基于Netvlad神经网络的室内机器人全局重定位方法
2020-05-15陈承隆邱志成杜启亮田联房
陈承隆,邱志成,杜启亮,田联房,林 斌,李 淼
1.华南理工大学 机械与汽车工程学院,广州510640
2.华南理工大学 自主系统与网络控制教育部重点实验室,广州510640
3.华南理工大学 珠海现代产业创新研究院,广东 珠海519170
4.广州地铁设计研究院股份有限公司,广州510010
5.日立电梯(广州)自动扶梯有限公司,广州510660
1 引言
近年来,随着人工智能技术飞速发展,作为人工智能技术结晶的智能机器人行业也迎来新的契机,越来越智能的机器人被应用于社会生活的方方面面,如超市导购、快递分拣、酒店前台引导、智能送餐、变电站巡检[1]等。而这些机器人功能的基础都需要精确的位置信息才能够完成,因此机器人全局定位和定位失效恢复功能就显得极其重要。
目前室内机器人的全局定位恢复功能的实现主要分为四种方案:基于激光雷达二维点云的匹配定位[2-4]、基于WLAN 和位置指纹的定位[1]、基于文本的图像检索定位[5]和基于图像内容检索[6-15]的定位。其中基于激光雷达的匹配定位使用贝叶斯滤波框架[3]将定位问题转换为了概率分布问题,在小型室内地图中比基于WLAN和位置指纹的定位效果更加稳健,但是在区域有动态目标和地图中有对称房间的情况下定位容易失败。基于WLAN 和位置指纹的定位则是通过信号衰减理论模型将接收到的信号强度和能量损耗转化为传播距离的方法,在无噪声干扰的实验室环境下表现较好,但在实际环境中容易受到环境噪声干扰,精度下降严重。基于文本的图像检索需要人工构建图像的文本描述,对于小型数据集比较适用,但是因为人们难以用文字全面描述整个图像的内容而导致查询精度并不高。对于基于图像内容检索的定位,又分为全局特征向量匹配和局部特征向量匹配[16],其中局部特征向量的生成需要人工构建感兴趣区域,容易受到人为认知局限性的影响,而全局特征向量更好地利用了卷积神经网络能够提取深层特征的特性,能够提取到人工难以找到的细节特征,从而在高相似数据集中具有较高的鲁棒性。提取特征向量后通过特征匹配方法在图像数据库中找到与查询图像最相似图像的位置标签作为查询图像的位置,此方法因其较高的准确性被广泛应用于定位问题中,但其在弱光以及缺少特征情况下仍表现不佳。
室内环境中,不仅是相近地点的全景图像具有很高的相似性,而且对于空间隔离的全景图像有时候也表现为极高的相似性,所以在室内仅使用摄像头一种传感器进行重定位是非常困难的。充分利用机器人上多种传感器的信息是解决机器人全局定位[17]的主流方向。
针对上述定位方法存在的查询准确率低的问题,本文提出了多阶段多传感器自适应调整的全局重定位方法,包括重定位引导阶段、粗定位阶段和精定位阶段三个子阶段。下面分别介绍各个阶段及具体流程。
2 框架流程及引导阶段
整体流程分为在线定位和离线训练两个部分,如图1所示,离线阶段通过改进的Netvlad网络训练获取模型参数并保存模型,以供在线定位阶段使用。在线定位阶段首先获取激光雷达的实时信息,根据障碍物信息以一定规则引导机器人到达空旷区域,然后旋转拍摄离散的全景图像,将图像输入Netvlad[18]网络进行图像查询,计算相似性排名,如果相似性得分都小于阈值则判定查询失败,返回引导阶段,否则将得到的粗略的定位信息作为蒙特卡洛定位的初值继续迭代定位,经过一段时间粒子不收敛则判定为定位失败,返回引导阶段,否则认为定位成功。

