基于深度学习的异常事件检测研究综述
2020-05-24符祖峰王德红郑维鑫
符祖峰 刘 松 王德红 牟 珍 郑维鑫
(1、2、4、5.安顺学院电子与信息工程学院,贵州 安顺561000)(3.《安顺学院学报》编辑部,贵州 安顺561000)
传统的异常检测方法主要分为两类:局部特征建模方法和全局特征建模方法。局部特征建模方法基于局部视觉特征的模型来表示事件,并基于统计、词袋、稀疏表示、特征学习等技术来检测异常。在文献[1]中提出了一个用于描述异常活动检测的统计模型。这个模型主要考虑在高维空间中观测到的特征。假设正常行为特征的概率分布密度函数为g0(·),异常行为特征的概率分布密度函数为g1(·)。则异常行为检测就可以看成预测一个实例服从的概率密度函数是g0(·)还是g1(·)。但是这些分布通常是未知的,即使给出了训练数据也很难估算出来。同时带标签数据的不足、异常行为的多样性、背景的多变性给检测带来很多的困难。文献[2]提出了基于局部时空特征的多尺度的非参数化的异常行为检测方法,直接计算多尺度局部特征的统计信息。非参数化方法不依赖于从训练数据中学习到的基于运动和外观特征的参数模型,而是直接用时空描述符来表达场景的正常程度。文献[3]提出了稀疏组合学习框架用于异常行为检测,将原来的复杂问题转化为小规模的最小二乘优化问题。文献[4]使用支持向量机进行异常检测,用最大子序列搜索方法进行异常定位。文献[5]提出了基于时空信息表示图像纹理的人群异常检测算法,用低层次的统计特征来避免复杂的机器学习和识别过程。文献[6]利用光流特征和前景占用特征从单元结构中提取压缩的描述性特征,通过高斯混合模型来评估压缩特征集,用马尔科夫链和词袋方法来检测异常事件。
全局特征建模方法将视频中的实体作为一个整体,常基于密度、轨迹等整体特征进行异常检测。文献[7]提出基于整体特征和密度的人群异常检测方法,从人群冲突、集体性、运动速度、密度四个维度提出了场景层面的整体特征。运动不稳定性在文献[8]中被用于无监督的识别异常事件。文献[9]提出结合运动矢量用运动金字塔来对视频帧进行分层处理。这种分层处理方法减少了计算开销,从而实现实时的异常检测。文献[10]通过计算运动矢量的空间导数,利用假设检验技术检测密集人群中的恐慌行为。文献[11]建立了一种时空运动分析方法,通过评估帧上运动加速度的一致性来检测异常事件。文献[12]基于显著时空特征和稀疏组合学习,将时空梯度模型与前景检测相结合,实现了异常行为的自动检测和识别。
深度学习技术在异常事件检测中已经有了一定的研究成果,但整个研究尚处于起步阶段。本文将从评价指标、常见的神经网络模型、检测框架和基准数据集四个方面进行详细的介绍。
1 异常检测评价指标
人群异常检测是指在室内或室外环境中基于视频检测人群是否出现异常事件。检测的异常事件分为暴力性的和非暴力性的。暴力性的异常事件有群殴、踩踏、聚集、奔跑、恐慌逃散等。非暴力性的事件有跌倒、徘徊、围观、静坐等。检测的目标可以是个体也可以是群体。
异常检测使用的性能包括真阳性率、假阳性率、精确率、召回率、检测速度等。令TP是正样本中被预测正确的数量,TN是正样本中被漏报的数量;FP是负样本被误报的数量,FN是负样本中被预测正确的数量。
真阳性率(True Positive Rate, TPR)
TPR = TP / (TP +FN).
假阳性率(False Positive Rate, FPR)
FPR = FP / (FP + TN).
精确率(Precision, P)
P = TP / (TP + FP).
召回率(Recall, R)
R = TP / (TP + FN).
