对金融风险预警系统的多方面研究显得更加有必要。
国外的研究主要侧重于运用计算机技术和离散数学相关算法去分析金融资产和股票市场变化因素,通过数据挖掘相关算法分析股票市场中指标数据,并提取相关影响成分,最终设计为模型。构建宏观经济预警指标的研究比较多,Borio和Drehmann侧重金融体系研究,含房价基差、股价基差、信贷基差等预警指标[3];Grimaldi以欧洲金融事件(研究数据样本为1999—2009 年)衡量金融危机与极端金融事件发生之间的关系[4];Brave和Butters针对美国金融条件指数分析货币市场、债券及股票市场及银行体系[5],Bianco等根据美国日交易数据监测系统性金融风险[6];Penikas针对以色列建立宏观经济指标建立了该国金融稳定指数[7];Acemoglu等研究了金融网络结构与系统性金融风险间的关系[8]。而在微观层面金融风险预警研究比较少,而且集中于投资者的研究,如投资者注意力研究,如Da Z等研究证实注意力指数主要反映了个人投资者的注意力[9],Schroff等研究通过google搜索量实证分析出股票的信息需求与投机行为显著正相关[10];还有投资者行为研究,如Kraussl和Mirgorodskaya研究了媒体信息可以强化公众预期,从而引起投资者对互联网财经新闻及相关论坛的关注分析从而影响股市[11]。运用大数据的机器学习对股市影响的研究也比较多,如运用RESSET金融研究数据库,在大数据技术下分析市场的融资融券的买卖行为对股票市场影响,运用大数据机器学习实现人工智能与金融资产相结合的方法研究,这些研究大多数是对股市涨跌算法进行事后分析。[12-14]
而国内的学者运用大数据对金融风险的研究也非常多,主要集中在统计学结合计算机技术应用于金融行业的研究,也有对个股案例进行详细的指标分析和建立预测模型。影响较大的研究证实了未定权益分析(Contingent Claims Analysis,CCA)的风险指标对我国系统性金融风险预警具有较好的适用性,为我国金融风险测度提供了良好的理论研究基础[15-17],李志辉等根据风险相依性,进行了扩展研究,实现了CCA方法的优化[18]。金融风险预测方面更多是运用大数据技术建立预测模型,通过股市历史数据进行实证分析。如讨论将 Markov链过程理论应用于股票交易市场对股价综合指数的分析预测模型,探讨大数据的时代背景下应如何正确地进行股票投资,从大数据、机器学习和行为金融学的角度出发研究炒股行为生成的随机变量,并基于某只股票的历史数据运用相应的算法实现预测功能等。[19-21]还有一部分国内学者在研究用户参与金融市场并对其产生的影响,更倾向于研究投资者与财经新闻、网络论坛、微博等媒体关系,论证其能在较大程度上影响证券市场。[22-24]
