基于数据优化的灰色预测模型在天津市供用水量预测中的应用
2020-05-14王晴晴王雪奎
王晴晴,王雪奎
(1.海河水利委员会海河下游管理局,天津 300061;2.中交天津港湾工程研究院有限公司,天津 300222)
灰色理论是著名学者邓聚龙教授在20世纪80年代提出的,用以研究“部分信息已知,部分信息未知”的“小样本”“贫信息”系统[1]。因该系统具有原理简单、计算方便、预测精度高、可检验性强等优点[2],被广泛应用于社会各个领域,如建筑物变形监测[3-5]、医学疾病发展趋势研究[6-7]、污染物排放控制等方面[8-9]。随着众多学者研究的不断深入,发现原始离散数据的光滑度是影响模型精度的关键因素之一,原始离散数据越光滑,利用这些数据所建立模型的精度就越高,也就越能真实反映预测数据的发展趋势[10]。笔者采用优化原始数据中的异常值,消除序列波动性以提高建模序列的光滑度,对天津市2010—2017年城市供用水量进行建模,比较数据优化前后的建模精度,并对天津市未来5 a的供用水量做出预测。
1 灰色GM(1,1)模型的建立
(1)设非负原始数列为x(0)=(x0(1),x0(2),…,x0(n))。
(2)建模可行性检验。计算原始数列的级比,对其建立灰色预测模型GM(1,1)的可行性进行判断。若用来建模的原始数列的级比λ(k)都落在可容覆盖区间X=()内,则数列x(0)可以建立GM(1,1)模型并进行灰色预测。

(3)对经过可行性检验的原始数列x(0)进行1-AGO变换,生成一次累加数列x(1)=(x1(1),x1(2),…,x1(n))。
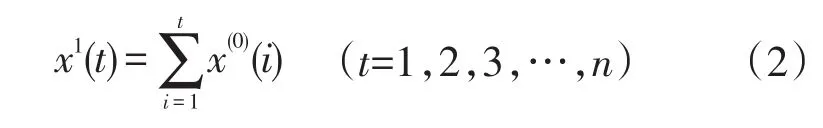
(4)对一次累加数列x(1)建立GM(1,1)模型的时间响应公式。

式中:a,μ为待识别的灰色参数,a为发展灰数,μ为内生控制灰数。
(5)构造数据矩阵B和数据向量YN。
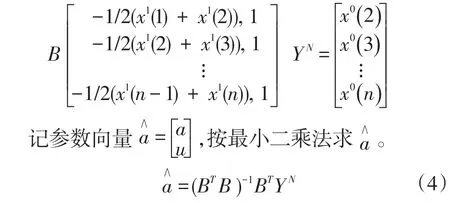
(6)将参数a,μ代入微分方程(3)求解时间响应。

方程的解即为一次累加数列x(1)的预测值,经累减逆运算得原始数列x(0)的预测值。
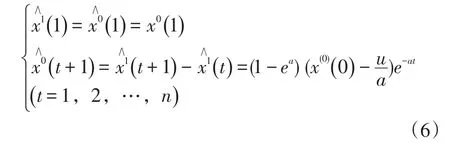
由式(6)可知,当(1-ea)(x(0)(0)-)、a符号相反 时 ,(t+1)(t=1,2,…,n)数 列 递 增 ;当(1-ea)(x(0)(0)-)、a符号相同时,(t+1)(t=1,2,…,n)数列递减。
当原始数列存在波动性时,对其中的异常值进行优化处理,基于新数列模型进行的GM(1,1)灰色预测结果将更符合实际。
2 模型精度检验
(1)记k时刻的残差为:
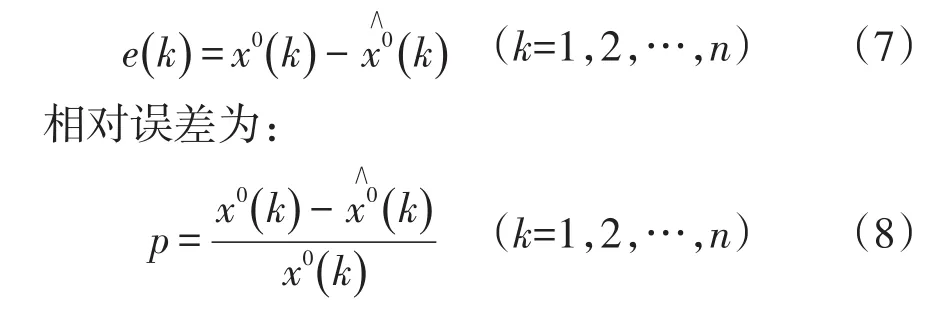
(2)分别求取原始序列x(0)及残差e(k)的平均值。

(4)后验差比值计算公式为:

小误差概率计算公式为:

预测模型精度等级,见表1。

表1 预测模型精度等级
3 实例分析
城市用水量预测不仅是给水配套工程,更重要的是协调控制工程,通过对水量的预测和平衡计算,依据水资源承载力,对城市的可持续发展提供科学技术支撑。天津市作为京津冀协同发展及环渤海经济圈的重要城市,水资源缺乏问题日益突出,水资源总量不足以承担全市用水需求,对外调水的依赖性日益增大。
以2010—2017年天津市城市供用水量为原始数列,原始数列为 x(0)=(21.73,22.46,21.29,23.76,24.09,25.68,27.23,27.49)。由此可以看出,剔除2012年供用水量数据后,原始序列呈现递增规律。为排除异常值对模型可能的不利影响,并保持原序列的连续性,取2011、2013年供用水量数据平均值作为2012年的优化值,经优化后的原始数列呈绝对递增性。建立传统模型I与基于数据优化后的模型Ⅱ,通过比较得出较优模型,进而对城市未来供用水量进行预测,结果见表2。供用水量数据来源于《天津市统计年鉴2018》。

表2 2种模型预测结果比较
由表2可以看出,2种模型模拟精度较高,预测精度均为1级。其中,模型I最大相对误差为-5.63%,后验差比值C=0.271 2;模型Ⅱ相对误差和后验差比值明显低于模型I,预测精度和拟合效果均优于模型I(如图1所示)。这说明基于数据优化的改进模型对提高灰色预测模型精度有显著作用。

图1 2种模型预测结果
基于以上结论,利用模型Ⅱ对天津市2018—2022年城市供用水量进行预测,结果见表3。

表3 天津市2018—2022年城市供用水量预测值亿m3
4 成果分析
(1)对天津市供用水量建立基于数据优化的GM(1,1)灰色预测模型,取得了较好的建模效果,说明消除原始数据波动性以提高灰色模型预测精度不但可行,而且更能反映出系统特征,相比传统模型更接近实际。
(2)从预测结果看,未来5 a内,天津市城市供用水量呈现增长趋势,到2020年城市供用水量将超过30亿m3,天津市水资源短缺问题将更加严峻。天津市应在未来城市规划中,综合水资源、水环境承载能力,优化区域空间发展布局,对人口、经济发展规模和资源开发强度进行合理管控,“以水定城”,以缓解水资源与城市发展之间的矛盾。
(3)笔者提出的数据优化处理方法对异常值较少的原始数列预测效果较好,但对波动性强、变幅较大序列的适用性还有待进一步研究和探讨。
