基于轨迹数据的多工况典型驾驶行为能耗评估
2020-05-16吴丽宁景首才
惠 飞 吴丽宁 景首才 魏 诚 李 敬
(长安大学信息工程学院 陕西 西安 710064)
0 引 言
近年来,汽车产业成为国民经济的重要支柱,因此交通也已成为我国乃至全世界能源消耗量最高的行业,其中道路交通最为严重。2013年葡萄牙运输部门使用的石油资源占全国一年总量的40%,其中道路交通占81%[1];2014年我国清洁能源、可再生能源以及电力在车用燃料替代中超过了500万吨[2];2015年北京市交通运输业能源消耗占全市能源消耗的18.23%[3];2016年在乘用车保有量继续增长、新型城镇化不断推进的背景下,我国石油需求同比增长4.3%左右[4];2017年我国消耗的能源高达110.8亿吨,并且2018年的消耗量比上年增长4.6%[5]。从当前情况观察到,道路交通方面使用石油比例逐年增长,若再不对机动车的能耗进行研究和治理,能源短缺问题将会越来越严重。
国内外学者基于机动车行驶参数在能源消耗碳排放方面做了大量研究:文献[6]在分析安全辅助系统对能耗的影响时,排除了速度变化的影响,将加速度波动作为能耗增加的主要原因进行研究。文献[7]分析了在交通限制下速度和加速度两个参数对能耗的影响。文献[8]通过燃油密度、发动机转矩、转速计算油电混动汽车的单位耗油率。文献[9]通过t-检验证明了减少能耗及碳排放的措施不会影响汽车行驶速度,并且分析出空调温度、轮胎、燃油密度、车辆阻力、车重等可能影响能耗的因素。文献[10]收集了一些在行驶过程中利于减少能耗的因素,分析出提供中等频率的评估信息可以使用户长期处于低能耗阶段。文献[11]发现合理的驾驶风格可以节省5%~20%的能耗。文献[12]在高速、主干道、二级公路上比较能耗的变化情况,并建立了以速度作为唯一参数的能耗模型。文献[13]通过对所有道路环境中的交通流量进行控制和管理,发现驾驶员能源消耗明显降低。文献[14]通过跟弛模型对速度进行优化,发现该模型能有效降低车辆能耗。文献[15]在交叉口停车线以及上游下游处,通过改变驾驶行为,研究排放的变化情况,并基于每个路段构建不同的排放模型。
综上,由于行驶参数与能耗之间存在直接关联且易于获得,因此国内外学者在研究减少能耗的生态驾驶行为时多以行驶参数为出发点。但是驾驶员因素也是能耗和排放增加的最主要成因,若要从驾驶员角度出发,则能达到缓解交通拥堵、减少能源消耗和污染物排放的目的,对交通行业的发展具有重要意义。基于此,本文分析了在多工况下,急加速、急减速、正常加速、正常减速、匀速这五种典型驾驶行为的能源消耗情况,并且提出一个基于多工况的驾驶行为能耗评估模型,期望可为政府部门制定节能减排政策以及交通部门实施交通管控方面提供参考。
1 多工况驾驶行为能耗评估模型
本文提出一个多工况驾驶行为能耗评估模型,如图1所示。该模型实现过程包括:数据预处理、多工况驾驶行为识别、能耗分析与模型验证三个部分。第一部分:进行数据采集和预处理;第二部分:利用K-means对驾驶工况进行分类,形成低速、中速、高速三类,然后参考行驶参数对驾驶行为进行特征提取,最后进行两级聚类算法,即首先对特征参数进行谱聚类,然后对一级聚类结果使用AGNES算法进行二次聚类,得到急加速、急减速、正常加速、正常减速、匀速五类;第三部分:量化分析不同驾驶行为的能耗,并且通过将实际能耗与模型计算的能耗进行对比来验证模型精度。

