基于3D双流卷积神经网络和GRU网络的人体行为识别
2020-05-16来兴雪周志全秦晓宏池亚平
陈 颖 来兴雪 周志全 秦晓宏 池亚平
1(西安电子科技大学计算机科学与技术学院 陕西 西安 710000)2(北京电子科技学院 北京 100070)
0 引 言
基于计算机视觉的人体行为识别近几年得到广泛的关注,研究者们在人体行为识别领域提出了很多研究方向和方法[1-3]。传统的行为识别方法中特征提取主要是依赖人为的规定和设置,对于复杂环境下的行为识别很难有较好的效果。基于深度学习的行为识别技术需要大量的样本来训练深度网络,不需要手动选取特征,比传统的识别方法具有更高的特征表征能力。由于卷积神经网[4-7](Convolutional Neural Network,CNN)在图片分类任务中有很好的效果,研究者们致力于将卷积神经网络应用到行为识别等计算机视觉任务中[8-10]。经典的二维卷积神经网络框架有Alexnet[11]、GoogLeNet[12]、VGGnet[13]等。文献[14]结合卷积神经网络和支持向量机,提取手势图像的特征。文献[15-16]研究了卷积神经网络在图片分类方面的应用,提出了一种在线预测算法,该算法可以预测图像识别效率的提高。文献[17-19]中提出用3D卷积神经网络提取视频的内容特征的同时提取视频的时间特征,是视频分类和行为识别中的经典模型。双流卷积神经网络[20-21]也是视频分类和行为识别等计算机视觉任务中一种主流的方法,其通过空间流和时间流学习视频中的空间信息和动作相关的时间域信息,最后空间流和时间流各自通过分类器进行分类,将分类结果进行筛选或结合作为该视频的分类结果。