基于随机森林法的农作物遥感识别方法研究
——以阿荣旗部分区域为例
2020-05-23包珺玮于利峰乌兰吐雅许洪滔乌云德吉于伟卓
包珺玮,于利峰,乌兰吐雅,许洪滔,乌云德吉,于伟卓
(内蒙古自治区农牧业科学院,内蒙古 呼和浩特 010031)
农作物面积提取和分类是农情遥感研究的基础,对指导农业生产、乡村振兴战略实施具有重大意义。早期受到影像数据源单一限制,在土地类型分类、农作物识别研究领域,中等分辨率影像作为主要数据源,被国内外学者大量使用。然而,对于种植结构复杂、农作物光谱特征复杂地区,农作物分类结果常表现出分类精度低、误差大等缺点[1]。自2015年6月欧空局(European Space Agency)成功发射Sentinel_2A 以来,因其影像覆盖范围大、分辨率高、光谱信息丰富等优点为遥感农作物识别、面积提取等研究领域提供了有力数据支撑[2]。朱琳[3]利用Sentinel_2A 多源遥感数据在农作物分类和面积提取的研究中发现,分类精度及Kappa 系数都比光学遥感分类结果好;王蓉等[4]利用Sentinel_2A影像结合DEM 高程模型提取雨养区和灌溉区的冬小麦种植面积,认为Sentinel_2A 影像对冬小麦提取效果明显。农作物面积提取是农作物估产、长势等农情信息分析的基础,提高分类精度对于农情遥感监测尤为重要。
随机森林法作为一种集成学习方法,具有高效、灵活等特点,被广泛应用于中高分辨率影像的分类研究中。黄双燕等[5]基于Sentinel_2A 数据,采用机器学习方法以地块基元为基本单元,提取农作物分类信息,有效解决了“椒盐”效应问题,提高了农作物的分类精度。雷小雨等[6]利用随机森林方法结合构建差值特征对南方水稻种植面积进行提取,改善了水稻面积提取的精度。王娜等[7]利用单变量特征和随机森林方法进行苏北地区主要农作物的识别和提取,有效降低了数据冗余,提高了农作物的分类精度。因此,选择适合的遥感数据源、特征变量及算法模型已成为农作物分类研究的重要内容。
本研究通过挖掘遥感数据的光谱特征、参数特征和纹理特征等信息,构建基于机器学习的作物提取模型,旨在为未来大尺度提取农作物面积提供借鉴。
1 研究区概况
阿荣旗地处内蒙古呼伦贝尔市东南部,全旗总面积1.36 万km2,境内有耕地面积471.6 万km2,种植作物种类丰富,主要作物有玉米、马铃薯、大豆、水稻、杂粮等,常年粮食生产能力30 亿kg,是全国441个优质商品粮基地、内蒙古自治区5 个大豆主产区之一,阿荣旗部分区域遥感影像见图1。
2 数据预处理与分析
2.1 数据预处理