帧每秒(Frames per second, FPS),表示算法的处理速度。
ROC(Receiver Operating Characteristic)曲线
ROC曲线是一个二维图形,其横轴表示假阳性率,纵轴表示真阳性率。这种曲线能够可视化的比较各种检测方法的性能。在异常行为检测中,它用于显示检测方法对真阳性与假阳性之间的性能权衡。
ROC线下面积(AUC)
AUC是指ROC曲线下与坐标轴之间的面积,是衡量检测算法优劣的一种性能指标。当AUC=1时,对应的分类算法成为完美分类器。
等错误率(Equal Error rate, EER)
等错误率是指在ROC曲线中错分正负样本概率相等的点,也就是ROC曲线与[1,0]-[0,1]连线的交点,用来衡量算法的平均错误率。
等检测率(Equal Detection Rate, EDR)
等检测率是指在等错误率下对应的检出率(Detection Rate,DR)。
2 基本的神经网络模型
2.1 常见的网络结构
目前已有多种深度神经网络结构用于检测异常行为,如卷积神经网络(CNN)[13]、长短时记忆网络(LSTM)[14]、自编码器(AE)[15]和生成对抗网络(GANs)[16]。
(1)卷积神经网络
卷积神经网络已成为深度学习中最常见的网络结构。改变网络的深度和广度,就可以调整模型的能力,使之更具泛化性。在很多问题上卷积神经网络都获得很好的效果,主要是因为它的设计是基于图像的本质上一些强有力且基本正确的假设,如统计结果的稳定性和像素依赖的局部性。在卷积神经网络中,每一个卷积核可以看成某一种特征的探测器。越是高层的卷积核所提取的特征就越抽象,隐含的语义就越丰富。为了解决具体的问题,卷积神经网络已经出现了很多变种,如2维卷积和3维卷积已经被用于处理视频信息。
(2)长短时记忆网络
与卷积神经网络相比,递归神经网络(RNN)更擅长处理序列数据,能让每一步的计算都利用以前的信息,在自然语言处理中取得了巨大的成功。但是,一般的递归神经网络无法处理长期依赖[17]。为了解决这个问题,长短时记忆网络被设计出来。这种网络模型属于递归神经网络,但通过添加一些逻辑门,显式地允许递归神经网络学习何时使用“忘记门”忘记以前的隐藏状态,以及何时根据新的输入更新隐藏状态。文献[18]提出了基于时空的长短时记忆网络(Temporal and Spatial LSTM, TS-LSTM)。文献[19]提出了基于注意力的长短时记忆网络(Residual Attention-based LSTM, Res-ATT),解决了分层长短时记忆网络的退化问题。
(3)生成对抗网络
生成对抗网络具有两个不同的网络,一个命名为生成器,另一个命名为判别器。在训练期间,生成器的目标是随机生成尽可能真实的实例使得能够骗过判别器,判别器的目标是尽可能判断准确从而不被生成器欺骗。通过对抗学习,生成器能够生成非常接近真实数据的新数据,从而使得生成对抗网络能够在没有外界监督的情况下获得一个很好的信息重建能力。其中内部监督信息是依靠生成器和判别器相互博弈来获取的。
带条件的生成对抗网络(conditional GANs)[16]学到了有附加条件的数据生成模型,被用于解决图像到图像的翻译转换问题[20]。带各种条件的生成对抗网络也已经被设计出来,如深度卷积生成对抗网络(Deep Convolutional Gans)、循环一致生成对抗网络(Cycle-Consistent Adversarial Networks)等。
(4)自动编码器
大多数的异常检测方法都基于自编码器。自编码器能够通过无监督学习,对原始数据进行重构,从而学到输入数据的高效表示,网络结构如图1所示。
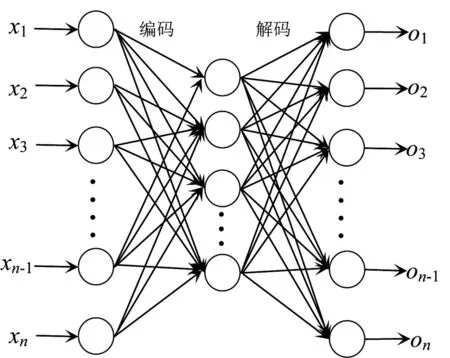
图1 自编码器的结构示意图
自编码器的重构误差为
其中xi对应于原始数据,oi对应于重构的输出。自编码器通过极小化重构误差来学习数据的统计特征。为了应对各种实际任务,自编码器出现了很多变种。在重构误差中增加针对隐藏层参数的惩罚项使得自编码器的参数稀疏。这样的自编码器被称为稀疏自编码器(Sparse AE,SAE),常用来处理迁移学习问题。去噪自编码器(Denoising AE, DAE)是自编码器的随机增强版,在输入端增加了随机腐蚀层,腐蚀样本常用白噪声或椒盐噪声。将多个去噪自编码器联接起来,形成一个深度框架,就变成了栈式去噪自编码器(Stacked denoising AE, SDAE),常被用于学习视频数据的外观和运动特征表示。为了加快运算速度,使用单层的自编码器的边缘栈式去噪自编码器(Marginalized Denoising AE, MDA)被提出,在计算速度和性能之间作了一个平衡。
