基于启发式强化学习的动态CRE偏置选择算法
2020-05-18邓逸飞
谷 静,邓逸飞,张 新
(西安邮电大学 电子工程学院,西安 710121)
0 概述
第五代移动通信技术(5G)具有超高的频谱利用率和能效,和第四代移动通信技术(4G)相比,其传输速率和资源利用率提高了至少一个数量级,并且在无线覆盖、传输时延、系统安全和用户体验等方面也有显著提高[1]。异构网络作为第三代合作伙伴计划(3GPP)组织在长期演进(Long Term Evolution,LTE)系统中所提出的网络种类,在4G网络中解决了业务多样性的问题。但是,在异构网络中位于低功率基站附近和宏小区边缘的宏用户设备(Macro User Equipment,MUE)会受到低功率基站较强的信号干扰,因此,3GPP组织在长期演进扩展(Long Term Evolution-Advanced,LTE-A)通信系统中引用了小区范围扩展(Cell Rang Expansion,CRE)技术[2],以均衡宏基站与微基站之间的负载。由于引入CRE后宏小区边缘的用户设备依然受到较强的信号干扰,因此扩展区域中的小区间干扰协调(Inter Cell Interference Coordination,ICIC)成为研究人员关注的热点。
文献[3]提出家庭基站(Femtocell)合作模型CRE框架,提高了家庭基站接入点范围扩展系统的灵活性,但未提高宏小区边缘用户的通信质量。文献[4]提出一种分布式自适应CRE偏置方法,其基站间信息交互不足,CRE偏置不能达到全局最优。文献[5-7]有效提高了宏小区用户的整体吞吐量并实现了基站负载均衡,但所用算法过程过于复杂。文献[8]针对上行链路干扰提出一种虚拟软切换方法,该方法对边缘用户信干噪比的提升效果较差。文献[9]提出一种基于大数据驱动框架和多臂Bandit算法的在线学习机制,但其样本数量过少,不符合实际要求。
本文提出一种基于启发函数的HSARSA(λ)算法,以动态设置Femto基站(Femto-Base Station,FBS)的CRE偏置值。每个FBS独立地从经验中学习CRE偏置值,从而最大限度地提高宏小区边缘用户的整体通信速率,实现较好的负载均衡效果。
1 系统模型与偏置方法
1.1 系统模型
