基于多层注意力机制深度学习模型的虚假评论检测
2020-05-16曾致远卢晓勇徐盛剑陈木生
曾致远 卢晓勇 徐盛剑 陈木生,2*
1(南昌大学软件学院 江西 南昌 330047)2(江西理工大学软件工程学院 江西 南昌 330013)
0 引 言
顾客在作出购买选择时越来越依赖于互联网上的评论,但是互联网给用户提供便利的同时,也为那些潜在的虚假评论创造了机会。虚假评论,即为了欺骗消费者而编写的虚构评论。为了获得更多利润,一些商家通过雇佣写手编写积极评论来宣传商品或者编写消极评论来打击竞争对手[1]。随着虚假评论的蔓延和增长,越来越多的研究开始关注虚假评论的识别。
虚假评论检测的研究可以追溯到Jindal等[1]的早期工作。早期有代表性的研究[2-5],一般采用人工提取的特征和机器学习模型来训练分类模型。随着深度学习技术的迅速发展,越来越多的研究采用端到端的神经网络模型自动提取文章表示,并取得了更好的分类效果。文献[6-8]采用“句子层-文章层”分层结构,采用注意力机制学习文章表示,取得了比传统方法更好的效果。
虽然使用基于神经网络的模型取得了比传统模型更好的效果,但是这些端到端的模型没有结合虚假评论文本中表现出的情感特征。仔细研究虚假评论与正常评论的区别,可以得到以下结论:(1) 虚假评论表达的情感要比真实评论更强烈,文献[4]也提出与此相同的结论;(2) 一条评论中表达情感最强烈的地方是开头和结尾;(3) 虚假评论常以相似的句子开头或结尾,这可能是因为虚假评论一般由专门的写手创作,而同一个人可能会创作大量相似的评论。表1列举了一些虚假评论经常出现的开头和结尾。

表1 虚假评论中一些相似的开头和结尾
基于上述结论,本文提出一个基于注意力机制的多层编码器模型(Attention-based Multilayer Encoder,ABME)用于虚假评论检测。与文献[6-8]模型不同,本文没有直接采用“句子层-文章层”的通用结构,而是根据虚假评论的情感文本的分布特征将评论的开头、中间和结尾部分分开编码,分别使用双向LSTM编码,得到三个独立的文章局部表示。然后使用自注意力机制和注意力机制将三个局部表示集成为一个文章表示。最后用全连接神经网络得到分类结果,以期提升虚假评论检测的准确率。
1 相关工作
虚假评论的研究最早由Jindal等[1]提出,他们将垃圾评论分成了三种类型:(1) 不真实的评论(虚假评论);(2) 不相关的评论(即不是针对商品本身而是对商品品牌或制造商等与商品无关的评论);(3) 非评论文本。他们还发现,识别类型2和类型3的评论很容易,但是识别类型1的虚假评论很难。现在的研究主要关注类型1的垃圾评论检测,即虚假评论检测。
Ott等[2]通过雇佣在线写手,构建了第一个公开的虚假评论检测数据集。他们通过亚马逊众包平台(MTurk)让在线工作者创作针对芝加哥20个旅馆的虚假评论。通过这种方式,他们分别收集了400条积极和消极的虚假评论。针对Ott等[2]提出的数据集,一些学者展开了新的研究。Li等[5]提出了一个基于隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的主题模型来做虚假评论检测。Xu等[9]尝试从句子的依存关系树中提取文本特征。 Banerjee等[10]提出了一个语言框架来分析真实评论和虚假评论在可读性、写作风格方面的区别。邵珠峰等[11]基于虚假评论者和真实评论者在情感极性上存在的差异,增加评论文本的情感特征,并结合用户之间对于特定商品之间的关系,创建了一个多边图的模型以识别虚假评论。栾杰等[12]通过提取多种情感特征结合文本特征使用支持向量机进行分类,得到较好的检测效果。