图1 全局重定位流程图
在整个流程中引导过程十分重要,它是整个方法形成闭环的关键过程,一定程度上提高了重定位系统的稳定性。
首先将激光雷达障碍物信息按照角度均分为8 个区域,每个区域中心轴为区域主方向,统计每个区域内障碍物平均距离,以机器人当前位置为圆心,1 m 为半径,与平均距离最远的区域的主方向相交点为目标点,如果目标点在障碍物上(不可达)或者接近障碍物,则将半径缩小为0.5 m。最后将机器人引导至目标点,在定位失败后重复此过程直至定位成功。
3 原始Netvlad网络粗定位
Netvlad是Relja等人提出的一种快速高效的针对室外的大规模地点识别方法,其使用了Vlad(Vector of Locally Aggregated Descriptors)编码技术,即使用聚合后的局部特征表示全局特征的编码方法。Netvlad 考虑了离散全景图像之间的空间信息,可以从任意一张或多张图片中快速准确地进行地点识别,并使用了软分配和更多的可训练参数,得到的特征向量描述对于视角和光照变化具有很高的鲁棒性,原始论文中的实验也证明了这一点。
3.1 原始Netvlad网络结构及原理
Netvlad 卷积神经网络的训练过程是求解和优化特征提取网络输出的N×D(N=W×H)维特征图描述符中K×D 个聚类中心的位置和每个描述符对所属类中心贡献的权重,统计特征图描述符与聚类中心之间的带权重残差和作为图像描述向量,使得其与查询图像之间欧几里德距离最小的图像之间的描述向量的相似度最高,而与远离查询图像的图像之间的描述向量相似度最小。其中使用图像的拍摄地点来作为训练过程中的弱监督标签,判定正负样本规则使用欧几里德距离函数。网络结构[18]如图2 所示,输入图像尺寸为640×480,基础网络为VGG-16[19],使用了VGG-16的前13个卷积层,最终输出特征图尺寸为W×H×D(20×15×512),在VGG-16特征图输出后接入Netvlad层。在Netvlad中输入N(W×H)个D 维局部描述符,将聚类算法获得的K×D 个聚类中心作为参数,计算N 个特征点与聚类中心的带权重残差和作为图像描述矩阵V 的元素,最终将V 转换成矢量形式并归一化作为图像的特征描述向量输出。矩阵V 元素计算公式为:

式中,Xi是特征图输入,xi(j )第j 维的第i 个描述符,ck(j )为第j 维的第k 个聚类中心,是每个xi(j )描述符对第k 个聚类中心的贡献权重。软分配权重计算公式为:
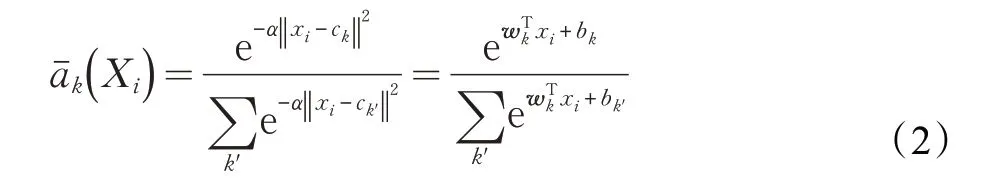
式中,wk=2αck,bk=-α‖ ck‖2,α是一个正常数,用来控制权重对距离的响应程度,ck是第j维第k个聚类中心。软分配函数是Netvlad 卷积神经网络与原始的Vlad 方法的核心区别,因为原始Vlad 方法使用的是硬分配函数,权重分配非1 即0,即应分配函数不可微,无法参与误差反向传播,一般使用提取到的特征向量送入SVM、Random Forest等分类器训练。而Netvlad将权重分配函数换成了可微分函数,又将聚类中心ck解耦成wk、bk、ck三个可训练参数,比传统方法更具有灵活性。
3.2 损失函数
Netvlad 网络中损失函数使用了弱监督的三元组排序损失,即,对于每个查询图像q都从数据库中找到一组正样本图像和一组负样本图像,如果查询图像q 与最匹配的一个正样本的地点标签之间的欧几里德距离小于其与所有负样本之间的欧几里德距离,则损失为0,反之,则按照距离差值进行损失惩罚。匹配度最高的唯一正样本图像则根据欧几里德距离最小原则在一组正样本图像中进行挑选,选取后三元组为,其中为:

总损失函数为:
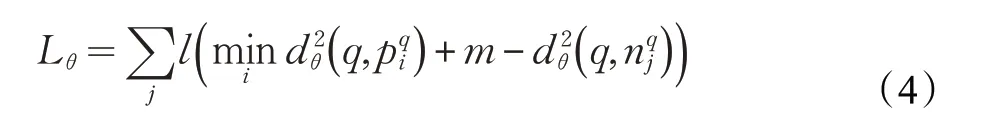

图2 原始Netvlad网络结构图
4 改进的Netvlad网络粗定位
4.1 栅格地图连通域距离
欧几里德距离和连通域距离对比如图3 所示,图中圆点为数据集图像采集点,实线长度为欧几里德距离,虚线长度为连通域距离,两点之间只有实线则两种距离相等。如果使用欧几里德距离判定1 号位置的正样本图像,则3 号地点图像会被判定为正样本,然而3 号地点由于和1 号地点隔着墙体,图像相似度必然会很低,在训练过程中会产生错误惩罚,影响模型收敛速度和稳定性,同理2 号点的正样本中会包含4 号点。如果使用连通域距离,1 号点的正样本则不会选择3 号点,而是2 号点,2 号点的最匹配图像则会选择6 号点。在负样本选择中,3 号和4 号点会被分配到1 号和2号点的负样本中。本文将正样本选择标准中计算量较大的欧几里德距离计算改为矩阵元素值查询,但稍微增大了存储空间,在室内环境下的数据集中能够提高算法的稳定性。

图3 欧几里德距离和连通域距离对比图
4.2 引入Resnet残差网络
VGG-16 网络是由16 个卷积层和3 个全连接层组成,整个网络全部统一使用3×3 的卷积核,共有16 个权重层,包含参数1.38 亿个。VGG-16 网络具有训练参数众多,计算量大,网络深度较浅,提取特征层级较浅,收敛速度较慢等缺点,而Resnet-50 由于引入了残差结构使得深层网络不容易发生退化问题,与具有相同参数量和计算量的线性网络结构相比能够提取到更加深层的特征,减小了模型的复杂度,提高了模型的检测识别率和收敛速度。鉴于上述优点,本文将Netvlad 中提取特征的主干网络替换为Resnet-50,改进后的Netvlad 主干网络的网络结构如图4所示,网络输入仍是640×480,新的特征图提取层为Resnet-50 中的Conv2_x、Conv3_x、Conv4_x 和Conv5_x,最终输出特征图尺寸为20×15×512,去掉Resnet-50 最后的均值池化层和全连接层,添加1×1卷积层conv6,步长为1,输出通道为512。
5 自适应蒙特卡洛精定位
传统的蒙特卡洛定位在一定程度上可以解决全局定位和机器人绑架问题,一般通过添加随机粒子尝试恢复位姿,这个方法会大量增加无贡献粒子的数目,容易导致算法收敛性变慢或者耗尽计算机内存,且只能小概率恢复定位。本文结合库尔贝克-莱布勒散度[4](Kullback-Leibler Divergence,KLD)采样,以及自适应蒙特卡洛算法。由图像查询得到的粗定位地点位置作为自适应蒙特卡罗定位的初始随机抽样种子。将按照高斯分布产生的粒子,作为初始位置,可以明显提高位姿恢复的概率。
KLD 是一个描述两个概率分布差的测量值,其大小能够反映粒子群当前分布和真实分布之间的偏差。根据偏差变化大小可以判定机器人是否定位丢失和被绑架,并以此为标准动态的增加或减少粒子数,时刻保证使用最少的粒子获得当前分布对真实分布的最优近似。最小的KLD粒子数为:

图4 改进后的Resnet-50结构

其中,Nb表示样本占用的子空间数;ε 是目标分布误差的最大值;1-δ 表示误差小于ε 的概率。当生成的粒子数大于Nkld时,可以停止采样过程。
6 实验
6.1 实验设备及软件环境
本文使用轮式机器人作为移动平台,如图5 所示,在机器人顶部中心位置安装有舵机和摄像机,舵机只有一个俯仰自由度,偏航自由度由移动平台提供。摄像机分辨率设置为640×480,在距地面37 cm 处安装了一个单线激光雷达,扫描角度360°,角分辨率0.5°,帧率为10 帧/s。具体设备如表1所示。

