基于深度学习的个性化对话内容生成方法
2020-05-21郝少阳张秋韵於志文
王 豪,郭 斌,郝少阳,张秋韵,於志文
基于深度学习的个性化对话内容生成方法
王 豪,郭 斌,郝少阳,张秋韵,於志文
(西北工业大学计算机学院,陕西 西安 710072)
人机对话系统是人机交互领域一个非常重要的研究方向,开放域聊天机器人的研究受到了广泛关注。现有的聊天机器人主要存在3个方面的问题:①无法有效捕捉上下文情境信息,导致前后对话内容缺乏逻辑关联。②大部分不具备个性化特征,导致聊天过程千篇一律,且前后对话内容可发生矛盾。③倾向于生成“我不知道”、“对不起”等无意义的通用回复内容,极大降低用户的聊天兴趣。本研究中利用基于Transformer模型的编解码(Encoder-Decoder)结构分别构建了通用对话模型和个性化对话模型,通过编码历史对话内容和个性化特征信息,模型可以有效捕捉上下文情境信息以及个性化信息,实现多轮对话过程,且对话内容符合个性化特征。实验结果表明,基于Transformer的对话模型在困惑度(perplexity)和F1分数评价指标上相比于基线模型得到了一定的提升,人工评价显示模型可以正常进行多轮交互对话过程,生成内容多样性高,且符合给定的个性化特征。
深度学习;对话系统;聊天机器人;个性化;上下文感知
1 背景知识
人机对话系统是人机交互领域一个非常重要的研究方向,形式多样的对话系统正处于蓬勃发展阶段。文本生成,即自然语言生成,是实现对话系统的关键技术,可以利用各种不同类型的信息,如文本、图像等,自动生成流畅通顺、语义清晰的高质量自然语言文本。2003年BENGIO等[1]将神经网络语言模型应用于文本生成任务中,利用神经网络进行语言建模,为了解决自然语言中的长期依赖问题,2010年MIKOLOV等[2]利用RNN建立语言模型,提出了循环神经网络语言模型RNNLM,显著提高了语言模型的准确性。之后RNN及其各种变体如长短时记忆网络(long short-term memory, LSTM)开始成为自然语言处理技术中最常用的方法。而最近提出的Transformer模型[3]成功解决了RNN模型中存在的一些问题,引发了一轮又一轮的研究热潮。
社交聊天机器人,即能够与人类进行共情对话的人机对话系统,是人工智能领域持续时间最长的研究目标之一。聊天机器人若想与用户建立情感联系,必须具有几种能力,首先是上下文情境整合能力,在聊天过程中考虑各种情境信息来产生相应的回复内容,增加用户的真实交互感。同时聊天机器人必须拥有前后一致的个性化人格,如年龄、性别等,如果这些特征发生变化,很容易让用户产生剥离感。最后是对话内容必须具有多样性,不能总是产生“我不知道”、“是的,没错”这种通用回复,否则用户极易产生厌倦。
为了解决这些问题,本文构建了基于情境的个性化对话内容生成模型。对话过程中考虑上下文情境信息和考虑个性化特征信息,并采用多种优化方法增加生成回复内容的多样性,生成上下文连贯一致且符合个性化特征的高质量对话内容。本文的主要工作内容和贡献包括以下几个方面:
(1) 利用基于Transformer模型构建通用对话模型。通过编码历史对话内容,有效捕捉上下文情境信息,实现多轮对话过程。
(2) 调整通用对话模型结构,编码阶段加入个性化特征信息,构建个性化对话模型,有效捕捉其特征,生成符合个性化特征且前后保持一致的对话内容。
