一种免注册标识的增强现实方法
2020-05-07陈佳瑜
张 乐, 张 元*, 韩 燮, 陈佳瑜
(1.中北大学大数据学院,太原 030051;2.中国人民银行太原中心支行,太原 030001)
增强现实技术是一种将虚拟世界叠加到现实世界中的技术,通过该技术可以加深用户对于现实世界的认知,便于用户更加形象具体地理解现实世界[1]。增强现实系统主要包括视频获取、图像识别、三维注册、虚实融合等模块[2],其中识别和注册是核心研究内容,如文献[3]中采用人工标识跟踪定位技术。该技术可以通过图像模板匹配或编码特征标识来识别标识信息。图像模板匹配的方法需要将目标图像进行校正,然后再与3种光照和4个方向上标准图像进行逐一匹配,所以该方法的计算量过大,设备要求较高;而另一种编码特征标识的方法是对图像内部进行解码来识别标识。文献[3]中使用海明编码的方式将每一行编码的第3位和第5位设置为有效码,其余3位设置为校验码,通过该方法可以有效提高识别效率,但是最多只能标识1 024种标识。以上两种方式在应用开发中都需要提前置入标识信息和虚拟信息,导致面对新的应用场景需求,只能重新开发,并且标识的注册也需要人工注册,必须在近距离观察目标物体才能准确地识别标记,光线的强弱、标记被遮挡或短暂移出视野等情况都会导致应用无法识别跟踪标识和加载模型[4]。文献[5]中采用自然特征跟踪定位的方式去识别标识,该方法需要从视频图像中提取特征点,然后与提前注册的特征进行匹配,从而载入合适的虚拟物模型,计算量较大,需要不断地提取视频流中的特征点,并且识别效率较低,文献[5]中识别90%的特征点。以上方法所带来的问题都极大地限制了增强现实(augmented reality, AR)应用的实用性,影响用户体验。
针对以上问题,提出一种免注册标识的增强现实方法。该方法采用C/S(客户端-服务端)架构,以HoloLens作为客户端,通过凝视、语音和手势的操作方式进行人机交互[6-7],采集目标信息,使用用户数据报协议(user datagram protocol, UDP)将信息传输给服务端,服务端使用训练好的卷积神经网络(convolutional neural network,CNN)[8]完成识别分类后,HoloLens根据分类结果从服务器动态加载出虚拟信息,并以HoloLens的空间映射功能替代传统AR技术中的标识跟踪功能,从而实现增强现实效果。其中,识别分类功能是采用迁移学习[9]思想,微调AlexNet[10]模型的参数实现。该方法相较于之前的增强现实方法,目标信息识别不再局限于特定的标识信息,同时有较高的识别准确率,用户的活动和操作不再受客观因素的限制,不需要持续近距离地观察目标信息,在加载新的虚拟信息时,只需要将该虚拟信息上传服务器即可,不用对客户端重新开发。
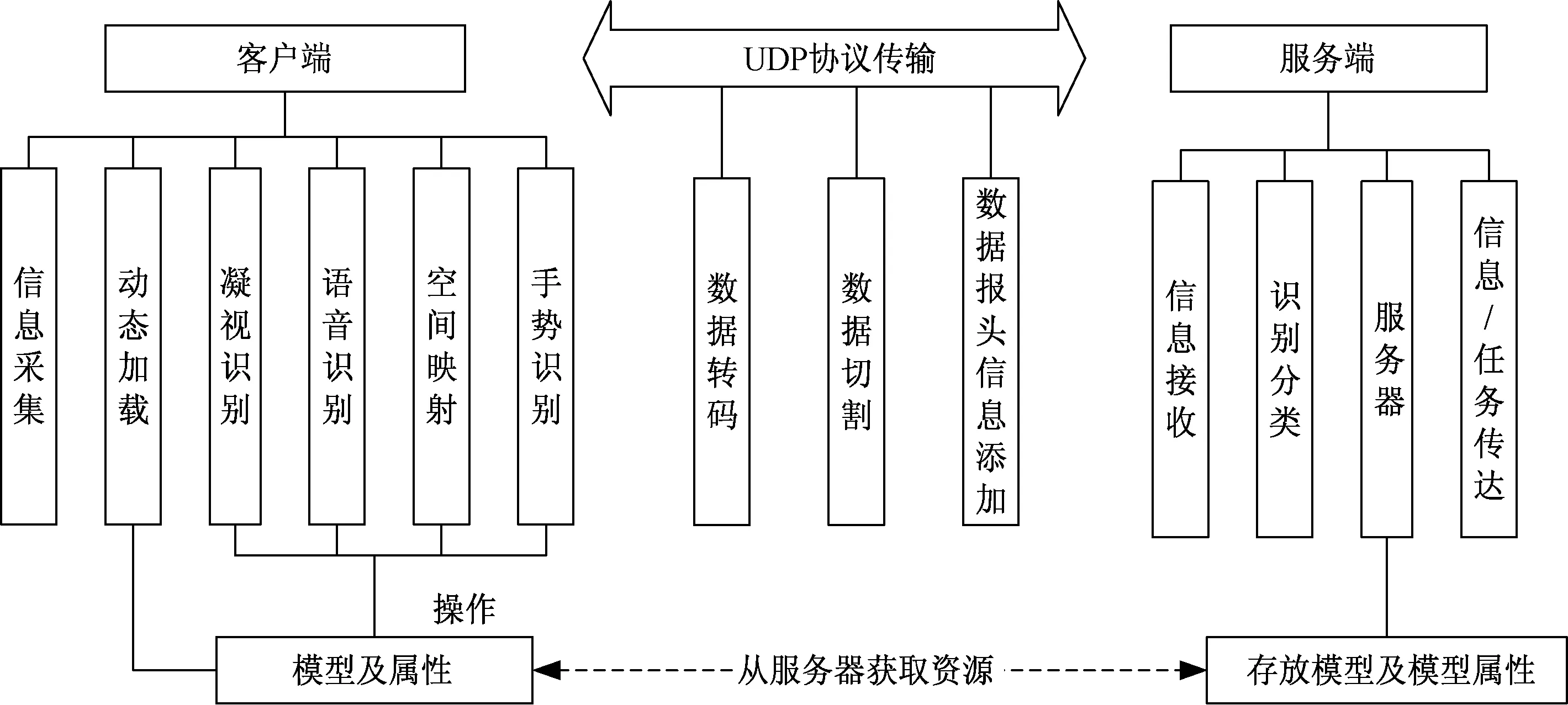