Li等[4]采用和文献[2]同样的方式收集了餐馆和医生领域的虚假评论数据集,并扩充了文献[2]提出的旅馆数据集,还探索了一种通用的方法来识别虚假评论。基于Li等[4]收集的数据集,一些学者提出了基于深度学习的虚假评论检测方法。文献[6-8]采用“句子层-文章层”分层结构,并结合注意力机制学习文章表示,在领域内和跨领域的实验中都取得了比传统方法更好的效果。
2 方法设计
针对虚假评论分类问题,本文提出了一个基于注意力机制的多层编码器(ABME)。如图1所示,模型分为四层,第一层是双向LSTM编码器[13],它将一条评论的首、中和尾三个部分编码成三个向量s1、s2、s3。第二层是自注意力机制(self-attention)编码器,它将三个局部表示的s1、s2、s3编码成三个全局表示z1、z2、z3。第三层是注意力机制编码器(attention),它将三个全局表示z1、z2、z3合并成一个最终的全局表示O。最后一层是分类层,由全连接神经网络和Softmax组成,它输出模型的分类结果。

图1 基于注意力机制的多层编码器
2.1 BiLSTM模型
长短期记忆网络(LSTM)[13]是一种改进的循环神经网络(Recurrent Neural Network,RNN)[14]。它相对于普通的RNN模型,加入了记忆单元和门机制,记忆单元中信息的更新、遗忘和传递分别由三个门(gate)来控制[13]。相比于普通的RNN模型,LSTM能够提取序列较长距离的依赖关系,并能有效地缓解RNN梯度消失的问题。
在将序列输入LSTM模型之前,首先使用分布式向量表示[15]来编码词语,对于每个词w,从矩阵E中查找w的向量表示e(w),e(w)∈Rd。E是通过预训练得到的模型参数,E∈Rm×d,m是词典长度。本文使用fasttext模型[16]在wiki语料训练得到的参数矩阵E。一个由n个词组成的评论可以被表示成(e1,e2,…,e3),其中ei表示第i个词的embedding。
为了更好地捕捉序列的双向信息,本文采用双向的LSTM来编码评论的embedding序列[17],双向LSTM的结构如图2所示。
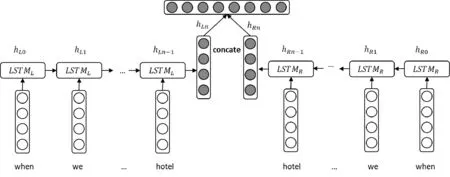
图2 双向LSTM模型
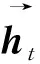
(1)
(2)
BiLSTM编码器的H输出由正向和反向LSTM最后一个位置的输出向量拼接得到。如果(e1,e2,…,e3)是一个句子或文章,则H是该句子或文章的向量表示。H将被输入下一层编码器继续编码或者直接输入分类层分类。
(3)
2.2 第1层:BiLSTM编码器