本文系统由双层异构网络构成,可供选择的低功率基站有微基站(Pico-Base Station,PBS)、FBS以及中继基站(Relay-BS,RBS),如图1所示。该系统选择FBS作为低功耗基站,这是因为近年来超过80%的无线数据吞吐量发生在室内,在上述低功率基站中,FBS体积最小,部署最灵活且成本最低,网络安全性能较高,研究FBS的性能可以更好地解决室内通信问题[10]。在系统中随机分布n个用户设备,其中包括m个MUE以及k个微用户设备(Femto User Equipment,FUE)。所有用户设备采用开放式接入(Open Access,OA)方式,和封闭式接入(Closed Access,CA)相比,OA在用户设备密度较大时优势更加明显[11]。
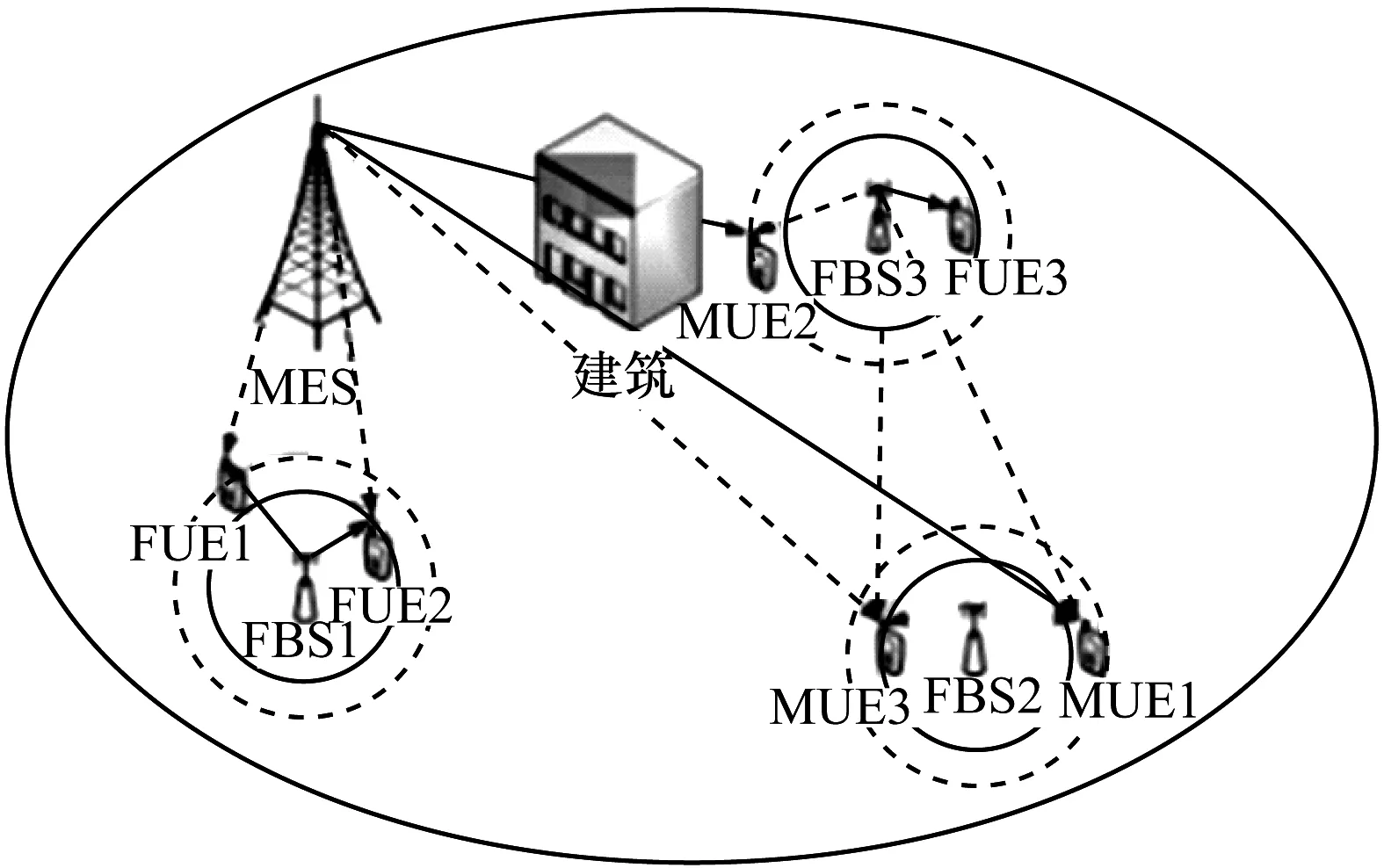
图1 双层异构网络示意图
FBS的传输功率一般为23 dB~30 dB,在存在宏基站(Macro Base Station,MBS)的情况下,FBS的传输速率范围将变小。MBS的发射功率约为45 dB,与FBS的传输功率最少相差16 dB,这使得有过多用户接入MBS,从而造成MBS过载和能效降低的现象,进而导致FBS功率资源浪费。系统中的上行链路并非如此,上行链路中不同基站(Base Station,BS)的信号强度主要取决于其在上行链路的传输功率[12],因此,本文系统只考虑下行链路的传输功率。
图1中的实线为小区当前的范围,虚线为小区应调整的范围。将分布在不同小区的FBS、MUE、FUE分别编号为FBS1、FBS2、FBS3、MUE1、MUE2、MUE3、FUE1、FUE2、FUE3等。系统主要存在以下3种干扰情况:
1)FBS1距MBS较近,FUE1位于FBS1小区边缘且距MBS也较近,这时FUE1将受到MBS较强的信号干扰,应降低FBS1的CRE偏置值使FUE1接入MBS。
2)MUE1位于MBS小区边缘处且距MBS较远,MUE1距FBS2很近但位于FBS2小区边缘外。MUE1经过长距离路径损耗与阴影衰落后接收到的MBS信号质量大幅降低,同时还会受到来自FBS2与FBS3下行链路的信号干扰,应增大FBS2的CRE值使MUE1接入FBS2。
3)MUE2到FBS3的距离与MUE2到MBS的距离相差不大,但MUE2位于建筑物后,导致其接收MBS信号受阻。因此,在MBS信号覆盖较弱的建筑密集区,应增大FBS3的CRE偏置值使MUE2接入FBS3。
总结以上3种情况,本文将针对同层与跨层干扰使各种类型基站边缘用户的通信质量与通信速率下降等问题进行分析。在下行链路中,根据系统模型,第i个MUE的信干噪比为:
(1)
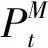
由文献[3]得到路径损耗公式为:
PLm=c(dM)n
(2)
其中,c为常数,dM为用户到基站的距离,n为介质指数。
