一种抗噪的移动时间势能聚类算法
2020-05-18陆慎涛葛洪伟
陆慎涛,葛洪伟
(江南大学 a.江苏省模式识别与计算智能工程实验室; b.物联网工程学院,江苏 无锡 214122)
0 概述
聚类算法是一种无监督的学习方法,其遵循一定的规则将数据分成若干个类别,满足同一类别数据尽可能相似、不同类别数据尽量相异的原则,并在不同领域聚类分析都作出了重要贡献,如模式识别[1]、生物信息[2-3]、大数据分析[4]等。当前聚类分析引起了研究人员的关注,并提出多种典型的聚类算法,如基于划分的聚类算法(K-means[5-6]、K-medoids[7]等)、基于层次的聚类算法(Chameleon[8]、Cure[9]等)、基于密度的聚类算法(DBSCAN[10]、DPC等)和基于网格的聚类方法聚类算法(STING[11]、WAVECLUSTER[12]等)。这些聚类算法虽然有着较好的聚类效果,但大部分算法对含噪声复杂的数据集的聚类效果较差,影响算法的实际应用。
文献[13]提出一种移动时间层次聚类算法TTHC,该算法按照数据点本身的势能和数据点与父节点的相似度构建边缘加权树,依照提前设置的类簇中心个数使用层次聚类得到结果。由于TTHC算法采用了全新的基于移动时间的相似性度量准则,相对于传统的聚类方法,TTHC算法具有高效便捷的特点,可取得较优的聚类结果与聚类精度。但TTHC算法对数据集进行聚类时,无法识别出数据集中存在的噪声数据点,聚类结果容易受到噪声数据的影响。
本文提出一种抗噪的移动时间势能聚类算法(APCTT)。该算法依照相似度来寻找各数据点的父节点,从而获得各数据点和父节点之间的距离,并按照该距离以及数据点本身的势能值得到λ值,根据λ值递增曲线找到数据集中的噪声点,并聚到一个新类簇,对去除噪声点后的数据集根据数据点和父节点之间的距离进行层次聚类以获得聚类结果。
1 移动时间层次聚类算法及其缺陷分析
1.1 TTHC算法
TTHC算法是基于势能的聚类来计算各数据点的势能值。数据点之间的势能Φij定义如下:
(1)
其中,rij为点i与点j的欧氏距离,δ是用来防止发生rij为零。minDi是点i到其他各点的最小距离,其与δ的计算方式如式(2)、式(3)所示:
minDi=minrij≠0,j=1,2,…,N(rij)
(2)
δ=mean(minDi)/S
(3)
其中,N是数据点个数,S是比例因子,设置为1,mean是求平均值的函数。在得到每两个点之间的势能Φij后,那么数据点的势能Φi定义如下:
(4)
遵照牛顿运动定律,质点间引力大小如下:
Fij=|Φi-Φj|/rij
(5)
质点的加速度如下:
(6)
因此,质点从数据点i移动到数据点j所需时间如下:
(7)
数据点i和数据点j的相似度定义如下:
(8)
父节点的定义如下:
(9)
其中,Si为数据点i和父节点parent[i]的相似度,那么Si的定义如下:
Si=Si,parent[i]
(10)
1.2 TTHC算法缺陷分析
TTHC算法虽然方便快捷,但是并不能识别一些数据集中存在的噪声数据点,即无法处理这些噪声数据点,因此对这些数据集进行聚类后的结果也不准确。
如图1(a)所示的数据集,深色点是噪声数据点,采用TTHC算法聚类后获得的结果如图1(b)所示。从图1(b)可以看出,使用TTHC算法进行聚类后获得的结果和原始数据集有着较大误差,很多数据点都被分配了错误的类别,这是由于TTHC算法不能识别数据集中的噪声数据点,影响到了TTHC算法的聚类效果与精度。因此,如何使算法自适应地识别数据集中的噪声数据,并对噪声数据点处理后的数据集进行聚类,是进一步研究分析的内容。

