基于RGB-D图像的室内场景语义分割网络优化*
2020-05-11王子羽张颖敏陈永彬王桂棠
王子羽 张颖敏 陈永彬 王桂棠
基于RGB-D图像的室内场景语义分割网络优化*
王子羽1张颖敏2陈永彬3王桂棠1
(1.广东工业大学机电工程学院,广东 广州 5100062.广州沧恒自动控制科技有限公司,广东 广州 5106703.佛山沧科智能科技有限公司,广东 佛山 528200)
针对卷积神经网络在室内场景的图像语义分割中难以取得较高的分割精度,提出一种基于RGB-D图像的室内场景语义分割网络。该网络采用分别训练逐渐融合的方式对原始数据进行处理,并在解码阶段加入强化监督模块,有效提高语义分割的准确率;同时引入反残差的解码方法和跳跃结构降低信息损失。实验结果表明:REDNet的像素精度达80.9%,平均精度达58.4%,区域交集精度达46.9%,这些分割精度均高于FCN-32s,FCN-16s,SegNet,Context-CRF,FuseNet,RefineNet等常用语义分割网络。
RGB-D图像;语义分割;深度学习;卷积神经网络
0 引言
语义分割算法作为机器人进行场景理解的关键技术,是机器人实现人工智能应用以及与外界交互的关键。实质上,语义分割算法是一种分类算法。首先,判断输入图像中每个像素的类别;然后,将其标定;最后,得到物体在图像中所在位置的区域类别。
目前,语义分割算法主要有传统语义分割算法和基于深度学习的语义分割算法2种。传统语义分割算法采用区间信息、图像特征、分类算法等方法对输入图像进行语义分割。Zhang等[1]提出隐马尔可夫随机场(Markov random field,MRF)模型,并利用MFR产生的间接估计随机过程来分割图像;Kumar等[2-3]提出条件随机场(conditional random field,CRF)模型,其结合了最大熵模型和隐马尔可夫模型的特点,是一种经典分割模型;Felzenszwalb等[4]提出将HOG特征算子应用于语义分割算法;Karsnas等[5]采用基于区域的分割方法将图像分割成具有相同性质的小块;Yang等[6]根据支持向量机算法,提出一种基于层次模型的图像分割算法;Cohen等[7]使用几种颜色空间,如RGB,YcBcr,HSL,Lab和YIQ等分割图像。