基于评论的首尾相比于中间内容对于识别一条评论是否真实更加重要这一假设,首先将一条评论分成开头、中间和结尾三个部分并分别用w1、w2、w3来表示三个部分的word embedding序列,其中w2的长度要远远大于w1和w3。因为首尾相比于中间内容更加重要,可以提高w1、w3的权重来提升其对分类结果的影响。将w1、w2、w3输入到三个互相独立的BiLSTM编码器中,将wi编码成si,得到维度相同的三个向量:s1、s2、s3,si∈Rdm。分别表示首句、中间句子和结尾。虽然原始序列中w2的长度远大于w1和w3,但是经过BiLSTM编码后得到的s1、s2、s3的维度是相同的。这样对于下一层编码器而言,三个输入向量之间是平行的。
s1、s2、s3分别表示首句、中间句子和结尾,但三个向量之间是互相独立的,即都只包含评论的一部分信息。使用BiLSTM对整条评论编码,得到评论的全局表示sc,sc∈Rdm。虽然可以直接通过LSTM编码得到全局表示sc,但是还可以对s1、s2、s3、sc继续编码,得到更好的全局表示。
2.3 第2层:自注意力机制编码器
BiLSTM编码器得到的三个向量s1、s2、s3都是互相独立的局部表示。为了得到序列的全局表示,需要对s1、s2、s3应用自注意力机制。
自注意力机制[18]是一种特殊的注意力机制,它比RNN和CNN更容易提取不同位置间的依赖关系,而且参数量更少。相比于普通的注意力机制,自注意力机制最大的特点是所有的key、value和query都来自于上一层编码器。具体而言,从上一层编码器得到三个向量s1,s2,s3,sc∈Rdm,并将三个向量合并成一个矩阵S=[s1:s2:s3],S∈R3×dm。在本层中,S既是query又是key和value。自注意力机制的计算是使用query中的每个向量queryi和key中的每个向量keyj做比较,得到相似度矩阵Attention,表示为
Attentionij=sim(queryi,keyi)
(4)
然后将Attention作为权重对value做加权组合得矩阵Z,Z和value的维度相同。
使用注意力机制的关键是计算注意力权重Attention,即相似度函数Sim。计算注意力权重的常用方法是点积和多层感知机(Multi-Layer Perception,MLP)。本文使用MLP来学习注意力权重,因为MLP可以拟合任何连续函数。Attention的计算式表示为:
Attention=Softmax(tanh(W·ST+b))
(5)
式中:Attention∈R3×3,W∈R3×dm,b∈R3×3。
最后的输出Z是S的加权平均,由矩阵Attention和矩阵S点乘得到。它是维度和S相同的矩阵,可以表示为[Z1:Z2:Z3]。Zi和si相对应,相比于si,Zi包含了序列所有位置的信息。
Z=Attention·S
(6)
虽然自注意力机制能很好地捕捉不同位置之间的依赖关系,但是它本身并不能提取序列的位置信息。为了不丢失序列的位置信息,本文将位置编码加入到自注意力机制编码器的输出中。本文采用Vaswani等[18]提出的分别采用正弦、余弦函数来编码序列的位置信息,分别表示为:
(7)
(8)
PE是位置pos对应的向量编码,PEpos,2i、PEpos,2i+1分别是在向量PE上第2i、2i+1个位置的值。相对于其他编码方式,这种编码方式能够有效提取词语的相对位置信息,而且不会给模型增加参数。
