基于MapReduce的分治k均值聚类方法
2020-05-23臧艳辉席运江赵雪章
臧艳辉,席运江,赵雪章
(1.佛山职业技术学院 电子信息学院,广东 佛山 528137;2.华南理工大学 经济管理学院,广东 广州 510000)
0 引 言
Hadoop的MapReduce框架是大数据处理的最理想的框架[1]。数据聚类是数据挖掘和处理过程中最重要的任务之一。其中,k均值算法应用最为广泛,但其全局搜索能力较弱,随机性使得聚类结果可能陷入局部最优,对簇密度不均的数据集处理效果和并行处理能力较差。
针对k均值算法的不足,许多专家学者进行研究。其中,文献[2]对k均值算法在迭代计算过程中易产生内存泄漏做了进一步的优化。文献[3]采用多次随机采样的方式确定算法的k值,为聚类中心点个数选择提供了较好的解决方案。文献[4]研究了一种比例均衡的聚类算法,有效地提高类簇的聚类质量。为了克服原始k均值算法在Hadoop平台上需多次遍历数据集的问题,文献[5]提出了一种基于初始聚类中心点优化的选择算法,能够一次遍历所有数据集,减少了原算法的遍历时间,算法的加速比得到了提高。文献[6]提出了一种改进流式k-means算法,对能够克服随机性导致的聚类结果陷入局部最优缺点,但其并行处理能力有待提高。
为了解决上述问题,提出了一种基于MapReduce的单通道分治k均值聚类方法。本研究创新点总结如下:
(1)所提方法减少了聚类的时间和I/O的复杂性,设n为项目数,I为迭代次数,p为可用处理器数,则复杂度将由O(I·n/p) 降低为O(n/p)。
(2)分治k均值聚类法对最优k均值法解的近似结果为O(log2k),对结果的最优性给出了强有力的界限。
(3)考虑到结果的速度和质量,分治k均值聚类法优于k均值法和改进的k均值法。当机器数量或数据量增加时,分治k均值聚类法扩展性更好。
1 原始k均值法和改进的k均值方法
k均值法是一种非常经典的聚类算法[7-9]。许多研究者已经为并行架构提出了多个并行版本,而且为分布式系统提出了几个版本,但是基于MapReduce提出的工作却相对较少。在数据流聚类领域有一些相关的工作,研究人员试图在一次传递中聚集给定的数据集,还有研究者提出了几种用于流式数据的k均值变体[10]。这些解决方案能够在一次通过中聚集数据集,但它们都不具备固有的能力,可以在分布式系统中执行,尤其是MapReduce框架。
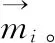
(1)每个簇应至少分配一个数据项,即:∀Ci∈C∶Ci≠∅;
(2)每两个不同的集群应该没有共同的数据项,即:∀Ci,Ci∈C∶Ci∩Cj=∅。