文献[22]等提出融合卷积层和长时递归层的长时递归卷积网络(Long-term Recurrent Convolutional,LRCN),LRCN通过2维卷积神经网络提取视频的特征流,利用LSTM(Long Short-Term Memory,LSTM)将特征流输入到LSTM网络获取视频处理结果,该模型能更有效地利用视频的时间特性。
基于以上分析,本文提出一种基于3D双流卷积神经网络和GRU网络的人体行为识别模型。该模型在双流卷积神经网络中的空间流和时间流用3D卷积神经网络提取视频时域上的表征信息和运动信息,然后进行时空特征融合后输入到GRU网络,提取视频时空融合特征向量序列的长时间序列化特征,最后利用Softmax分类器进行人体行为识别。由于GRU网络具有长时记忆信息的能力,本文将双流卷积神经网络与GRU网络相结合建立更深层次的网络结构,使人体行为识别模型能更强地表达视频的时序性特征。
1 模型结构设计
1.1 模型结构流程图
本文提出的基于3D卷积神经网络和GRU网络的人体行为识别模型主要包含四个模块:时空特征提取、时空特征融合、GRU网络提取时空特征向量序列时序性特征、Softmax分类器进行人体行为识别。首先在双流卷积神经网络的空间流和时间流分别使用3D卷积神经网络提取视频时域上的表征信息和运动信息,然后对空间流特征向量和时间流特征向量进行自适应加权融合,将融合的特征向量序列作为GRU网络的输入学习视频的时序性特征,最后通过Softmax分类器进行人体行为识别。模型的流程图如图1所示。