(3) 利用标签平滑、带有长度惩罚的多样化集束搜索等算法解决模型倾向于生成通用性回复的问题,丰富生成内容的多样性。
2 相关工作
近年来,人机对话系统备受学术界和工业界的关注,创建一个自动人机对话系统为人类提供特定的服务或与人类进行自然交流不再是一种幻想[4]。
SORDONI等[5]基于RNN构建了一个端到端回复生成模型,通过编码历史对话,捕捉上下文情境信息,生成连贯一致的对话内容。VINYALS等[6-7]利用了LSTM进行对话模型的构建。尽管LSTM在一定程度上缓解了长距离依赖问题,但是实际应用过程中仍有可能遇到更长的上下文内容,文献[8]提出多层循环编解码模型(hierarchical recurrent encoder-decoder, HRED),将编码过程分为2个层次,分别编码单词序列和句子序列,得到上下文表示向量,指导解码过程。实验表明,多层编码结构可更有效地捕捉上下文信息。不同的上下文语境对生成回复内容有着不同的影响,SHANG等[9]引入了注意力机制(attention mechanism),通过计算不同时刻上下文的权重,决定上下文内容在回复中的表达程度,取得了更好的效果。
虽然RNN的天然序列结构适合进行自然语言处理的任务,但其严格的线性结构会导致训练过程中容易发生梯度消失或爆炸问题,而且难以进行并行训练,这在大规模应用场景中是一个很严重的问题。为了解决这些问题,Google在2017年提出了一种新的序列建模模型-Transformer模型[3]。该模型一经提出,就在NLP领域引起了极大的反响,其抛弃了RNN中的序列结构,整个模型完全由Attention模块构成,有效地解决了长距离依赖问题和并行计算能力差的问题。Transformer模型可以高效地捕捉文本序列的语义信息,在语义特征提取能力、长距离特征捕获能力、任务综合特征抽取能力都远超过RNN模型[10]。最近相当火爆的大型预训练模型如GPT模型[11]、BERT模型[12]的基本结构均为Transformer,在多种自然语言处理任务中创造出极佳的成绩,其出众的能力显而易见。
纯数据驱动的端到端对话系统无法考虑个性化特征,不能给用户沉浸式的交互体验[13]。LI等[14]提出个性化回复生成模型,使用类似词嵌入的方式将用户编码到高维隐空间中,以指导回复生成过程。LIU等[15]提出了个性化回复生成模型,通过用户的交互对话内容来隐式学习用户的个性化特征。LUO等[16]提出了基于记忆网络(memory network)的个性化目标驱动型对话系统,编码用户个性化特征,同时利用全局记忆单元存储相似用户对话历史,生成更加符合用户个性化的内容。现有的聊天机器人研究中还存在着一些不足,如何更加高效地捕捉上下文情境信息、保持一致的个性化特征、以及生成更加多样性的回复内容,仍是目前亟待解决的问题。
3 Transformer模型结构
本文利用了Transformer模型进行非目标驱动型对话系统即聊天机器人的构建,且实现了与用户进行开放域内的对话。Transformer模型的本质上是编-解码架构,模型的整体结构如图1所示。
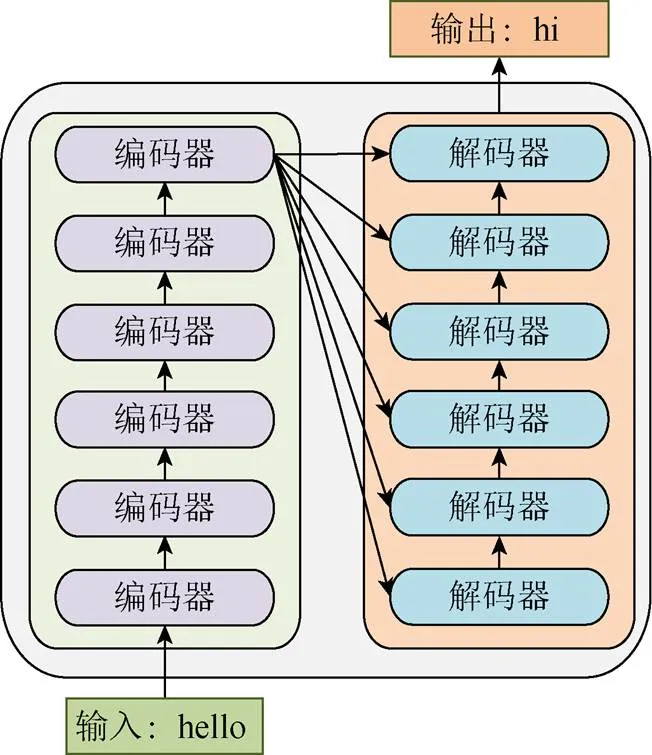
图1 Transformer模型整体结构图