这些约束意味着硬分区和分区聚类。分配给群集的数据项应尽可能相似。因此,也应该定义相似性度量。使用最广泛的相似性度量是欧几里德距离的倒数[11]。任何两个d维数据项之间的欧氏距离可以使用以下等式计算
(1)
在此定义的另一个属性是群集的中心。群集的中心(质心)实际上是该群集中所有数据项的平均值。通常,为了在一组数据项上运行k均值法算法,能够计算每两对数据项之间的距离并计算一组数据项的中心是足够的[12]。可以使用以下公式计算群集的中心(质心)
(2)
在讨论分治k均值聚类法之前,有必要定义k均值法和改进的k均值法的原理。k均值法是一种简单而快速但有效的聚类算法[13]。算法1给出了具体程序。
算法1:k均值法
(1)procedurek-MEANS (M,k) ▶returns k centers
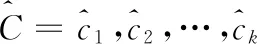
(3)repeat

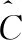

(7)endprocedure
理论上,重复k均值法的主循环,直到中心集合收敛并且没有变化。此过程也称为劳埃德算法。然而,在实践中较满意的结果可能需要多次迭代才能得到。因此,k均值法的主循环通常被限制为固定数。文献[11]提出了一种改进的k均值法,对k中心的初始化选择一组精心挑选的初始中心而不是随机初始化。如果假设D’(x) 是数据项x到已经选择的最近中心的距离,则改进的k均值法的初始化步骤可以定义为算法2。在其余部分,使用n作为数字数据集中的数据项,d表示每个数据项的大小(维度计数),k表示簇的数量。
算法2:改进的k均值算法中心初始化
(1)procedureimprovedk-Means (M,k) returns k centers as the initial seed
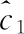
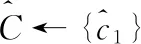
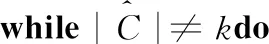
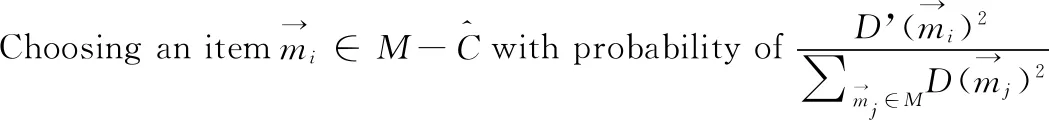

(7)endwhile

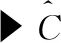
(9)endprocedure
2 提出的分治k均值聚类法
采取分治法处理大数据集,将整个数据集拆分为更小的块,这些块可以存储在每台机器的主存储器中,通过可用的机器传播,数据集的每个块由其分配的机器独立地聚类。块能够完全并行处理,从每个块中提取一些中间中心,从块中提取的中间中心集可以安装到单个机器主存储器中的更小数据集,并且从这个较小的集合中提取最终中心。