基于深度学习的语义分割算法是当今研究的主流。Long等[8]提出全卷积网络(fully convolutional networks,FCN)结构,把传统神经网络中全连接层替换为卷积层,同时引入上采样及跳跃结构;Noh等[9]基于FCN结构提出采用编码-解码的DeconvNet结构;Badrinarayanan等[10]提出SegNet,采用类似DeconvNet结构,在解码器端实现更平滑的反池化操作;He[11]等提出深层次的深度卷积神经网络模型ResNet,引入残差模块,用于应对梯度爆炸等深度学习的难题。
由于RGB图像颜色选择模糊物体之间的边界,从而使场景中的空间信息大量丢失,如图1所示,导致FCN结构在室内场景的语义分割中难以取得较高精度。McCormac等[12]将深度信息和RGB信息直接组合成4通道信息,改善语义分割效果,提高了分割精度。Hazirbas等[13]通过实验提出一种分别训练逐渐融合的方式进行图像处理,取得比深度信息堆叠融合更好的实验结果。

图1 RGB图像与深度图像
本文提出一种基于残差网络(residual neural network,ResNet)的优化网络结构——带有编码-解码结构的残差网络(residual coder-decoder net, REDNet)。在下采样过程使用分别训练逐渐融合的方式提取图像信息;在上采样过程加入强化监督模块,优化语义分割结果。
1 REDNet结构
本文提出的语义分割网络REDNet结构如图2所示。该网络是以ResNet-34[11]为基准的深度神经网络,包括RGB图像训练分支(主要分支)和深度图像训练分支(次要分支)。2个分支单独训练又逐渐融合,即分别训练逐渐融合结构。
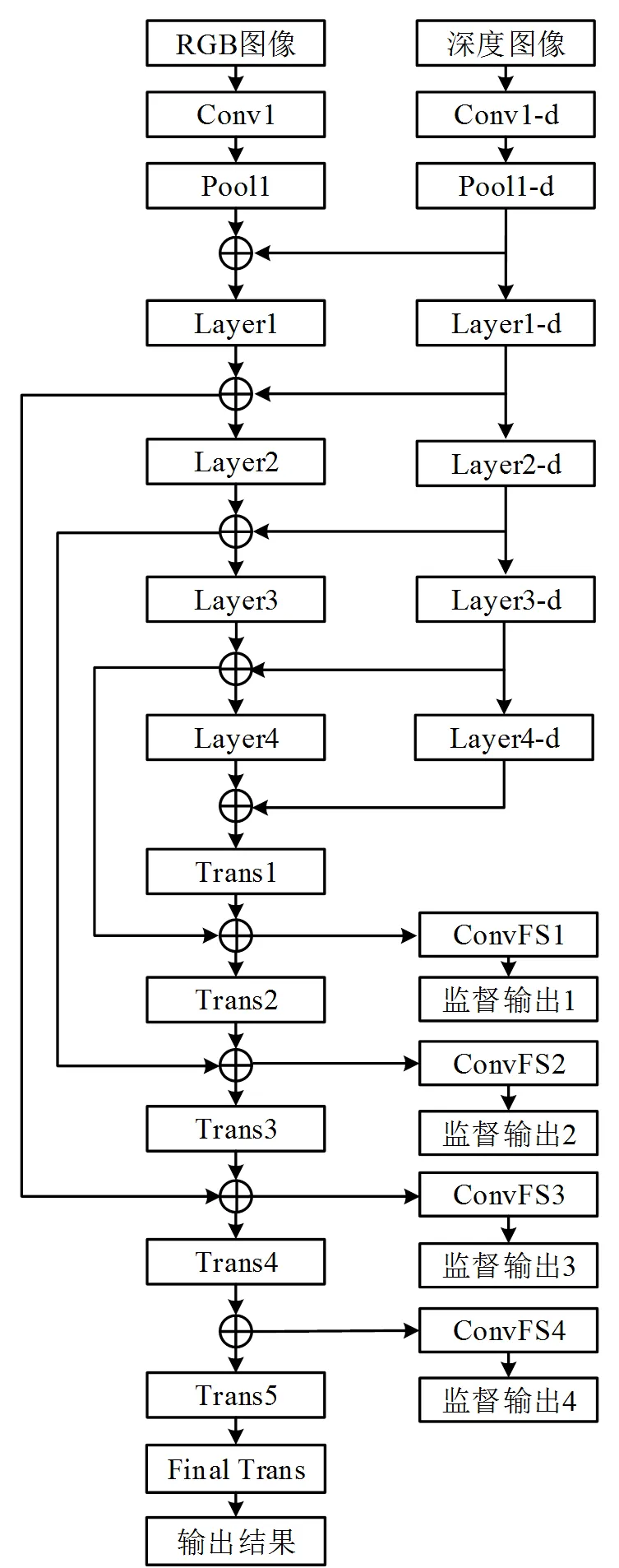
图2 REDNet结构
与传统编码-解码的神经网络结构不同,REDNet的下采样和上采样过程都引入了残差模块结构,同时上采样过程还引入了强化监督模块。
1.1 残差与反残差模块
本文采用的残差模块如图3所示,其中,Conv指卷积操作,[(3,3),1,1]表示卷积核是3×3,卷积步幅是1,通道系数是1。带下采样的残差模块相较于普通残差模块多了1个下采样分支,这相当于对输入尺寸进行1个下采样。为保持主要分支和次要分支的输出可直接进行元素相加,需转换其空间尺寸大小和特征通道数量。
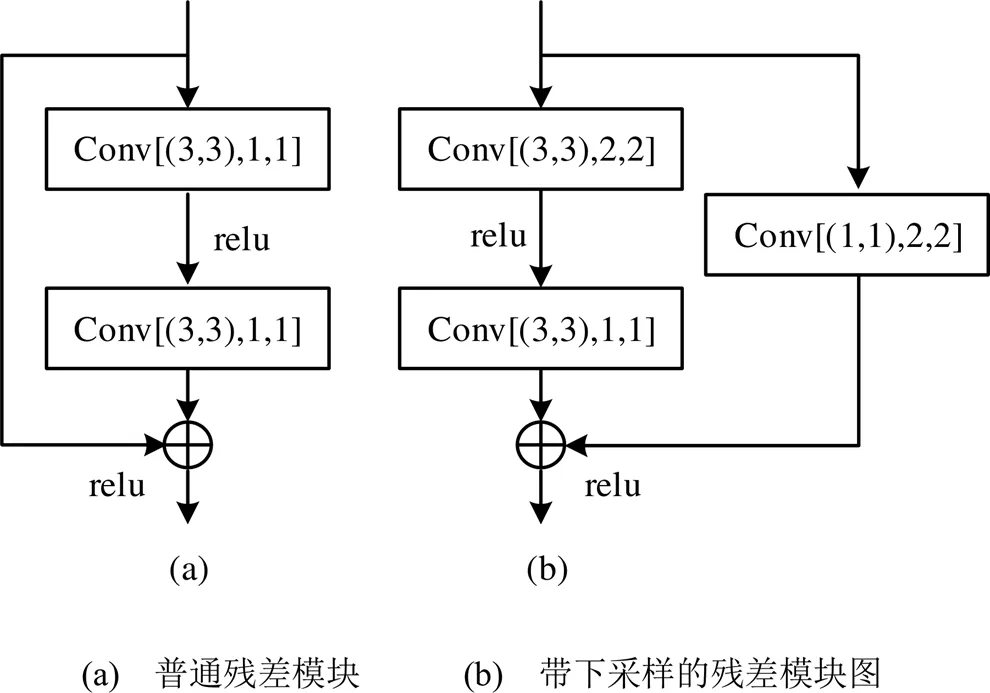
图3 残差模块
