关于重塑数据湖的探讨
2020-05-20安徽刘扬
■ 安徽 刘扬
编者按:大数据时代,可以存储原始的、不受数据类型限制的数据湖被视为信息化建设的技术演进方向。但数据沼泽成为建设数据湖过程中普遍遭遇的难题。如何重塑数据湖、规避数据沼泽成为目前数据湖建设的瓶颈。本文探讨了数据沼泽产生的根源,梳理了重塑数据湖的技术路径,为规避数据沼泽陷阱和建设高质量、高价值的数据湖提供建议。
从信息化建设的实践来看,数据湖随着Hadoop等技术的快速普及而被广泛用于大数据平台的存储与使用。尽管目前对数据湖的定义尚有许多分歧,但其核心理念已得到接受,亚马逊、IBM等科技公司已将数据湖作为向企业级客户提供的重要产品。
由于数据湖最初的理念在于不对原始数据进行数据治理,通过原始数据提升了数据使用的灵活性和低成本,使得数据湖在建设中始终无法回避一个核心难题——数据沼泽。
一旦进入数据湖的数据完全没有经过数据治理,那么在使用时,原始数据自身以及在存储、维护过程中存在的任何缺陷都有可能成为使用障碍,让用户在使用时无从下手,从而减少使用,而使用频率的降低又会使这些缺陷更加难被发现并解决,最终会导致数据湖沦为数据沼泽。但是,如果在进入数据湖时进行数据治理,那么治理成本可能高于经济效益。同时,也有可能在治理过程中舍弃潜在的经济效益,难以体现出数据湖有别于数据仓库的根本价值。
规避数据沼泽陷阱的探索
从规避数据沼泽陷阱的探索来看,主要有三类方向:
一是聚焦简单关联关系数据的分析,在单一系统或模块中构建数据湖。通过人工智能与大数据相结合,直接将结构化、半结构化、非结构化数据一起计算分析。这方面的商业实践已较成熟。
二是专注存储与计算方式的技术革新。这类探索顺应存储和计算分离的技术潮流,充分考虑带宽和内存成本下降速度远快于存储成本的现实情况,将原本的集中式存储改为分布式存储。
三是加强元数据管理。元数据管理的核心思路是将对原始数据的描述编纂成电子目录,其技术实质是数据治理的基础工作。
在实际应用中,第二类与第三类探索通常结合使用,逐步实现数据资产存储从传统数据仓库向数据湖的技术演进。
这些探索在数据湖建设过程中规避了数据沼泽陷阱,但也付出了相应的成本,例如数据湖的数据来源受限、数据存储的复杂性与脆弱性上升、数据入湖时的数据治理等。
实际上,这些探索的实质是解决数据湖建设中经济效益显著或者数据治理成本可控的部分,用确定性收益规避不确定性风险。换言之,没有触及到数据沼泽的产生根源。
数据沼泽的产生根源
事实上,与数据仓库相比,数据湖的最大价值在于入湖数据潜在价值的再发现,最能产出超额收益的部分来源于数据价值发掘过程中的不确定性风险。而数据沼泽的产生根源不在于人工智能等数据价值再发现工具缺乏、数据存储与计算的能力不足,也不在于元数据管理的水平限制,而在于入湖数据的数据间内在关联性的缺失,在于业务逻辑无法完整的体现在入湖数据的数据间内在关联性上。
数据间内在关联性,总体来说可以分为三类:
一是业务逻辑上数据间本质的映射关系。即如果不同的系统或模块在同一个业务逻辑上存在上下游关系,那么在该业务逻辑下这些系统或模块内的数据之间一定存在某种保持不变的特性。(这种映射关系和数据内在的数据映射机制在机理上相通,关于数据内在的数据映射机制可参看笔者拙作《系统通用模块建设思考》)例如在资金使用的业务逻辑下,财务模块的支付数据与采购模块中的合同数据之间的映射关系。
二是系统或模块间的耦合关系。耦合关系在数据层面主要关系到数据的内在一致性,系统或模块间的耦合程度一旦达到数据耦合或更高类型,那么在数据湖建设中无需额外考虑其内在一致性。
三是数据间时空一致性。由于数据湖目前普遍采用分布式存储,不同节点内的数据在同一时点可能存在差异,同时不同系统或模块的数据采集机制也不尽相同,因此数据间时空一致性涉及到数据的更新机制、同步策略、校验方法等,并且直接影响到数据进行关联分析时的可信度、可用性等。
同时,数据湖中业务逻辑直接体现在入湖数据的数据间内在关联性上,不再需要数据仓库中业务逻辑到数据逻辑的人工转换。传统的数据仓库是将业务逻辑由人工操作转换成数据逻辑,即我们通常所使用的ETL等。
这种人工操作主要凭借人对业务逻辑和数据本质的理解,其开发质量取决于用户需求的表达和开发人员对用户表述的了解,开发效率直接受到双方沟通效率的制约。也就是说,一旦入湖数据的数据间内在关联性无法完整的体现业务逻辑,为了数据可用,势必要再次处理数据,从而付出高昂的数据治理成本。
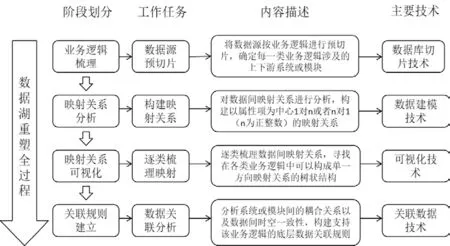
图1 数据湖重塑
重塑数据湖的技术路径
针对数据沼泽的产生根源,重塑数据湖需要建立通用的技术路径,对入湖数据进行全面的数据重构。重塑数据湖的技术路径总体来说如图1所示。
第一阶段,广泛梳理业务逻辑,通过数据库切片技术将数据源按业务逻辑进行预切片(即只提取出数据结构、不同属性项的完整性等关键信息,不进行真实切分),确定每一类业务逻辑涉及的上下游系统或模块。
第二阶段,以业务逻辑为出发点,使用数据建模技术对预切片进行数据间映射关系进行分析,看上下游系统或模块中的数据之间能否以属性项为中心构建出1对n或者n对1(n为正整数)的映射关系。
第三阶段,使用可视化技术逐类梳理数据间映射关系,寻找在各类业务逻辑中可以构成单一方向映射关系的树状结构(或者一一映射结构)。
第四阶段,回溯该树状结构所涉及的数据源,分析其所包含系统或模块间的耦合关系以及数据间时空一致性,通过关联数据技术构建支持该业务逻辑的底层数据关联规则。
总结与展望
本文探讨了数据沼泽产生的根源,梳理了重塑数据湖的技术路径。但是,在重塑数据湖的过程中还可能遇到一些复杂情况,比如说复杂的数据间映射关系(如n对m、非结构化数据间映射关系等)、数据间时空不一致情况下底层数据关联规则的建立等。对这些复杂情况的处理解决还需要进一步的分析探讨。