综合已有研究可以发现,国内外基于大数据研究股票宏观市场走势并生成相应的预测模型的成果比较丰富,也有对个股走势分析和预测模型的微观层面研究,而对金融市场受相关参与者影响研究比较少。目前,我国大数据在各行各业的应用已初显成效,部分领域的应用已经处于全球领先地位,其中大数据与资本市场关系的研究亦是金融市场的研究热点。运用大数据建立用户参与预测模型对上市资本市场整体影响则基本空白,对于金融市场相关参与者包括企业家,消费者,网民(含移动网民,下同),投资者等的结构分析(年龄、收入、学历),行为分析,体量分析(网民、投资者),指数分析(企业家信心指数、消费者指数)等对股票市场的影响的研究仍然有待进一步深入,本课题以大数据源和用户参与行为为观测点,基于用户参与视角和大数据技术对金融风险的影响及预警系统的构建,设计用户参与评价体系和用户参与预测模型,预警系统可以有效降低金融风险,防范股票市场的大起大落对实体经济产生负面影响。
二、指标体系与模型构建
在有效市场假说下,金融市场风险信息体现在股票价格走势中,股票价格变动所包含的信息不仅有价值而且及时、准确,因此,可以围绕股价进行区域金融、金融机构等的风险实证研究。[25-28]在股市下降趋势时期(也称“熊市”)只要稍有风吹草动,A股市场的群体恐慌心理会不断降低投资者的投资信心,造成抛售压力增加,由此形成恶性循环的现象。金融风险分析在股市下降时期的预测效果都比较差,出现非理性行为时一般难以提前预警,传统研究注重各类风险指标、预测指标分析,对投资者及通讯现代化产物网民与股市走势的关系并不清楚。本研究通过数据爬虫技术采集数据源(网络大数据),选取样本范围从2000年到2018年,以全球GDP及增长率、中国A股上证指数(A股主板市场)、中国互联网网民结构、财经网站访问情况、投资者构成、企业家信心指数、消费者指数等为统计样本,采用统计学(借助工具SPSS)方法结合金融行为学分析金融市场相关参与方,并以此构建金融风险预警系统。
1.用户参与评价体系。在人类活动中,触发各类大型事件的往往是人为因素,而在利益面前,尤其是风险投资,人类的各类需求、思维、情绪、博弈等更是人类参与、触发事件的重要因素。在金融风险事件中,有政府层面、经济形势等因素,但大众参与也是触发系统风险的主要成份。在金融资产评估及资本市场交易过程中,尽管已经出现自动交易软件,但核心仍然是人类,因此用户参与者评价体系研究是围绕网民、投资者、企业家、消费者等多个维度构建的。2005年网民和投资者数量已经超过1个亿,且每年保持在10%以上的增长率,而到2018年投资者(实际持有金融资产,不计开空户)仍然未超过1个亿,网民的影响力远超投资者。大数据对金融学研究的影响通常是多方面的,次要用户企业家、消费者等相关指数在一定程度上反应了金融市场的投资回报与风险预期。首先综合分析相关影响因素,再建立一定的评价体系,然后对其指标进行赋权,本研究的用户参与评价体系建立步骤:
(1)相关性分析:通过中国A股上证指数走势、交易量、振幅变化与用户量级、用户结构、用户行为进行相关性分析、多层次分析。
(2)评价指标的确定:先通过用户量与A股市场交易量、振幅等关系指标分析,再以用户性别、年龄、学历结构选取影响资本市场交易的指标,然后根据用户在互联网及移动互联网的搜索引擎、网络新闻、微博、社交网站、网络炒股等横向行为,结合中国权威的东方财富网、同花顺、和讯等财经网站访问人次、有效浏览时间等纵向行为作为指标建立依据。最后依据网民、投资者的传播、情绪、预测、赌博心理等建立用户风险指标,详细指标如表1和图1所示。
(3)获取及规范数据:运用网络爬虫技术(详见下文数据采集算法)采集用户参与评价体系各类指标数据材料,网民和投资者两个层面统计差距以及统计方法不一致等,还需要进行修正成可提供分析的规范数据,包括以下:
i.采集过程统计时段以日、周、月、季、半年及年度不一致
ii.统计开始、结束存在时间差
iii.部分采集数据的缺失
iv.统计结果的求累加或平均值需要人为判断
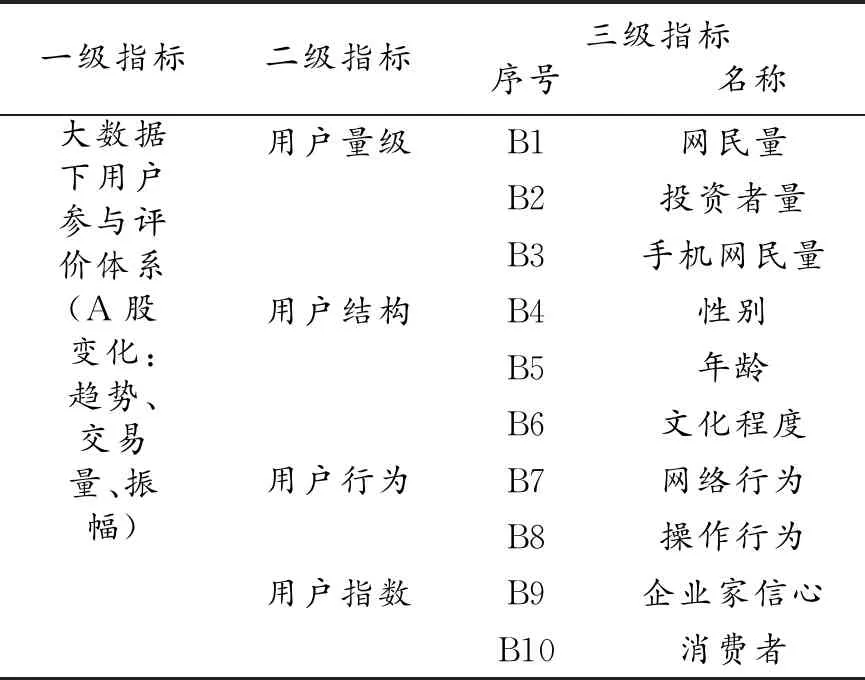
表1 用户参与评价体系指标
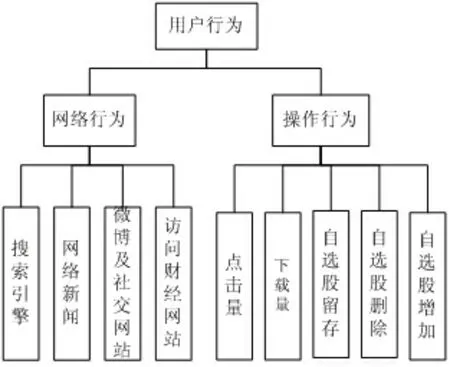
图1 用户行为框图
2.用户参与指标赋权。用户量级、用户结构、用户行为可以通过数据分析及统计软件初步确定其相关性分析,传播、情绪、预测、赌博心理等用户风险指标难以通过统计数据确定,则通过专家打分法确定权重,具体工作过程如下:
(1)通过方差(公式1)检验包括水平方差(公式2)、组内方差(公式2),根据数据的稳定性筛选不必要的分析指标,如用户的年龄变化趋势,表达公式如下:
(1)
(2)
式中n表示统计数据个数,μ表示n个统计数的平均数,σrow表示水平之间或不同组之间的方差,σcol表示同一水平之内或同组之内的方差。
(2)用“数据说话”,根据三级指标的数量与一级指标之间的关系,以2000年至2017年之间的数据进行单位间隔中所出现的频率或数量,并不断累加,根据数据分布图(散点图)结合matlab软件推导出符合数据与指标之间的函数关系,数据拟合后会出现高次多项式函数,然而这种函数不利于图形的检验,也不容易得出数据之间是正相关还是负相关,因此还需要进行修正和趋势模拟为低次少项式函数,具体操作步骤如下:
i.Matlab一次函数: polyfit(xdata,ydata,1),xdata、ydata分别表示三级、一级指标的数据(以数组形式按时间顺序成对出现)
ii.计算和方差精度(precision,p):即拟合数据和原始数据对应点的误差的平方和,本研究假定误差平方和精度范围在0.1之内,公式如下:
(3)

(3)根据统计数据把用户行为作为中介变量,由用户量级和用户结构形成用户行为的影响基础,而用户行为系最为直接产生用户风险的指标,以此建立用户参与评价体系影响路径(如图2所示),用户参与评价体系与用户参与评价体系影响路径将作为用户参与模型的建立基础。
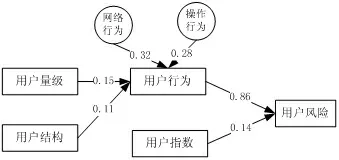
图2 用户参与评价体系影响路径分析
3.用户参与预警模型。在用户参与评价体系基础上,根据用户参与影响路径分析,建立大数据用户参与模型,旨在通过用户体量影响、用户结构各类数据分析及用户群体行为,一方面,减少大数据下用户非理性传播、情绪化行为、预测不科学、赌博心理等风险;另一方面,模型通过机器学习算法提供波动预测、趋势预测、行为预测等,以期降低剧烈波动的概率,具体模型如图3所示。

图3 大数据用户参与模型
三、预警系统设计
金融风险预警系统的功能包括了数据采集系统、数据库系统、预警系统,整个系统的设计围绕“数据说话”,运用数据挖掘技术建立有价值的数据库,再通过机器学习算法设计预警跟踪和偏离纠正等,全过程中以数据为中心,具体基于大数据的金融风险预警系统框架如图4所示。
1.系统功能。
(1)采集系统:因金融风险预警系统相关指标
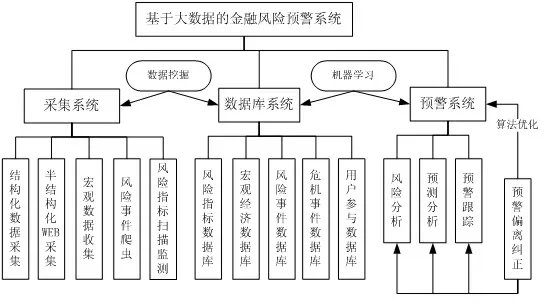
图4 大数据下金融风险预警系统框架
数据包括了非结构化数据,而这部分数据在互联网上内容采集、清洗及分析难度较大,且经常需要人为干预,因此需要结合爬虫技术、扫描监测技术以比较全面地获取金融风险数据和相关事件的数据信息,采集系统的基础数据是预警系统的依据,其对金融风险预测准确性有相当大的影响。
(2)数据库系统:通过采集系统获得的数据,仍然需要进一步分析,不仅需要数据挖掘技术的支持,还要有大数据分析的手段。数据库系统是预警系统的核心,预警模型的相关指标数据分类和汇总都在数据库系统中完成,数据库系统完善程度直接影响机器学习的预测能力。
(3)预警系统:预警报告主要以指标临界值和预警区间的方式展示出来,在确定的风险分析和预测分析后,形成预警报告。同时,预警系统是否与实际相符,还需要进行实证跟踪,对预测的结果偏差分析原因,并改进相关的算法以提升机器学习系统的预测功能,缩小后续的预测差距,提升预警系统的准确性和科学性。