将式(2)代入式(1)中得到式(3):
(3)
同理可得到第i个FUE的信干噪比为:
(4)
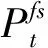
由香农公式可得第i个MUE到MBS的通信速率为:
(5)
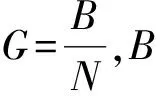
同理可得第i个FUE到第k个PBS的通信速率为:
(6)
所有用户的总通信速率为:
(7)
总用户功耗[13]为:
PMD=N[PW·Rt+Ps(1-Rt)]
(8)
其中,PW为用户活跃时的总功耗,PS为用户非活跃时的总功耗。系统最终能效为:
(9)
其中,PMA为系统总功耗,PBS为MBS的发射功率,S为宏小区的面积。
1.2 CRE偏置方法
本文在考虑参考信号接收功率(Reference Signal Received Power,RSRP)大小的基础上,通过评估导频信号(参考信号)的强度来触发移交程序。用户在比较来自各基站参考信号的功率大小后,会连接到信干噪比相对较高的基站。此外,使用CRE将偏压值加到FBS发射信号上可使更多的用户连接到FBS,相当于将FBS小区范围人为扩大。若MBS和PBS的发射功率满足以下关系:
此时,用户会连接到MBS。若MBS和PBS的发射功率满足以下关系:
此时,用户会连接到FBS。MBS和PBS的发射功率差会使得边缘用户受到相邻小区基站信号的干扰[12],因此,需要通过调整CRE偏置值(Δbias)来降低边缘用户受到的干扰。
传统经验将CRE偏置值设定为6 dB,华为公司提供的GRE偏置值为9 dB。下文以边缘用户的平均吞吐量为参考来寻求合理的GRE偏置值。
2 基于HSARSA(λ)算法的CRE偏置选择
通过调整GRE偏置值来降低边缘用户受到的干扰,既要考虑各基站间的信息交互,又要根据时延与用户分布的变化来动态调整偏置值。经验偏置值与其他算法基本无法简单有效地解决最佳偏置值的选择问题。为此,本文在强化学习(Reinforcement Learning,RL)的基础上提出一种基于启发函数的改进SARSA(λ)算法,即HSARSA(λ)算法。和SARSA(λ)算法相比,HSARSA(λ)算法的奖赏反馈更快,其学习性能显著提高。
2.1 强化学习与SARSA(λ)算法
