一种循环神经网络的词义消歧方法
2020-05-21张春祥周雪松高雪瑶
张春祥 周雪松 高雪瑶

摘 要:词义消歧是自然语言处理领域中的一个重要研究问题。针对汉语一词多义现象,结合上下文语境,采用循环神经网络(Recurrent Netural Networks,RNN)来确定歧义词汇的真实含义。以目标歧义词汇为中心,提取其左右4个邻接的词汇单元。从中抽取词形、词性和语义类作为消歧特征。以消歧特征为基础,结合循环神经网络来构建词义消歧分类器。利用SemEval-2007: Task#5的训练语料和哈尔滨工业大学语义标注语料来优化RNN的参数。使用SemEval-2007: Task#5的测试语料对词义消歧分类器进行测试。实验结果表明:所提出的方法能够提高词义消歧的准确率。
关键词:词义消歧;自然语言处理;循环神经网络;消歧特征
DOI:10.15938/j.jhust.2020.01.012
中图分类号: TP391.2
文献标志码: A
文章编号: 1007-2683(2020)01-0080-06
Abstract:Word sense disambiguation is an important research problem in natural language processing field. For the phenomenon that a Chinese word has many senses, recurrent neural network(RNN) is used to determine true meaning of ambiguous word with its context. Target ambiguous word is viewed as center and its four adjacent word units are extracted. Word, part-of-speech and semantic categories are extracted as disambiguation features. Based on disambiguation features, recurrent neural network is used to construct word sense disambiguation classifier. Training corpus in SemEval-2007: Task#5 and semantic annotation corpus in Harbin Institute of Technology are used to optimize parameters of RNN. Test corpus in SemEval-2007: Task#5 is applied to test word sense disambiguation classifier. Experimental results show that the proposed method can improve accuracy of word sense disambiguation.
Keywords:word sense disambiguation; natural language processing; recurrent neural network; disambiguation features
0 引 言
