基于支持向量机的钢板缺陷分类问题的研究
2020-05-09丛成吕哲高翔王敏
丛成 吕哲 高翔 王敏

摘 要:现实工业生产中,钢板表面存在不同类型的缺陷,为了研究这些缺陷类型,需要对大量钢板进行特征提取,从缺陷中提取有价值的属性或度量。随后对提取的特征进行选择,选择降低缺陷分类错误的特征信息。在钢板表面缺陷检测系统中,缺陷识别是关键步骤之一,属于多分类问题。采用主成分分析对初始数据进行降维处理,然后采用支持向量机作为分类器,对钢板表面缺陷进行分类,以研究钢板的缺陷类型。同时采用基于Keras的神经网络进行对比分类,并优化钢板缺陷分类。
关键词:特征提取;主成分分析;支持向量机;Keras;神经网络;机器学习
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2020)04-00-03
0 引 言
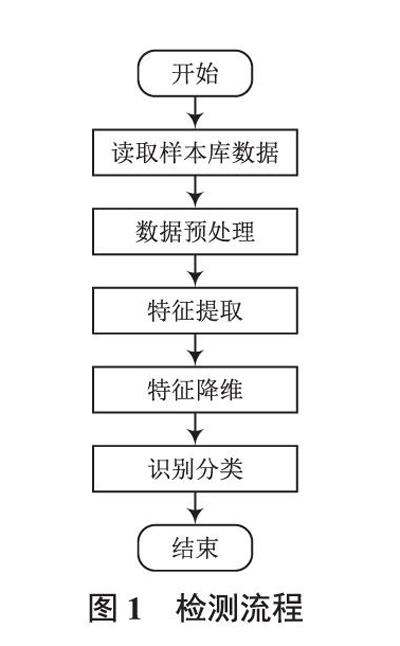
我国钢材制造产业迅猛发展,但钢板表面质量检测技术发展仍然缓慢,国内只有部分钢材生产商掌握了钢板表面质量检测技术,其余生产企业主要依赖于人工检测。在现实工业生产过程中,钢板表面可能会出现各种类型的缺陷,例如结疤、Z_划痕、K_划痕、污渍、裂纹等。受噪声、光照、钢板数量等因素影响,在后期图像处理过程中对采集的缺陷图像进行处理面临着很大的困难。基于已有的分类算法理论基础和实际工业生产环境,我们对缺陷检测和识别进行了深入研究,分析如何提高钢板表面缺陷检测准确度和识别精度,以提高产品质量、降低制造成本。钢板表面缺陷检测流程如图1所示。
1 数据预处理
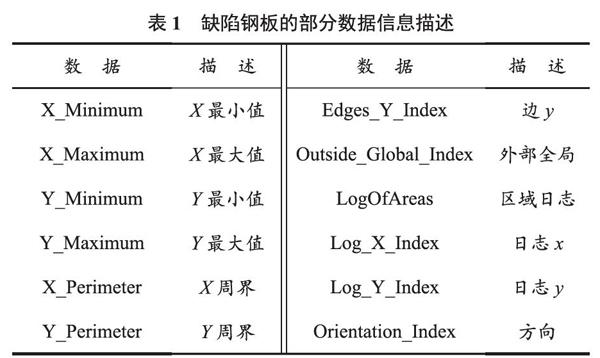
钢板缺陷分类的数据源提供了1 941个数据,每个数据有34种信息字段。前27个字段描述了钢板故障相关信息因子,后7个信息字段描述了包括七种可能的缺陷类型,分别为结疤、Z_划痕、K_划痕、污渍、裂纹、压痕、其他缺陷。输入向量由27个指标组成,其中包括X最小值、X最大值、Y最小值、Y最大值、像素_区域等指标,这些指标近似描述缺陷的几何形状及其轮廓。所有的数据集存储在faults.csv中,为方便分类,我们需要对数据进行预处理,先将1 941个
数据划分为两部分,即前1 000个数据作为训练集,后941个
数据作为测试集。再将原有csv文件划分为两个子文件input.csv和label.csv,用于表示算法的输入、输出。label.csv的
7列为虚拟变量,即如果板故障归类为“Stains”,则该列中将有一个1,其他列中将有0。缺陷钢板的部分数据信息描述见表1所列。
高维特征量作为训练样本进行识别分类时,存在很多问题。维数太高使得计算过程复杂,会耗费大量时间,因此需要在计算时间和信息量间进行适度衡量,其一,希望通过降维的方式来节省计算量和时间;其二,希望降维后的特征量尽可能多得保持原来的信息。本文采用主成分分析法对特征向量降维。主成分分析法是实现特征降维的有效方法,本文首先对提取的特征值进行归一化处理,再通过PCA对缺陷特征进行降维,实现有效特征的选择。对上述七种缺陷提取特征,将27维特征向量降至11维。降维后钢板表面的缺陷分类准确率较之前提升2%。
(1)训练集共有M个样本,每个样本大小为m×n,对应的训练样本矩阵如下:
(1)
对矩阵进行向量化处理,式中,ai是指将第i个图像数据矩阵变成m×n维的列向量。
(2)计算M个样本的平均值:
(2)
(3)计算第i个样本与均值的差值:
ci=ai-φ,i=1, 2, ..., M (3)
(4)构建样本的协方差矩阵:
(4)
式中,A=[c1, c2, ..., cM]是差值矩阵。
(5)求样本协方差矩阵的特征值和特征向量,构造特征空间。
2 分类原理
2.1 支持向量机SVM分类原理
训练集如下:
T={(x1, y1), (x2, y2), ..., (xn, yn)} (5)
式中:xi∈Rn,yi∈{-1,+1},i=1,2,…,N;xi为第
i个特征向量;yi为xi对应的标签;(xi,yi)称为训练集T中的第i个样本点。
训练的最终目的是在特征空间划分出一个超平面,线性可分SVM利用间隔最大化距离求最优分离超平面。线性可分SVM学习得到的分离超平面为:
(6)
式中:xi为第i个输入向量,即样本集合中的向量;w为xi对应的权值向量;偏置量为b,即超平面相对原点的偏移。得到的分类决策函数为:
(7)
SVM通过寻找支持向量使数据集间隔最大化,从而找到最优分割超平面。对于非线性可分样本,需要引入核函数。核函数能够将低维空间中的样本数据映射到高维空间,使得样本线性可分,其计算公式如下:
(8)
式中:φ表示从输入空间到高维空间的非线性特征映射过程。加入约束条件后,寻找最优分割超平面的过程可以看作是一个凸二次规划问题求解的过程。通过求解该问题,得到最优分类函数,其表达式如下:
(9)
式中,ai*和b*是只由支持向量確定的参数,能够用来调控最优分类平面。
2.2 基于Keras的神经网络分类原理
卷积神经网络属于前馈神经网络,本文是通过构建多个卷积层、汇聚层和全连接层交叉而成的一个网络,基于反向传播算法对划分出的训练集进行训练[1]。如果仅全连接前馈神经网络训练样本,则会导致参数太多、陷入局部最优。加入卷积神经网络后,通过局部连接、权重共享和等变表示,对神经网络进行二次优化。新加入的神经网络具有新特点:在超平面上平移、缩放和旋转不变性。基于Keras的神经网络模型采用序列模型和通用模型。序列模型各层之间是依次顺序的线性关系,在第k层和第k+1层之间可以加入各种元素来构造神经网络,这些元素可以通过一个列表来制定,然后作为参数传递给序列模型以生成相应模型。通用模型通过函数化的应用接口来定义模型,在定义模型时,从输入的多维矩阵开始,之后定义各层及其要素,最后定义输出层。输出层的值域对应钢板缺陷的类型[2]。
3 实验结果与分析
3.1 基于支持向量机的钢板表面缺陷分类算法
3.1.1 钢板缺陷的SVM分类模型的建立
钢板缺陷的SVM分类模型的建立步骤:
(1)对所给数据集进行划分,将其划分成训练样本集和测试样本集;
(2)选择适当的核函数,通过参数寻优来构造支持向量机模型,常用的核函数形式主要包括线性核函数、多项式核函数、径向基型核函数和Sigmoid核函数。
3.1.2 钢板缺陷的SVM分类模型实验结果分析
在支持向量机分类问题中[3],采用Kaggle中提供的缺陷钢板数据集,钢板数据集共有1 941个数据,共分为7类,每个数据包含27个属性。在本题中,将所有数据分为7类,根据LibSVM和SMO解决缺陷钢板的多分类问题。支持向量机有2个重要参数,c-惩罚系数和kernel-径向基函数,默认c的参数为1.0,默认的kernel参数为Rbf。对2个参数进行调参,观察不同核函数和惩罚系数对分类性能的影响。分类结果见表2所列。
当c=0.6,kernal=Poly时,SVM的分类误差最小,errorrate=16.92%。对于不同核函数的分类方法而言,采用Poly核函數的错误率最低,且其明显优于其他三种核函数,所以在缺陷钢板分类问题中,采用Poly核函数c=0.6的惩罚系数时,分类效果最好[4]。
3.2 基于Keras的神经网络
3.2.1 基于Keras的神经网络钢板表面缺陷分类算法
基于Keras的神经网络钢板表面缺陷分类算法步骤如下:
(1)选取适当的基准网络,然后使用faulty-steel-plates数据集对该网络进行预训练;
(2)对所给数据集进行划分,建立用于训练的专用缺陷检测数据集;
(3)基于步骤(1),搭建整体检测网络,并设置该网络对应的超参数,包括卷积神经网络[5]的层数、卷积核大小、卷积滑动步长、池化方式和激活函数类型;