Sentinel_2A 卫星是具有13 个光谱波段并携带多光谱仪的全球环境卫星。包括10 m 分辨率的红、绿、蓝波段及1 个近红外波段,4 个20 m 分辨率植被红边波段、2 个短波红外线波段,60 m 分辨率水蒸气、卷云、沿海气溶胶数据(表1)。
根据研究区农作物生长的物候期,选用2018年7月影像,数据经过大气校正、重采样,ENVI 软件转换为标准格式后得到10 m 分辨率影像。利用与Rapid eye 影像相近的红边波段及短波近红外波段显著放大农作物之间的光谱差异,达到提高农作物识别准确度的目的[8]。
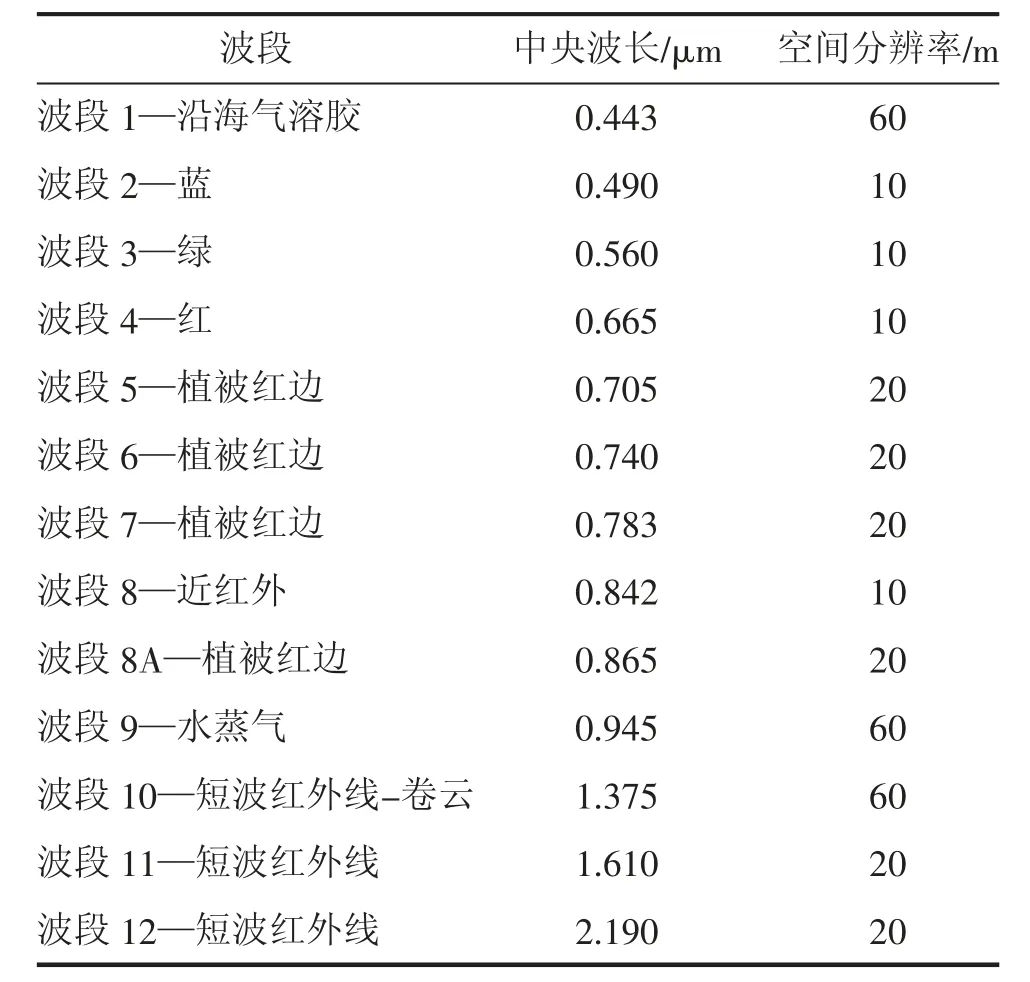
表1 Sentinel_2A 光谱范围
2.2 地面调查
地面调查数据包括解译点坐标信息、验证点坐标信息、照片等内容。利用手持差分GPS 设备沿着省级、市级、县级等主要道路,选择农作物种植类型丰富且集中连片区域,按照每5 km 1 个解译点的标准采集。地面调查共采集解译标志394 个,验证点100 个,采集作物包括玉米、高粱、大豆、甜菜,研究区解译点分布见图2。
2.3 辅助数据
本研究选取2014—2015年快鸟影像、Word view影像为底图解译出已经确定耕地面积范围并去除了线状地物信息的2 m 分辨率的呼伦贝尔市耕地底图为辅助数据,用于剔除分类结果中的草地、林地、沙地等非耕地图斑,减少冗余数据对分类结果精度的影响。
3 研究方法
3.1 技术路线
农作物面积提取主要以计算机解译为主,充分利用Sentinel_2A 影像丰富的光谱信息,结合研究区种植结构制定技术路线(图3)。
3.2 特征分析
基于像元的分类方法受到同物异谱及同谱异物的影响,出现“椒盐”现象严重,使得地块整体结构遭到破坏。因此,本研究拟从光谱特征、参数特征与纹理特征入手,选择农作物识别关键期,探索农作物分类的方法。
3.2.1 光谱特征分析 采用均值漂移的算法改善影像分割精度和准确度。均值漂移(mean shift,MS)算法是一种通用的聚类算法,其特点是不受数据分布特征及形态影响,适用于多种分布特征的影像数据[9]。该算法最初由FUKUNAGA 等[10]于1975年提出,之后针对采样点对周围样本的重要程度,提出了一组核函数,将均值漂移算法的使用范围进行了发展,其基本数学表达式为:
其中,Sh 是一个半径为h 的高维球区域,k 表示n 个样本点有k 个点落入Sh 中。对于所有采样点,每个样本点的重要性应该是不同的,离中心点越远,其权值应该越小。故引入核函数和权重系数来提高跟踪算法的滤波性并增加搜索跟踪能力。在一个d 维的欧式空间中,x 表示该空间中的一个点,用一列向量表示,存在标准化常量c,d 使得核函数k(x):