图1 缺陷分析示例
2 APCTT算法
2.1 噪声点识别
APCTT算法首先定义λ值,λ值是数据点与父节点的距离和数据点的势能的绝对值的比值,通过构造λ值的递增曲线来识别数据集中的噪声数据点。定义1即数据点是否为噪声数据的考量指标。通过分析可以发现,噪声数据点的势能值往往比正常数据点的势能值大,并且噪声数据点到父节点的距离也比正常数据点到父节点的距离大。因此,噪声数据点的λ值和正常数据点的λ值差异明显,可以根据λ值来识别噪声数据点和正常数据点。
定义1λi是数据点与父节点之间的距离和数据点势能的绝对值的比值,如式(11)所示:
λi=ρi/|Φi|=ρi/(-Φi)
(11)
在式(11)中,由于数据点的势能都是负值,因此数据点的势能的绝对值等于势能的相反数。在一般情况下,数据集中的噪声数据点的数量远远少于正常数据点,而且噪声数据点的分布比较稀疏,所以它们的势能值都比较大,又由于势能恒为负值,因此它们势能的绝对值比较小,此外这些噪声数据点和父节点的距离也比较大,但是数据集中的非噪声数据点分布较之噪声数据点会更密集,因此其势能比噪声数据点势能要小得多。噪声点判定示意图如图2所示。
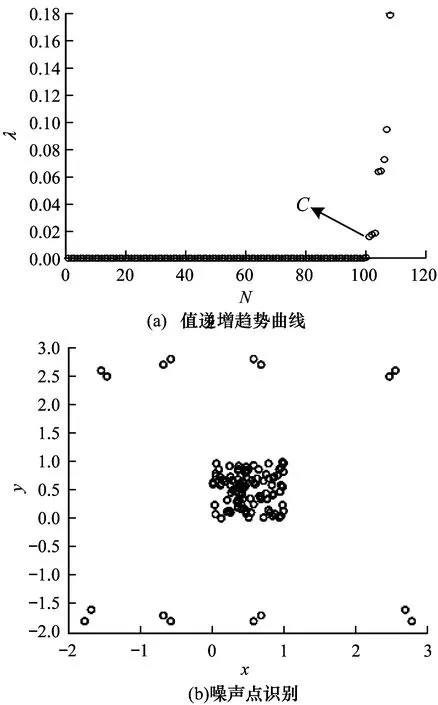
图2 噪声点判定示意图
因为势能等于负值,所以非噪声数据点的势能的绝对值就比较大,和数据集中的噪声数据点相比,这些非噪声数据点和父节点的距离也相对较小。通过绘制数据点的λ值递增曲线,可以在λ值的递增曲线上发现,噪声数据点和正常数据点之间存在一个拐点,图2(a)中的点C即为数据集的拐点,递增曲线上位于拐点前面的数据点为正常数据点,递增曲线上位于拐点后面的数据点为噪声数据点,图2(b)为对数据集识别噪声数据后的结果,其中,分布在图中上下的圆点是数据集被识别出来的噪声数据点。从图2(a)和图2(b)可以看出,通过在λ值递增曲线上寻找拐点,从而通过找到λ值的递增曲线上的拐点识别出数据集中的噪声数据点这一方法是可行的。识别出数据集中的噪声数据点后,对分离出噪声数据点之后的数据集进行下一步算法处理。
2.2 算法描述
数据点之间的相似度基于质点在数据点间的移动时间得到,然后基于数据点之间的相似度来寻找父节点。根据每个数据点与其父节点的距离来生成边缘加权树,再基于此边缘加权树采用层次聚类的方法来取得聚类结果,其中边缘加权树中的权值即为数据点与父节点的距离,采用层次聚类之后再取得聚类结果。APCTT算法步骤描述如下:
步骤1按照式(1)~式(10)计算各数据点势能值与数据点之间的相似度,依据相似度寻找各数据点的父节点,再计算数据点到其父节点的距离。
步骤2根据式(11)计算各个数据点的λ值,按照λ值大小绘制递增曲线,寻找递增曲线中的拐点,通过曲线的拐点来完成噪声数据的识别。
步骤3将识别出的噪声数据聚到一个新的类簇。
步骤4对分离出噪声数据后的数据集根据数据点与父节点的距离作层次聚类,获得聚类结果。
2.3 算法时间复杂度分析
APCTT算法的时间复杂度由计算势能与相似度以及距离、对λ值进行升序排序、基于数据点到父节点的距离使用层次聚类三部分构成。假定有n个数据点,那么对数据点之间的距离与相似度和数据点势能的计算需要的时间复杂度是O(n2),对λ值作升序排序所需的时间复杂度是O(n2),对去除噪声数据点后的数据集进行层次聚类所需的时间复杂度是O(n2),所以APCTT算法所需的时间复杂度是O(n2)。由于TTHC算法的时间复杂度是O(n2),结合以上分析,相对于原始的TTHC算法,APCTT算法的时间复杂度未增加。
3 实验结果与分析
3.1 实验结果评价指标
本文实验中采取FM[14]、F1-measure[15]和ARI[16]3个评价指标对实验结果作分析。3个评价指标都是位于0~1之间,数值均是越靠近1表示聚类的效果越佳,越靠近0表示聚类的效果越差。
3.2 结果分析
在合成数据集及UCI[17]真实数据集上与各算法作对比实验来检验APCTT算法的性能。算法中使用的距离都默认为欧式距离。
3.2.1 合成数据集的聚类结果分析
表1中的DS1数据集是由4组随机数构成,都是服从正态分布并且期望值都等于0,第1组的数据点个数是200个,标准差为2,中心是(0,0);第2组的数据点个数为200个,中心为(16,11);第3组的数据点个数为400个,标准差为3,中心为(6,13);第4组的数据点个数为800个,标准差为4,中心为(12,0)。DS2数据集是3组服从标准正态分布的随机数,3个中心数据点分别是(0,0)、(3,5)和(6,0),每一组都是有300个数据。DS1数据集和DS2数据集都是不含噪声数据点的。2two2d+n、flame+n是对无噪声数据的数据集添加噪声点后的数据集。运用CSPV算法[18]、PHA算法[19]、TTHC算法和APCTT算法对合成数据集作聚类实验。

