针对交通标志识别的三种模型的对比与融合
2020-05-08陈叶舟
陈叶舟
(西南大学 西塔学院,重庆400715)
交通标志是道路基础设施的重要组成部分,它们为道路使用者提供了一些关键信息,并要求驾驶员及时调整驾驶行为,以确保遵守道路安全规定。若是没有交通标志,可能会发生更多的事故,由于司机没法获知最高安全速度是多少,不了解道路状况,好比急转弯、危险路段等等。近年内,每一年大约有130万人死在道路上。
如果没有这些道路标志,这个数字肯定会更高。固然,自动驾驶车辆也必需遵照交通法规,因而必须掌握辨认和理解交通标志的能力。
交通标志识别是类别频率不平衡的多类别分类问题。这是一个具有高度实用意义的具有挑战性的现实世界计算机视觉问题,几十年来一直是研究课题。关于此主题的许多研究已经发表,但是仍旧有很多的问题待改进的地方,道路标志的设计遵循明确的设计原则,使用不同的颜色,形状,图标和文本来帮助驾驶员识别。这些允许类之间的广泛变化,使具有相同一般含义的标志(例如各种速度限制)拥有共同的一般外观,从而导致交通标志的子集彼此非常相似。照明变化,部分遮挡,旋转和天气情况进一步增加了分类器必须应对的视觉外观变化范围。
1 背景介绍
1.1 交通标志数据集介绍
本创采用德国 GTSRB
该数据集共有43 个种类(例如限速20 公里/小时、禁止进入、颠簸路等等),其中增加了照明变化,部分遮挡等多种情况,每个现实世界的交通标志只会出现一次。

图1 GTSRB 数据集示例[1]
1.2 VGG-16 网络介绍
VGG 是Oxford 的Visual Geometry Group,K. Simonyan 和A. Zisserman 在ILSVRC 2014 提出的高性能卷积神经网络,并发表论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》[2],共有两种结构,分别是VGG16 和VGG19,两者并无本质上的区别,只是网络深度不一样。
1.2.1 VGG 16 的结构
VGG 16 的结构包含了16 个隐藏层(13 个卷积层和3 个全连接层)
1.2.2 VGG 16 的特性
VGGNet 的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5 或7x7)卷积层好
验证了通过不断加深网络结构可以提升性能
VGG 耗费更多计算资源,并且使用了更多的参数,训练花费及其消耗时间

图2 VGG-16 网络结构[2]
1.3 Resnet 网络介绍
随着网络深度的不断增加,模型精度却并没有一直提升,并且这个问题显然不是完全由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差也变高了,这可能是因为更深的网络会因为梯度消失/爆炸问题,从而阻碍网络的收敛。也就是说, 网络的性能随着深度的增加出现了明显的退化。ResNet[3]就是为了解决这种退化问题而诞生的。ResNet主要有五种主要形式:Res18,Res34,Res50,Res101,Res152;每个网络都包括三个主要部分:输入和输出部分,中间卷积部分,网络之间的不同主要在于中间卷积部分的残差块参数和个数存在差异。

图3 Resnet 中的残差块结构[3]

图4 Depthwise convolution 和pointwise convolution[4]
1.4 Mobile_net 网络介绍
Mobile_ne[4]是谷歌提出的一种小巧而高效的CNN 模型,在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency). MobileNet 的基本单元是深度级可分离卷积(depthwise separable convolution),一种可分解卷积操作(factorized convolutions),其可以分解为两个更小的操作:depthwise convolution 和pointwise convolution, 会大大减少计算量和模型参数量。
2 实验过程
2.1 解决数据集分布不均的问题