图5 实验硬件平台

表1 移动平台设备组成
为了对比原始模型和改进Netvlad 网络模型的区别,基于图5 所介绍的实验平台,本文在Ubuntu 操作系统下结合ROS软件框架实现了以上所述基于改进Netv‐lad 卷积神经网络的室内机器人全局重定位方法。算法运行环境如表2所示。
6.2 数据集
全局定位范围大小为30 m×60 m 的室内区域,包含6 个房间和1 条走廊,为保证定位精度,数据采集点间隔为2 m,拍摄起始角度为全局地图y 轴方向,多数选择室内过道中间区域为采集点,训练集共采集108 个地点图像,共864 张图像,测试集共采集42 个地点。数据集的格式制作为标准的Pittsburgh 数据集格式,每个地点图像包括以机器人为圆心的圆上均匀的8个方向的8张图像,作为离散化的全景图像,由于特征向量的提取考虑了同一个地点离散图像之间的空间信息,所以不需要人工标注和拼接成全景图像。图6 显示了华南理工大学3号楼2 层和部分实验室室内区域的栅格地图,分辨率为5 cm×5 cm。图中选择性的显示了测试集中4 个地点的图像,同一个地点仅显示第一张图像,黑色箭头为图像拍摄方向。
表2 软件环境

图6 华南理工大学3号楼2层栅格地图
6.3 模型训练及验证
在6.2 节所述的数据集上分别使用原始的Netvlad模型和改进的Netvlad 模型进行训练,训练采用SGD 优化方法,动量因子设置为0.9,图像批处理大小设置为12,聚类算法中心数k 为64,初始学习率为0.001,如果模型训练10 个周期内性能不再提升,则将学习率减半,20个周期内性能不再提升,则停止训练。如果根据图像相似度查询得到的前N 个预测地点中任意一个在以查询图像真实地点为圆心1 m 为半径的圆内,角度误差在22.5°以内,则认为查询结果正确。文中定义TOP@N为根据相似度查询得到的前N 个图像。对于图像查询一般使用精确率对模型进行评价,精确率定义为查询正确地点数目和查询地点总数的比值。对比实验分别训练4个模型:原始Netvlad(VGG-16)、单独添加连通域距离改进的Netvlad 模型(VGG-16+AStar)、单独引入残差网络改进的Netvlad 模型(Resnet-50)和同时加入两种改进的Netvlad 模型(Resnet-50+AStar),模型训练损失及测试集精确率如图7(a)~(d)所示,损失曲线x轴已做归一化,曲线平滑因子0.744。
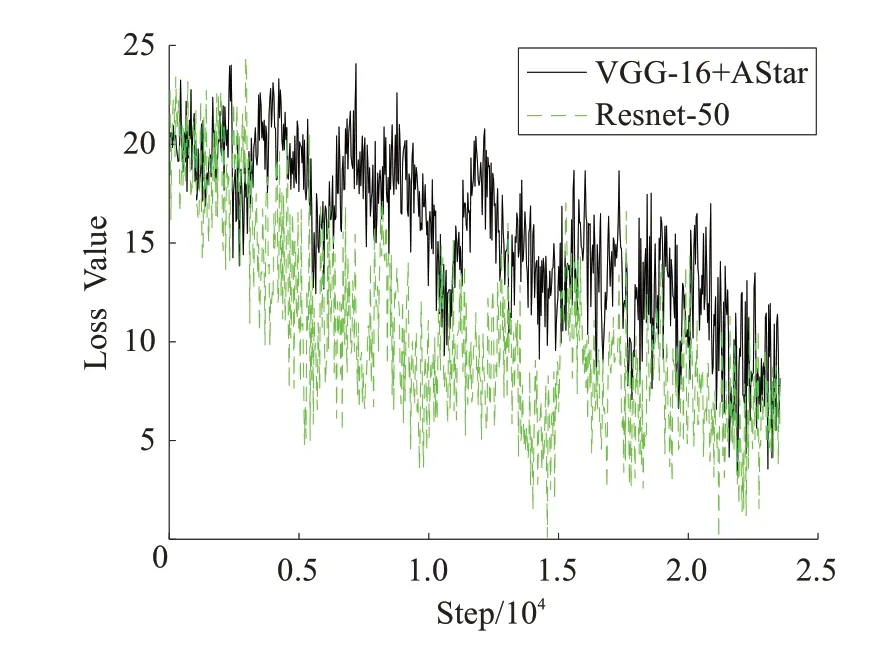
图7 (a) VGG-16+AStar和Resnet-50损失曲线