表1 合成数据集
图3和图4分别是4种算法在各数据集上实验的聚类结果。表2~表4分别是对不同的数据集使用各算法进行实验所得的3个聚类评价指标值。从图3、图4可以看出,对于DS1和2two2d+n数据集,APCTT算法具有较优的实验结果。从图4(a)、图4(b)和图4(c)可以看出,CSPV算法、PHA算法和TTHC算法不能识别出数据集中的噪声数据点,而从图4(d)可以明显看出,APCTT算法准确地识别出了数据集中的噪声数据点,从而能够提高算法的聚类效果。表2~表4表明,APCTT算法在DS1、DS2、2two2d+n和flame+n数据集上,3个聚类评价指标都高于或者等于TTHC算法。此外,在2two2d+n和flame+n数据集上,APCTT算法可以识别出噪声数据点并且把其归入一个新的类簇,而TTHC算法并不能识别出噪声点。

图3 不同算法在DS1合成数据集上的聚类结果
Fig.3 Clustering effects of different algorithms on DS1 synthetic datasets
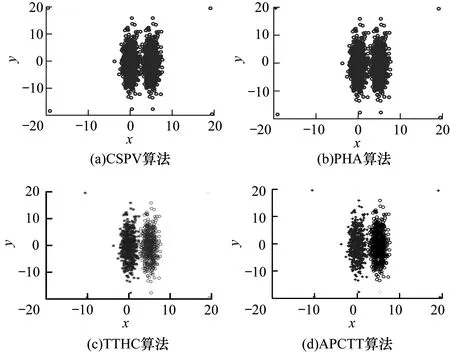
图4 不同算法在2two2d+n合成数据集上的聚类结果
Fig.4 Clustering effects of different algorithms on 2two2d +nsynthetic datasets