词义消歧是自然语言处理领域中的基础性研究问题。同时,也是机器翻译和机器理解中的核心步骤。鹿文鹏根据依存句法分析结果来提取歧义词汇的依存约束集合。从WordNet中找出歧义词汇各个词义的代表词。根据词义代表词在依存约束集合中的依存适配度来选择正确的词义[1]。鹿文鹏等[2]利用文本领域关联词和句子上下文词来构建消歧图。利用领域知识来调整消歧图。同时,使用改进的图评分标准对消歧图中的各个词义结点的重要程度进行打分。杨陟卓等[3]运用语言模型来优化有监督消歧模型。充分利用有监督消歧模型和语言模型来确定歧义词汇的真实含义。在训练语料不足的情况下,这种方法可以有效地改善词义消歧的效果。王少楠等[4]将上下文语境中具有明确含义的实词作为输入。在上下文语境中,获取可以表示歧义词汇语义的其它特征。最后,利用贝叶斯概率模型将这两种信息结合起来,共同实现歧义词汇的语义表示和归纳。实验结果表明:这种方法可以得到更好的语义表示和归纳效果。唐共波等[5]将多义词的上下文作为消歧特征,以形成特征向量。通过计算多义词词向量与特征向量之间的相似度来进行词义消歧。该方法可以大大地减少词义消歧模型的时间复杂度。杨陟卓等[6]设计并实现了一种基于模拟退火的词义消歧方法,能够自动估计各种知识类型的关系权重,并优化各种知识对消歧效果的影响。这种方法有效地克服了数据稀疏和知识获取的瓶颈。杨振景等[7]提取歧义词汇上下文中的局部词、局部词性以及局部词和词性对作为消歧特征,并对这三种特征赋予不同的权重。同时,利用支持向量机模型来确定歧义词汇的真实含义。范弘屹等[8]給出了一种改进的语义相似度计算方法。在原有方法的基础上,考虑HowNet中义原的深度和密度对词语相似度的影响。挖掘义原之间的关系,改进原有的计算方法。张健立等[9]利用WordNet中的语义关系来构建语义关系图。根据歧义词汇与其上下文之间的关联度,来确定它的最佳含义。Zhu[10]提出了一种基于冯诺依曼核的半监督词义消歧方法。利用词与词之间的共现来定义图。根据有标注和无标注训练数据在图中的传播过程来计算术语之间的语义相似度。然后,根据语义相似度来构造冯诺依曼核。Huang等[11]将语义分析视为多个语义序参数竞争的过程,提出了一种基于改进协同神经网络并融入词义信息的角色标注模型。Abualhaija等[12]以遗传模拟退火算法和蚁群算法为基础,提出了一种蜂群算法来解决词义消歧问题。Hung等[13]提出了一种基于口语词文档的词义消歧方法。首先构建了情感词汇网词典,然后利用所构建的词典进行词义消歧。史兆鹏等[14]从依存句法分析结果中提取歧义词汇及其上下文的词性、依存结构和依存词。构造歧义词汇语义类的权值函数,选择权值最大的语义类进行消歧。高璐等[15]提出了一种利用知网实例库和知网关系进行词义消歧的算法。钱涛等[16]给出了一种基于超图的词义消歧模型。利用词汇链找到歧义词汇与上下文词汇之间的高阶语义关系。将上下文词汇作为结点,利用词汇链所找到的超边来构建超图。利用基于最大密度的超图谱聚类算法来确定歧义词汇的含义。任海英等[17]提出了一种基于维基百科的多策略词义消歧方法。设计了类别一致性、内容相关性和词义重要程度三个指标。利用二次消歧方法来确定歧义词汇的真实含义。刘峤等[18]提出了一种基于语义一致性的集成实体链接算法,能够更好地利用知识库中实体之间的结构化语义关系,提高了算法对概念相似实体的区分度。许坤等[19]利用语料库来构建从实体到知识库的映射,对谓词进行消歧。然后,将自然语言问句转化为计算机可理解的结构化查询语句。杨安利等[20]用无标注文本来构建词向量模型,结合特定领域的关键词信息,提出了一种新的词义消歧方法。