将整个过程安装到MapRduce框架中,在映射阶段处理块,并且在缩减阶段处理较小的中心集。其主要优势是单通道,并且比基于MapReduce的k均值法实现能产生更准确的结果。为了解释分治k均值聚类法,在不考虑Map-Reduce 的情况下解释的分治法,解释如何将解决方案安装到MapReduce中。
2.1 分治法
为了定义分治法,首先需要定义应用于每个块的算法和应用于中间中心集的最终算法。对于每个块,应用改进的k均值法并提取k个中心。如果有c块,在每个块上应用改进的k均值法之后,将有一组k×c项作为中间集。为了更准确,也会为每个提取的中心保留分配的项目数。也就是说,从每个块中提取k个中心和分配给每个中心的项目数。除了更高的准确性,保持中心的权重有助于证明分治k均值聚类法的最优性。
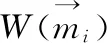
(3)
此外,改进的k均值法的选择概率须更改为
(4)
将拟议的划分和分治方法拟合到MapReduce框架中非常简单。由于每个块的处理独立于其它块,因此可以在专用映射任务中处理每个块。即每个映射任务选择一块数据集并在该块上执行改进的k均值法,然后将得到的k个中心及其权重作为输出[14]。
在映射阶段完成之后,形成一组中间加权中心作为映射阶段的输出,并且该组中心被给予单个减少任务,并获取一组中心数据及其权重,然后执行最终改进的k均值法,并返回最终中心作为输出。
2.2 接近误差界
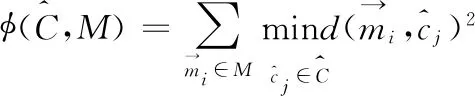
(5)
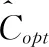
由于需要证明不依赖于数据集的分区方式,因此证据的直接且重要的结果是以下语句:“块大小和数据集的顺序对分治k均值聚类法的误差界限没有影响。”但是,为了达到更好的质量,更小的块尺寸更适合更大的块尺寸。
2.3 调整块大小

2.4 收敛性判定
对于任意数据对象而言,在聚类迭代的过程中,其数据对象均会被分配到离自己最近的簇中。随着聚类质心的不断调整,数据对象都将会越来越向着有利于自己的簇进行靠近,ε的值会趋近于一个固定值,当ε的值最终不变化时,算法最终达到最优聚类。但原始k均值法在每次迭代计算过程中并未指出,当算法收敛到某种程度时,就可以结束整个算法的迭代计算过程,并未将准则函数的值ε作为算法是否完成的判定标志。分治k均值法采用最小加权距离来重新确定数据点应该被分配的类簇,并以此来判断算法的收敛性。
3 实验结果与分析