RL是人工智能体实现自主行为的理论基础,其对策略和状态具有强大的表征能力,能够模拟复杂的决策过程。RL还赋予人工智能体自监督学习能力,使其能够自主与环境交互,在试错(Trial and Error)中不断进步[14]。RL作为人工智能领域的一个重要分支,被认为是实现类人工智能的关键,受到学术界和工业界的广泛关注。RL主要以马尔科夫决策过程为基础,该过程用状态(State)、动作(Action)、状态转移率(Possibility)和奖赏(Reward)构成的四元组{s,a,p,r}表示[15]。其中,动作与状态构成动作状态表,用以表示在某种状态下对根据策略π执行的动作进行的价值评估,也称为状态-动作对值函数,具体如下:
Qπ(s,a)=E(R|st=s,at=a)
(10)
式(10)表示状态-动作对值函数是在反馈奖赏R下状态值St等于某一状态S、动作值at取某一动作a时的数学期望。
最佳Q表值为:
(11)
人工智能体在每种状态下能获得最佳动作的策略为:
(12)
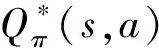
目前,诸如Q-Learning、TD(λ)、SARSA等强化学习算法已经在理论和应用方面取得较多成果[16]。SARSA算法借鉴Q-Learning算法的思想并利用TD算法的核心理论,使得行为决策与值函数迭代的一致性得到保障[17],这表明在学习控制方面SARSA算法优于Q-Learning算法。SARSA(λ)算法在SARSA算法的动作-状态对值函数更新过程中加入了资格迹,如下:
(13)
其中,γ与λ均为折扣因子。
资格迹是基于有效跟踪原理形成的多步在线学习理论,其能有效地使原算法在获得奖赏时更贴近目标值。但是,SARSA(λ)算法在新环境中学习速率较慢,忽略了很多有价值的信息。由于缺乏有效的策略选择机制,SARSA(λ)算法在状态空间需要多次遍历才能收敛。引入启发函数对SARSA(λ)算法在贪婪选择与状态动作对更新时进行改进,可使其在策略选择与汇报奖赏中取得更快的学习速率和更多的有效信息。
2.2 HSARSA(λ)算法
2.2.1 启发函数
启发式强化学习(HARL)采用启发函数来影响人工智能体在学习中的动作选择。文献[18]较早提出启发加速的Q-Learning算法,启发函数Ht(st,at)表示在当前状态下执行此动作的重要性。该方法将经验值作为启发信息,给特定行动加以奖赏,并可作为约束条件来缩小搜索范围使算法更快达到收敛效果。
对于某一状态st,启发值Ht(st,at)只有普遍高于值函数Qt(st,at)的变化值时才能影响动作选择,且要尽量减小误差。启发函数与策略紧密相关,选择动作的策略是决定整个过程是否更接近最优状态的重要因素。策略从形式上可定义为:
π(s)=argmax[Qt(st,at)+μHt(st,at)β]
(14)