本文以歧义词汇为中心,选取它左右两侧的4个邻接词汇单元中的词形、词性和语义类作为消歧特征,利用循环神经网络来确定它的正确语义。
1 消歧特征的选择
歧义词汇的语义类别是由其上下文环境所决定的。在歧义词汇的上下文中,包含了很多用于确定歧义词汇语义的语言学知识。要想确定歧义词汇的真实含义,就要从其上下文中挖掘相关的信息,这就是所谓的消歧特征提取。特征选取的方法不同,词义消歧的结果会不同,这将会直接影响到词义消歧的效果。
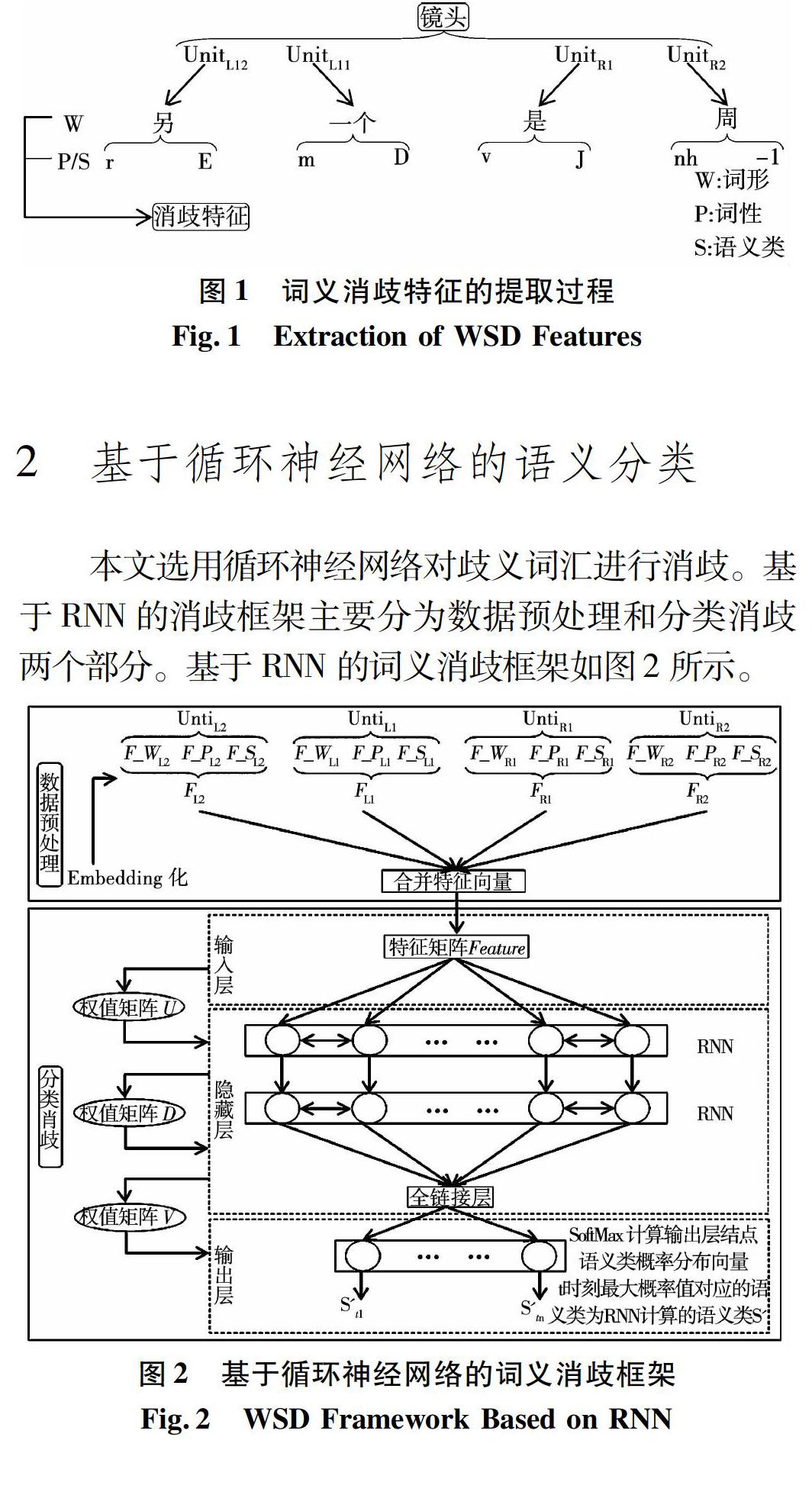
以歧义词汇为中心,选取其左右邻接的4个词汇单元。从这4个词汇单元中,分别提取其词形、词性和语义类3种消歧特征。以包含歧义词汇“镜头”的汉语句子为例,其消歧特征的提取过程为:
汉语句子:另一个镜头是周总理向灾区群众讲话。
分词结果:另一个镜头是周总理向灾区群众讲话。
词性标注结果:另/r一个/m镜头/n 是/v 周/nh总理/n向/p 灾区/n 群众/n讲话/v 。
语义类标注结果:另/r/E 一个/m/D 镜头/n/D 是/v/J 周/nh/-1 总理/n/A向/p/K 灾区/n/C 群众/n/A讲话/v/H 。
消歧特征的提取过程如图1所示。其中,W表示词形;P表示词性;S表示语义类。UnitL1和UnitL2分别表示歧义词汇左边邻接的两个词汇单元。UnitR1和UnitR2分别表示歧义词汇右边邻接的两个词汇单元。歧义词汇“镜头”左侧的两个词汇单元分别为“另/r/E”和“一个/m/D”。此处,r表示代词;m表示数词;“另”所属的语义大类为E;“一个”所属的语义大类为D。歧义词汇“镜头”右侧的两个词汇单元分别为“是/v/J”和“周/nh/-1”。此处,v表示动词;nh表示姓氏词;“是”所属的语义大类为J;“周”所属的语义大类为-1。从这4个词汇单元中,分别提取词形、词性和语义类作为消歧特征。
在数据预处理部分,将训练数据转换为RNN所能接受的标准输入数据。在传统的数据处理中,采用了独热编码(one-hot)方法。采用寄存器对不同的状态进行标识。在任意时刻,寄存器只有一位设置为1,其余位均设置为0。使用这种方法所得到的特征向量是非常稀疏和冗长的。为了解决这个问题,引入了Embedding层来对输入数据进行处理。将所提取的消歧特征转化为一个由浮点数表示的特征矩阵。在特征矩阵中,每一列表示一个词汇单元的特征向量。所得到的数据是稠密的,能更好地表示特征信息。使用公式(1)来计算词汇单元的各个消歧特征的Embedding向量。
其中:矩阵M∈Rd*V是一个随机初始化的大规模浮点数矩阵;d为Embedding向量的维数;V为消歧词窗所包含的词汇单元数目;vm是词汇单元的消歧特征的one-hot表示。在Embedding层中,采用点乘运算来求解消歧特征所对应的Embedding向量rm。
在汉语句子C中,歧义词汇w的人工标注语义类为S。歧义词汇w左侧第二个词汇单元为UnitL2=(WL2, PL2, SL2);左侧第一个词汇单元为UnitL1=(WL1, PL1, SL1);右侧第一个词汇单元为UnitR1=(WR1, PR1, SR1);右侧第二个词汇单元为UnitR2=(WR2, PR2, SR2)。对于词汇单元UnitL2,计算WL2的独热编码;然后利用公式(1)来获取它所对应的Embedding向量F_WL2。计算PL2的独热编码;然后利用公式(1)来获取它所对应的Embedding向量F_PL2。计算SL2的独热编码;然后利用公式(1)来获取它所对应的Embedding向量F_SL2。连接F_WL2、F_PL2和F_SL2,形成特征向量FL2。同理,可以获得UnitL1的特征向量FL1、UnitR1的特征向量FR1和UnitR2的特征向量FR2。以特征向量FL2、FL1、FR1和FR2为基础,构造特征矩阵Feature={FL2, FL1, FR1, FR2}。使用特征矩阵Feature和人工标注语义类S来训练RNN,以获得优化的模型参数。