式(2)应满足k 是非负的、非增的、连续的。平均的偏移量会指向样本点最密的方向,也就是概率密度函数的梯度方向,引入核函数和权重的系数后得到式(3):
式(4)是一个单位核函数,H 是一个正定d×d 的对称矩阵,ω(xi)是采样点x(i)的权重[11]。苏腾飞等[12]利用改进型MS 滤波算法对高分辨率影像分割,其结果明显改善了农田边界平滑效果,优化了影像分割精度。
由图4 可以看出,经过MS 处理后的影像,在纹理特征、作物边界、平滑度等特征上都有很好地改善。
3.2.2 参数特征分析 遥感的参数特征是指采用了比值运算和归一化处理得到的一系列指数。通过比值运算,以几何级数进一步扩大反射率之间的差距,农作物在指数影像上得到最大的亮度增强,达到农田特征区分的目的。
归一化植被指数(normalized difference vegetation index,NDVI)表达式为:
NDVI 通常是用卫星遥感数据计算,以评估目标地区绿色植被的生长状况。计算方式是利用红光与近红外光的反射,能显示出植物生长、生态系的活力与生产力等信息。数值愈大表示植物生长愈多。
土壤调节植被指数(soil adjusted vegetation Index,SAVI)通过引入了土壤调节因子L,使无论是在深色还是在浅色土壤背景中求得的植被指数都完全相等,从而消除了土壤背景的干扰,表达式为:
SAVI=[(NIR-RED)(1+L)]/(NIR+RED+L)(6)
式(6)中,L 即为土壤调节因子,其值介于0~1。“0”和“1”分别代表植被覆盖率极高和极低的两种极端情况[13]。通常选择0.5 可以较好地减弱土壤的背景差异,清除土壤的噪声影响。
增强植被指数(enhanced vegetation index,EVI)表达式为:
式(7)中,EVI 通过加入蓝色波段以增强植被信号[14],矫正土壤背景和气溶胶散射的影响。
3.2.3 纹理特征分析 纹理是地物的物理形态所表达出的灰度空间相关特性,纹理特征的核心问题是纹理区域的一致性和相邻区域边界的准确性[15]。高分辨率数据下,由于不同种农作物之间的生理形态与疏密情况的差异,不同农作物之间也存在纹理区别(图5),可以有效区分农作物类型。
灰度共生矩阵是利用图像中两个像素灰度级联合分布的统计形式,反应纹理灰度级相关性规律的常用分析方法[16]。通过反复测试,选择3×3 窗口,在ENVI 软件中对其均值(Mean)、方差(Variance)、一致性(Homogeneity)、熵(Entripy)、灰度(Contrast)5个统计量进行提取:
式中,n 为灰度值的阶数,p(i,j)是n×n 的归一化共生矩阵,u 为p(i,j)的均值。鉴于红边波段对作物识别比较敏感,因而使用红边波段作为纹理特征的提取波段。