其中编码和解码模型分别由6个编码器和解码器组成。每个编码器和解码器的结构分别如图2所示。编码过程中,数据首先经过自注意力(Self-attention)模块得到加权之后的特征向量,再经过前馈神经网络得到输出。解码器比编码器中多了编-解码注意力模块,用于得到解码阶段当前时刻输出与编码阶段每一时刻输入之间的相关关系。
自注意力机制是Transformer模型最核心的部分,捕捉一个序列自身单词之间的依赖关系,根据上下文信息对句子中的单词进行编码,使得单词向量中蕴含丰富的上下文信息。计算过程中,输入序列的每个单词的词嵌入向量分别与3个权重矩阵相乘得到对应的、及向量,然后将当前单词的向量与输入序列中其他单词的向量作点积运算得到相关程度,进行归一化后的结果再通过Softmax激活函数得到概率分布,最后将概率分布作为权重值对每个单词的向量进行加权,得到当前时刻单词的向量表示,即
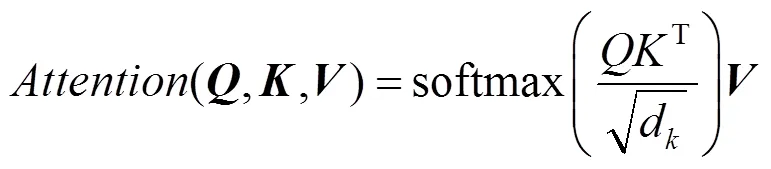
4 个性化对话模型设计
4.1 通用对话模型
本文实验过程中首先进行通用对话模型的设计与实现开放域多轮日常对话过程。本文中设计的通用对话模型基于编-解码结构,其中编码端和解码端分别由Transformer编码器和解码器组成。模型的整体结构如图3所示。

图3 通用对话模型结构图
编码端和解码端的层数均为12层,为了考虑上下文情境信息,在编码阶段,将历史对话内容编码,其中可能包含多个句子序列,每个序列独自输入模型,与当前时刻输入共同作用影响解码阶段的预测输出。
4.2 模型输入编码
利用词嵌入方法Word2vec,将输入对话数据转换为词向量,维度为512维。由于Transformer模型没有捕捉序列数据的能力,因此利用位置编码(Positional Embedding)的编码序列中单词位置信息,使模型可以区分序列中不同位置的单词。位置编码的向量维度与词嵌入向量的维度相同,通过式(2)和(3)进行单词的位置编码,即
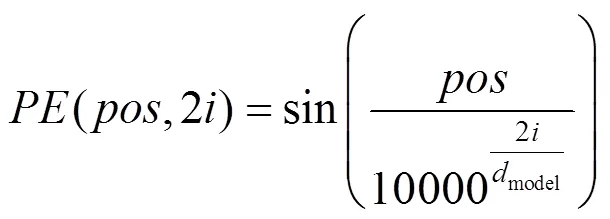

其中,为单词的位置;为单词的维度。得到序列中每个单词的位置编码之后,将其值与单词的词向量做加和操作,得到每个单词的输入向量。
4.3 多头注意力机制
在自注意力机制的基础上,模型中提出了多头注意力(multi-head attention)机制,每个自注意力模块称为一个注意力头。多头注意力机制的计算过程中,首先对输入序列经过个不同的注意力头进行计算,然后将这个不同的特征矩阵按列拼接为一个特征矩阵,再通过一个全连接层,压缩为与单个注意力头维度相同的矩阵,得到多头注意力模块输出结果。计算如下
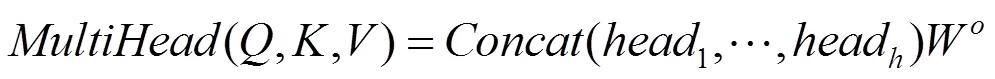

本文实验过程中,编码和解码端的多头注意力层均包含12个注意力头,整合方式不是标准Transformer模型中的方式,而是求所有注意力头的对应维度上的平均值,以减少降维过程中信息的损失并加速模型训练。
4.4 个性化对话模型
通用对话模型可以进行多轮的对话,但过程中未考虑个性化信息。没有个性化特征的聊天机器人在对话过程中可能会产生语义不一致的现象,如前文提及自己为学生,而后文却在上班。使其用户产生剥离感,易使用户意识自己在跟一个虚假的机器人聊天,难以建立长期的情感联系。为解决此问题,本文设计了个性化对话模型,通过赋予聊天机器人个性化特征,使其可以根据自身的特征产生合适的回复内容,提升用户的聊天交互体验。