与残差模块类似,反残差模块也有2种形式,如图4所示。普通反残差模块与普通残差模块具有相同的网络结构;带上采样的反残差模块与带下采样的残差模块结构相似,主要区别在于卷积步幅和通道系数不同,且前者是解码过程,后者是编码过程。

图4 反残差模块
1.2 算法结构
REDNet网络模型采用编码-解码结构,在网络前半段对输入图像进行下采样,缩小特征层的空间尺寸;在网络后半段进行上采样,放大特征层的空间尺寸;最终输出的分割结果与输入图像大小一致。此外,还采用跳跃结构,把底层信息的精细特征传递到高层抽象信息,有效提高了语义分割精度。
REDNet在编码阶段使用分别训练逐渐融合的方式将RGB图像和深度图像的信息进行融合。模型主要分支从首个卷积层Conv1到残差层Layer4的结构以及次要分支结构,采用ResNet-34结构。分别训练逐渐融合的方式操作如下:
1)主要分支Pool1层输出和次要分支Pool1-d层输出以元素相加的形式融合,并把融合结果作为主要分支Layer1层输入;
2)以此类推,主要分支Layer2,Layer3,Layer4和Trans1的输入数据分别来自主要分支Layer1,Layer2,Layer3,Layer4和次要分支Layer1-d,Layer2-d,Layer3-d,Layer4-d运算结果的融合;
3)所有数据信息汇集到主要分支,次要分支完结,模型编码结束,随后的上采样解码阶段只有1条主要分支。
在解码阶段,REDNet采用3个跳跃结构保留精细特征用以提高分割精度。但Layer4层之后的结构被带有反残差模块的反卷积层代替,不再是传统ResNet结构,如图2所示。Trans2层输入是Layer3层与Layer3-d层信息融合结果再与Trans1层的输出信息融合产生的。以此为例,这种信息融合模式在上采样的解码阶段贯穿始终,其作用是优化语义推断的分割细节。本文没有将Trans4层运算结果与Pool1层和Pool1-d层的运算结果进行融合作为Trans5输入,是因为Pool1和Pool1-d的运算结果只进行一次卷积运算,其中细节信息十分原始,与Trans4层输出接近最终分割结果的区别较大,直接融合会降低分割精度,因此本文仅进行3次跳跃融合。其中,Layer1和Trans5使用普通残差模块;Layer2~Layer4采用带下采样的残差模块;Trans1~Trans4采用带上采样的残差模块;Final Trans层为反卷积层。