其中,μ∈R,β∈R均为评定启发函数重要性的参数,数值越大其影响越大。在式(14)的基础定义下,启发函数可定义为:
(15)
2.2.2 更新公式
SARSA(λ)算法在选择动作时使用ε-贪婪策略,HSARSA(λ)算法将ε-贪婪策略改进为:
(16)
上述改进可以使人工智能体在根据策略选择动作时通过Ht(st,at)来分析动作的优劣,不断保留优势摒弃劣势,有效减少了无用搜索,最终使算法加速收敛。
2.2.3 算法流程
HSARSA(λ)算法将系统模型中的偏置值bi={CRE1,CRE2,…,CREi,…,CREn}和用户的SINR分布值与HSARSA(λ)算法中的状态表和动作表相结合。动作是决定最终结果的因素,因此将偏置值CREi的分布设定为动作分布表。状态是在执行动作后所造成的影响效果。将CRE偏置值代入路径损耗公式可求出偏置范围ΔL,根据ΔL可求出边缘用户的信干噪比。将调整CRE偏置值后会受影响的用户信干噪比分布列为状态表,再根据动作和状态建立值函数表Qπ(SINRi,bi),HSARSA(λ)算法流程如图2所示。
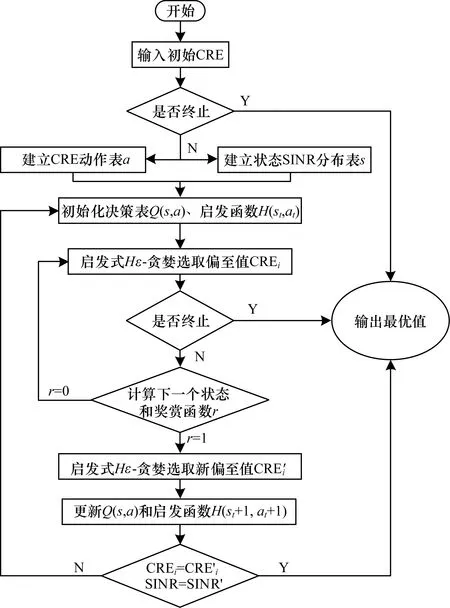
图2 HSARSA(λ)算法流程
HSARSA(λ)算法的伪代码为:
Begin:
建立动作表bi
建立状态表SINRi
初始化Qπ(SINRi,bi),et(SINRi,bi)
For each episode:
Ⅰ.在当前状态下,用Hε-贪婪策略选取Ht(SINRi,bi)动作bi
Ⅱ.若当前动作不为最优,则重复以下步骤:

B.在当前新状态SINR′i下,利用Hε-贪婪策略在SINR′i中选择新的偏置值b′i
Ⅲ.更新Ht(SINR′i,b′i)与Qπ(SINR′i,b′i)
δ=R+γQπ(SINR′i,b′i)-Qπ(SINRi,bi)
et(SINR′i,b′i)=et(SINRi,bi)+1
Ⅳ.更新状态动作对表
Q′π(SINRi,bi)=Qπ(SINRi,bi)+αδet(SINR′i,b′i)
et(SINR′i,b′i)=γλet(SINR′i,b′i)
直到SINRi=SINR′i,bi=b′i,算法终止
其中,α为学习率
在本文系统中,当人工智能体发现新的状态时,如果一直将状态添加到Q表中,Q表值就会增加,这违背了内存约束条件,且会延长学习时间。为解决该问题,使用经验偏置值以实现更快的收敛。由于经验偏置值较易得知,在开始学习和发送数据前,可用试错法检查所有的经验偏置值以缩短学习时间。