2.系统流程。在各大知名财经网站中含有上市公司丰富多样而且呈一定规格化的数据,为数据爬虫采集、归类提供了方便,数据有效性非常高,对数据库优化有着十分重要的意义。另外规范的数据来源也依赖于采集源的数据结构,如同花顺(目前在中国系比较权威的财经数据来源,且提供了大数据服务,有免费也有收费项目),根据研究分析需要将采集到的数据进行关联性分析,设计相应实体及实体关联,整合成可用规范的数据库(可供分析的基础数据)。在规范的数据库上面进行数据挖掘建模,分析财经数据和用户参与相关影响,并经一定的修正形成具有商业价值的数据库(可提供分析报告、商业解决方案),在数据建模过程中不断优化数据库,供更深层次的数据分析,具体数据采集、建模、分析过程框架如图5所示。

图5 数据采集及分析框图
这些海量的财经数据采集需要借助工具分析用户参与预测模型有用的信息及影响因素,然后在有效数据基础上建模,其中复杂数据分析可以使用数据挖掘、机器学习等算法,如采用Spark算法对采集的数据进行归类、预测、逻辑回归等。
3.相关算法。从中国证券登记结算有限公司、知名财经网站(163、sina)上筛选要爬虫的位置,如在163中明确财经站点地图,建立爬虫目标URL集合,然后逐个分析URL对应的DOM结构(节点组成,也称标签列表),形成对应的DOM树。因本研究采集网站集中度很高,且同一网站下的DOM结构基本一致,这给DOM树的创建带来很大的方便,假设要抓取某网站的n个URL,每个URL对应m个DOM结构(标签为成对出现),则通过双循环可以完成某网站的DOM结构遍历即2m-1×n,建理想效率如(4)式所示。
(4)
式中,domij表示DOM树所有边的操作数。
在Python编程中,为了方便机器解析和生成,采用JSON(JavaScript Object Notation),具体算法程序如下:
import requests
import re
import json #轻量级的数据交换格式,易于编写
def run(self):#实现主要逻辑
#1.循环提取url
for url in url_list:
#2.发送请求,获取响应
html_str = self.parse_url(self.url)
#3.提取数据
for dom in dom_list:
dict_response = json.loads(html_str)
#根据不同的DOM结构获取不同节点的数据
content_list = [i[“group”][‘text’] for i in dict_response[“data”][“data”]]
test= dict_response[“data”][“main_content”]
#4.保存
self.save(content_list)
#5.获取下一页的url ,回到下一循环