在解码阶段增加强化监督模块,如图2所示。其作用是对模型上采样阶段中Trans1~Trans4的激活层进行强化监督,强迫每个卷积层都能提取出对分割有用的特征,一层一层地优化最终的语义分割结果。该强化监督模块同样是一个卷积层,ConvFS1~ConvFS4卷积核为1×1,步幅为1,输出通道为37,即不改变输入数据的空间尺寸,只是对该位置进行物体分类,其输入是Trans1~Trans4四个反残差层。
2 实验网络构建和训练
本文采用当前应用较广的RGB-D语义分割数据集-SUN RGB-D图像数据集[14],其拥有10,335张RGB图像和深度图像同步数据,共包含20个场景和37个类别。该数据采集时使用IntelRealSense,Asus Xtion,Kinect v1和Kinect v2四种RGB-D图像获取设备,导致数据有4种不同尺寸。本文输入数据的尺寸统一为640×480像素,并将5285张图片作为训练集,其中有1000张图片为验证集;其余5050张图片作为测试集。
2.1 参数初始化
REDNet初始化参数时,引入迁移学习[15]的思路对网络参数赋值。利用ResNet-34在ImageNet数据集上进行物体分类训练,训练完成后将Conv1~Layer4的参数初始为训练中相应值。因为主要分支Conv1输入为RGB三通道图像信息,次要分支Conv1-d输入为单通道深度图像信息,所以不能简单地把Conv1的参数赋给Conv1-d。由于在RGB三通道图像信息获取中,不同卷积核对不同颜色的敏感度不同,因此,可通过平均RGB 3个分量的参数得到仅对灰度图像敏感的卷积核参数。
2.2 REDNet模型训练
训练REDNet模型时,用损失函数来衡量模型的表现,损失函数越低代表模型在分割任务中的表现越好。本文使用交叉熵损失函数对模型进行评价,计算公式为
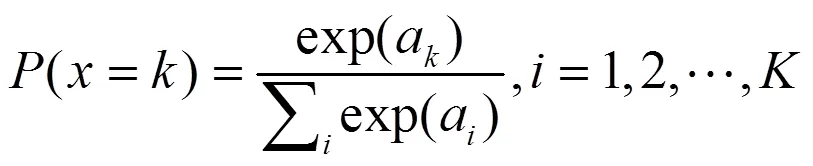
式(1)中,(=)为像素点属于正确类别的概率;为分类算法中类别的数量;a为第个类别的特征值。
当网络最后一层使用softmax函数时,交叉熵的公式为
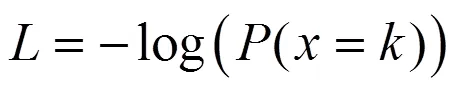
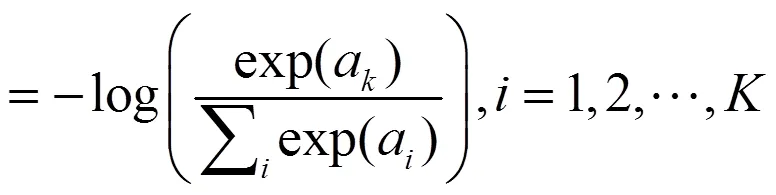