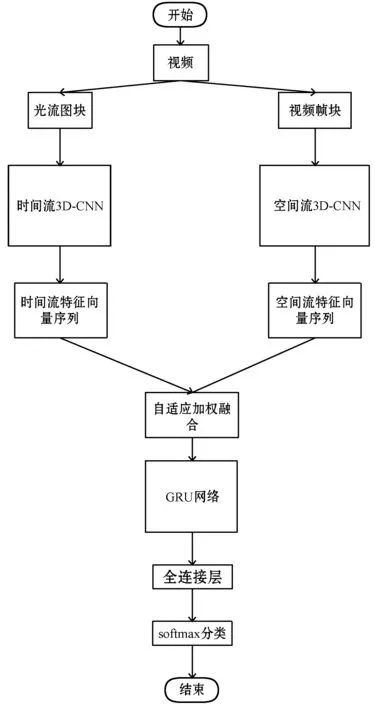
图1 基于3D双流神经网络和GRU网络的人体行为识别模型
1.2 时间流和空间流卷积神经网络
本文模型的输入是视频多个连续的特征帧块,取视频连续的16帧作为一块。空间流的输入是多个静态的图片帧块,该流通过3D卷积神经网络提取视频中时间维度上的表征信息。空间流使用3D卷积核对视频帧块进行卷积,从而可以获取视频帧块的时间特性。时间流以多个连续的光流图块作为模型的输入,每块8个x方向光流图和8个y方向光流图。光流图通过比对相邻帧的像素值变化得到像素运动的图片,比如打羽毛球这个动作,光流图可以体现在一定的空间范围内身体移动的周期性动作,并且能更加清晰直观地表达人物的移动状况。
本文中时间流和空间流均采用3D卷积神经网络,包含8个卷积层、5个池化层、2个全连接层和一个分类层。8个卷积层的卷积核个数分别为64、128、256、256、512、512、512、512,卷积核大小为3×3×3且步长为1,池化层采用3维池化操作。
在模型训练过程中,特征图的大小会根据不同网络层产生相应的变化,卷积层不会改变特征图的大小,因为在卷积层进行了加边处理。在池化层对特征图进行3维下采样操作,特征图的大小会相应变化。图2为3D卷积神经网络结构示意图。
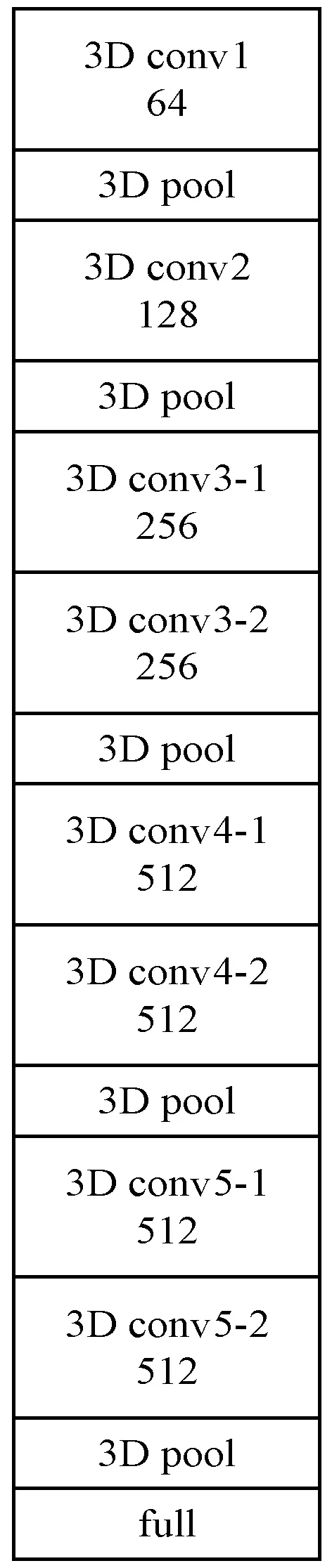
图2 3D卷积神经网络结构示意图
