基于轻量级神经网络的人群计数模型设计
2020-05-18平嘉蓉张正华
平嘉蓉,张正华*,沈 逸,陈 豪,刘 源,杨 意,尤 倩,苏 权
(1.扬州大学 信息工程学院(人工智能学院),江苏 扬州 225127;2.扬州苏水科技有限公司,江苏 扬州 225000;3.扬州国脉通信发展有限责任公司,江苏 扬州 225000)
0 引言
公共场所下密集人流量的实时统计对社会管理和公共安全具有重要意义[1]。人群计数可以用于商业管理,统计各个区域和出入口的行人流量,可以为商场的管理、服务和销售等提供重要的参考指标[2],进一步研究、修改模型可以为智能交通车流量、智能水利下船数量的视频统计轻量化打下基础。
深度学习与传统手工设计人群计数方法不同,深度学习利用端到端的方式训练神经网络,自动提取目标深度特征,避免主观人为干扰,同时降低了手工设计的人力劳动成本[3]。人群计数是一项计算机视觉任务,将人群图像作为输入,输出相应的人群密度图,最后对密度图进行积分求和输出最终结果[4]。随着计算机视觉技术的逐步发展,大量的人群计数算法被提出,其中,深度学习领域核心的人群计数算法为Multi-CNN[5],Switch-CNN[6]和CSRNet[7]。本文采用VGG-16作为网络框架进行模型的搭建。
在实际的应用场景中,不仅要求更高的检测精度,为了达到实时性的要求,计算复杂度和模型大小也是重要的考虑因素,因此需要对网络模型进行压缩,以减小网络模型的参数量,同时保持网络模型的检测精度[8]。目前,精简模型的主要方法为轻量级网络的设计,例如谷歌提出的MobileNet[9]、旷世科技的ShuffleNet[10]和SqueezeNet[11]等。本文利用Xilinx公司提供的神经网络量化工具DNNDK对网络压缩量化编码,生成轻量级神经网络,使人群计数得以在现场可编程门阵列(Field Programmable Gate Array,FPGA )上实现。
本文针对轻量级神经网络的生成及部署问题,选取FPGA的硬件加速器来提高计算效率,减小功耗。FPGA具有低功耗和可重构性等特点[12],运用Xilinx官方提供的神经网络量化工具,对训练好的网络进行量化压缩编码,生成适用于深度学习网络的硬件加速器,最终在FPGA上实现人群计数。
1 基于VGG-16的卷积神经网络重构
为了更好地实现人群计数,同时考虑FPGA硬件计算能力有限,采用以结构简单著称的VGG-16模型[13]。