2.2 预训练的深度神经网络模型
深度神经网络的训练是耗时的,利用预训练的网络模型进行迁移学习是加速网络训练的常用手段。经常被使用的预训练网络模型有AlexNet、ZFNet、VGGNET、Fast-rcnn等。
(1)AlexNet
AlexNet[13]是一个深度卷积神经网络,在2010年的ImageNet竞赛中获得了图像分类大赛的第一名。这个网络有5个卷积层、最大池化层、3个全连接层,有650000个神经元和6000万个参数,能够实现1000类的图像分类。AlexNet网络用ReLU函数作为激活函数,用局部归一化方法增强泛化能力,并用数据扩张和辍学机制(dropout)减少过拟合的出现。基于在图像分类问题上的成功,训练好的AlexNET常被用于作为一个部件,组合到其他的网络结构中实现迁移学习。ZFNet是AlexNet的修改版,使用特征可视化技术对网络结构进行了优化,在2014年ImageNet竞赛中获得了很好的成绩。
(2)VGGNet
VGGnet[21]是2014年ImageNet竞赛的第二名,因具有很好的可迁移性而备受关注。该网络模型使用具有非常小的接受域的卷积核,如3×3的卷积核刚好可以捕捉上/下/左/右/中的信息,1×1的卷积核被看成是一种线性变换。整个网络结构是多个卷积层堆叠后接入三个全连接层,最后用Softmax层来实现1000类的图像分类。常见的VGGNet是16层卷积层加上3层的全连接层,具有14400万个参数。
(3)Fast-rcnn
Fast-rcnn[22]网络将卷积神经网络用于目标检测,极大的提高了检测速度。该网络首先用卷积神经网络来提取图像特征,再借助筛选过的Region Proposals使用Roi pooling层抽取里面的特征,同时使用金字塔池化方法来应对不同尺度的目标,最后用Roi Network进行分类判断和边框回归。
3 检测框架
传统的异常检测方法依赖于手工提取的特征,并根据这些特征来设计分类算法实现异常事件的识别。算法的优劣取决于特征提取算法和分类算法的性能。基于深度学习的异常检测使用深度神经网络实现特征的自动提取、自动选择有用的特征、自动利用特征进行识别,基本上实现了端到端的识别与检测。传统方法和深度学习方法的不同如图2所示。基于深度学习的异常检测方法可以分为四种模型:时间规律模型、时空模型、表示学习模型、生成模型。

图2 传统方法与深度学习算法对比
3.1 时间规律模型
该模型侧重于评估卷积神经网络提取的特征随时间的变化,采用类似于二值分类器的分类方法对连续视频帧进行迭代区分,从而实现在视频中捕捉异常信息。文献[20]提出了时间卷积网络,用二值量化层作为卷积神经网络的最后一层,来表达时间运动模式。为了维护相邻帧的局部信息,文献[23]使用栈式递归神经网络(Stacked RNN)实现时间连续的稀疏编码,采用浅层结构加快了异常行为的识别速度。基于稀疏编码进行异常行为检测,让正常行为对应一个较小的重构误差,发生异常时出现较大的重构误差。
3.2 时空模型
时空模型的灵感来自于从视频获得的显著性信息。通过从帧的显著性区域获取空间信息,用多尺度直方图光流来获取运动的时间信息,实现了异常事件的检测。文献[24]首次使用时空卷积神经网络进行异常检测和定位。文献[25]将一个多尺度的Fast-rcnn网络与环境特异性异常检测相结合实现异常检测与计数。文献[26]为了对视频中实体的速度和方向进行建模,将光流特征输入到卷积神经网络,结合支持向量机实现了端到端的异常检测。
3.3 表示学习模型
文献[27]使用深度缓增特征分析网络对视频进行高层次的抽象后实现异常事件识别。全局异常检测采用时间建模方法,局部异常检测采用基于差的平方和的多尺度分析方法。这种方法不依赖于任何分类器,也不使用手工制作的特性表示。文献[28]提出了基于回归的深度度量学习方法,不仅可以基于特征提取密度,还可以实现更好的距离测量,可以被用于异常行为检测。
3.4 生成模型