RNN是一种利用序列信息来进行数据处理的模型[21]。其特点是:能够保存当前时刻的上下文状态;在上下隐藏层的结点之间,存在连接边。在RNN中,包括输入层、隐藏层和输出层。
输入层接受特征矩阵Feature。将特征向量FL2、FL1、FR1、FR2分别赋给输入层所对应的结点。在隐藏层中,神经元是相对独立的。隐藏层的层数是由特征向量的个数决定的。在t时刻,隐藏层结点的状态是由t时刻的输入层结点所接受的特征向量和t-1时刻的隐藏层结点状态共同决定的。将隐藏层的计算结果先送入全链接层,然后再送入输出
层的SoftMax函数。其目的是:使SoftMax函数的输入和输出维数相同。SoftMax函数根据t时刻输入的特征向量和t-1时刻隐藏层结点状态来计算t时刻的语义类概率分布向量。
图中S′t1表示t1时刻,语义类概率分布向量中,最大的概率所对应的语义类;S′ti表示ti时刻的语义类概率分布向量中,最大的概率所对应的语义类。SoftMax输出结果是一个向量。其维數为语义类的数目。若歧义词汇w有n种语义类别S1,S2,…,Sn,则SoftMax输出一个n维的语义类概率分布向量{P(S1),P(S2),…,P(Sn)}。在输出向量中,各个分量表示歧义词汇在各个语义类下的概率分布。在输出层中,最后一个结点的SoftMax函数输出语义类概率分布向量。在向量中,最大概率值P(Si)所对应的语义类Si,就是RNN计算的歧义词汇的语义类。
在图2中,U表示输入层与隐藏层之间的连接权值矩阵;D表示t-1时刻的隐藏层与t时刻的隐藏层之间的连接权值矩阵;V表示隐藏层与输出层之间的连接权值矩阵。矩阵U、D和V是RNN的模型参数。在模型训练之前,将矩阵U、D和V随机初始化为很小的数值。
3 基于循环神经网络词义消歧模型的训练
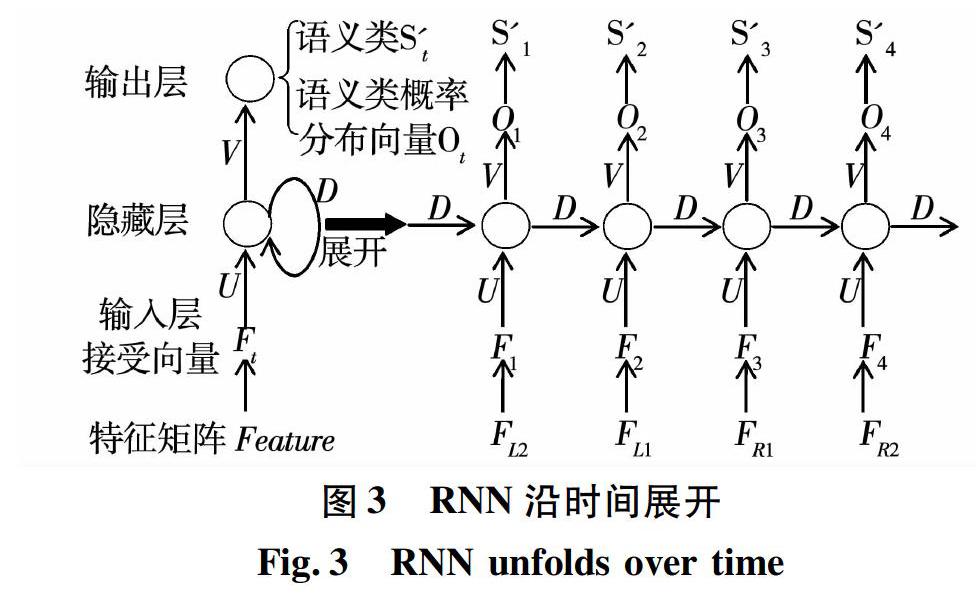
RNN是一种基于时间维度的模型。隐藏层可以在时间维度上进行展开。此处,设置RNN的隐藏层层数为4。基于时间维度展开的RNN模型如图3所示。
在图3中,Feature表示特征矩阵;Ft表示t时刻输入层结点所接受的特征向量;At是t时刻隐藏层结点的状态;Ot是t时刻所输出的语义类概率分布向量;S′t是t时刻RNN所输出的歧义词汇的语义类。其中,t=1, 2, 3, 4。RNN的训练过程包括前向传播过程和反向传播过程。
1)前向传播过程。
在前向传播过程中,根据t时刻所接受的特征向量Ft和t-1时刻隐藏层结点的状态At-1,来计算t时刻的语义类概率分布向量Ot={P(S1), P(S2), …, P(Sn)}。整个传播过程是自底向上进行的,具体步骤如下所示。
①输入特征矩阵Feature={FL2, FL1, FR1, FR2},Ft为t时刻输入层所接受的向量,赋值F1=FL2,F2=FL1,F3=FR1,F4=FR2;
②for(t=1; t<=4; t++)