图7 (b) VGG-16和Resnet-50+AStar损失曲线

图7 (c) VGG-16+AStar和Resnet-50精确率

图7 (d) VGG-16和Resnet-50+AStar精确率
由训练过程中的损失曲线可知,未加入连通域距离的模型损失震荡幅值范围较大,未引入残差网络的模型的最终损失值较高,由精确率曲线可知,两种改进均可提高模型收敛速度和精确率,且当TOP@N 为1 时引入连通域距离后模型精确率提升了1.323%,引入残差网络后模型精确率提升了3.287%,当TOP@N 为4 时引入连通域距离后模型精确率提升了3.529%,引入残差网络后模型精确率提升了8.541%,故加入连通域距离的改进可以抑制室内场景模型的错误惩罚,加快模型收敛,引入残差网络可以提高模型的判别能力。
6.4 基于图像查询的粗定位
本文模型可以兼容每个地点的查询图像小于8 张的情况,以简化重定位复杂度,但会损失部分精确率。为了全面评价4个模型定位精确率在1 m范围内和角度误差范围内的精确率,故对测试集42 个地点进行精确率测试。在测试集中选取10 个地点分别使用4 个模型对每个地点进行50 次查询,为了获得最佳查询性能每个地点查询图像固定为8 张图像,TOP@N 为4,测试结果如表3所示。

表3 平均精确率结果
根据表3 可知,加入连通域距离后4 个模型精确率在TOP@N 为1 时平均提升了1.7%,为4 时平均提升了3.2%,引入残差网络后模型精确率在TOP@N 为1 时平均提升了2.9%,为4 时平均提升了8.0%。同时加入两种改进后模型在TOP@N 为1 时精确率提升了4.6%,为4 时提升了11.2%。基于图像查询的重定位虽然可以帮助机器人定位,但定位准确率会随着定位精度的提高呈指数型下降,随着TOP@N 的减小而下降。故为了提高机器人定位精度,本文选择按照图像相似度排名给予查询出的地点标签相应权重,权重系数为4∶3∶2∶1[17],按照图像标签和权重系数分配自适应蒙特卡洛定位算法中初始粒子的分布位置和数量。
6.5 自适应蒙特卡洛精定位
根据上一节测试结果,本节实验选择原始Netvlad模型(VGG-16)和改进的Netvlad 模型(Resnet-50+AStar)做对比,本文采用TOP@N 为4作为本节实验设定,在实验过程中机器人每旋转45°拍摄一张环境图像。本文在实现了整个全局重定位系统的基础上,对全局重定位和绑架问题进行了测试。测试流程如图8 所示,其中A 至B 段为人工操控机器人行走阶段,B 至C 段为机器人绑架路线,在C 点由机器人自行判定定位丢失,这种情况下需要系统进行机器人全局定位,由改进的图像粗定位模块提供初始位姿,将排名前5 的地点按照上一节中的权重向自适应蒙特卡洛系统注入1 000 个初始粒子,经过引导阶段和图像查询定位以及自适应蒙特卡洛精定位过程,在D点成功定位。
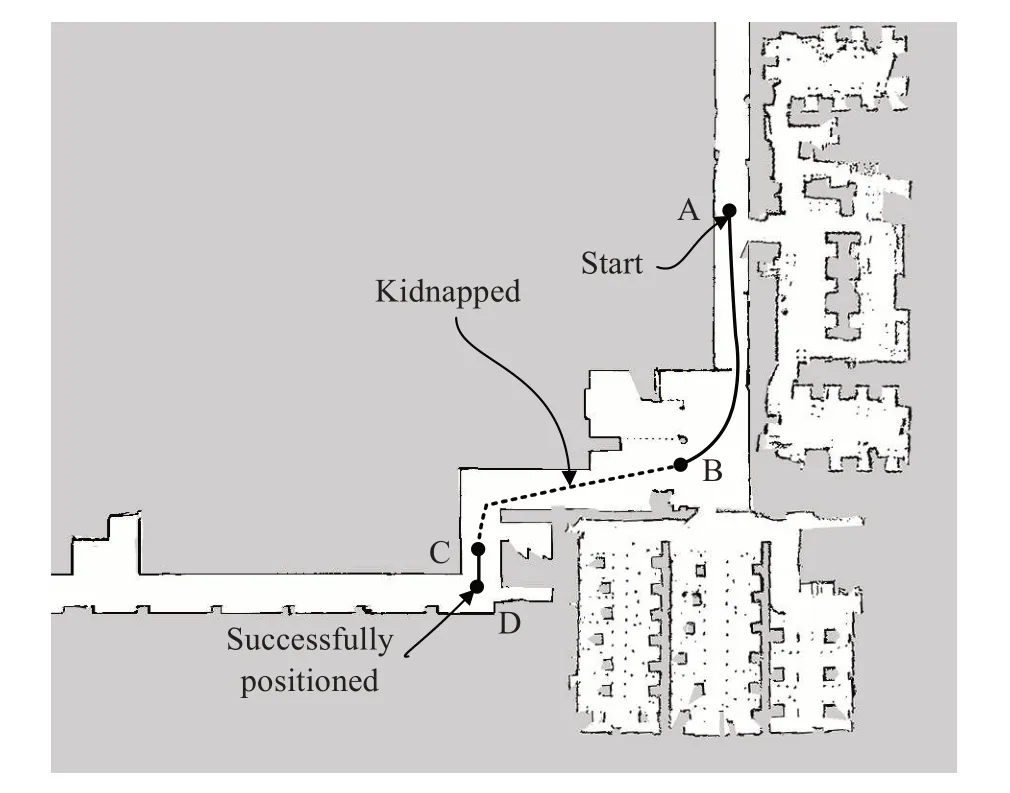
图8 机器人重定位流程图