本模型的损失函数是以ConvFS1~ConvFS4和最终5个输出结果搭建的5个交叉熵函数之和。
训练REDNet模型时,采用带动量项系数的随机梯度下降方法更新参数。训练初始动量项系数为0.9,学习速率初始为0.002,训练100次后,训练学习速率乘以系数0.9进行衰减。
实验平台采用Intel I7-7700K中央处理器;NVIDIA GeForce 1080Ti显卡;Ubuntu 16.04 LTS操作系统,实验框架为pytorch。
3 实验结果分析
语义分割网络训练结果如图5所示。由图5可知,基于RGB-D图像的室内场景语义分割网络在对室内场景进行分割时,地面、墙壁、椅子、床、箱子等室内常见物体轮廓有清晰的界定,明确地标定其分割区域。

图5 语义分割结果
语义分割常用的3个评价标准分别是:
1)像素精度(pixel accuracy),即所有像素中分类正确的精度百分比,计算公式为

2)平均精度(mean accuracy),即各类物体像素精度的平均值,计算公式为

3)区域交集精度(IoU),即各类物体正确的分割区域与算法输出分割区域的交集所占两者总面积的百分比,计算公式为
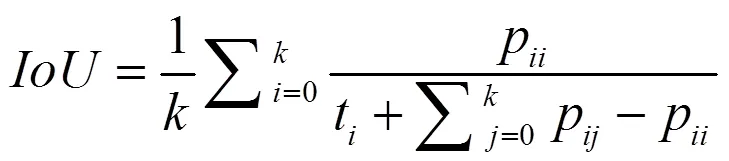
式中,p为类算法分类正确的像素数;p为属于类却被分入类(包括=的情况)的像素数;t为正确类别区域的总像素数;为所有分割类别的数量。
REDNet与其他常见网络的分割精度对比如表1所示。在相同实验条件下,先使用其他常见语义分割网络完成分割任务,得到分割精度;再对REDNet进行训练得到分割精度。需要说明的是:REDNet0没有采用强化监督模块,REDNet采用强化监督模块。
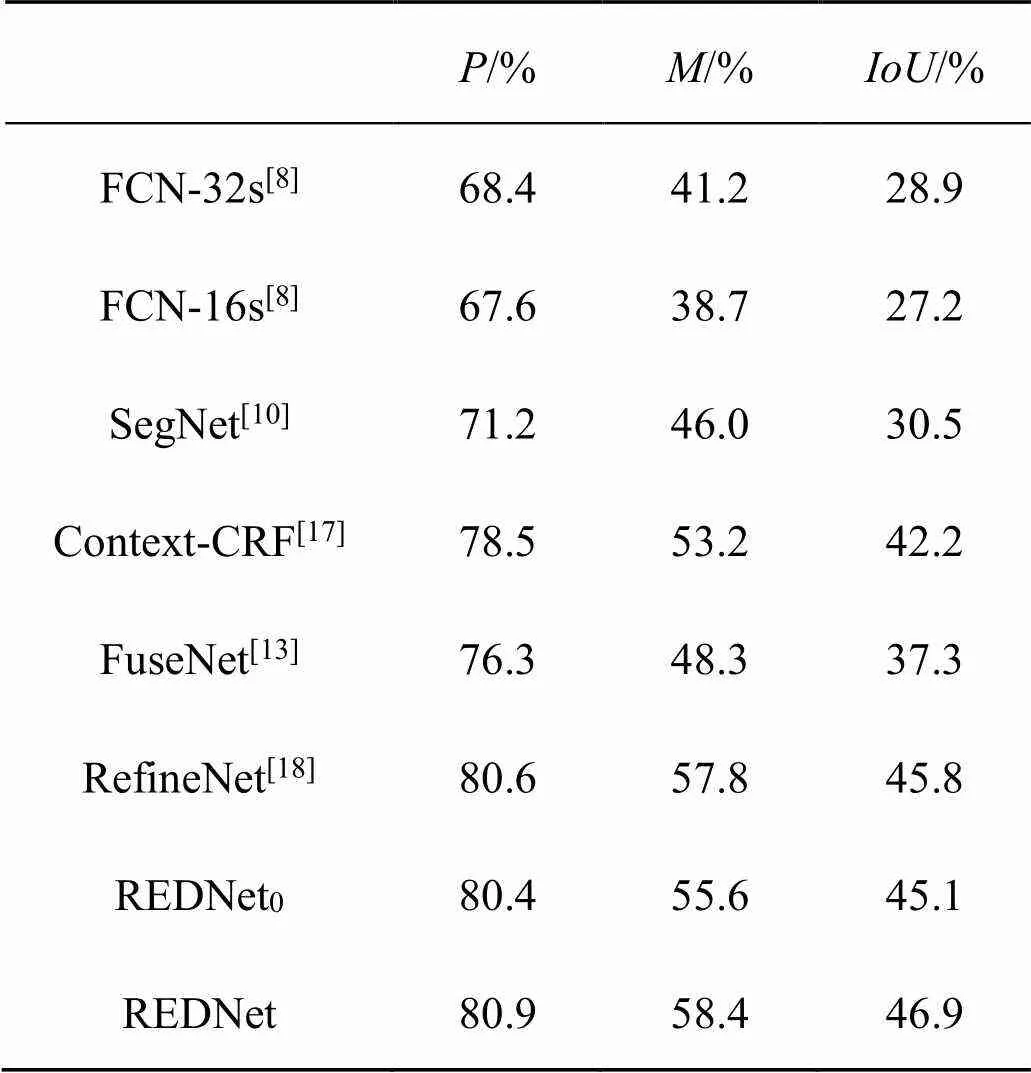
表1 REDNet与其他常见网络的分割精度对比
由表1数据可以看出:REDNet的分割精度高于其他常见的语义分割网络。从REDNet0和REDNet的数据对比可以得出:采用强化监督模块可以提高网络精度。
4 结语
本文基于ResNet提出一种优化改良的网络模型——REDNet。
1)在下采样过程,采用分别训练逐渐融合的方式对主要分支和次要分支的图像信息进行融合,有效保留数据的原始信息,提高语义分割的精度。
2)在上采样过程,添加强化监督模块,对每一层的解码层进行监督学习,提高了网络的分割精度。
3)在编码-解码过程中,都加入残差模块,有效解决了参数更新时梯度弥散的问题。
[1] Zhang Y, Brady M, Smith S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm[J]. IEEE Transactions on Medical Imaging, 2001,20(1):45-57.
[2] Kumar Sanjiv, Hebert Martial. Discriminative random fields: A discriminative framework for contextual interaction in classification[C].IEEE International Conference on Computer Vision. Nice: IEEE Computer Society, 2003:1150-1157.
[3] Kumar Sanjiv, Hebert Martial. Discriminative fields for modeling spatial dependencies in natural images[C].Advances in Neural Information Processing Systems. Vancouver: Neural Information Processing Systems Foundation,2004:1531-1538
[4] Felzenszwalb P F , Girshick R B , Mcallester D , et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9):1627-1645.
[5] Kårsnäs Andreas, Dahl A L, Larsen R. Learning histopathological patterns[J]. Journal of Pathology Informatics, 2011,2.
[6] Yang Y , Hallman S , Ramanan D , et al. Layered object models for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(9):1731-1743.