1.3 基于监督的时空特征加权融合
本文提出时空特征自适应加权融合方式,代替传统的最大值融合和均值融合等方式,让模型更关注重要的特征向量,忽略冗余的信息,提高模型的可解释性。

(1)
式中:ci是自适应加权融合后的特征,该特征作为模型中GRU网络的输入;αi、βi是对每个特征向量计算得到的权重,代表其在模型后半部分进入GRU网络进行视频时序性训练的重要性。权重的计算公式为:
(2)
式中:αi是特征序列的归一化函数。αi的计算过程中以标量ei为输入,ei的计算公式为:
ei=a(vi)v∈(x,y)
(3)
式中:a是Attention模块,实质是个打分函数,它的输入只依赖特征向量vi。
Attention模块的输入是基于3D卷积神经网络和GRU网络的人体行为识别模型的前半部分中空间流和时间流3D卷积神经网络的输出数据,即视频的空间流特征向量和时间流特征向量。模块的输出是每个特征向量的自适应加权值。该Attention模块示意图如图3所示。
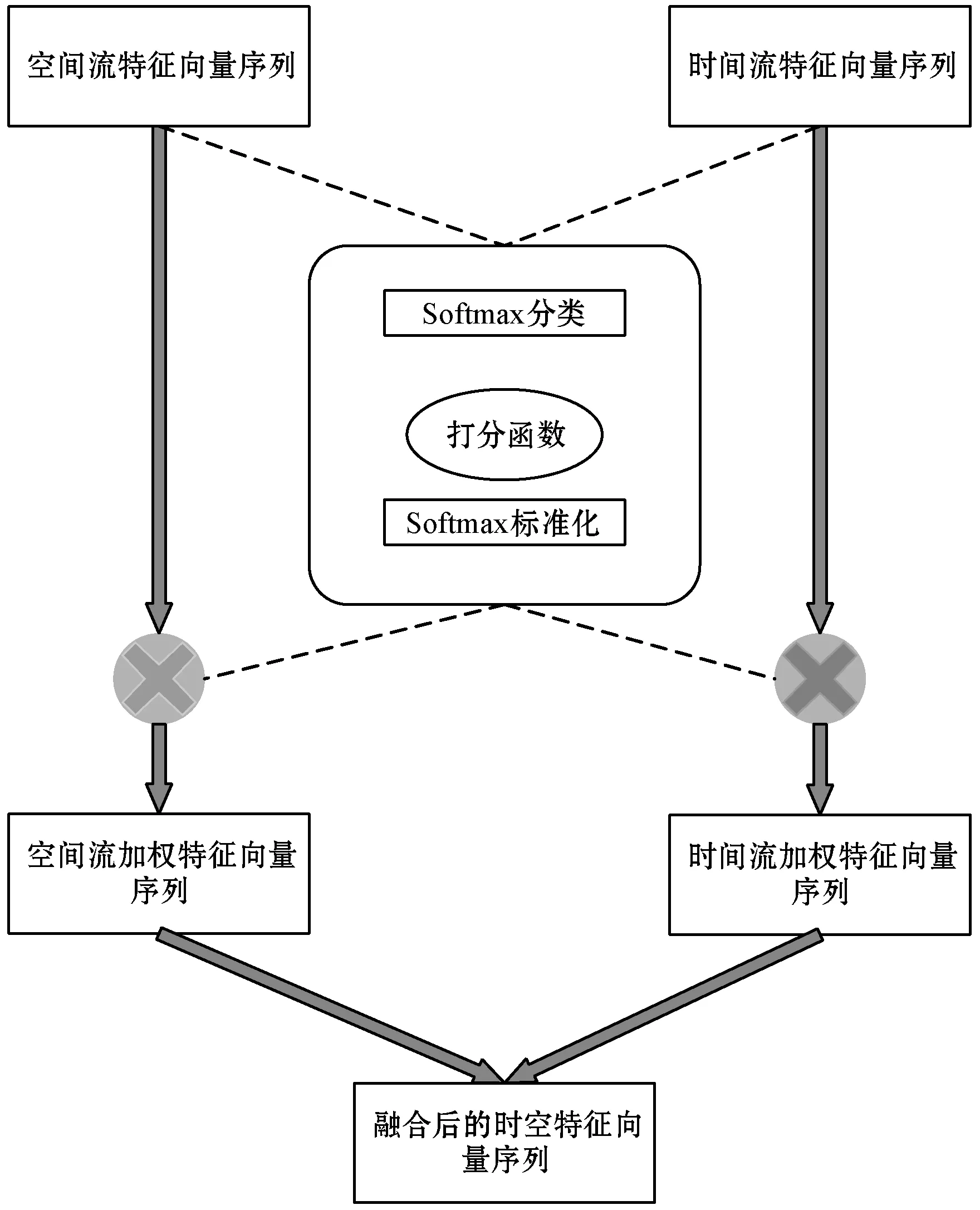
图3 Attention模块示意图
打分函数伪代码如下所示:
输入:空间流和时间流特征向量,即fspace={x1,x2,…,xt}和ftime={y1,y2,…,yt}
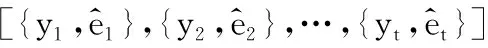
算法:
BEGIN
whilei≤t
//根据Softmax分类器对特征向量分类
whilei≤t
store_list←{xi,ei}