本文设计的个性化对话模型是基于编-解码框架,其中编码端和解码端分别由Transformer模型的编码器和解码器组成,具体层数设置均与通用对话模型相同。与之不同的是,个性化对话模型需要考虑个性化特征信息,并在模型的输入部分添加个性化信息进行编码,模型编码阶段结构如图4所示。
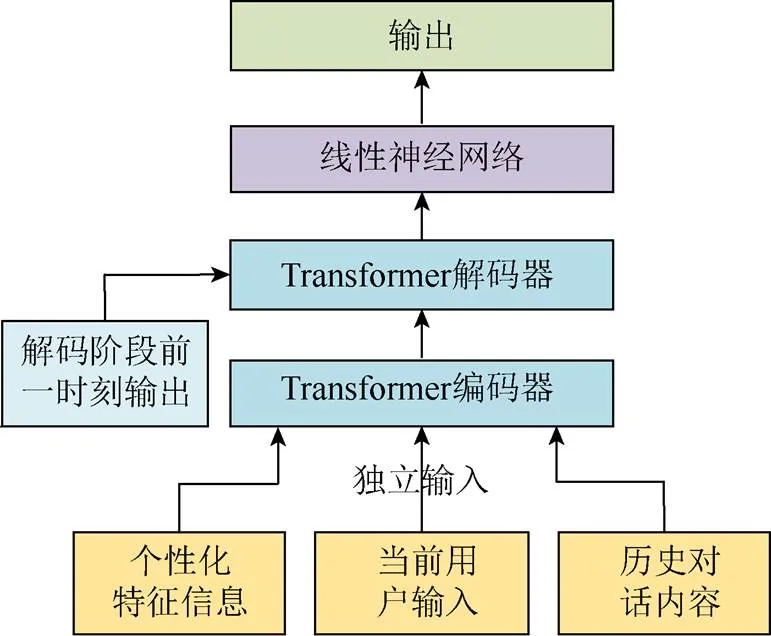
图4 个性化对话模型结构图
编码过程除了对当前用户输入和历史对话进行编码,最关键的部分是对个性化特征信息进行编码,本文中的个性化特征指一组对人物进行描述的句子信息,编码后的个性化特征向量与当前输入和历史对话内容共同指导解码阶段的回复生成过程。
解码过程中,编-解码注意力模块可以确定当前时刻用户输入、历史对话内容以及个性化特征信息对当前时刻输出的影响程度。通过综合考虑上下文情境信息和个性化特征信息,个性化对话模型可以生成与上下文连贯一致并且符合特定的个性化特征的回复内容。
4.5 模型优化
4.5.1 标签平滑算法
在Seq2seq模型的训练过程中,通常通过最小化句子序列的负对数似然概率优化模型,即
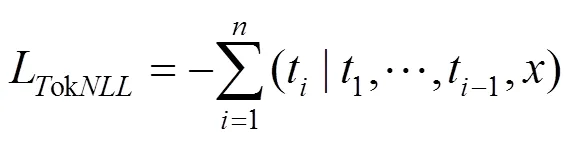
但该训练过程会强迫模型进行非零即一的预测以区分真实数据和生成内容,降低模型的泛化性能。标签平滑(label smoothing)算法通过类似正则项的作用使模型对其预测结果降低自信以解决此问题。利用一个与当前输入无关的先验分布来平滑预测目标的分布函数,通常采用所有的单词的均匀先验分布。标签平滑等价于在负对数似然函数的基础上添加一个KL散度项,即计算先验分布与模型预测输出概率之间的距离,即

通过防止模型将预测值过度集中在概率较大的类别上,从而降低通用回复出现的概率,增加生成回复内容的多样性。
4.5.2 长度惩罚的多样化集束搜索算法
集束搜索算法是Seq2seq模型解码阶段常用的一种算法,其参数为解码过程在每个时刻选择概率最高的个单词作为输出。通过在每个时刻选择概率最高的个单词,该算法最终生成个概率最高的句子序列,并使其最大化,从而生成更加合理的结果,提高生成句子的质量。
由于一个句子序列的概率由多个单词的概率累乘得到,生成的句子序列越长,累乘得到的概率值可能就会越小,因此集束搜索算法倾向于生成较短的句子。Google提出了长度惩罚方法解决这个问题[17],通过降低短序列的概率值,提高长序列的概率值,使模型有更多的机会生成较长的序列,即
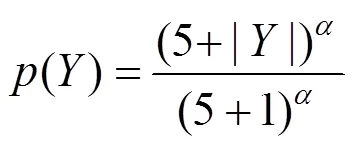
在实验过程中取值为0.6。
集束搜索算法中存在的另一个问题为生成的个句子的差异性不大,多样性较低。通过将生成结果进行分组,组间加入相似性惩罚来降低生成多个结果的相似性,迫使模型生成更加多样化的内容,减少通用回复的出现。
5 实验验证
5.1 数据收集与处理
实验过程利用了2个对话数据集。首先是DailyDialog数据集[18],其中共包含13 118组多轮对话,平均每组对话中包括8轮对话过程。按照8∶1∶1的比例对该数据集进行切分得到训练集、验证集和测试集,划分结果见表1。在训练数据中平均每组多轮对话为7.7轮。