[7] Assaf Cohen, Ehud Rivlin, Ilan Shimshoni, et al. Memory based active contour algorithm using pixel-level classified images for colon crypt segmentation[J]. Computerized Medical Imaging and Graphics, 2015, 43:150-164.
[8] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[J]. Computer Vision and Pattern Recognition. Boston: IEEE Computer Society,2015: 3431-3440.
[9] Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation[C]. IEEE International Conference on Computer Vision. Santiago: IEEE Computer Society, 2016: 1520-1528.
[10] Badrinarayanan Vijay,Kendall Alex,Cipolla Roberto. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.[J]. IEEE transactions on pattern analysis and machine intelligence,2017,39(12):2481-2495.
[11] He K , Zhang X , Ren S , et al. Deep Residual Learning for Image Recognition[C]// IEEE Conference on Computer Vision & Pattern Recognition. IEEE Computer Society, 2016.
[12] McCormac J , Handa A , Davison A , et al. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks[C]// IEEE International Conference on Robotics & Automation. IEEE, 2017.
[13] Hazirbas C , Ma L , Domokos C , et al. FuseNet: incorporating depth into semantic segmentation via fusion-based CNN architecture[C]//ACCV Asian Conference on Computer Vision. ACCV,2016.
[14] Song, Shuran, Lichtenberg, Samuel P, Xiao, Jianxiong. SUN RGB-D: A RGB-D scene understanding benchmark suite[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2015.
[15] Thrun S, Pratt L. Learning to learn[M].[S.l.]: Springer Science & Business Media, 2012. Recognition (CVPR). IEEE, 2015:567-576.
[16] 项前,唐继婷,吴建国.多级上采样融合的强监督RGBD显著性目标检测[J].计算机工程与应用,2019,20:1-9.
[17] Lin G, Shen C, Hengel A v d, et al. Exploring context with deep structured models for semantic segmentation[J]. arXiv preprint arXiv:1603.03183, 2016.
[18] Guosheng Lin, Anton Milan, Chunhua Shen, et al. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017.
Optimization of Indoor Scene Semantic Segmentation Network Based on RGB-D Image
Wang Ziyu1Zhang Yingmin2Chen Yongbin3Wang Guitang1
(1. School of Electromechanical Engineering, Guangdong University of Technology, Guangzhou 510006, China 2. Guangzhou Cangheng Automatic Control Technology Co., Ltd. Guangzhou 510670, China 3. Foshan Cangke Intelligent Technology Co., Ltd. Foshan 528200, China)
In recent years, convolution neural network has been widely used in image semantic segmentation and achieved great success. We propose a semantic segmentation network for indoor scenes based on RGB-D images: REDNet. This network model uses separate training and gradual fusion to process the original data, and adds an forced supervision module in the decoding phase, which effectively improves the accuracy of semantic segmentation. At the same time, the anti-residual decoding method and jump structure are introduced to reduce the information loss. The experimental results show that REDNet has 80.9% pixel accuracy, 58.4% mean accuracy and 46.9% IoU, which are higher than FCN-32s, FCN-16s, SegNet, Context-CRF, FuseNet, RefineNet and other semantic segmentation networks.
RGB-D image; semantic segmentation; deep learning; convolution neural network
广州市科技计划珠江科技新星专题项目(201806010128);佛山广工大研究院创新创业人才团队计划项目。
王子羽,男,1993年生,硕士研究生,主要研究方向:机器学习和深度学习。E-mail: 676333341@163.com
张颖敏,女,1993年生,硕士研究生,主要研究方向:机器视觉及智能测控。E-mail: 2897273264@qq.com
陈永彬,男,1990年生,博士研究生,主要研究方向:机器学习人工智能。E-mail: 519075099@qq.com
王桂棠(通信作者),男,1964年生,本科,教授,主要研究方向:机器视觉及智能测控。E-mail: wanggt@gdut.edu.cn
TP391.7
A
1674-2605(2020)02-0005-06
10.3969/j.issn.1674-2605.2020.02.005