为了评估分治k均值聚类法,对实际和合成数据集进行了详细的实验。将实验分为两个主要部分,在一台机器上评估分治k均值聚类法并使用单个线程。在单机实验期间,只使用实际的数据集,目标是评估分治k均值聚类法与标准k均值法及改进k均值法相比的准确性。因为大多数可用的现实世界数据集都不是很大,可以在一台机器上轻松处理,所以使用一台机器进行此实验。
使用Hadoop框架进行了一系列分布式实验,在分布式实验中,使用了庞大的合成数据集,目标是将分治k均值聚类法的性能和准确性与可用的k均值法变体进行比较。实际表明尽管分治k均值聚类法的最坏情况误差界限相比于改进的流式k均值法更宽松,但实际上它产生了更好的聚类解决方案。
3.1 数据集
为了评估分治k均值聚类法的性能,使用了一组合成数据集和4个真实数据集。使用的4个真实数据集是:“美国人口普查数据(US census data)”,也称为“US Census”;“KDDCUP04生物数据集(KDDCUP04 biology dataset)”又名“KDD04”;“扑克手数据(Poker hand data)”又称“扑克(Poker)”;“皮肤分割(Skin segmentation)”又名“皮肤(Skin)”;以及“Birch算法的数据集(the Birch algorithm’s dataset)”,又名“Birch”。所有数据集都可通过UCI机器学习库获得。
与现有的相关工作一样,合成数据集是通过从5个维度的超立方体中随机选择k个中心来生成的,这些超立方体的边长度为500,然后从标准差10的高斯分布中添加点,以每个中心为中心。因此,合成数据集包含一组分离良好的聚类,最佳中心是原始中心。合成数据集由NORM-X表示,其中X表示数据集中的项目数。
3.2 实验设置
实验采用40台机器的私有云,每台机器都有一个2核2.4 GHz Xeon CPU和12 GB RAM。所有机器均安装Ubuntu Linux12.04和OpenJDK7,Apache Hadoop1.2和Mahout0.8也安装在MapReduce框架中。分布式实验在40台机器上完成,而串行实验在具有3.4 GHz i7 CPU和 8 GB RAM的单台机器上执行。
对于串行实验,使用Apache Commons Math 3.2实现。对于连续实验也尝试了Weka和MATLAB,但两者都比Apache Commons Math慢,无法处理像USCensus这样的大型数据集。对于分布式实验,使用Apache Mahout来基于MapReduce的k均值法实现,以及使用GraphLab来基于MPI的分布式改进的k均值法实现。
3.3 串行实验
系列实验的主要目标是将分治k均值聚类法与k均值法和改进的k均值法进行比较,对比结果见表1。对每个数据集用了3个不同数量的聚类:10、50、100。