2.4 第3层:注意力机制编码器
自注意力机制层输出的矩阵Z包含了序列的全局信息,BiLSTM层输出的向量sc也包含了序列的全局信息,使用注意力机制将矩阵Z和向量sc编码成最终的全局表示O。
注意力机制是一种序列建模的常用方法,可以被描述为将一个查询向量query和一个键值对集合映射成输出output,其中query、key、value、output都是向量。在本层中,query是向量sc,key和value是矩阵Z。和自注意力机制一样,注意力机制也是将query和key做比较。两者的区别是,在注意力机制中,query是向量,而且一般来自于序列外部,而自注意力机制中的query是矩阵,通常就是序列本身。此外,因为query是向量,所以由query和value计算得到的Attention也是向量而不是矩阵。和自注意力层一样,本文使用MLP来训练注意力权重(Attention),并使用Softmax归一化权重。其计算式表示为:
Attentioni=sim(query,keyi)
(9)
Attention=Softmax(tanh(scWq+Wk,vZT+b))
(10)
式中:Attention∈R1×3,Z∈R3×dm,sc∈R1×dm,Wk,v∈R1×dm,b∈R1×3。最终的输出向量O是Attention和Z的加权平均。
O=Attention·Z
(11)
式中:O∈R1×dm。O由sc和Z编码得到,包含了前面两层的信息,能更好地表示整条评论。
2.5 第4层:分类层
分类层由全连接神经网络和Softmax分类器组成,全连接神经网络将文章表示O映射为二元类别的分数y:
y=tanh(WOT+b)
(12)
式中:W∈R2×dm,y∈R2。Softmax函数将分数y归一化:
(13)
式中:p∈R2。归一化后的结果p可以看成是模型的预测结果在二元类别上的概率分布。
3 实验结果分析
3.1 数据集和评价指标
本文使用Li等[4]发布的虚假评论数据集作为实验用数据集。该数据集包含三个领域:旅馆,酒店和医生。数据集的分布如表2所示,数据集包含三种类型:“Turker”,“专家”和“用户”。其中“Turker”和“专家”属于虚假评论,而真实评论来自用户。“Turker”是Li等[4]和Ott等[2]使用亚马逊众包平台(MTurk)收集的虚假评论,这些虚假评论由一些在线工作者编写。“专家”是由一些具备一定领域知识的领域专家创作,而真实评论来自于那些可信度高的用户。因为“专家”类别的样本数量太少,本文实验没有采用。
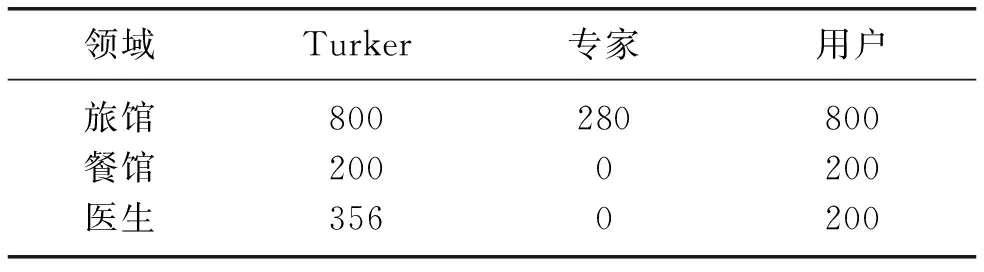
表2 三个领域的数据集分布
文献[4]和文献[6]针对上述三个领域的数据集设计了三种实验:领域内实验,跨领域实验和混合领域实验。领域内实验指的是训练集和测试集均来自相同领域的数据集,此时模型的准确率应是最高的。跨领域实验指的是训练集来自一个领域的数据集,而测试集来自另外一个领域的数据集,其目的是为了检验模型的领域适应能力和泛化能力。混合领域实验指的是将所有领域的数据归集到一个数据集,即使用多领域的训练集训练出模型,再用多领域的测试集来检验模型。混合领域实验是对跨领域实验的补充,其目的同样是为了检验模型的领域适应能力和泛化能力。本文也尝试了这三种实验。为了让实验结果更加可靠,本文采用5折交叉验证将数据分成5个fold,其中4个fold作为训练集,剩下的fold作为测试集,最后取5次实验测试结果的平均值。