第2个数据集是Persona-Chat个性化对话数据集[19],其中共包含1 155组个性化信息,每组中至少包含5句个性化描述,如“我是一个艺术家。我有4个孩子”。其中共包含10 981组多轮对话,平均每组多轮对话包含14.9轮对话。按照8∶1∶1的比例对数据集进行切分得到训练集、验证集和测试集,划分结果见表2。
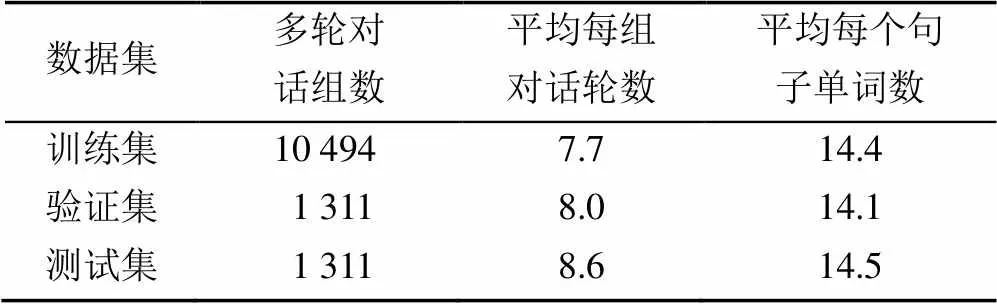
表1 DailyDialog数据集切分结果
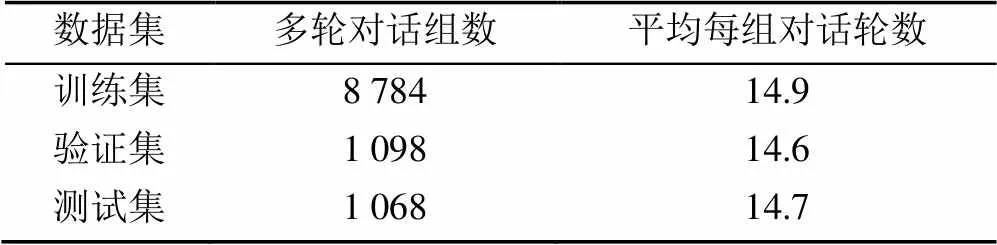
表2 Persona-Chat数据集切分结果
5.2 评价指标
5.2.1 困惑度
困惑度(Perplexity)指标可以用来衡量一个概率预测模型预测样本的好坏程度,困惑度越低代表模型的性能越好,即

其中,Y为一个句子序列中的第个单词。
5.2.2 F1分数(F1-Score)
F1分数是分类问题的一个衡量指标,是精确率(precision)和召回率(recall)的调和平均数,即

F1分数计算过程中,根据预测句子与目标句子序列的单词匹配程度计算精确率和召回率,F1分数越高说明模型预测句子序列的准确度越高,模型的性能越好。
5.3 参数设置
利用DailyDialog数据集训练通用对话模型,并利用Adam优化器优化加入了标签平滑正则项的对数似然函数。训练批次大小设置为128,学习率设置为6.25e-5,当梯度值大于5时进行梯度裁剪。利用Dropout机制防止过拟合现象的发生,概率为0.1。利用Persona-Chat数据集训练个性化对话模型,开始时直接加载通用对话模型初始化参数,然后进行模型的训练,参数设置与通用对话模型相同。
5.4 实验结果
5.4.1 通用对话模型实验对比分析
实验过程采用了3个基线模型:①基于RNN的Seq2seq模型,直接将所有历史对话进行编码;②添加了Attention机制的Seq2seq模型;③HRED模型[8],将上下文对话信息分层编码,且利用双向RNN结构,加入了Attention机制。对比实验结果见表3和表4。

表3 通用对话模型困惑度对比实验结果

表4 通用对话模型F1分数对比实验结果
从表3和表4可看出,基于RNN的Seq2seq 2个模型指标均表现最差,而在添加了Attention机制后结果有了明显的提升,说明Attention机制对编解码结构的效果具有明显的提升作用。而HRED模型通过多层编码结构考虑了更多的上下文对话信息,使其较双向RNN结构和Attention机制模型结果有了更进一步的提升。而本文利用的Transformer模型在对比实验中取得了最好的结果,证明该模型可以产生更加高质量的对话内容。
表5为使用通用对话模型进行对话的示例。可以看出,模型可较为流畅地与人进行开放域的聊天过程,很少生成通用回复,几乎所有回复中都包含有用的信息,并且可以考虑到上下文信息,整个聊天过程可以有效持续进行。

表5 通用对话模型对话示例
5.4.2 个性化对话模型实验结果
为了体现个性化特征对对话过程的影响,从数据集中随机抽取一组个性化特征描述,将其赋予聊天机器人作为其个性化特征,验证聊天机器人能否有效捕捉个性化特征。由于机器评价指标无法判断对话内容中是否包含个性化特征,因此对于个性化对话模型暂利用人工评价的方法进行评价,通过人工判断对话过程中模型产生的对话回复是否符合被赋予的特定的个性化特征来评价模型的性能。表6随机抽取的一组个性化特征描述内容。

表6 随机抽取的个性化特征