VGG-16网络模型共包含13个卷积层、3个全连接层以及5个池化层。在对VGG-16网络的重构中,考虑到硬件的计算能力,为实现缩小计算量的初衷,取VGG-16网络中前10层卷积层作为基础模型;以人群计数为目标,模型输出应为密度图,为使输出密度图积分后得到人群数更准确,在模型最后加入2层卷积层及1层上采样层。该模型为生成轻量级神经网络奠定了基础,并确保了系统结果的精确性。VGG-16重构后的网络架构如图1所示。网络中主要包含卷积层、池化层和上采样层。
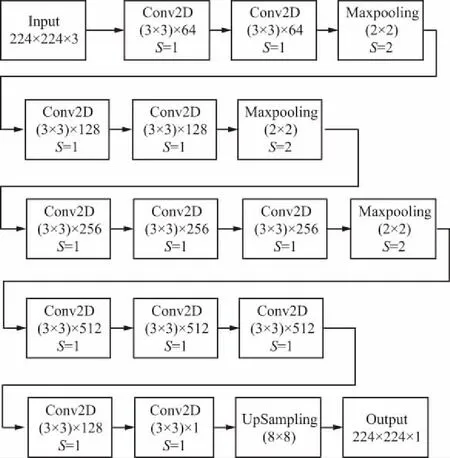
图1 网络架构Fig.1 Network framework
卷积层主要用于提取特征。假设第q层为卷积层,第k-1层为输入层,则第k层的卷积如下:
(1)
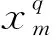
池化的主要作用是将特征图分为多个区域,然后通过对各个区域求像素平均值或者最大值等来减小特征图的尺寸,池化又称为下采样。本模型选取最大池化进行池化操作。
假设第q层为池化层,第q-1层为输入层,则第q层池化的计算如下:
(2)
式中,down为下采样函数;β为权重的参数。
上采样层的主要目的是放大原图像,从而获取更高的图像分辨率。由于对图像的缩放操作并不能带来更多关于该图像的信息,因此图像的质量将不可避免地受到影响。
假设第q层为上采样层,第q-1层为输入层,则第q层上采样的计算如下:
(3)
式中,up为上采样函数;β为权重的参数。
2 轻量级神经网络的实现及硬件部署
人工设计轻量级神经网络的主要思想在于设计更高效的网络计算方式,主要是针对卷积的计算方法,通过合理减少卷积核的数量,减少目标特征的通道数,结合设计更高效的卷积操作等方式,从而构造更加有效的神经网络结构[3]。本文为了对网络模型轻量化,生成轻量级神经网络,并将其部署到FPGA上,借助Xilinx®DNNDK量化工具进行了容器化开发环境的搭建、模型的转换、冻结与量化,生成轻量级神经网络;借助Xilinx®深度学习处理器单元 (DPU)将其部署至FPGA上。
对改进后的VGG-16人群计数模型进行冻结操作,从而减少未参与推理的Op节点;将原模型的权重文件与模型文件整合为一个文件,通过DNNDK工具,使模型权重由高精度范围向低精度范围直接进行映射,从原有的FP32减少至INT8,得到的冻结模型缩小约2/3体积,完成模型的轻量化。模型体积对比如表1所示。