图9 原始模型和改进模型全局定位误差图
图9 显示了两种模型在TOP@N 为4 情况下的全局重定位误差,在a 段机器人从B 点被绑架至10 m 外的C点,3 s 后启动全局重定位,b 段从12 s 开始引导机器人前进1 m,原地旋转并拍摄8张查询图像,c段从第21.5 s开始图像查询,原始Netvlad 模型经过e 段在第49.8 s 完成图像查询粗定位过程,粗定位误差为1.63 m,由于粗定位误差较大,经过f 段在第66.7 s 定位收敛,而改进的Netvlad 模型经过a、b 段在第21.5 s 完成查询图像拍摄,然后经过c 段在第38.5 s 完成粗定位过程,粗定位平均误差为0.9 m,最后经过d 段在第48.8 s 全局定位收敛。原始Netvlad 模型提取特征时比改进的Netvlad 模型的参数量大,故粗定位过程要慢11.3 s,其因为误差较大,精定位过程收敛要比改进的Netvlad 模型慢6.6 s,粗定位误差过大容易引起二次全局重定位,定位时间将会翻倍。故从整体上看,改进的Netvlad 模型要优于原始Netvlad模型。
7 结论
针对室内移动机器人的全局定位和绑架问题,本文提出一种利用激光雷达信息预先引导,再利用改进的Netvlad 卷积神经网络图像查询进行粗定位,最后利用粗定位得到的位置作为初始位置进行自适应蒙特卡洛定位的闭环定位方法。本文方案使用聚合的局部特征作为全局特征表示,比人工标注感兴趣区域方法的特征表征能力更强,对于环境高度相似的数据集具有更高的鲁棒性,并省去了繁杂的图像标注工作,实验效果满足要求,故本方案能够有效解决室内移动机器人的全局定位和和绑架问题。但系统对于动态场景的适应性还有待进一步研究,对于多个场景下机器人自适应性问题,可以使用由大型室内数据集训练的有一定泛化能力的通用模型,省去离线训练阶段,但是有针对性的训练则精确率会更高。