表7为使用个性化对话模型进行对话的示例。可以看到,模型可流畅地与人进行开放域的多轮聊天过程,且考虑到上下文和个性化特征信息,如“我喜欢电子游戏”、“我的头发是金色的”等信息均符合被赋予的个性化特征。因此,本文设计的个性化对话模型可以很好地融入个性化特征,实现个性化多轮对话过程。

表7 个性化对话模型对话示例
6 总结与展望
本文主要探索了开放域聊天机器人的回复生成技术。模型通过将当前时刻输入、历史对话以及个性化特征进行编码,指导解码阶段的回复生成过程,实现前后连贯的多轮对话,并且保持一致的个性化特征,同时生成内容多样性较高。实验结果表明,本文设计的模型在困惑度和F1分数评价指标中取得了对比实验的最好结果,并且可以与人类进行持续对话过程,前后逻辑保持一致,很少出现通用性回复,并且符合个性化特征。本本实验过程中直接将所有历史对话内容进行编码来实现多轮对话,可能导致模型不能全面而有效地捕捉上下文信息,因此在未来的研究过程中,需要考虑如何更加高效地从长跨度的历史对话中捕捉有效上下文信息,增强多轮对话能力。直接利用既定的句子形式的个性化特征作为一部分输入进行编码是构建个性化对话模型的一种解决方法,但在实际应用过程中却较难实现,因此如何得到更加通用的个性化特征以及如何利用少量的个性化数据对深度模型进行有效地训练是今后研究的主要方向。
[1] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3(2): 1137-1155.
[2] MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent neural network based language model[EB/OL]. (2020-02-23). http://xueshu.baidu.com/ usercenter/paper/show?paperid=f2fef7f500521c4031ef9794c11c9318&site=xueshu_se.
[3] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EL/OL]. [2020-02-23]. https:// www.researchgate.net/publication/317558625_Attention_Is_All_You_Need.
[4] CHEN H, LIU X, YIN D, et al. A survey on dialogue systems: Recent advances and new frontiers[J]. ACM SIGKDD Explorations Newsletter, 2017, 19(2): 25-35.
[5] SORDONI A, GALLEY M, AULI M, et al. A neural network approach to context-sensitive generation of conversational responses[EB/OL]. [2020-02-23].https://www.microsoft.com/en-us/research/publication/a-neural-network-approach-to-context-sensitive-generation-of-conversational-responses/.