基于RNN的词义消歧过程为:将测试数据转换为特征矩阵。利用前向传播过程来计算歧义词汇的语义类别。将特征矩阵中的特征向量分别赋给RNN模型输入层的接受向量Ft(t=1, 2, 3, 4)。使用优化后的权值矩阵U、V、D作为RNN的参数。在隐藏层中,利用式(1)来计算结点的状态。在输出层中,利用式(4)来计算语义类概率分布向量。取最后一个结点的输出向量O4={P(S1), P(S2), …, P(Sn)}作为语义类概率分布向量。在语义类概率分布向量O4中,根据式(5)来选择最大概率值P(Si)。Si就是RNN计算所得到的歧义词汇的语义类别。
4 实 验
本文将SemEval-2007:Task#5的训练语料和测试语料作为训练数据和测试数据。其中,SemEval-2007:Task#5是ACL2007的一个组成部分,即SemEval-2007国际语义评测的中英文词汇任务(task#5 multilingual Chinese English lexical sample task)。该任务共包含40个歧义词汇。从中选取常用的10个歧义词汇。其中,含有两种语义类的歧义词汇有5个,分别为“表面”、“儿女”、“气象”、“望”、“中医”;含有3种语义类的歧义词汇有5个,分别为“补”、“成立”、“赶”、“日子”、“长城”。
为了度量本文所提出方法的性能,共进行了两组实验。在第1组实验中,选取歧义词汇左右邻接的两个词汇单元的词形作为消歧特征,采用贝叶斯(Bayes)分类器来确定歧义词汇的语义。使用SemEval-2007:Task#5的训练语料对贝叶斯分类器进行训练。利用优化后的贝叶斯分类器对SemEval-2007:Task#5的测试语料进行词义消歧。在第2组实验中,选取歧义词汇左右邻接的四个词汇单元的词形、词性和语义类作为消歧特征,利用RNN来确定歧义词汇的真实含义。利用Embedding层将消歧特征转化为特征矩阵,作为RNN的输入。利用SemEval-2007:Task#5的训练语料对RNN进行优化。使用优化后的RNN对SemEval-2007:Task#5的测试语料进行语义分类。两组实验的消歧准确率如表1所示。
5 结 论
本文提出了一种循环神经网络的词义消歧方法。以歧义词汇左右相邻的四个词汇单元的词形、词性和语义类作为消歧特征,使用RNN来判别歧义词汇的真实含义。使用SemEval-2007:Task#5的训练语料和哈尔滨工业大学的语义标注语料来优化RNN的参数,以提高词义消歧的精度。使用优化后的RNN对SemEval-2007:Task#5的测试语料进行词义消歧。实验结果表明:RNN词义消歧方法的准确率要优于贝叶斯词义消歧方法。
参 考 文 献:
[1] 鹿文鹏, 黄河燕. 基于依存适配度的知识自动获取词义消歧方法[J]. 软件学报, 2013, 24(10): 2300.LU Wenpeng, HUANG Heyan. Word Sense Disambiguation Based on Dependency Fitness with Automatic Knowledge Acquistion[J]. Journal of Software, 2013, 24(10): 2300.
[2] 鹿文鹏, 黄河燕, 吴昊. 基于领域知识的图模型词义消歧方法[J]. 自动化学报, 2014, 40(12): 2836.LU Wenpeng, HUANG Heyan, WU Hao. Word Sense Disambiguation with Graph Model Based on Domain Knowledge[J]. Journal of Automation, 2014, 40(12): 2836.