表1 串行执行结果
如表1的结果所示,分治k均值聚类法聚类结果优于k均值,分治k均值聚类法比k均值法和k均值法++更快。对于在500次迭代之前未实现收敛的情况,削减执行。结果表明,改进的k均值法比k均值法收敛得更快,还得到具有更优的簇。由于数据集不是很大,因此对于每个数据集和簇编号,分治k均值聚类法的块大小设置为10k。
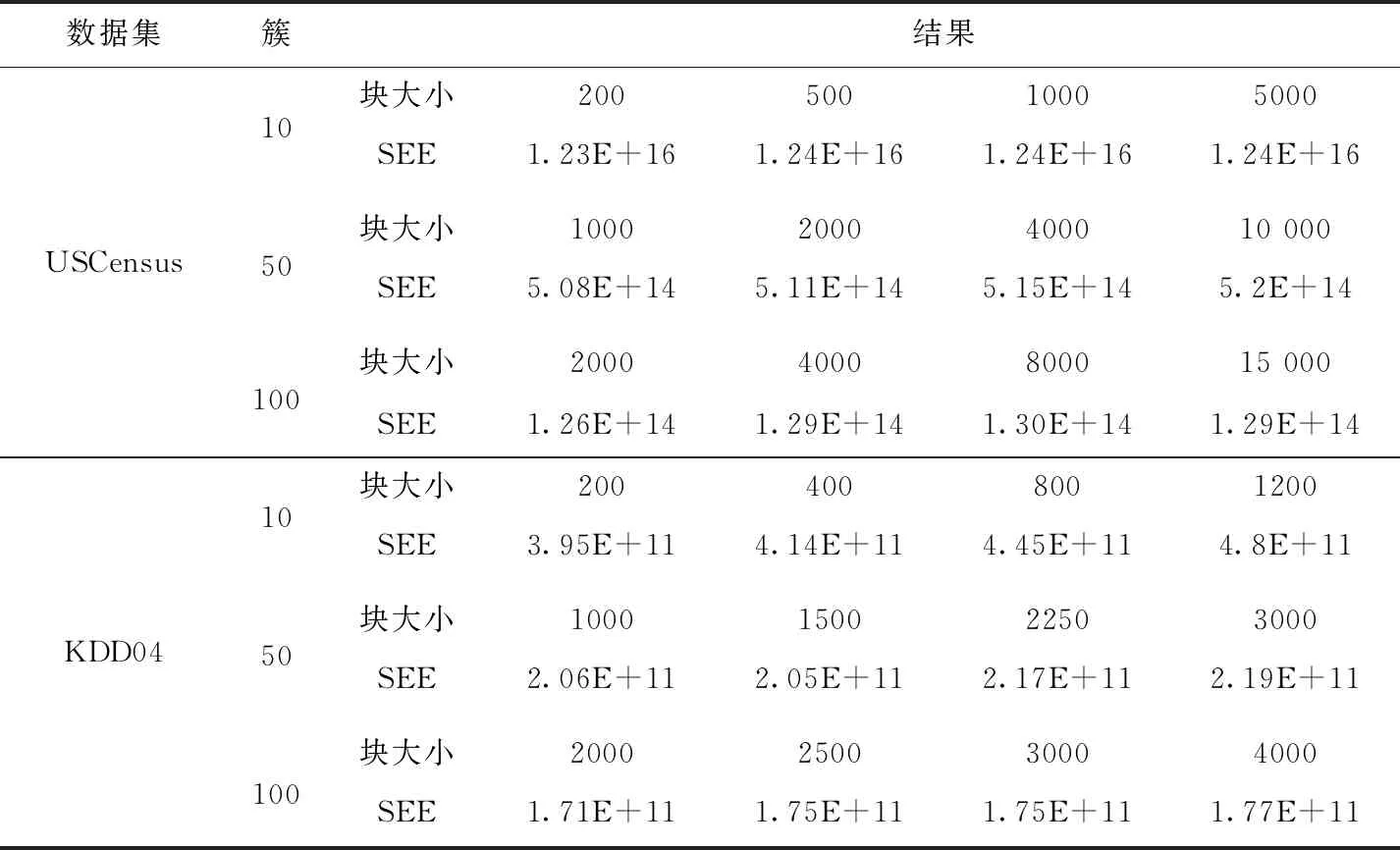
表2 不同块的数据集对分治k均值聚类法结果的影响
3.4 分布式实验
分布式实验主要目标是比较分治k均值聚类法与可用解决方案相比的速度及准确性。生成了4个由10 50 100和500个簇组成的大型合成数据集。每个数据集包含10亿个项目。由于项目有5个特征,簇的标准差等于10,因此最优聚类的预期SSE在5×1011左右。
3.4.1 与ApacheMahout的比较
对Mahout的代码进行些调整,使标准和改进的流式k均值法运行得更快。例如,对于k=100和k=500,改进的流式k均值法的原始版本在经过一段时间运行后崩溃,但在调整完成后,它成功完成了聚类。实验细节见表3,最佳值用粗体表示。每个设置执行11次,并报告中值。
从表3可以看出,分治k均值聚类法总是比其它解决方
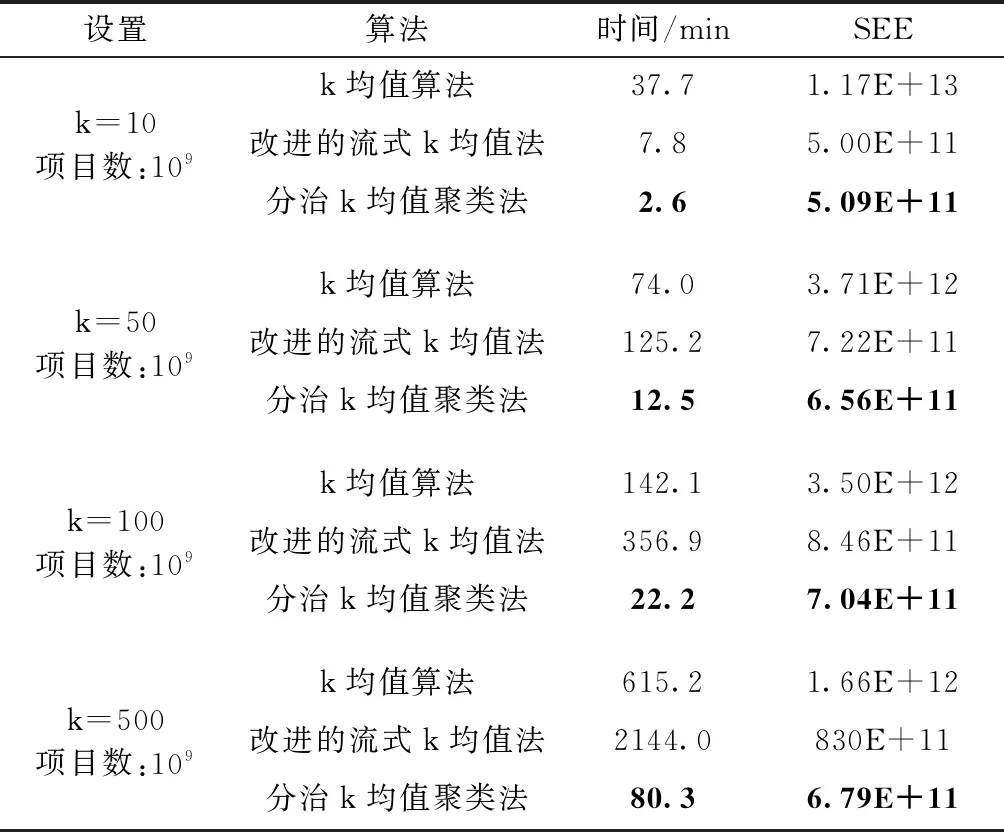
表3 与Mahout相比,分治k均值聚类法的质量和性能
案快几倍。在所有数据集中,超过95%的执行时间用在映射阶段,表明分治k均值聚类法是单通道,并且与标准k均值法的单次迭代一样快。标准k均值法和分治k均值聚类法的执行时间通过簇数的增加而线性增加。改进的流式k均值法从每个块中选择k·logk项,与k均值法和分治k均值聚类法相比,它的增长是线性的,它们通过增加簇的数量线性增长。考虑到分治k均值聚类法的质量将5×1011作为最佳聚类的预期SSE结果。考虑到准确性,k均值法总是最差的。当k为10时,改进的流式k均值法和分治k均值聚类法具有大致相同的精度,对于10以上的簇数,分治k均值聚类法具有最佳精度。当群集数量增加时,改进的流式k均值法的准确性下降,作为改进的流式k均值法的构建块的k均值算法在大量群集时执行不良,而分治k均值聚类法在具有大量聚类的数据集时结果更优。
3.4.2 与GraphLab的比较
通过GraphLab项目测试了改进的k均值法的分布式版本。GraphLab不使用MapReduce模型,而是使用消息传递接口(MPI)。为了执行改进的k均值法,GraphLab在可用机器之间平均分割数据集,并且每台机器将其所有共享加载到主存储器。当10亿个项目数据集作为输入时,并未被执行,因为数据集不在机器的主存储器中。生成了一个较小的数据集,其中包含5个、50个、100个和500个集群的5亿个项目。这些数据集的最佳SSE值为2.5×1011。