所有用户的共同偏置值虽然不是每个用户的最优偏置值[19],但其通常较接近最优偏置值。引入共同偏置值可减小内存并加快收敛速度。当用户移动到另一个FBS信号覆盖区域时,Q表数据即使发生变化也仍具有相似性,在一种情况下获得的数据也有助于在另一种情况下的学习[20]。使用这些数据作为下一次学习的初始值,即使情况不同,用户也会学习环境以进行Q表的更新。
3 实验结果与分析
本文采用蒙特卡罗仿真方法,在Matlab2014R环境下进行实验。实验参数如表1所示[10,18],设置1个MBS和6个FBS,结果取20次实验的平均值。

表1 实验参数设置
根据服务质量(Quality of Service,QoS)评判标准,本文对系统边缘用户的通信速率、能效以及吞吐量进行分析。
从图3可以看出,通信较差与通信较好的用户已进行均衡化处理,两类用户的通信质量趋于一致,即采用HSARSA(λ)算法得到的CRE偏置值能有效均衡边缘负载,使整个系统的通信质量得到提高。
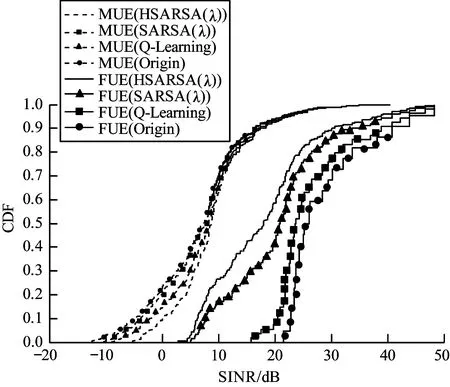
图3 MUE与FUE的SINR累积分布
从图4可以看出,随着用户分布量的增加,应用Origin、Q-Learning、SARSA(λ)和HSARSA(λ) 4种算法得到的系统用户平均吞吐量逐渐上升。当用户分布量超过0.3时,系统用户的平均吞吐量均显著上升,当用户分布量为0.5~0.7时,应用HSARSA(λ)算法得到的系统用户平均吞吐量比SARSA(λ)算法高约7%,比Q-Learning算法高约15%。

图4 不同算法的系统用户平均吞吐量分布
Fig.4 Average throughput distribution of system users of different algorithms
从图5可以看出,随着边缘用户分布量的增加,应用Origin、Q-Learning、SARSA(λ)和HSARSA(λ) 4种算法得到的系统边缘用户的平均吞吐量逐渐提升。当边缘用户分布量为0.6~0.8时,应用HSARSA(λ)算法得到的系统边缘用户平均吞吐量比SARSA(λ)算法高约6%,比Q-Learning算法高约12%。由此可知,HSARSA(λ)算法可使系统边缘用户的吞吐量得到较大提升。
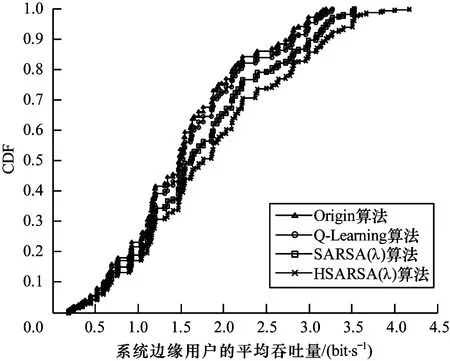
图5 不同算法的系统边缘用户平均吞吐量分布
Fig.5 Average throughput distribution of system edge users of different algorithms