[3] 杨陟卓, 黄河燕. 基于语言模型的有监督词义消歧模型优化研究[J]. 中文信息学报, 2014, 28(1): 19.YANG Zhizhuo, HUANG Heyan. Supervised WSD Model Optimization Based on Language Model[J]. Journal of Chinese Information Processing, 2014, 28(1): 19.
[4] 王少楠, 宗成慶. 一种基于双通道LDA模型的汉语词义表示与归纳方法[J]. 计算机学报, 2016, 38(8): 1652.WANG Shaonan, ZONG Chengqing. A Dual-LDA Method on Chinese Word Sense Representation and Induction[J]. Chinese Journal of Computers, 2016, 38(8): 1652.
[5] 唐共波, 于东, 荀恩东. 基于知网义原词向量表示的无监督的词义消歧方法[J]. 中文信息学报, 2015, 29(6): 23.TANG Gongbo, YU Dong, XUN Endong. An Unsupervised Word Sense Disambiguation Method Based on the Representation of Sememe in HowNet[J]. Journal of Chinese Information Processing, 2015, 29(6): 23.
[6] 杨陟卓, 黄河燕. 基于异构关系网络图的词义消歧研究[J]. 计算机研究与发展, 2013, 50(2): 437.YANG Zhizhuo, HUANG Heyan. WSD Method Based on Heterogeneous Relation Graph[J]. Journal of Computer Research and Development, 2013, 50(2): 437.
[7] 张振景, 李新福, 田学东, 等. 基于SVM的离合词词义消歧[J]. 计算机科学, 2016, 43(2): 239.ZHANG Zhenjing, LI Xinfu, TIAN Xuedong, et al. Liheci Word Sense Disambiguation Based on SVM[J]. Computer Science, 2016, 43(2): 239.
[8] 范弘屹, 张仰森, 等. 一种基于HowNet的词语语义相似度计算方法[J]. 北京信息科技大学学报, 2014, 29(4): 42.
FAN Hongyi, ZHANG Yangsen, et al. Computing Method for Semantic Similarity of Words Based on HowNet[J]. Journal of Beijing Information Science and Technology University, 2014, 29(4): 42.
[9] 张健立. 一种基于语义关系图的词义消歧算法[J]. 科技通报, 2015, 31(3): 228.ZHANG Jianli. Word Sense Disambiguation Algorithm Based on Semantic Relation Graph[J]. Bulletin of Science and Technology, 2015, 31(3): 228.