[6] VINYALS O, LE Q. A neural conversational model[EB/OL]. [2020-02-23]. http://www.doc88.com/ p-9991503943118.html.
[7] LI J W, GALLEY M, BROCKETT C, et al. A diversity-promoting objective function for neural conversation models[EB/OL]. [2020-02-23].https:// www.microsoft.com/en-us/research/publication/a-diversity-promoting-objective-function-for-neural-conversation-models/.
[8] SERBAN I V, SORDONI A, BENGIO Y, et al. Building end-to-end dialogue systems using generative hierarchical neural network models[C]//Thirtieth AAAI Conference on Artificial Intelligence. New York: CAM Press, 2016: 3776-3883.
[9] SHANG L F, LU Z D, LI H. Neural responding machine for short-text conversation[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=6a378dcda923a20f3fb021e4bbb53690&site=xueshu_se.
[10] TANG G, MÜLLER M, RIOS A, et al. Why self-attention? a targeted evaluation of neural machine translation architectures[EB/OL]. [2020-02-23]. http:// xueshu.baidu.com/usercenter/paper/show?paperid=1s6v0ts0je6y0gg0u77g0t50ys723028&site=xueshu_se.
[11] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. [2020-02-23]. https://s3-us-west-2. amazonaws.com/openai-assets/research-covers/languageunsupervised/language understanding paper.pdf, 2018.
[12] DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/show?paperid=163v0jq00n460jd0bh1m02b0yd094771&site=xueshu_se&hitarticle=1.