图5 数据集中每类图片的分布情况
由上图可知,数据集在43 个种类上的分布严重不均衡,有的种类[如:第1 类:speed limit(30km/h)]图片数量超过了2000张,而有的种类[如:第19 类:Dangerous curve to the left]种类却少于500 张。这种分布不均的情况会导致卷积神经网络模型在训练和测试时,因某一种类样本更为充足和丰富而在这一类之中取得更好的测试结果,反之因某些类样本不足,最终导致整体的测试集上的识别正确率不佳。
所以,在利用numpy 库中sum 函数,保证选出的数据种类分布均衡的前提下,选出训练集中的20000 张图片作为最终的训练集,选出验证集中的2000 张作为最终的验证集,此举也同样可以一定程度上减少因计算量过大所耗费的训练时间。
2.2 数据集预处理
2.2.1 图像大小的统一化
原数据集中中图片大小不均等,大小为:15(宽)×15(高)×3(RGB 彩色通道)-250×250×3。为了使图片能够输入上述三种卷积神经网络,故采用reshape 讲数据集中所有的图像变为:224×224×3 的格式。
2.2.2 图像归一化
对输入为RGB 三通道的图片去各个维度的均值,是在利用神经网络解决图片问题时,常见的图片预处理操作。该操作可以使图像数据集的分布剧中,有利于模型对图像进行统一处理。
同时,采用的三个维度的均值为:103.939,116.779,123.68,三者是来自ImageNet 数据集中所有的平均三通道值。
2.3 对网络结构进行的改变
为了更好的进行对于交通标志的识别,对上述的三种网络,按照控制变量法,我们对其结构进行了如下改变。
2.3.1 Flatten 层的使用
在上述的网络结构中,若不进行网络结构的改变,原始输出的数据是多维,无法进行下一步的操作,故添加flatten 层使多维数据变成一维,可以理解成“压平”,完成从卷积层到全连接层的过度。
2.3.2 Dense 层的使用
Dense 层的作用等同于全连接层(Fully Connected Layers),在整个卷积神经网络中起到“分类器”的作用,上述三种网络中只包含了卷积层和池化层,将原始数据映射到隐层特征空间,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
在实验中,我们设置dense 层的尺寸为32。
2.3.3 Dropout 算法的使用[5]
Dropout 将在训练过程中每次更新参数时按一定概率随机断开输入神经元,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征, 所以可以用于防止过拟合。
在实验中,我们设置了dropout 的概率为:0.5。
2.4 训练过程
2.4.1 学习率,优化算法的选择
在实验中,我们选择了SGD(stochastic gradient descent)[7]为优化器,SGD 就是每一次迭代计算mini-batch 的梯度,然后对参数进行更新,是最常见的优化方法了,并利用momentum 项[6](模拟物理里动量的概念)能够在相关方向加速SGD,积累之前的动量来替代真正的梯度,抑制振荡,从而加快收敛。
缺点:实验初始,很难选择合适的Learning Rate[8],需要不断的根据实验结果对Learning Rate 此参数进行调整。
优点:在好的初始化和学习率调度方案的情况下,采用SGD 优化器所得到的结果更可靠。
在实验中,我们首先尝试了多种不同的学习率(learning rate)[8],0.0001,0.00001 和0.001 等。最终发现学习率为0.0001 时最为合适,故设置0.0001 为学习率,momentum[6]为0.9。
2.4.2 Epoch(整个训练集被训练算法遍历的次数)和批尺寸(batch_size)的选择
因为所采用的数据集数据量巨大,所以将数据集一次性的通过神经网络是不现实的,所以在实验中,我们将数据集分批(batch)处理。
因为实验所使用的数据集共有43 个种类,为了覆盖所有种类,我们将每一批的尺寸(batch_size)设置为40,整个训练集会通过神经网络模型100 次。
2.5 tensorboard 的加入防止过拟合
在实验中,我们也加入了tensorboard,将训练过程可视化,同时也可通过对比训练集和验证集的训练过程,来判断模型是否出现过拟合。
例如,下图中训练集和验证集的曲线变化趋势相同,则可判断为没有出现模型过拟合的情况。