[10]ZHU Wensheng. Semi-supervised Word Sense Disambiguation Using Von Neumann Kernel[J]. International Journal of Innovative Computing Information & Control, 2017, 13(2): 695.
[11]HUANG Zhehuang, CHEN Yidong. An Improving SRL Model With Word Sense Information Using An Improved Synergetic Neural Network Model[J]. Journal of Intelligent & Fuzzy Systems, 2016, 31(3): 1469
[12]ABUALHAIJA S, ZIMMERMANN K H. D-Bees: A Novel Method Inspired By Bee Colony Optimization For Solving Word Sense Disambiguation[J]. Swarm & Evolutionary Computation, 2016, 27(1): 188.
[13]HUNG C, CHEN S J. Word Sense Disambiguation Based Sentiment Lexicons for Sentiment Classification[J]. Knowledge-Based Systems, 2016, 110(1): 224.
[14]史兆鵬, 邹徐熹, 向润昭, 等. 基于依存句法分析的多特征词义消歧[J]. 计算机工程, 2017, 43(9): 210.SHI Zhaopeng, ZOU Xuxi, XIANG Zhaorun. Multi-feature Word Sense Disambiguation Based on Dependency Parsing Analysis[J]. Computer Engineering, 2017, 43(9): 210.
[15]高璐, 赵小兵. 一种实例库与义原关系相结合的概念消歧算法[J]. 首都师范大学学报(自然科学版), 2016, 37(3): 7.GAO Lu, ZHAO Xiaobing. A Concept Disambiguation Algorithm Based on Case Library and Sememe Relation[J]. Journal of Capital Normal University(Natural Science Edition), 2016, 37(3): 7.
[16]钱涛, 姬东鸿, 戴文华. 一个基于超图的词义归纳模型[J]. 四川大学学报(工程科学版), 2016, 48(1): 152.QIAN Tao, JI Donghong, DAI Wenhua. A Hypergraph Model for Word Sense Induction[J]. Journal of Sichuan University(Engineering Science Edttion), 2016, 48(1): 152.
[17]任海英, 于立婷. 一种基于维基百科的多策略词义消歧方法[J]. 现代图书情报技术, 2015, 31(11): 18.REN Haiying, YU Liting. A Multi Strategy Word Sense Disambiguation Method Based on Wikipedia[J]. Modern Library and Information Technology, 2015, 31(11): 18.
[18]刘峤, 钟云, 刘瑶. 基于语义一致性的集成实体链接算法[J]. 计算机研究与发展, 2016, 53(8): 1696.LIU Qiao, ZHONG Yun, LIU Yao. Consistent Collective Entity Linking Algorithm[J]. Journal of Computer Research and Development, 2016, 53(8): 1696.
[19]许坤, 冯岩松, 赵东岩, 等. 面向知识库的中文自然语言问句的语义理解[J]. 北京大学学报(自然科学版), 2014, 50(1): 85.XU Kun, FENG Yansong, ZHAO Dongyan, et al. Automatic Understanding of Natural Language Questions for Querying Chinese Knowledge Bases[J]. Acta Scientiarum Naturalium Universitaties Pekinensis(Natural Science Edition), 2014, 50(1): 85.
[20]楊安, 李素建, 李芸. 基于领域知识和词向量的词义消歧方法[J]. 北京大学学报(自然科学版), 2017, 53(2): 204.YANG An, LI Suyun, LI Yun. Word Sense Disambiguation Based on Domain Knowledge and Word Cector Model[J]. Acta Scientiarum Naturalium Universitaties Pekinensis(Natural Science Edition), 2017, 53(2): 204.
[21]刘明珠, 郑云非, 樊金斐, 等. 基于深度学习法的视频文本区域定位与识别[J]. 哈尔滨理工大学学报, 2016, 21(6): 61.LIU Mingzhu, ZHENG Yunfei, FAN Jinfei, et al. Area Location and Recognition of Video Text Based on Depth Learning Method[J]. Journal of Harbin University of Science and Technology, 2016, 21(6): 61.
(编辑:温泽宇)