图1 多工况典型驾驶行为能耗评估框架
2 数据采集与预处理
2.1 实验数据采集
为获取可复现的实验数据,本研究邀请不同驾驶员在相同天气状况下以市内相同路段为基础,把驾驶行为作为唯一变量进行实验。
实验在西安市如图2所示的线路上(粗线是轨迹,起点为长安大学本部,终点为西安城西客运站),由5名驾驶员进行数据采集,GPS设备按照20Hz采集信息。部分原始数据如表1所示。

图2 实车实验路线图

表1 部分原始数据
2.2 VT-Micro能耗模型
目前VT-Micro微观能耗模型是被大家公认的一种车辆瞬时能耗计算模型[16-17],本文选取VT-Micro来计算补充瞬时能耗数据。模型计算如下:
(1)
式中:MOEe为瞬时能耗;Li,j为a≥0的回归系数;Mi,j为a<0的回归系数;s为瞬时速度;a为瞬时加速度。基于瞬时能耗可计算出在驾驶行为i状态时的平均能耗,计算如下:
(2)

(3)
式中:FC指工况内的百公里油耗;v指均速度;D指燃油密度,93#汽油密度为725 g/l。
2.3 数据预处理
GPS设备可以采集经纬度、速度等信息,但是由于采集过程可能会受测试仪器、环境、驾驶员等影响,因此必须通过预处理移除不可信的数据,从而保证后续实验数据的有效性。另外本文假设在30分钟内车辆位置的变化范围不超过50 m被认为是停车。
本文预处理包括数据清洗、地图匹配、轨迹分段。数据清洗方面具体操作如下:
1) 删除超出实验路段经纬度范围的采样点;
2) 由于本文选取VT-Micro补充能耗,所以必须首先依据VT-Micro的参数标准,剔除无效数据;
3) 剔除具有相同时间戳的冗余采样点;
4) 本文驾驶行为不包含停车,因此要剔除无堵塞停车采样点;
5) 将原始数据切分成多个微观行程,每段时长不超过3分钟。
进行地图匹配时需要将GPS数据与标准经纬度信息匹配,剔除无效样本点。本文将选取一种针对大规模GPS数据的地图匹配算法[18]。
本文把轨迹段作为识别驾驶行为的基本单元,由于行驶过程中会产生有效与无效轨迹段,因此引入净曲率和平均距离指标来对此进行划分。用于计算净曲率和平均距离的因子如图3所示。
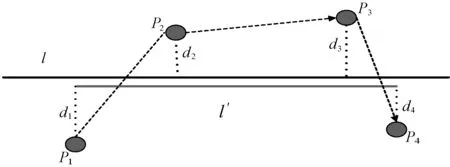
图3 计算轨迹净曲率和平均距离的指标
净曲率:表示实际轨迹与路网的匹配度,l/l′值为1表示完全匹配,反之表明差异性高。l表示轨迹原始长度,l′表示匹配到路网上的长度。
实验基于以上两个指标,利用随机森林分类器进行训练,然后根据训练后的模型对剩余轨迹段进行划分,最后基于有效轨迹段识别驾驶行为。
3 多工况典型驾驶行为聚类识别
3.1 不同驾驶工况的聚类研究
聚类在类标签未知时自动进行划分,是一种无监督学习算法,它尽可能将相似数据划分到同一个类,反之划分到不同的类。目前在交通类的研究项目中也广泛运用到聚类算法[19-21]。
3.1.1 基于Eros距离的相似度度量方式
目前最常用的度量方式是欧氏距离和动态时间弯曲距离[22]。利用欧式距离处理时间序列的相似度时,计算结果与实际距离有较大差异,因此本文不采用欧氏距离度量。动态时间弯曲距离曾经主要运用于语音识别[23],目的是寻找任意两个向量之间的最短距离,但在处理时间序列时,时间轴的微小变化也会对结果产生较大影响,因此本文也不选用动态时间弯曲距离进行度量。
本文选择借鉴多维时序相似性的度量思想,利用基于Eros(Extended Frobenius Norm)距离的度量方式对本文采样点进行相似性度量。Eros距离是基于矩阵加权F范数进行扩展的,矩阵Am×n的加权F范数如下[24]:
(4)
式中:w表示权重向量矩阵,迹为1。特征向量A-VA=[a1,a2,…,an]和B-VB=[b1,b2,…,bn]的Eros距离如下:
(5)
3.1.2 Eros距离中权值的计算方法
常见的权值计算方法有:和法、根法、特征根法、对数最小二乘法、最小二乘法[25]。本文在Eros距离中的权值计算过程如算法1所示。
算法1 计算权值向量
输入:特征值矩阵Sn×N
输出:加权向量
1) 将矩阵按列进行单位化
2) 计算矩阵每一行的和{sum1,sum2,…,sumn}
3) 计算整个矩阵的和Sum
4) 计算加权向量=sumi/Sum
3.1.3 基于K-means的工况聚类
本文针对采样点,利用基于Eros距离度量的K-means算法对驾驶工况进行聚类。实验部分研究低、中、高速三种驾驶工况,聚类中心见表2,各个工况的时间百分比见表3,聚类结果见图4,其中X轴为瞬时速度,Y轴为瞬时能耗。