(4)搭建多级特征融合网络,并将其与整体检测网络合并,得到缺陷检测网络;
(5)构建缺陷检测网络的损失函数;
(6)设置缺陷检测网络的训练超参数,包括优化方法、学习率、迭代次数、权重初始化策略、权重衰减参数、动量系数和数据增强方法;
(7)对训练集进行训练,使基准网络、多级特征融合网络和RPN共享卷积层和计算量[6];
(8)使用训练完成的缺陷检测网络执行钢板表面缺陷检测任务,得出缺陷类别。
神经网络简化图如图2所示。
神经网络[7]由多个卷积层和多个全连接层组成。首先由3个卷积层把来自输入层的数据逐步进行特征抽象,再进入2个全连接层进行特征关系和权重值计算,最后将结果输出到输出层。在卷积层中,使用tanh作为每层的激活函数,高斯核设置为3,初始输入维度为27。在全连接层中,使用dense类来定义完全连接的层,将层中的神经元数量指定为第一个参数,并使用tanh和Sigmoid分别作为这两层的激活函数,第一个全连接隐藏层有200个神经元,第二个全连接隐藏层有7个神经元,对应缺陷钢板的7种类别。导入Keras的相关模块,基于Keras构造上述模型,模型完整结构见表3所列。
3.2.2 基于Keras的神经网络钢板表面缺陷分类实验结果分析
实验环境为Windows 10系统,编程语言为Python,神经网络学习框架为Keras框架,将上文提出的faulty-steel-plates数据训练集进行特征提取与训练,Batch Size=32,Epochs=100,经过100步迭代,模型在训练集上所能达到的准确率稳定在92.2%左右,模型在测试集上所能达到的最高准确度为91.5%。基于Keras的神经网络钢板表面缺陷分类实验结果如图3所示。
4 结 语
本文针对缺陷钢板分类问题提出了基于Keras的神经网络算法和支持向量机算法[8]的分类模型,首先采用主成分分析法[9]对这27维缺陷特征向量进行降维处理,将降维后的数据进行分类,分类结果对比训练集和测试集的准确率,表明基于Keras的神经网络算法优于SVM方法,保证了分类模型具有较小的损失,尽可能多地提高模型训练的精确度。因此,Keras神经网络[10]比SVM更适合缺陷钢板分类问题的研究,是一种具有较高使用价值的样本分类方法。
参考文献
[1]杨钟瑾,史忠科.神经网络结构优化方法[J].计算机工程与应用,2004(25):52-54.
[2]赵元庆,吴华.多尺度特征和神经网络相融合的手写体数字识别[J].计算机科学,2013,40(8):316-318.
[3]方向,陈思佳,贾颖.基于概率测度支持向量机的静态手写数字识别方法[J].微电子学与计算机,2015(4):107-110.
[4]李佳,刘振宇.SVM与BP神经网络在石煤提钒行业清洁生产评价中的对比研究[J].中南民族大学学报(自然科学版),2018(4):18-21.
[5]李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].计算机应用,2016,36(9):2508-2515.
[6]刘长征,相文波.基于改进卷积神经网络的肺炎影像判别[J].计算机测量与控制,2017,25(4):185-188.
[7]吕耀坤.基于卷积神经网络的实景交通标志识别[J].物联网技术,2017,7(1):29-30.
[8]郭显娥,武伟,刘春贵.多类SVM分类算法的研究[J].山西大同大学学报(自然科学版),2010,26(3):6-8.
[9]徐宁,刘权,孟坤.基于主成分分析法的空气质量评估及污染扩散研究[J].科学中国人,2017(z2):47.
[10]马湧,王晓鹏,马莎莎.基于Keras深度学习框架下BP神经网络的热轧带钢力学性能预测[J].人工智能技术,2019,43(2):6-10.