全卷积神经网络首次在[29]中被用于异常检测。这种方法使用预训练的AlexNet网络提取特征,用稀疏自编码器来表示特征,用高斯模型来检测异常。文献[30]提出了竞争级联的深度神经网络,它组合了栈式自编码器和卷积神经网络。为了实现高效的时间异常检测,利用级联神经网络的浅层特征来检测背景简单的图片碎片,而深层特征用来检测其他复杂的图片碎片。文献[31]用三个堆叠去噪自编码器来学习外观和运动的联合表示,并用支持向量机对异常进行评分。为了解决缺乏异常真实数据和异常的模糊性等问题,对抗生成网络被用于异常检测[32]。在这种框架下,多通道的表示形式用于外观和运动信息的融合。
4 基准数据集
为了更好地验证各种检测方法的效果,需要在公开数据集上做对比实验。目前常用的用于异常检测的基准数据集有UMN数据集、USCSD数据集、PETS数据集、Subway数据集、Avenue数据集、Train数据集、ScenicSpot数据集。
(1)UMN数据集
UMN数据集是明尼苏达州大学搜集的一个数据集,其中包含11个正常和异常的人群视频,分别在草坪、广场和室内三个不同的场景中。每个视频都有一个正常行为的初始阶段,并以一系列异常行为结束。行人四处走动的场景认为是正常样本,模拟人们奔跑的恐慌场景被视为异常样本。数据集的图像分辨率为240×320。
(2)UCSD数据集[33]
UCSD行人数据集是用静态摄像机以每秒10帧的速度捕捉不同的拥挤场景和异常情况,人群密度从稀疏到极度拥挤变化很大。整个数据集分为两个子集Ped1和Ped2。Ped1有34个训练序列和16个测试序列,约有3400个异常帧和5500个正常帧,图像分辨率为238×158像素。Ped2有16个训练和12个测试图像序列,约有1652个异常帧和346个正常帧,图像分辨率为360×240像素。训练数据集只包含由行人组成的正常视频事件。异常事件以非行人或异常运动模式为特征。
(3)PETS数据集
PETS数据集常被用于行为识别、跟踪等任务。该数据集包含两种不同的异常事件场景。在第一个场景中,正常事件被定义为朝不同方向行走的人,而异常事件被定义为朝同一方向聚集并向前行走的人。在第二个场景中,正常事件定义为在一个队列中行走的人,而异常事件定义为离开队列的人。由于视野和光照有明显的变化,行为检测具有一定的难度。
(4)Subway数据集[33]
Subway数据集对应两个不同的地铁站场景(入口和出口)监控视频。视频时长分别为96分钟(144,249帧)和43分钟(64,900帧)。在入口场景中,有66个不正常的事件,包括错误方向移动、人们不寻常的手势交互、突然停止或奔跑、逃票。在出口场景中包括19个异常事件,如错误方向移动和游荡。图像分辨率为512×384像素。该数据集存在异常数量少、空间可预测的不足。
(5)Avenue数据集[3]
Avenue数据集包含16个和21个分别用于训练和测试的视频。异常事件包括游荡、运行、抛出对象等。主要的挑战是轻微的相机抖动、训练视频中的一些异常值以及训练集部分正常模式缺失。
(6)Train数据集[34]
Train数据集主要是记录了在火车里走来走去的人,包含19218帧。异常事件主要是因人的异常动作造成。因动态光照变化和相机抖动问题,该数据集成为一个具有挑战性的异常事件检测数据集。
(7)ScenicSpot数据集[35]
ScenicSpot数据集是一个旅游视频数据集,包括18个视频剪辑(5964帧)。人的正常行走是正常事件。人群突然恐慌分散、快速运行、拥堵、踩踏、打架、乱扔东西是异常事件。
5 总结
异常检测一直是计算机视觉的研究热点,对提高室内和室外场所的安全性具有重要意义。本文从检测指标、基本网络模型、检测框架、基准数据集四个方面介绍了深度学习在异常检测方面的研究进展。虽然利用深度学习进行异常检测已经取得了显著的效果,但离解决实际问题还有很大的距离。基于深度学习的异常检测面临以下的挑战:
在实际问题中摄像机抖动、视频解码伪影、运动对象的遮挡、光照变化、尺度比例的变化、噪声等因素,给异常检测工作带来很大挑战。如何检测和改善相机状态、应对遮挡和各种变化、消除噪声影响等问题需要进一步的研究。
不同角度的观察会对异常行为的判断产生不同的结果。一个角度看是正常的,另一个角度看却是异常的。怎么利用多个角度的视频进行综合判断是一个极具挑战的工作。
深度学习经常面临的问题是被标定的训练数据不足。在异常检测活动中,往往缺乏足够的被标记的异常行为训练数据。设计更有效的策略进行无监督学习、利用上下文信息来进行异常检测,成为应对异常训练数据不足的一种手段。
异常检测研究领域是一个非常有前途的领域,因为它将作为未来许多基于计算机视觉的项目的基石,能够减轻对敏感地区持续监控的压力。将深度学习用于异常事件的实时检测仍有待深入研究。