3.3 分类方法
机器学习是在数据中自动分析获得规律,并利用规律对未知数据进行预测的算法[17]。随机森林法(random forest,RF)作为机器学习的重要方法拥有广泛的应用前景。其实质就是利用多种分类器投票决定分类结果,对于一个输入样本,N 棵树会有N个分类结果。而随机森林法可以集成所有的分类投票结果,将投票次数最多的类别指定为最终的输出[18]。在遥感领域其优点是几乎不需要设置参数就可以得到比较好的提取结果,而且能够有效地运行在大数据集上,能够满足未来大尺度范围提取的要求。
4 分类结果与精度评价
在耕地底图范围内,基于2018年Sentinel_2A影像数据,利用随机森林算法得到阿荣旗主要农作物空间分布情况(图6)。
4.1 精度验证与评价
分类精度是影像像元被正确分类程度的评价指标,本研究采用混淆矩阵精度分类,确定分类结果的精度和可靠性。混淆矩阵的分类评价指标包括:总体分类精度、Kappa 系数、漏分误差、错分误差、制图精度、用户精度,而总体精度和Kappa 系数指标直接影响和决定分类结果的准确性。在精度评价过程中,将野外采集的100 个地面验证点,采用定性和定量的方式对农作物品种判别准确度和农作物面积提取的精确度进行验证见图7,并建立了混淆矩阵评价指标见表2。
4.2 结果分析
由表2 可以看出,随机森林法对农作物分类的总体精度能到达到80%以上,Kappa 系数为0.727 7,表示总体分类精度较好。尤其是大豆和玉米的制图精度可以达到90%以上,但甜菜和高粱的出现错分现象比较明显,其主要原因是甜菜和高粱在8月份的光谱特征相似;大豆的分类结果理想,基本没有造成错分;甜菜的分类效果相对较差,错分为高粱和玉米的数量较多。由分类结果可知,采用均值漂移法可以有效改善作物混淆像元问题及地块内部异质现象,但是对于光谱特征相似的作物,分类结果不理想。
5 结论
基于前人研究成果,本研究以Sentinel-2A 影像为数据源,利用机器学习算法从影像光谱特征、数据提取方法和模型选择方面进行农作物遥感识别研究,分类精度较高,但仍存在许多不足之处。首先,数据选取时相受多因素影响,是否存在与最佳提取时期不匹配的问题还需进一步研究;其次,通过提取、挖掘遥感影像信息,较高精度地识别了农作物分布,但一定程度上也造成了数据量冗余;最后,对于存在农作物种类丰富、光谱特征复杂、农作物边界不清晰等问题的区域,在数据选取与模型改进方面仍需进一步研究。
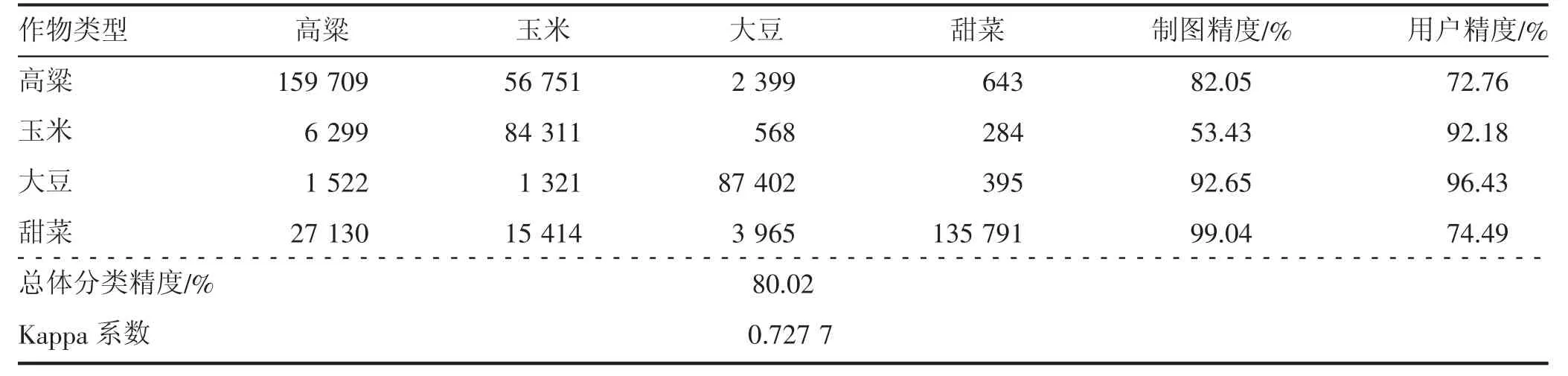
表2 随机森林法农作物分类结果混淆矩阵