在5亿个项目数据集上应用了GraphLab的改进k均值法和分治k均值聚类法,结果在表4中给出,最佳值用粗体表示。为了进一步比较,将改进的k均值法的最大迭代次数设置为10,将GraphLab设置为100。结果表明,在10到100次迭代之间存在非常小的差异(低于1%)。也就是说,10次迭代对于k均值就足够了,SSE没有相当大的改进。另一方面,与10次迭代相比,100次迭代至少需要5次。
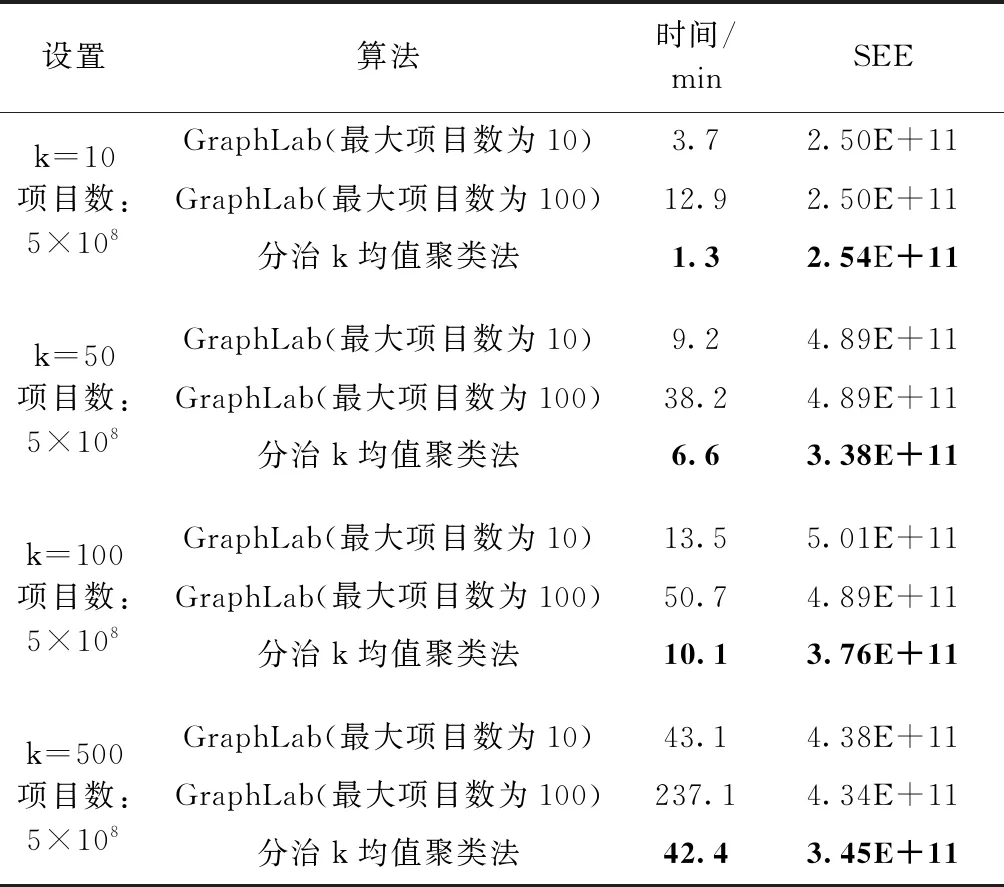
表4 提出的分治k均值聚类算法与基于GraphLab的分布式改进k均值法的比较
从表4可以看出,当最大迭代次数设置为10,最大迭代次数设置为100时,分治k均值聚类法比GraphLab的改进的k均值法更快。但与Mahout基于MapReduce的k均值相比,GraphLab的执行速度更快。GraphLab的速度背后有两个主要原因。首先,GraphLab将数据集加载到主内存中,在每次迭代中,它不需要从磁盘重新加载数据集。其次,GraphLab是用C++语言编写的,并使用MPI执行,MPI比使用Java语言编写并通过Hadoop执行的Mahout快得多。将所有数据集加载到主存储器中的要求是GraphLab分布式改进的k均值法解决方案的一个重要缺点,这使它无法处理非常大的数据集。
另一点是GraphLab的聚类结果的质量,考虑到结果的质量,预计GraphLab的改进的k均值法将胜过分治k均值聚类法,但当集群数量超过10时,分治k均值聚类法会生成更好的集群。因为原始数据集非常大,所以每个块都是公平的子样本,分治k均值聚类法在每个块上独立地应用改进的k均值法,分治k均值聚类法正在执行类似集合的方法。分治k均值聚类法的集合式方法使其更加稳定,因此,与改进的k均值法相比,k=10和k=500的SSE值之间的差异较小。
4 结束语
分治k均值聚类法是一种单通道和线性时间分布式数据聚类算法,其最优结果是O(log2k)。 实验结果表明,分治k均值聚类法在速度和结果质量方面,均优于k均值法和改进的流式k均值法。但分治k均值聚类法计算开销较大。
未来工作的方向是降低O(log2k) 的最优性界限,减少分治k均值聚类法的时间复杂度。另外还可以结合一些自动聚类方法,如贝叶斯信息准则(Bayesian information criterion,BIC)或Akaike信息准则(Akaike information criterion,AIC),使分治k均值聚类法能够自动预测聚类数量。