[13] LUO L C, HUANG W H, ZENG Q, et al. Learning personalized end-to-end goal-oriented dialog[EL/OL]. [2020-02-23]. http://xueshu.baidu.com/usercenter/paper/ show?paperid=186j06y09d7j00x05w670tp09v148579&site=xueshu_se.
[14] LI J, GALLEY M, BROCKETT C, et al. A persona-based neural conversation model[EB/OL]. [2020-02-23]. http://xueshu.baidu.com/usercenter/paper/ show?paperid=a94092c9f0f5fcd5f0f694b6a4ee9e99&site=xueshu_se&hitarticle=1.
[15] LIU B, XU Z, SUN C, et al. Content-oriented user modeling for personalized response ranking in chatbots[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2018, 26(1): 122-133.
[16] LUO L C, HUANG W H, ZENG Q, et al. Learning personalized end-to-end goal-oriented dialog[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=186j06y09d7j00x05w670tp09v148579&site=xueshu_se&hitarticle=1.
[17] WU Y H, SCHUSTER M, CHEN Z F, et al. Google’s neural machine translation system: bridging the gap between human and machine translation[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=f6aeebc74cba16edb4c8706df0ba9536&site=xueshu_se&hitarticle=1.
[18] LI Y R, SU H, SHEN X Y, et al. Dailydialog: a manually labelled multi-turn dialogue dataset[EB/OL]. [2020-02-23].http://xueshu.baidu.com/usercenter/paper/ show?paperid=52816efb19417f114ed83f7c54b9b6e7&site=xueshu_se&hitarticle=1.
[19] ZHANG S Z, DINAN E, URBANEK J, et al. Personalizing dialogue agents: I have a dog, do you have pets too?[EB/OL].[2020-02-23].http://xueshu.baidu. com/usercenter/paper/show?paperid=f47c6a2d79c51aac36742a4ab6856254&site=xueshu_se&hitarticle=1.
Personalized dialogue content generation based on deep learning
WANG Hao, GUO Bin, HAO Shao-yang, ZHANG Qiu-yun, YU Zhi-wen
(School of Computer Science, Northwestern Polytechnical University, Xi’an Shaanxi 710072, China)
Dialogue system is a very important research direction in the field of Human–Machine Interaction and the research of open domain chatbot has attracted much attention. There are three main problems in the existing chatbots. The first is that they cannot effectively capture the context, which leads to the lack of logical cohesion in the dialogue content. Second, most of the existing chatbots do not have specific personalized characteristics, resulting in the monotony in the chat process, and the dialogue content may be contradictory. Third, they tend to generate meaningless replies such as “I don’t know” or “I’m sorry”, which greatly reduces users’ interest in chat. The Encoder-Decoder framework based on Transformer was used to build the general dialogue model and personalized dialogue model. By encoding the historical dialogue content and personalized feature information, the model could effectively capture the context and the personalized information and realize multi-round dialogue process, generating personalized dialogue content. The experimental results showed that the dialogue model based on Transformer obtained better results on the evaluation metrics of perplexity and F1-score compared to the baseline models. Combined with manual evaluation, it is concluded that our dialogue model is capable of carrying out multi-round dialogues, with high content diversity and in line with the given personalized characteristics.
deep learning; dialogue system; chatbot; personalization; context aware
TP 391
10.11996/JG.j.2095-302X.2020020210
A
2095-302X(2020)02-0210-07
2019-11-19;
2019-12-27
国家重点研发计划项目(2017YFB1001800);国家自然科学基金项目(61772428,61725205)
王 豪(1996-),男,河南新乡人,硕士研究生。主要研究方向为人机对话系统。E-mail:wanghao456@mail.nwpu.edu.cn
郭 斌(1980-),男,山西太原人,教授,博士,博士生导师。主要研究方向为普适计算、移动群智感知。E-mail:guob@nwpu.edu.cn