whilei≤t
return store_list
END
其中:t是空间流和时间流3D卷积神经网络输出的特征向量个数,与模型输入的视频帧块、光流帧块有关;q是训练视频数据真正的类别数;g(x)该函数的作用是获得x所在类的类别个数;store_list作用是保存特征向量和其打分结果。
1.4 GRU网络
本文模型中用GRU网络提取视频时空特征向量序列的时序性特征,采用两层GRU网络,每层512个神经元。当空间流特征向量和时间流特征向量融合后按顺序输入到GRU网络中,GRU网络通过其神经元中更新门和重置门的设计,控制神经元中前一刻的隐层输出对当前隐层的影响程度,进行选择性的训练,提取时空特征融合向量时序性特征。在模型中加入GRU网络,提高了框架提取视频运动信息和时间特征的能力。GRU的神经单元如图4所示。
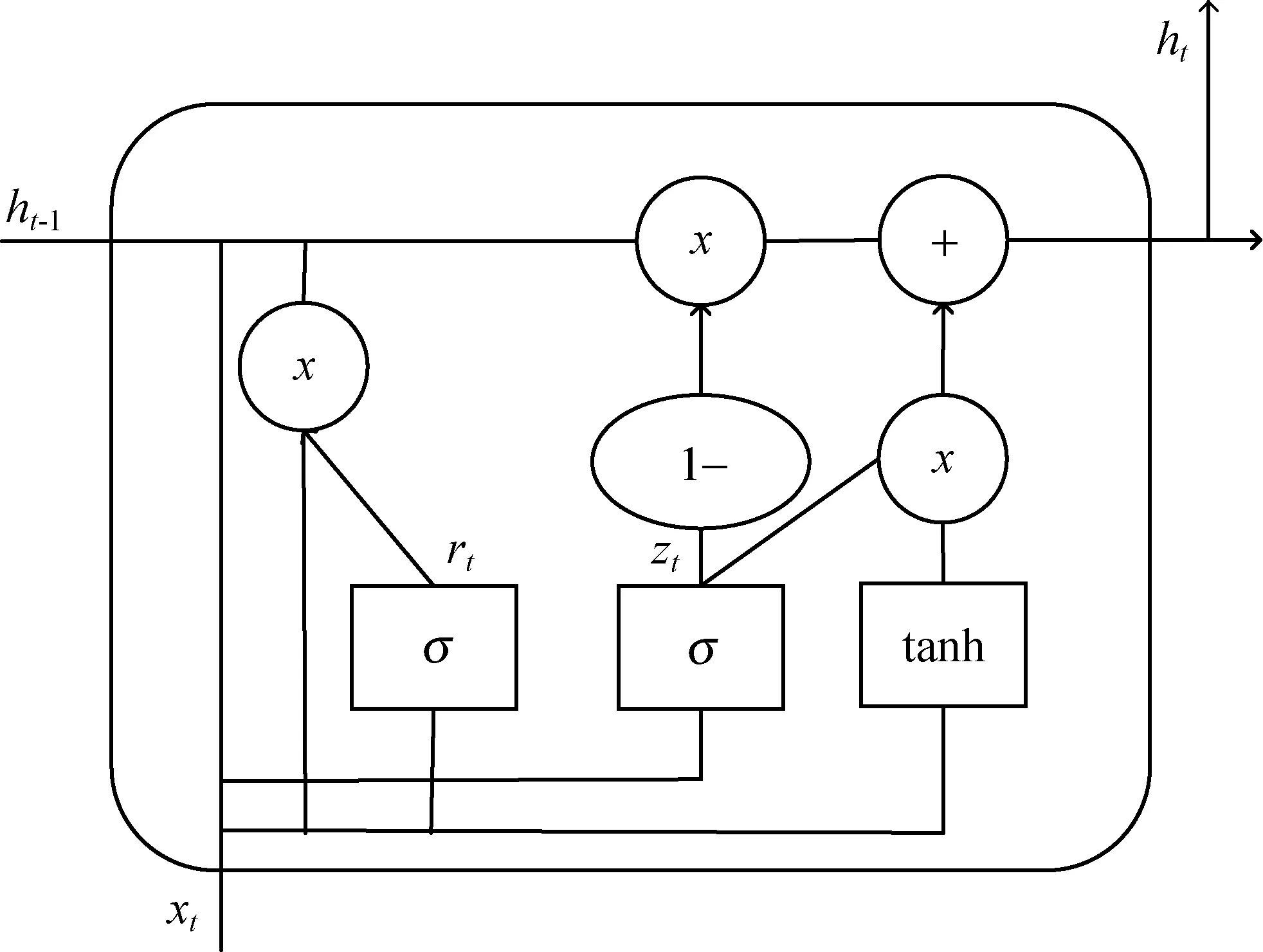
图4 GRU的神经单元
GRU网络的更新公式如下:
(4)

2 实 验
2.1 实验环境
本文实验数据采用行为识别数据集UCF101,该数据集是从YouTube网站上收集的各个动作的视频,有13 320个视频,每个视频的时长10秒左右,一共17小时,分辨率是320×240,共有101类动作,每个动作有100多个视频段,由不同的人完成,但是有相似的背景和方位。图5为该数据集中部分视频帧。从数据集中取出12 830个作为训练集,500个作为测试集,实验迭代次数为100次。

图5 UCF101数据集视频帧展示