表1 模型体积对比 MB
Tab.1 Model size comparison

原模型冻结后的模型轻量化后的模型94.131.48.3
DPU是一个可配置的计算引擎,专用于网络模型在FPGA上的部署。DPU需要指令来实现一个神经网络和可访问的存储位置,用于输入图像以及临时输出数据,还需要在应用程序处理单元(APU)上运行的程序来服务中断和协调数据传输。DPU顶层模块如图2所示,该单元包括一个高性能调度模块,一个混合计算阵列模块、指令获取单元模块和全局内存池化模块。
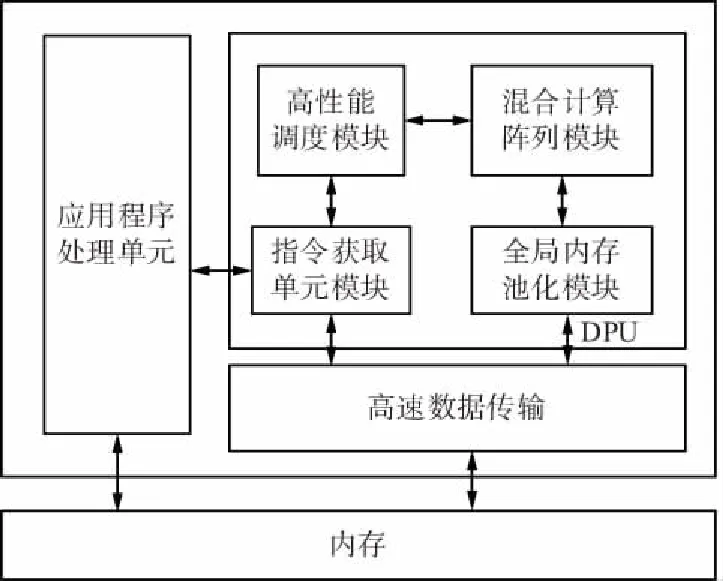
图2 DPU顶层模块Fig.2 Top-level module
为在PYNQ-Z2上进行轻量级神经网络部署,配置完成DPU,实现FPGA人群计数的硬件系统,通过系统时钟的方式记录了图片加载时间以及任务执行时间,配置基于X11协议的转发及编写计数显示界面用以显示运算结果。利用X11协议编写及转发的计数显示界面如图3所示。
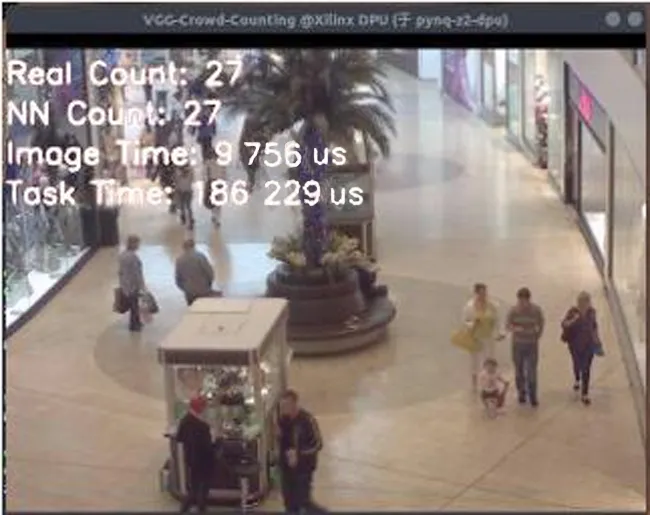
图3 显示界面Fig.3 Display interface
3 实验验证
本文基于如下平台构建:PC端CPU为E3 1231 v3,内存容量16 GB,显卡为Nvidia GTX980M,操作系统版本为Windows 10 LTSC 2019,以此作为网络构建、训练及量化环境。FPGA端采用Xilinx PYNQ-Z2开发平台,平台主要由2个Cortex A9内核以及可编程逻辑设计单元构成。
为了验证模型的有效性,本文进行了数据集的选取、误差函数的选取、网络训练、经过量化网络生成轻量级神经网络以及硬件部署,得到关键性能指标。
在人群计数利用方面,有许多带有人工标注的大型数据集,如UCF_CC_50[14],ShangHaiTech part A and B[15],Mall Dataset[16],WorldExpo’10[17]以及UCSD[18]。本文利用了香港中文大学提供的Mall Dataset数据集用以训练基于VGG的人群计数网络,该数据集包括了2 000张标注好的人群数据图像,同时尺寸统一为480×640×3。本文将Ground Truth的数量级提升100倍,便于网络收敛。用FPGA的量化特性指导网络优化,提高准确率,方便进行训练。