表2 驾驶工况划分结果

表3 驾驶工况时间百分比
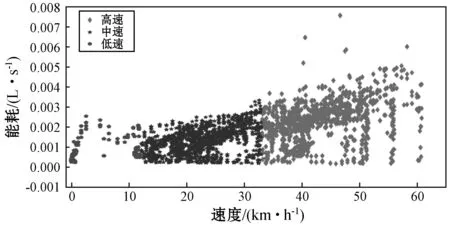
图4 驾驶工况聚类
3.2 不同驾驶行为的聚类研究
3.2.1 五种典型驾驶行为定义
本文基于行驶速度、加速度、持续时间与能耗之间的关系,提出五种与能耗相关的驾驶事件,分别是匀速、正常加速、正常减速、急加速、急减速,它们加速度的变化如图5所示。由于本文将轨迹段作为识别事件的基本单元,因此要求所有有效轨迹段的持续时长Δt≥2 s。

图5 加速度随时间变化图
3.2.2 驾驶行为特征提取
为了保证聚类效果的高效性,首先需要对以上五种典型驾驶行为进行特征提取。本文用于特征提取的参数见表4。

表4 用于特征提取的行驶参数
1) 匀速行为。匀速事件指在一段时间内加速度变化幅度较小的过程,它的变化如图5(a)所示。该事件的识别条件[26]如下:
-0.27 m/s2≤a≤0.27 m/s2
(6)
std(a)≤0.41 m/s2
(7)
2) 正常加速行为。正常加速指速度随时间缓慢增加的过程,它的变化如图5(b)所示。由于加速行驶时能耗量与持续时长呈正相关,因此在识别时除了考虑加速度还要考虑持续时间。该事件的识别条件[26]如下:
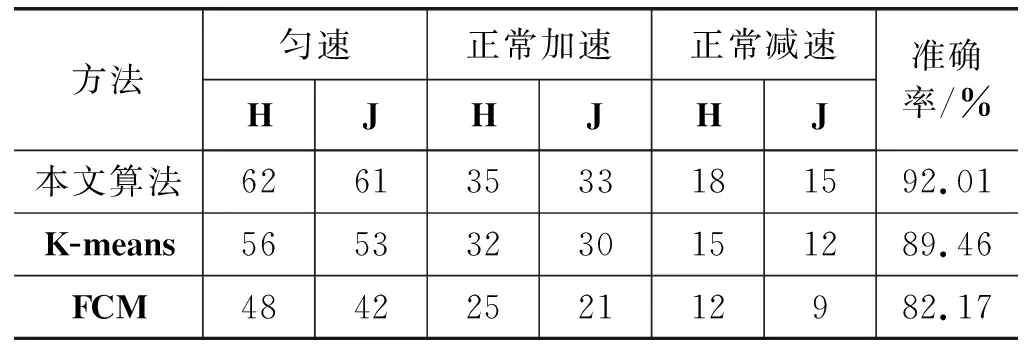
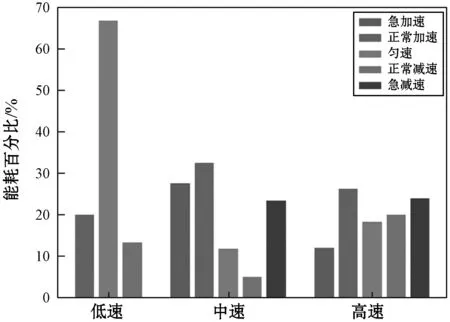
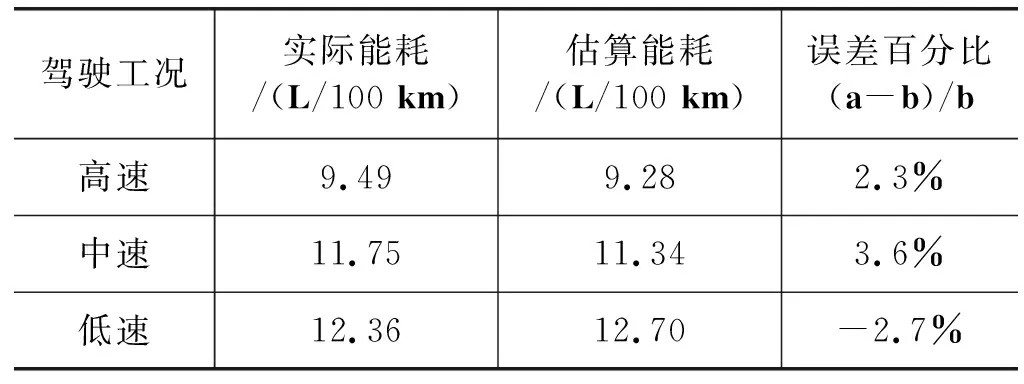
0.27 m/s2 (8) Δt≥2 s (9) 3) 正常减速行为。正常减速指速度随时间变化缓慢降低的过程,它的变化如图5(c)所示。该事件的识别条件[26]如下: -1.38 m/s2≤a<-0.27 m/s2 (10) 4) 急加速行为。急加速事件指驾驶员操作使行驶速度瞬间得到提升的过程,它的变化如图5(d)所示。该事件的识别条件[26]如下: a>1.11 m/s2 (11) 5) 急减速行为。