文献[4]使用F1、精确率(Precision)、召回率(Recall)和准确率(Accuracy)来评价模型的效果。针对二元分类问题,这4个指标的计算如下:
(14)
(15)
(16)
(17)
式中:TP为被正确分类的正例;TN为正确分类的负例;FP为错误分类的正例;FN为错误分类的负例。为了方便比较,本文也采用这4个指标来评价模型。在三种实验中,将本文提出的ABME模型和文献[4]提出的SAGE模型以及文献[6]提出的SWNN模型进行比较。其中,SAGE模型使用了n-grams特征,而SWNN模型是分层的CNN模型。
3.2 领域内实验
表3显示了本文设计的ABME模型和文献[4]、文献[6]的模型在旅馆、餐馆、医生领域上的实验结果。本文提出的ABME模型在旅馆和医生领域的实验中,在大多数性能指标上均取得了最好的结果;在餐馆领域的实验中,ABME模型在准确率(Accuracy)和召回率(Recall)上取得了最好的结果。由此可见,ABME模型在领域内的实验中取得了最好的结果。
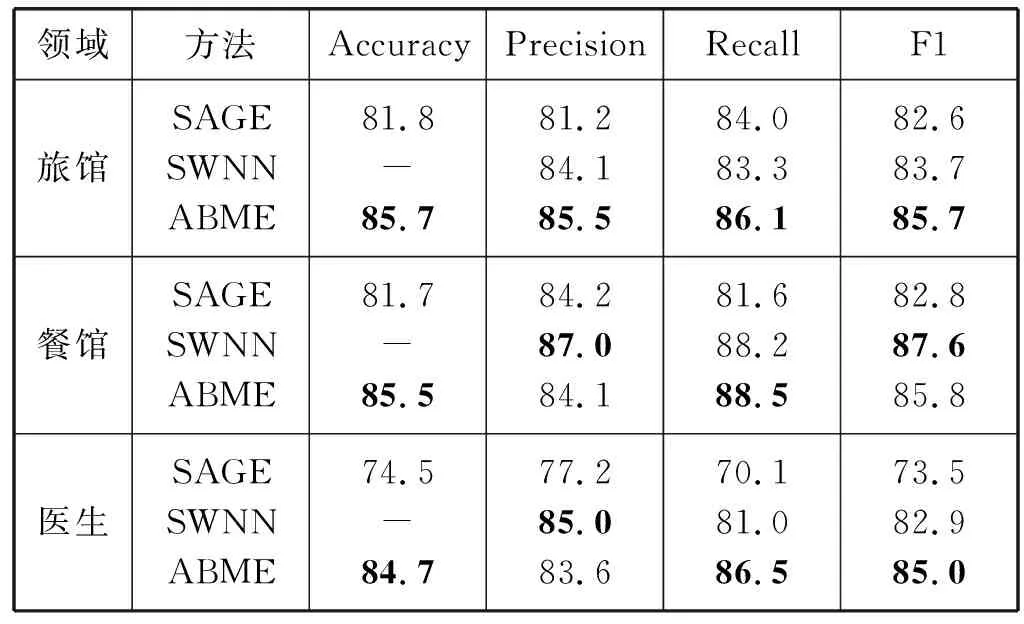
表3 领域内实验结果 %
3.3 跨领域实验
在三个领域的数据集中,旅馆数据集是最大的(1 600个样本),而餐馆和医生较小(400个样本),所以本文的跨领域实验使用旅馆数据集训练模型,在餐馆数据集和医生数据集上进行测试。
实验结果如表4所示,在餐馆领域的实验中,文献[4]的SAGE模型取得了最好的效果,而ABME模型和文献[6]的SWNN模型实验结果相当。在医生领域的实验中,文献[6]的SWNN模型取得了最好的效果,而本文的ABME模型的精度是最高的,并且其准确率与SWNN模型十分接近。总体而言,三个模型在餐馆数据集上的表现都要好于医生数据集,因为餐馆和旅馆的领域词汇更相近。
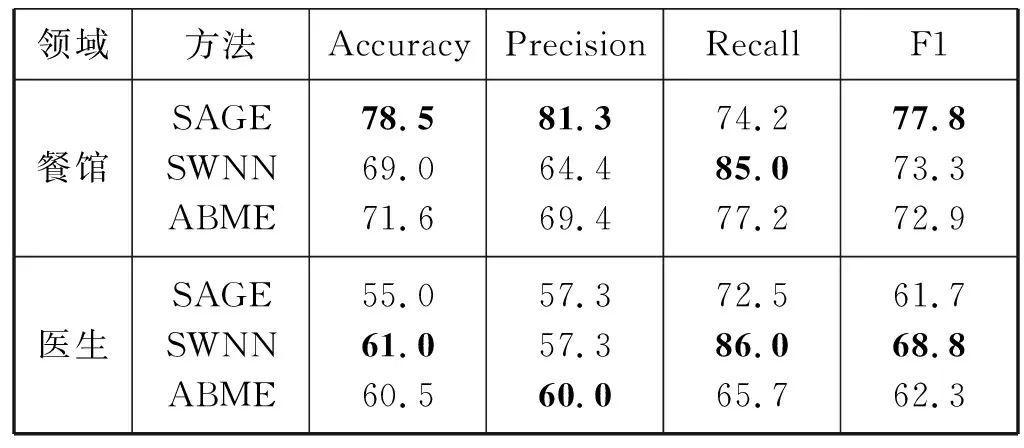
表4 跨领域实验结果 %
3.4 混合领域实验
混合领域实验结果如表5所示。文献[4]并没有做这个实验,所以只和文献[6]的模型比较。本文提出的ABME模型在准确率(Accuracy)和精确率(Precision)上得到了最好的结果,实验结果说明本文提出的ABME模型和文献[6]提出的SWNN模型在混合领域数据上的表现相近。
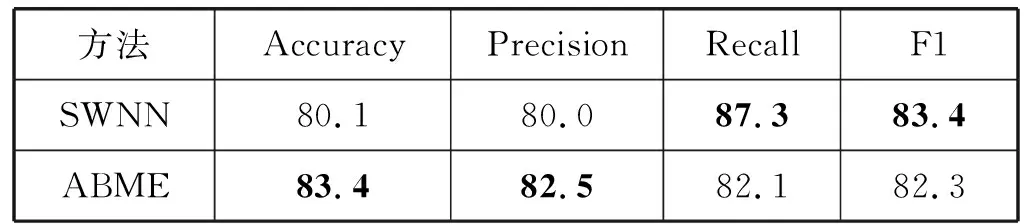
表5 混合领域实验结果 %
4 结 语
本文提出了一个基于自注意力机制的多层编码器模型(ABME)来解决虚假评论分类和检测问题。本文模型将评论的首、中、尾分离来提高首尾的权重,并结合两层注意力机制的深度学习模型来获取评论的全局特征表示。实验结果表明,本文方法在部分实验中取得了最好的效果。模型在跨领域实验中的表现远没有领域内和混合领域的实验结果好,这可能是因为没有在模型中使用领域适应的方法。如果加入“领域无关特征”,并运用一些领域适应方法,模型的鲁棒性和泛化能力将进一步增强。