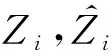
① 平均值绝对误差(MAE)。通过计算测试集中估计人数与真实人数的平均绝对误差获得,反映了模型对于测绘及人数基数的准确性,如下:
(4)
② 平均平方误差(MSE)。通过计算测试集中估计人数与真实人数的MSE获得,反映了模型对于测试集人群基数的准确性和稳定性,如下:
(5)
在PC端使用Keras构建基本网络结构,进行了网络模型的训练及参数的调整。网络输出的人群密度图如图4所示。
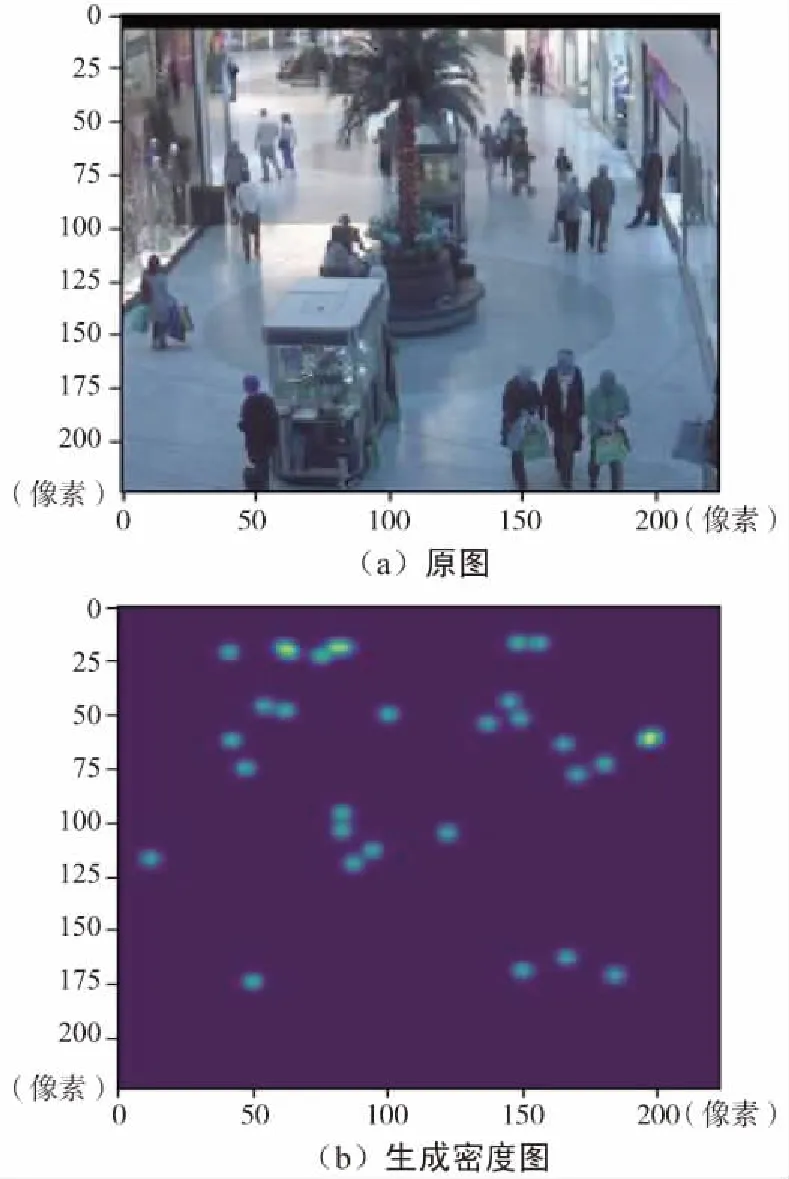
图4 密度图Fig.4 Density map
最后,将其量化生成轻量级神经网络后并部署在FPGA上,DSP利用率达到95.91%,并且分析得到如表2所示的关键性能指标。
表2 性能对比
Tab.2 Performance comparison

PlatformPCPYNQ-Z2DeviceE3 1231 v3 GTX980Zynq Z7020Clock Freq.3.40 GHz150 MHz(DPU)Memory16 GB DDR3L512 MB DDR3FPS76.92帧/秒5.38帧/秒Power220 W4.763 WEfficiency0.35 FPS/W1.13 FPS/WMSE18.418.4
可见,PYNQ-Z2平台相比于PC平台的功耗比突出,而且在量化后,性能指标也大致相同,由此可见,轻量级神经网络性能与卷积神经网络性能并无下降,同时,将轻量级神经网络部署于FPGA上大大提高了能效比,对未来的生产投入有重要意义。
4 结束语
通过对现有模型的改进与密度图的增量处理,使人群计数模型效果更好,该系统的均方误差量化后可达到18.4。将卷积神经网络进行量化生成轻量级神经网络,部署于FPGA中,并通过FPGA并行化操作处理运算,实现对神经网络推断的加速以及轻量级神经网络的准确性及低功耗性。利用PYNQ-Z2特性,合理调度CPU和FPGA,使ARM端与FPGA端软硬件协同工作,让技术应用落地,有效提高了人群计数网络的能效比,对其应用于便携式设备提供了参考。本文仍需要扩展训练集和训练次数,增加准确率;优化网络结构,增加执行效率,使其性能表现更优。