表2 4种算法在合成数据集上的FM值

表3 4种算法在合成数据集上的ARI值
表4 4种算法在合成数据集上的F1-measure值
Table 4 F1-measure values of four algorithms on synthetic datasets
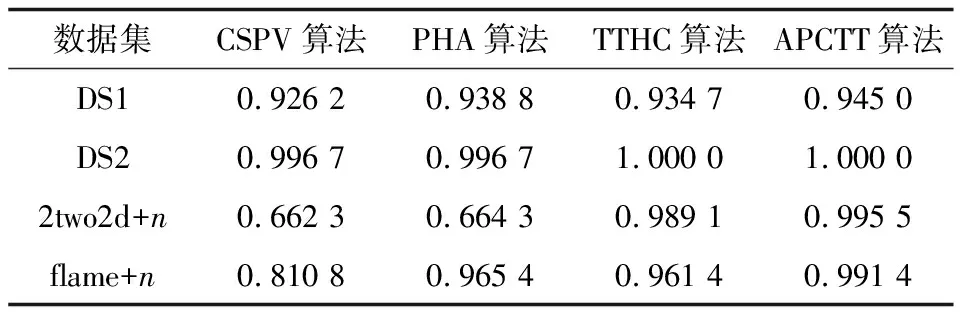
数据集CSPV算法PHA算法TTHC算法APCTT算法DS10.92620.93880.93470.9450DS20.99670.99671.00001.00002two2d+n0.66230.66430.98910.9955flame+n0.81080.96540.96140.9914
从表2~表4可以看出,在DS1、DS2、2two2d+n和flame+n数据集上,APCTT算法的3个评价指标都比PHA算法高,而且APCTT算法能够识别出噪声点,所以聚类结果更好,但是PHA算法由于无法识别噪声数据,导致聚类结果要比APCTT算法差。在DS1、DS2、2two2d+n和flame+n数据集上,APCTT算法的3个评价指标均比CSPV算法高,由于CSPV算法在对数据集聚类时未考虑到数据集中存在的噪声点并去识别,因此导致聚类效果会变差。根据上述分析,相对于TTHC算法不能识别数据集中的噪声数据,且聚类结果容易被噪声数据影响,APCTT算法不但可以识别噪声数据点,而且将噪声点归入一个新的类簇之后可以获得更好的聚类结果。
3.2.2 UCI数据集的聚类结果分析
使用不同算法对UCI数据集(见表5)进行聚类实验,检验APCTT算法的性能,得到的实验结果如表6~表8所示。
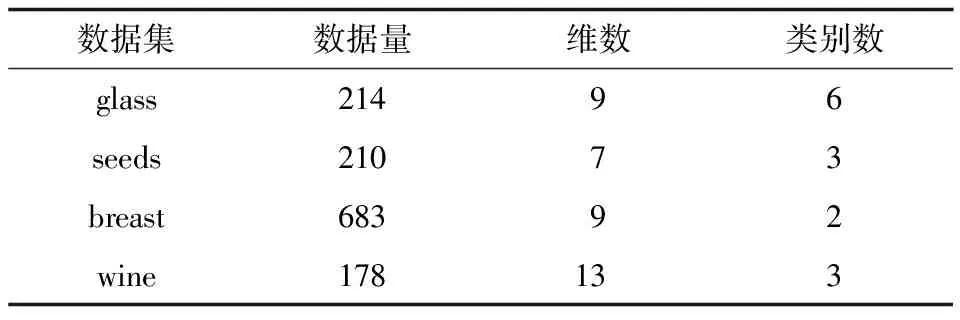
表5 真实数据集
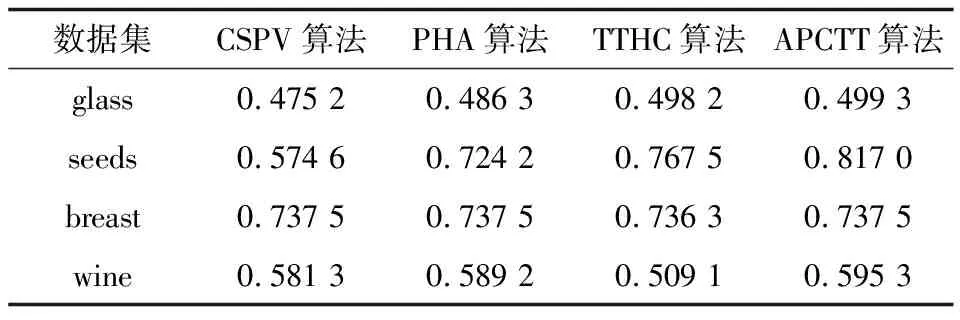
表6 真实数据集FM值

表7 真实数据集ARI值

表8 真实数据集F1-measure值
从表6~表8可以看出,对于glass、seeds、breast和wine数据集,APCTT算法的FM值、ARI值以及F1-measure值都比TTHC算法高。在glass、seeds和wine数据集上,APCTT算法的3个评价指标值都比CSPV算法高。在breast数据集上,APCTT算法的ARI值和F1-measure值都比CSPV算法高,FM值等于CSPV算法。针对glass、seeds和wine数据集,APCTT算法的FM值、ARI值和F1-measure值都比PHA算法高。在breast数据集上,APCTT算法的ARI值和F1-measure值都比PHA算法高,FM值等于PHA算法。
总体来说,APCTT算法在真实数据集上的聚类效果优于TTHC算法、PHA算法和CSPV算法。这是由于APCTT算法能够自动识别真实数据集中存在的噪声数据点然后将这些噪声点区分出来,并归到一个新类簇中,再对区分出噪声数据后的数据集作进行聚类,能够提高聚类效果。
4 结束语
针对TTHC算法无法识别出数据集中存在的噪声数据点,导致算法聚类效果较差的缺陷,本文提出一种抗噪的移动时间势能聚类算法APCTT。该算法将欧氏距离作为度量,在低维度的数据集上可以取得较好的聚类效果。实验结果表明,与原始TTHC算法相比,APCTT算法的FM值、ARI值以及F1-measure值均有明显提高。如何使APCTT算法在处理高维度数据集时,寻找更加有效的距离度量方法来取得较好的聚类效果将是下一步的研究内容。