然而,在实际数据爬虫过程中,同一网站中并非各DOM结构都一致,因此需要对每个URL建立不同的DOM结构以保证程序抓取的有效性。
4.相关实现。本研究宏观数据采集后,分析建立在庞晓波和王克达[19]研究的全球各国和各地区传染力分类基础上,并取2000年至2018年间GDP及增长率进行参照,剥离了中国香港、中国澳门、安道尔、巴勒斯坦等数据,并修正俄罗斯、沙特、刚果(布)、阿联酋、波黑、孟加拉、科特迪瓦、多米尼克、拉脱维亚、塞尔维亚、马其顿、也门等国家名称与全球宏观数据名称不匹配现象,通过构建宏观数据库可以比较清晰地查看相关宏观指数,实现效果如图6所示。
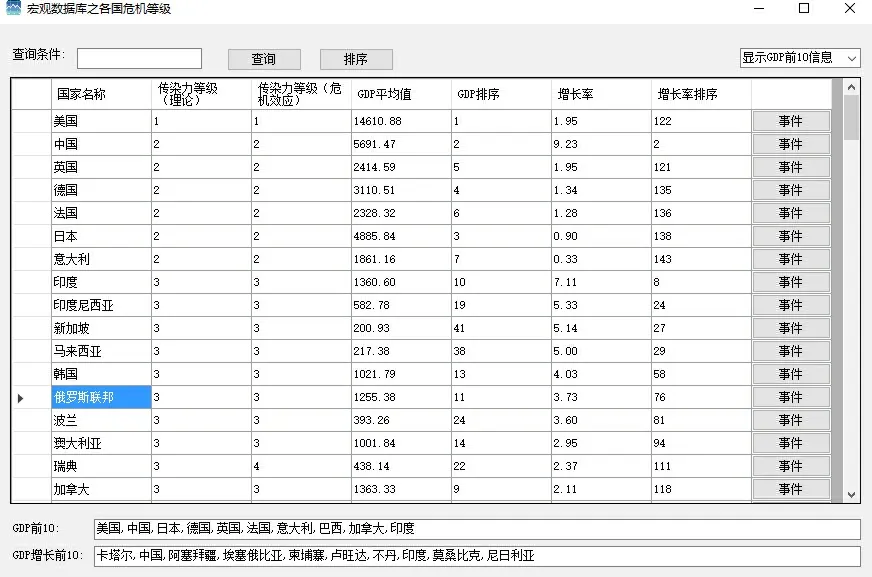
图6 宏观数据库效果图
突发事件确实存在对金融市场正面或负面的影响,事件的影响力大小一方面是指事件本身的重要性,另一方面则是用户参与如何影响事件及事件的传播。由于用户量巨大,用户影响力增加,在baidu和google指数中可以观测到事件的关注度,从国际事件到国内市场的宏观影响以及股票中重大资讯(并购重组等)的个股影响,已经可以证明这些事件的传播反馈到金融市场与用户参与行为有很强的相关性。因此,各国尤其是传染力等级为1和2的国家,对金融相关事件的采集及baidu和google指数进行跟踪,从而划分事件等级,形成有效的危机数据库,这对金融预警系统有着重要的数据支撑作用,同时这也适用于相关股票的重大资讯(主要运用于风险提示数据库)。
四、系统数据效果分析
据互联网发展报告显示,我国网民规模发展十分迅速, 2018年已经接近8个亿,互联网普及率也从不到3%发展到接近60%,同时由于智能手机、3G、4G等通讯技术飞速发展,手机网民也从2006年(受统计数据限制,2006年之前没有相关数据统计)的1300万迅速扩展到7.5亿(2017年12月),其中2007年到2012年每年增长同比均超过100%。与此同时,据中登公布数据,参与A股投资者2000年为6154万(同年增加的投资者为1343万),2002年因大量不规范账户清理,年末投资者数为6841万,到2018年已经达到13863万(开户数已经超过1.7亿,部分开户非有效投资者)。以投资者数和网民数量(含手机网民)两个视角看,用户参与数量庞大,投资者、网民的行为都会产生大量数据,而且网民的查阅和转载、传播行为大大增速,基于大数据的用户参与结构分析、关注度、情绪反应等群体行为对A股上证指数有着重大影响。
1.数据说明。大数据时代下金融风险预警系统所需要的支撑数据比较集中于财经类网站和互联网相关统计数据,为了提升基础数据的有效性和降低数据分析的复杂度,我们采集的数据均来自比较权威的网站和规范的数据库,因此采集方式也比较简便,主要数据来源以及采集方式如表2所示,下文中数据来源均引自表2,不再注明引用来源。