急减速事件指驾驶员操作使行驶速度瞬间降低的过程,它的变化如图5(e)所示。该事件的识别条件[26]如下: a<-1.38 m/s2 (12) 3.2.3 基于AGNES谱聚类的行为识别及准确度分析 本节基于AGNES谱聚类算法对提出的5种驾驶事件进行识别,由于原始实验样本具备属性广、数据量大、存在无效数据等特点,因此采用该方法对样本进行聚类分析。首先在对以上事件进行特征提取的基础上进行谱聚类,然后使用AGNES进行二次聚类,最后得到五个驾驶行为类。 在对每种驾驶工况进行行为识别时,首先利用谱聚类得到样本特征值和特征向量,然后用AGNES算法对上级结果进行聚类分析,其中AGNES算法可以减少人为因素的影响、提高聚类的准确率。实验整体流程如算2所示。 算法2 基于Eros距离的聚类算法实现 输入:高速、中速、低速工况中的有效轨迹段 输出:不同的驾驶行为类 1) 利用闵可夫斯基距离构建基于样本集的邻接矩阵; 2) 利用KNN算法获取相似矩阵W; 3) 基于W生成度矩阵D; 4) 利用W和D构建拉普拉斯矩阵L=W-D; 5) 对L的特征向量实现凝聚层次聚类算法; 6) 利用Eros距离计算特征向量的初始距离矩阵; 7) Loop 8) 获取距离矩阵中值最小的两个类; 9) 合并8)中的类,并覆盖以上索引值较小的类; 10)计算新类和其余类的距离,重新生成距离矩阵; 11) 重复8)-10)步,直到满足各工况下的类个数退出循环。 本文实验部分在低速时,由于车辆处于起步阶段因此没发生急加速、急减速,而在中速和高速时,为及时应对交通状况,以上五种行为都会发生。 本文方法与K-means算法、FCM算法的准确度对比结果如下:由本文方法在高速工况下识别到的各类行为样本量见表5,算法准确度比较见表6;中速工况下样本量见表7,准确度比较见表8;低速工况样本量见表9,准确度比较见表10。其中H指检测为某类驾驶行为的数据,J指正确检测为该类驾驶行为的数据。由表可知本文提出的基于Eros度量的两级聚类算法相对于K-means算法和FCM算法具有较高的准确度。 