从图6可以看出,HSARSA(λ)算法的平均能效最高,该算法在保证宏小区基本通信质量的前提下可大幅提高小区边缘用户的通信速率。HSARSA(λ)算法的平均能效比SARSA(λ)算法高11%,比Q-Learning算法高13%。

图6 不同算法的平均能效对比
Fig.6 Comparison of average energy efficiency of different algorithms
从图7可以看出,随着学习幕数的增加,Q-Learning、SARSA(λ)和HSARSA(λ)算法寻找最优CRE偏置值的步数逐渐减少。当学习幕数为15节时,HSARSA(λ)算法已收敛,SARSA(λ)、Q-Learning算法的收敛速率分别为40和60。HSARSA(λ)算法收敛时步数小于Q-Learning、SARSA(λ)算法,这表明HSARSA(λ)算法的收敛速率和搜索效率比其他2种算法更优。从图8可以看出,随着学习幕数的增加,Q-Learning、SARSA(λ)和HSARSA(λ)算法获得奖赏的数量均呈现出先降后增的趋势。当学习幕数为0~15节时,3种算法获得奖赏的数量均逐渐降低,其中,HSARSA(λ)算法的降幅最小。当学习幕数超过15节时,HSARSA(λ)算法获得的奖赏数量逐步上升。在学习幕数增加的过程中,当学习幕数相同时,HSARSA(λ)算法得到的奖赏更多,这表明HSARSA(λ)算法每步搜索的结果均比其他2种算法更接近最佳值。
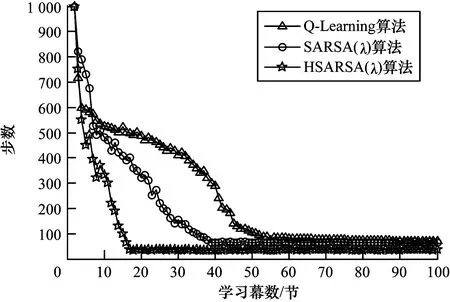
图7 不同算法的收敛性能对比
Fig.7 Comparison of convergence performance of different algorithms
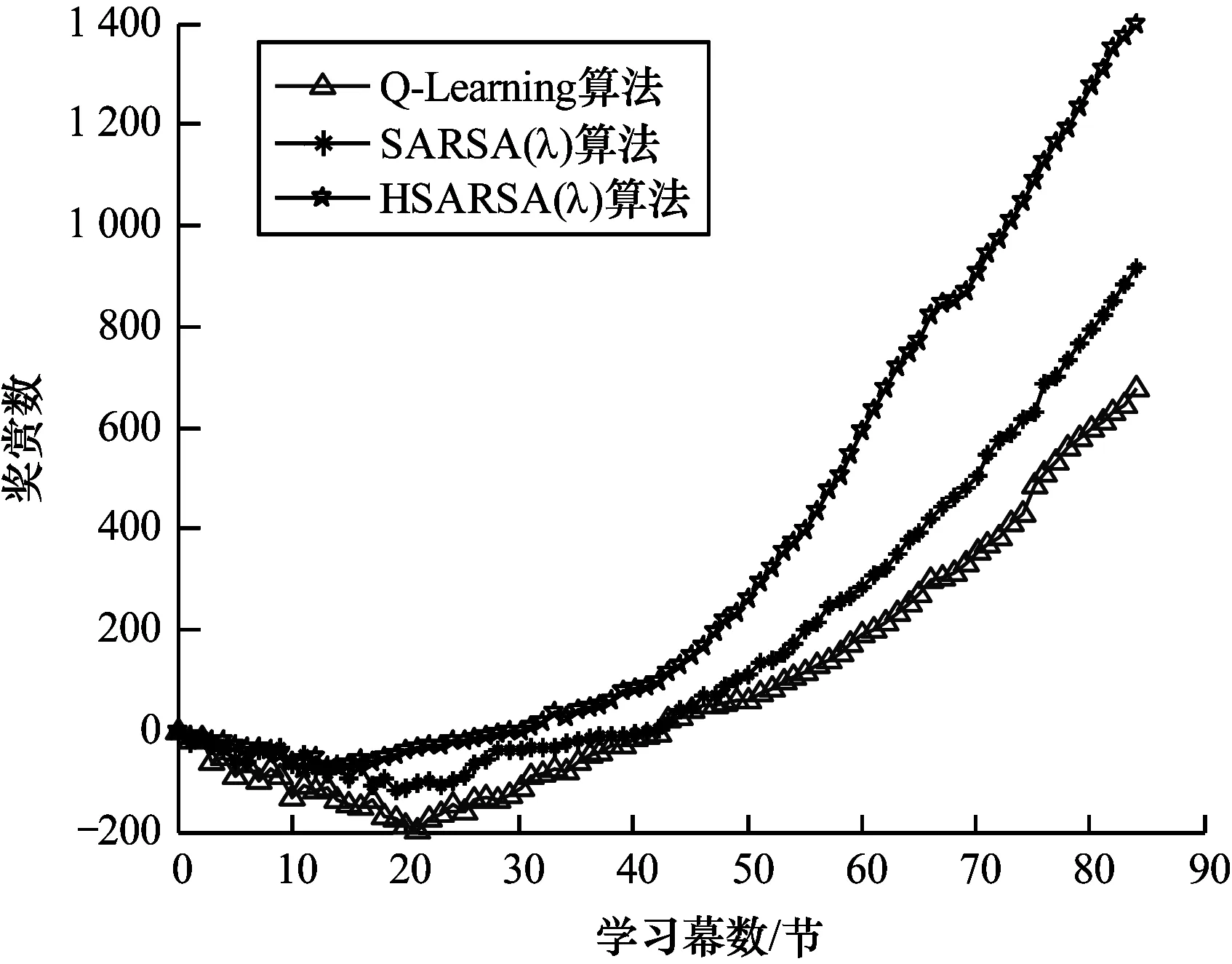
图8 不同算法获得奖赏的能力对比
Fig.8 Comparison of ability of different algorithms to obtain rewards
4 结束语
本文采用启发函数对强化学习中的SARSA(λ)算法进行改进,提出一种HSARSA(λ)算法,以动态设置FBS的小区范围扩展偏置值。该算法使宏基站功率资源卸载分流的同时使得微基站功率资源得到充分利用,从而实现系统的负载均衡。仿真结果表明,相比Q-Learning、SARSA(λ)算法,HSARSA(λ)算法的收敛速率和用户通信速率较高,其能同时保证宏用户与边缘用户的通信质量。下一步将在本文算法的基础上研究频谱资源的有效利用问题,以提升系统的通信质量。