本文模型中使用动态周期性下降的学习率,学习率周期性下降的好处是模型多次迭代过程中使用同一个学习率,能更有效地使用学习率。随着模型的训练,学习率渐渐变小并且不为0,下降幅度也随着迭代的进行变得缓慢,其目的是防止学习率下降得太快使模型难以收敛或者收敛速度缓慢。经过多次试验,本文模型采用的学习率如图6所示。
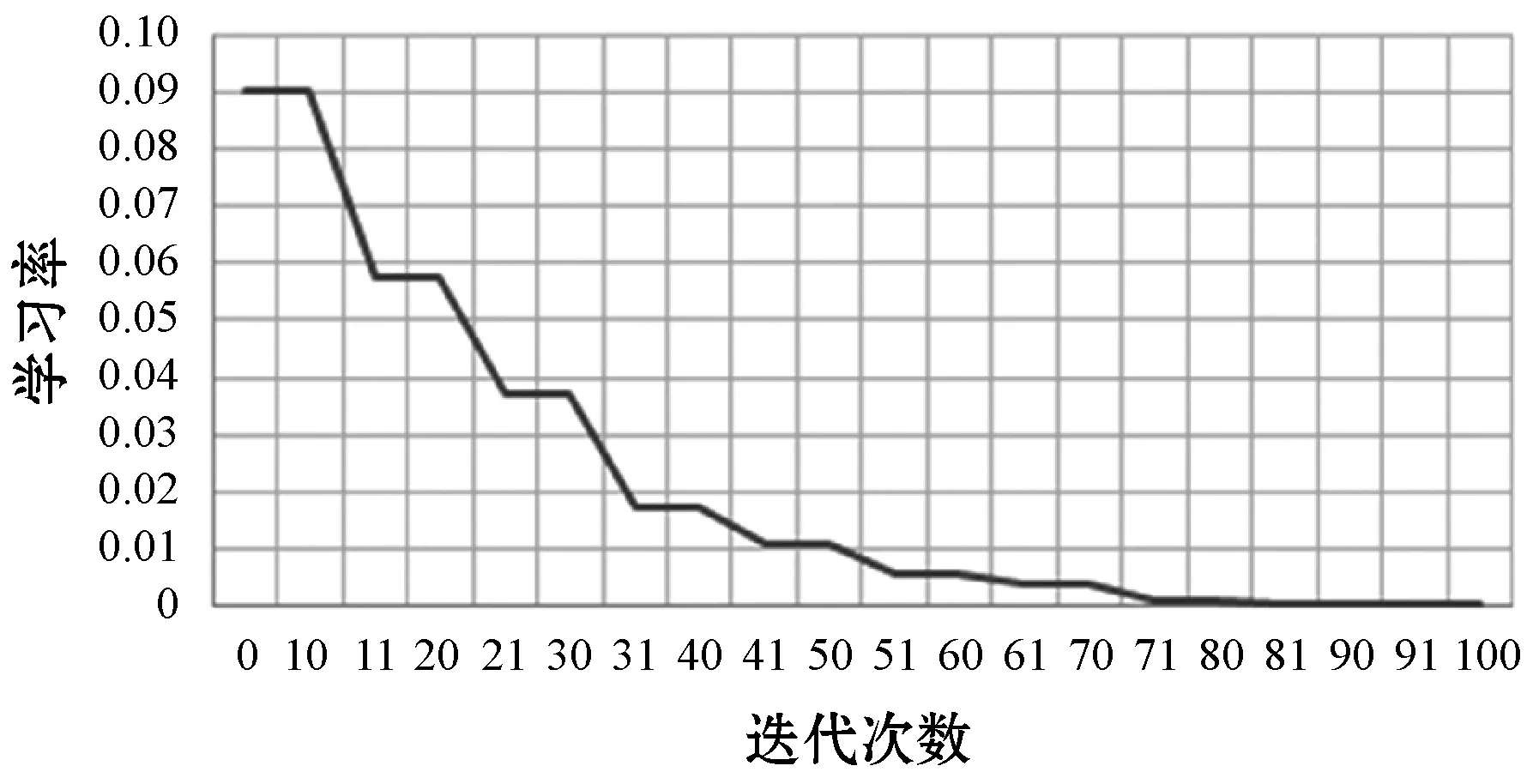
图6 模型学习率变化曲线图
2.2 实验结果与分析
表1展示了本文模型在UCF101数据集上的实验结果。由表可知,空间流和时间流分别采用3D卷积神经网络进行行为识别,空间流训练的是视频的图片帧,而时间流训练的是视频的光流图,在UCF101数据集上的行为识别率相差不大,分别为79.1%和80.8%。而本文模型的识别率为92.2%,说明本文方法比单一的用3D卷积神经网络的识别率更高。时空双流CNN-GRU神经网络的平均训练时间、平均测试时间比单一用3D卷积神经网络的空间流和时间流时间长至少4倍,因为本文模型的网络结构比较复杂,由时间流3D卷积神经网络和空间流3D卷积神经网络组成双流,又结合GRU网络构成,且本文模型的内存消耗也较大,但其识别率有较高的提升。
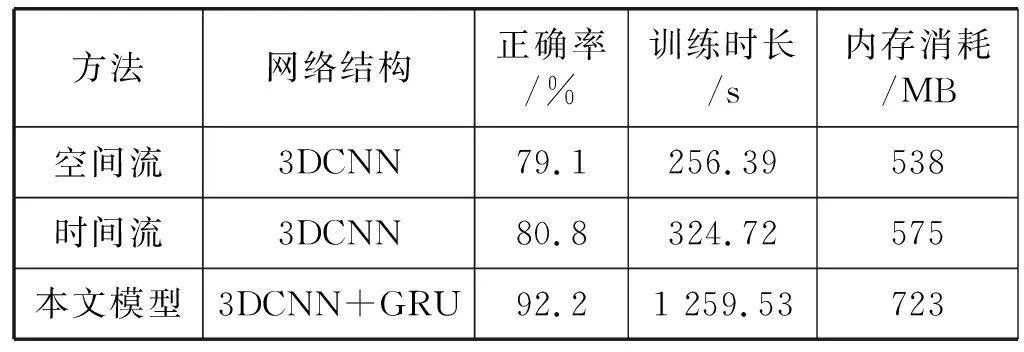
表1 模型在UCF101数据集上的实验结果