表2 采集数据源及方式
(1)数据接口:同花顺iFinD因其具有商业性质提供了很好的数据接口,北京广銮轩数据科技公司提供了大数据集和数据描述都可以很方便地进行数据导出,然后将所需要的数据根据数据库的模式匹配整理成规范的数据库。
(2)网络爬虫:在数据挖掘过程中,仍然有许多数据是无法通过规范的数据接口完成的,因此在基础数据采集过程中仍然需要在互联网上采集所需财经数据,如中国证券登记结算有限公司网站提供的投资者统计的情况,以及知名的财经网站,这些网站的网页格式也比较规范,采集难度不高,具体采集算法参看下文的算法说明。
2.宏观指数统计及分析算法。宏观分析采用A股主板市场上证指数(因为创业板更不成熟,涨跌幅过大,分析容易出现偏差),采集样本从1999年至2018年,A股上证指数获取分析信息有收盘价、最高价、最低价、开盘价、前收盘、涨跌额、涨跌幅、成交量、成交金额等。A股(上证指数)指标统计过程如表3所示,其中年度统计时以当年第一个交易日至当年最后一个交易日(除2018年外)为统计期间,统计结果如表4所示。
根据不同指标之间的数量关系形成大数据训练集,以A股(上证指数)指标为ydata(不同区间振幅及成交量),导入不同组的指标数据xdata(包括用户量、用户结构、用户行为等),然后计算出每组指标之间的拟合曲线,提供数据规律进行基础分析,具体算法过程如图7所示。
3.用户网络行为结果分析。因为用户的搜索引擎、网络新闻、微博、社交网站、网络炒股等相关行为数据在采集过程中由于数据源停止采集或数据源不规范而出现部分缺失,本研究使用简单的移动平均法,对其缺失数据进行预测补充(其中前值未采集的信息则不作补充),预测值pv公式如(5)式所示。

表3 A股(上证指数)指标统计过程
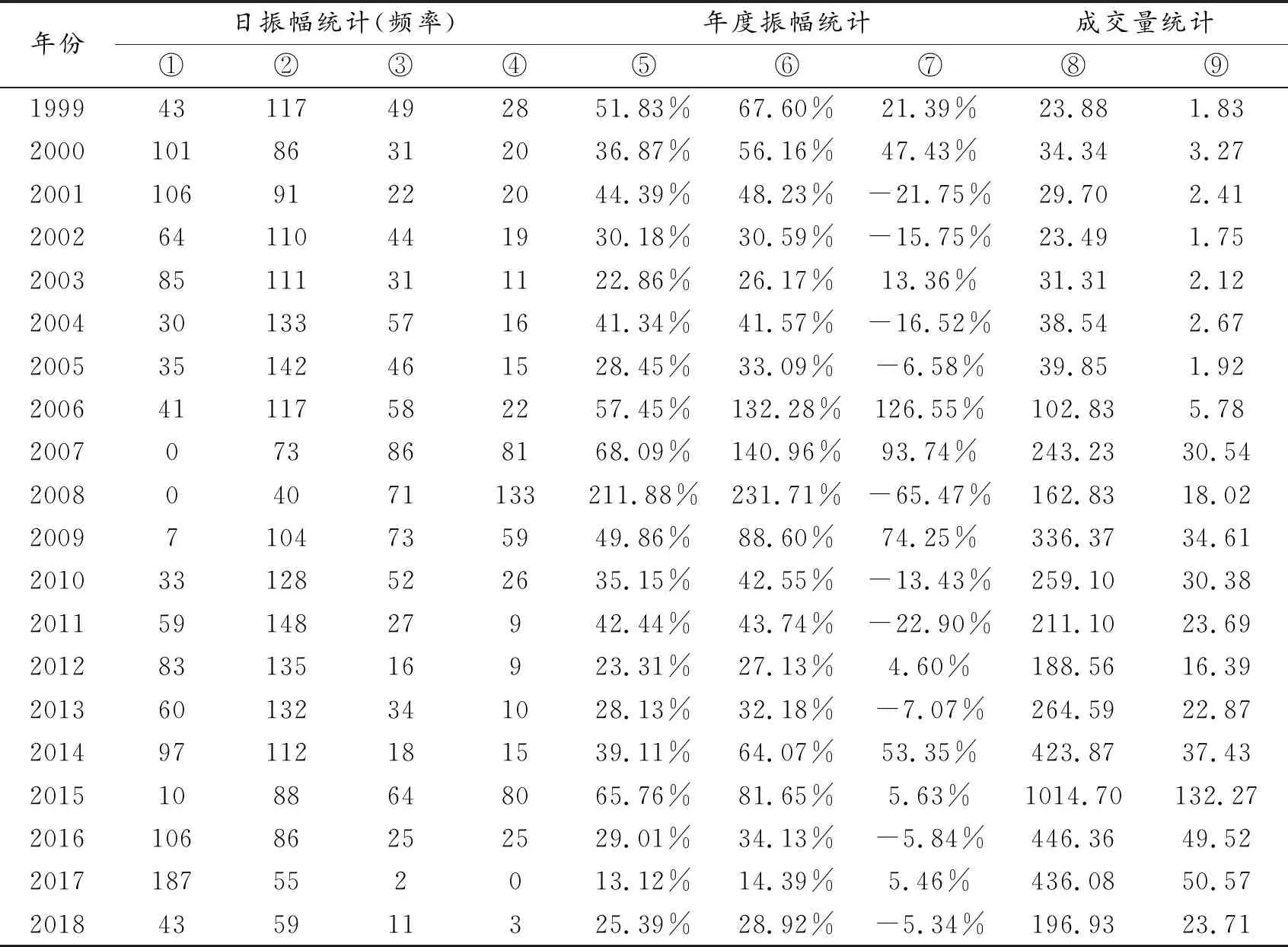
表4 A股(上证指数)指标统计结果
(5)
式中,An表示前期实际值,n表示统计的实际值个数。
观测网民的相关行为能够发现网民行为对投资的影响,其中网络炒股比例是以网络炒股人次在当年网民规模中的比例计算,具体统计及计算结果如表5所示,从统计数据上看搜索引擎、网络新闻是网民的重要行为。在2016、2017连续两年的互联网发展报告中,手机网民(也称“移动网民”)通过手机搜索、手机查看网络新闻等使用率均超过80%,截至2017年12月,手机搜索、手机查看网络新闻等使用率分别为82.9%、82.3%,手机以其便携性、易操作性将更迅速地影响网民行为。部分研究采用股票的点击量、自选股(添加、删除、留存等)进行用户行为分析及区间分析。