图8 验证集训练过程中随epoch 增加的正确率
2.6 训练耗时和训练结果的对比

表1 三种网络识别正确率对比

表2 三种网络损失函数(loss)对比

表3 三种网络训练时长对比
由上面的结果可得知,经过相同训练过程的三种网络,VGG_16 网络表现性能最优,但是从训练时长对比得知,vgg_16网络因为其计算参数巨大的原因,耗费时间多,几乎为“轻量”的Mobile_Net 的两倍。
3 模型融合
3.1 混淆矩阵(Confusion Matrix)[9][10]
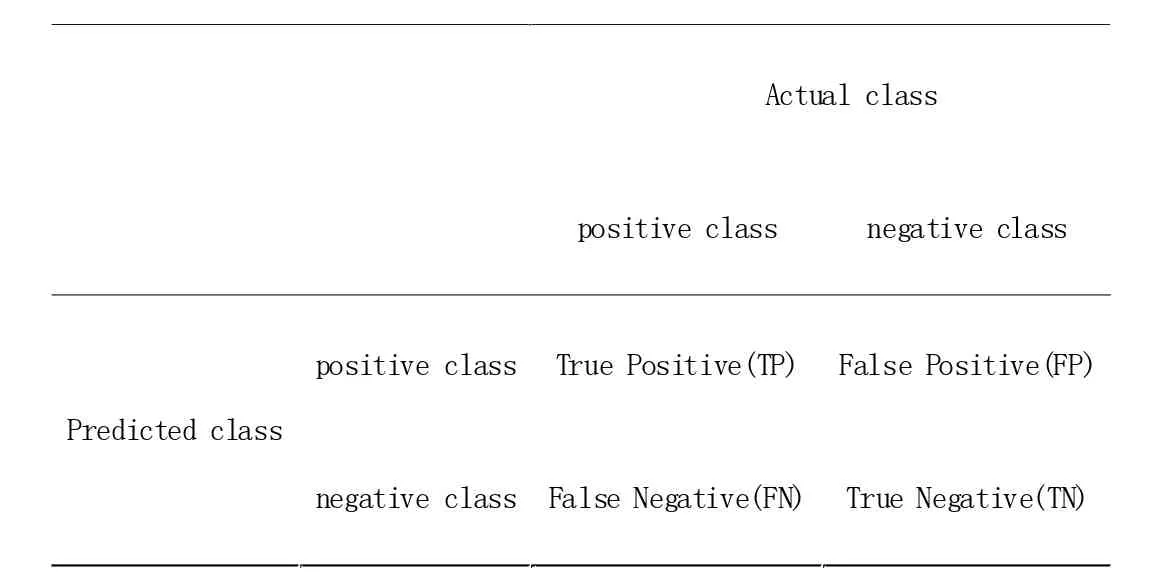
表4 混淆矩阵示意图
混淆矩阵(Confusion Matrix)又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,被广泛的应用在监督学习中[9][10]。而非监督学习,通常使用匹配矩阵(Matching Matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class 被预测成另一个class),例如表4,表5 中所示。
评价指标选择:
准确率(Accuracy)[11]、精确率(Precision)[11]、召回率)Recall[11])、F1 值[11]、ROC 曲线[11]的AUC 值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前四者可以从混淆矩阵中直接计算得到。

表5 TP、FP、FN、TN
准确率(Accuracy)[11]
准确率表示预测正确的样本(TP 和TN)在所有样本(all data)中占的比例

F1 值就是精确率和召回率的调和平均值,其认为精确率和召回率一样重要。

综合上述的评价指标,因为我们要表示的是模型对于特定类的识别情况,所以我们选择精确率(precision)作为指标,预测为该类的,有多少是该类。
例如图5 中的第0 类:
VGG_16 中预测为第0 类的,100%全是第0 类
Mobile_Net 中预测为第0 类的,51.7%是第0 类
Resnet_50 中预测为第0 类的,28.3%是第0 类
3.2 模型融合后结果对比
根据表6,我们可得知三种模型对于43 个种类的不同侧重,暨某模型对于特定的某几个种类,具有超越其余两种模型的测试结果。同时也可以发现,针对某些类别(类41 等),三种模型都没有很好的测试结果。
根据表6 中“最终确定的网络”,我们采取模型融合的方式对测试集再次进行测试,例如:对于第0 类,我们使用VGG_16网络,对于第一类,我们使用Resnet_50 网络,以此类推。最后,将所有类的指标平均后得到最后融合模型的测试结果如表7所示。
4 结论与后续展望
由表8 可知,融合模型在测试集上的准确率超越了其余三种模型,故融合模型这一操作在提升准确率上是有效的。

表6 三种网络对数据集中具体一类的识别精确率(Precision)对比

表7 融合模型在测试集上的结果

表8 融合模型与三种模型准确率(Accuracy)对比

表9 融合模型与其余模型对比
但是从表9 可知,融合模型仍旧与世界上顶尖专家在IJCNN 全球图像识别竞赛上所才用的方法有一定的差距,例如Fatin Zaklouta 采用的随机森林法(Radom Forest)。
同时,模型融合也与人类识别的结果由一定差距,为此,我们希望在以后工作中做如下改进。
(1)再次改变epoch 的次数;
(2)对数据集做数据增强工作;
(3) 尝试新的优化器,如Adam,不仅仅限于SGD 和Momentum。