最后,将本文方法与其他行为识别方法在UCF101数据集上进行了比较,如表2所示。由表可知,本文模型在空间流和时间流分别使用3DCNN,充分提取视频的内容信息和时间特性,特征融合后输入到GRU网络,提取长时间序列化视频的特征,让框架有更好的特征表达能力,模型在UCF101数据集上的识别率为92.2%。本文模型的识别率比Two-Stream(VGG)高0.8%,说明本文将3D卷积神经网络引入双流卷积神经网络中使模型更全面地提取了视频的信息,并且结合GRU网络,使视频的时序性信息得到有效的使用。
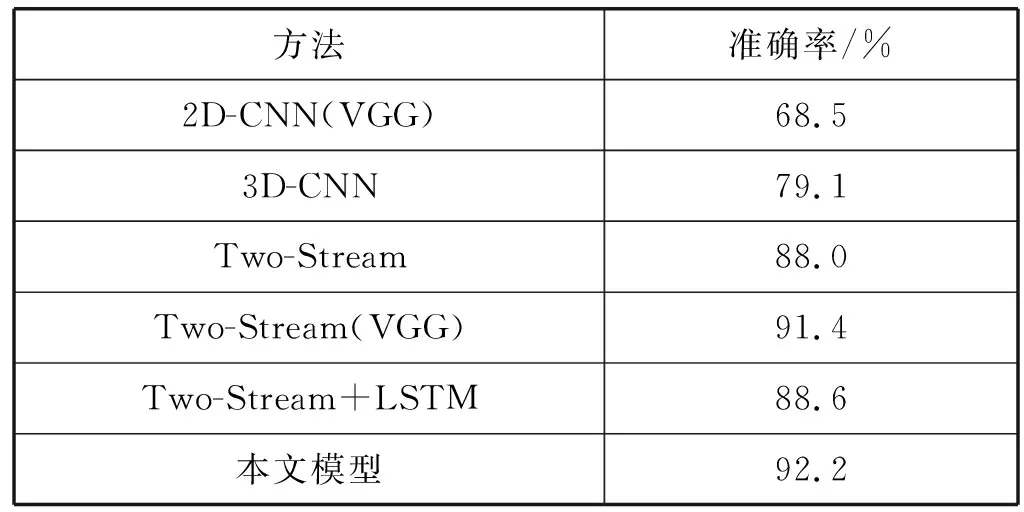
表2 各种识别方法在UCF101数据集上的识别率比较
3 结 语
针对原始双流架构中使用卷积神经网络提取视频的空间特征和时间特征而导致视频信息利用不足,并且无法真正学习视频的时序性特征的问题,本文提出了基于3D卷积神经网络的双流神经网络与GRU网络相结合建立的更深层次网络的人体行为识别模型。在双流卷积神经网络的空间流和时间流分别使用3D卷积神经网络提取视频时域上的表征信息和运动信息,采用3D卷积神经网络可以让更多的视频帧参与模型的训练,从而解决视频信息利用不足问题,并且使模型在空间域和时间域上更有效地提取视频的动作信息,让模型更多地表达视频的运动信息和时间特征。由于GRU网络具有长时记忆信息的能力,本文将双流卷积神经网络与GRU网络相结合建立更深层次的网络结构,可以提取视频时空融合特征向量序列的长时间序列化特征,使网络能更强地表达视频的时序性特征。在行为识别数据集UCF101和HMDB51上对本文提出的框架进行实验,证明了本文模型与同类方法相比,识别率得到了一定的提升。