表6 高速工况下算法准确度比较 表7 本文方法在中速工况下识别的各类行为样本量 表8 中速工况下算法准确度对比 表9 本文方法在低速工况下识别的各类行为样本量 表10 低速工况下算法准确度对比 实验部分针对个人出行轨迹数据进行分析,实现不同工况的聚类,其中高速工况的能耗占全部能耗的56.6%,中速工况能耗占38.6%,低速工况能耗仅占总能耗的4.8%。多工况下典型驾驶行为的累计能耗对比如图6所示,平均能耗分析如图7所示,评估模型准确度分析见表11。 图6 累计能耗对比图 图7 多工况下驾驶行为的平均能耗 表11 本文评估模型准确度分析 从图7观察到:高速工况的驾驶行为平均能耗高于中速、低速时任何行为的平均能耗。在高速工况下进行分析得到:急加速行为的平均能耗最高,比正常加速时高31%;急减速行为的平均能耗次之,比正常减速行为的平均能耗高35.4%;而中速工况时急加速行为的平均能耗比正常加速高11%,急减速行为的平均能耗比正常减速高85.9%。 本文主要工作是提出一个基于多工况典型驾驶行为的能耗评估模型,针对出行轨迹数据识别出高速、中速、低速三种驾驶工况以及急加速、急减速、加速、减速、匀速五种与能耗相关驾驶行为,并在每种情况下,分析机动车的能耗变化情况。实验在三种不同驾驶工况下,将该模型与K-means和FCM算法对同一数据集的行为识别精度进行比较,发现本文算法的识别度高达92%以上,优于其他两种算法。从机动车的能耗变化情况中发现:高速工况时急加速行为的平均能耗比正常加速高31%,急减速行为比正常减速高35.4%;中速工况时急加速行为的平均能耗比正常加速高11%,急减速行为比正常减速高85.9%。将实际能耗与模型能耗对比发现,该模型的能耗评估误差在±4%内。由此可见,该模型可以为交通部门的道路能耗评估提供有效方法,并且为交通部门实施交通管控提供参考。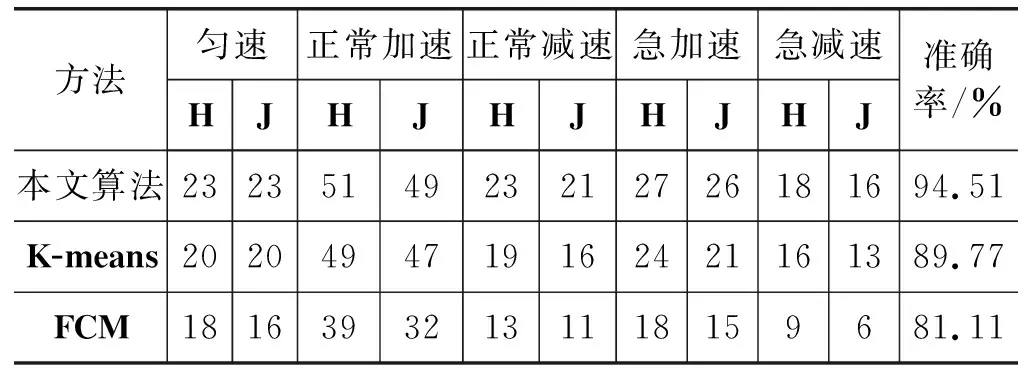



4 多工况下典型驾驶行为的能耗分析

5 结 语