在用户相关行为中,以网民查看财经信息展开采集(从2009年开始,截止日期为2018年3月),在采集结果基础上以年度平均访问为统计准则,网民财经网站访问情况如表6所示。通过访问财经网站的相关行为分析,结合资本市场(上涨和下跌)观测其行为,2015年处于大幅振荡(上半年大幅上涨和下半年大幅下跌),网民在财经网站上的访问量大大增加。
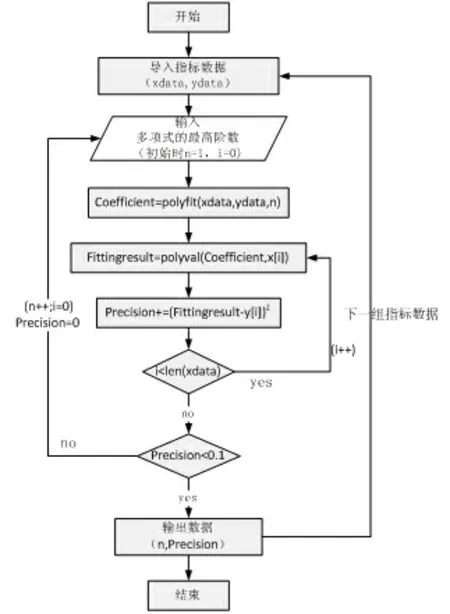
图7 不同指标数据与A股(上证指数)的拟合过程
4.用户参与模型相关性分析检验。在用户参与模型中各指标之间的数量关系根据年度变化具有连续变量之间的相关性,因此,本研究使用积差相关系数(也称Pearson系数),该系数可以比较直观地筛选出相关高的指标,并从高相关指标中再深入分析,用于验证模型的预测功能,具体计算公式如(6)式所示。
(6)
式中,x,y即为用户参与模型中不同指标,y同上ydata取以A股(上证指数)指标(不同区间振幅及成交量)数据,r表示两两指标之间的相关性,指标筛选依据如表7所示。因为指标中部分数据采集缺失,故在年度统计中,以比较齐全的数据区间(2000年至2016年)进行相关性分析,获得高度相关的分析结果(因文章篇幅有限,显著相关结果略)。
五、结 语
1.从用户年龄统计上看各年龄段的趋势变化不明显,但30岁以下不成熟的网民、投资者占比非常大,这个群体极易被网络媒体等信息影响,甚至误导,然后传播不当的信息,从而更容易导致信息偏差和市场振动。
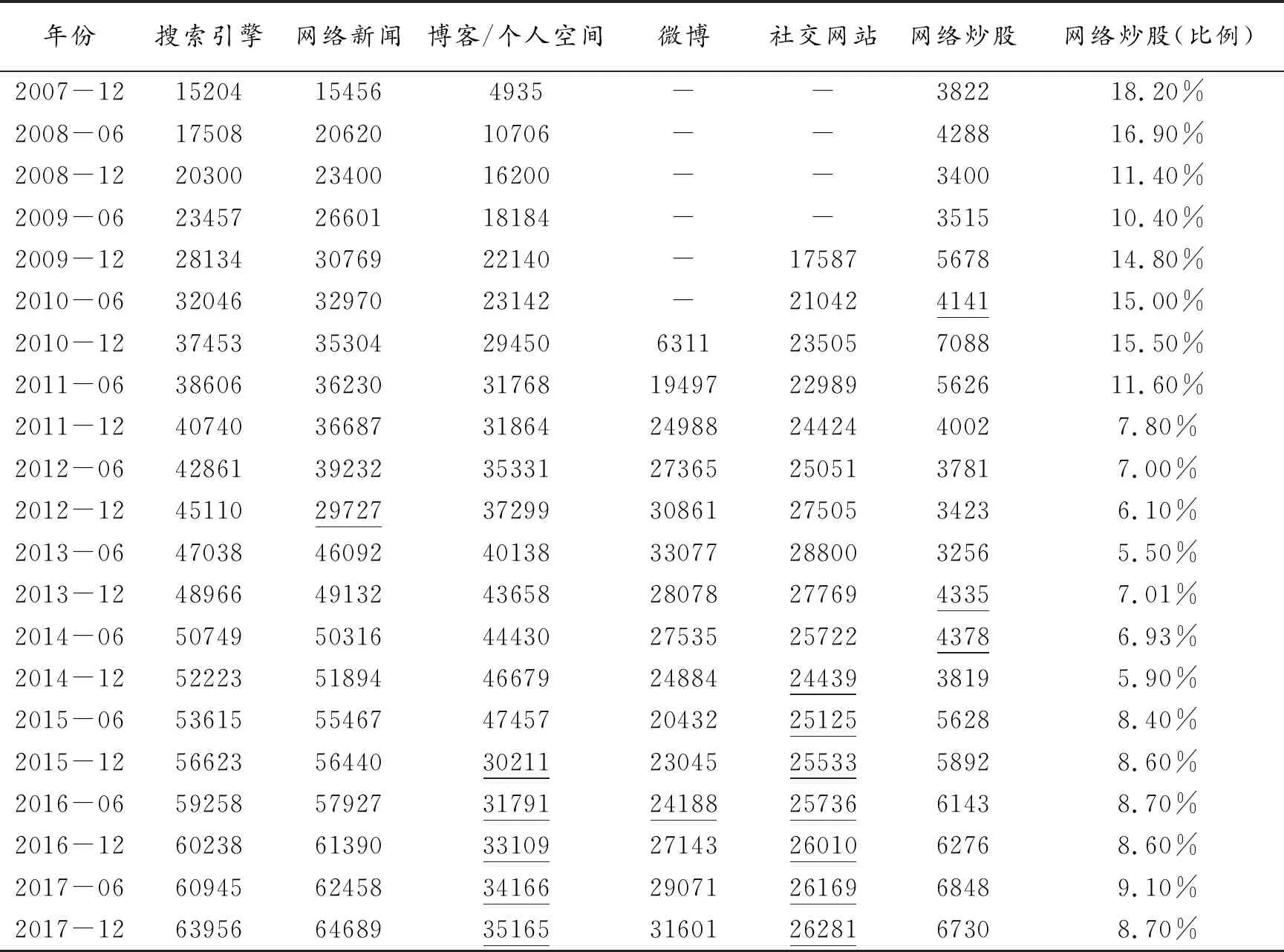
表5 网民网络应用使用情况统计(2007—2017年) 单位:万人
注:下划线为采集缺失数据,通过移动平均计算所得。
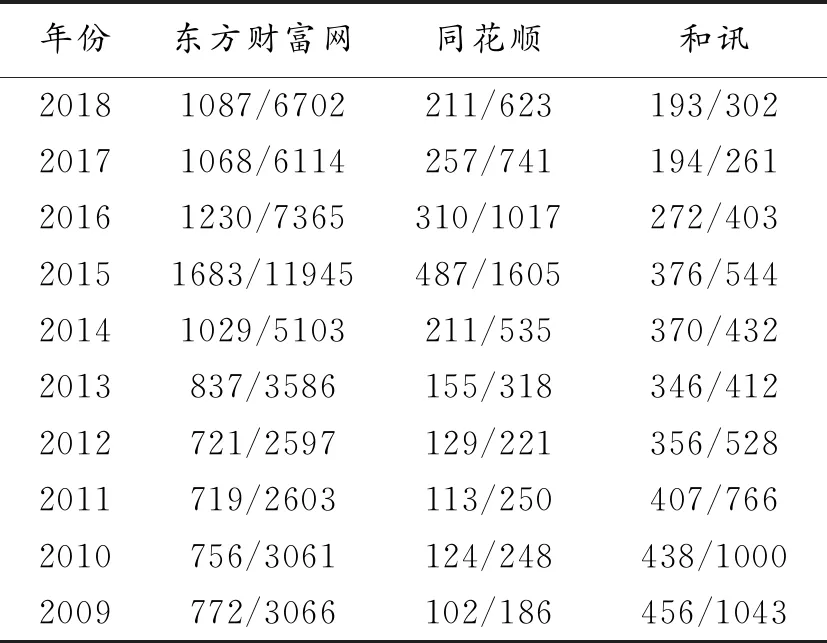
表6 网民财经网站访问情况(2009—2018年)单位:万人/万小时

表7 指标筛选依据
2.从学历上看,各学历层次的比例不稳定,投资者往高学历增长,低学历层次占比不断下降,而高学历对股市的影响主要有两方面:一是研究更为细致、查找资料更为有效、投资更为谨慎,二是投资手段更为科学,大数据、自动交易软件等技术手段应用率不断提升。
3.从用户行为分析结果,金融事件与股市波动(振幅)有着强相关性,尤其是负面信息在下跌趋势中其振幅会随着金融事件的蔓延而不断增大,用户产生的搜索指数也随之扩大。
显然,政治、金融、军事、疫情等各类事件在各国传染等级不一样,影响力的区别主要在于用户参与该事件传播导致风险传染等重大因素。因此,就各类金融事件在一定时间内对用户参与关注度的适度引导,可以有效控制和防止金融风险的发生和扩大。