图2 C/S架构设计Fig.2 C/S architecture design
1 系统架构
传统的增强现实识别标识的过程为对图像进行检测、计算标识的位置和方向,从而匹配虚拟物体,具体流程如图1所示。
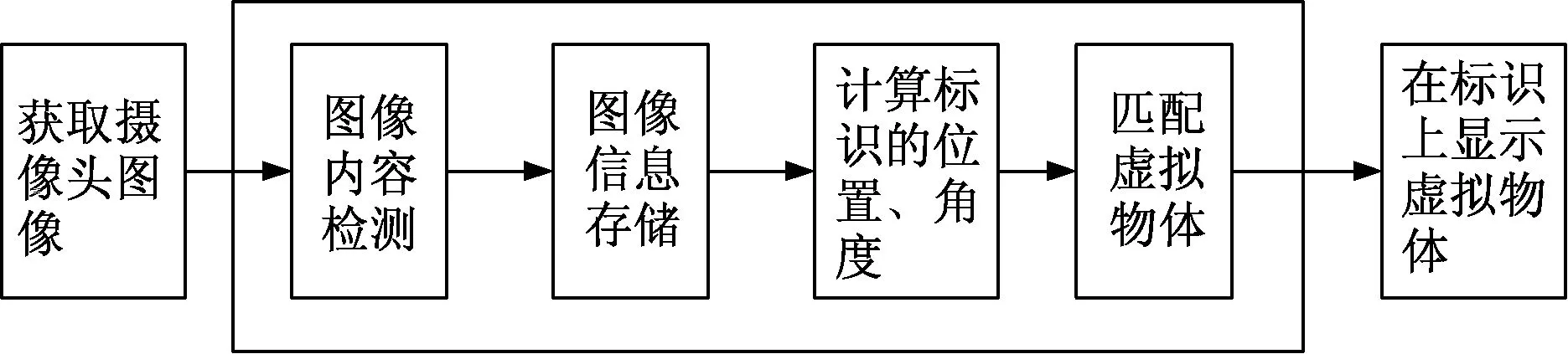
图1 传统AR流程Fig.1 Traditional AR process
采用C/S架构,通过UDP进行信息传输,客户端负责人机交互、信息采集以及虚拟模型的动态加载,服务端提供信息分类的功能,从而实现增强现实的效果。C/S架构设计如图2所示。
以高性能计算机作为服务端负责识别标识信息,不仅可以减少客户端的运算量,还可以使分类更加准确。此外,客户端本身无法携带大量的虚拟模型,而服务端不仅可以存储虚拟模型以供客户端加载,还可以在不更新客户端的情况下,编辑新的虚拟模型和添加操作响应事件来适应新的场景需求。
1.1 客户端(client)开发
HoloLens是一款无需线缆,可以完全独立使用的头戴式增强现实眼镜。HoloLens自身支持凝视识别、手势识别以及语音识别的操作方式,其与传统增强现实设备最大的不同在于,HoloLens所搭载的全息处理单元(holoLens processing unit,HPU)是微软为其量身定制的一款实时处理空间映射的专用芯片,可以将真实环境与虚拟对象相叠加,给用户带来一个感官效果真实的全新环境。
HoloLens通过其配置的惯性测量单元(inertial measurement unit,IMU)、环境摄像头和深度摄像头来实时采集用户周围的环境信息,并结合即时定位和地图重建(simultaneous localization and mapping,SLAM)算法和HPU处理器采集的信息进行实时处理,将虚拟信息合理映射,实现增强现实的效果。
HoloLens应用的开发主要由4部分组成,分别是信息采集、信息传输、人机交互以及模型动态加载。客户端使用Unity3D引擎作为核心开发平台,并使用与Unity3D引擎集成的HoloToolKit软件开发工具包(SDK)。HoloToolKit SDK中集成了负责交互设计的基本类库,其中语音识别、凝视识别和手势识别负责实现用户与系统、用户与全息对象模型之间自然而简洁的交互,空间映射功能则负责虚拟物体与物理世界之间的交互。
1.1.1 信息采集
信息采集是利用HoloLens对目标进行拍照,将拍摄结果以Jpg的格式保存,因为Unity3D引擎并不支持直接访问Jpg格式的图片,而是将其转换为Sprite格式,并加载至UI载体上进行显示。
1.1.2 信息传输
信息传输是通过UDP对图文信息进行传输,UDP具备传输速度快、报头短以及广播和多播的特点,但与此同时UDP可靠性较差。根据其单次可传输的最大字节数将传输的信息进行预处理,在发送端根据文件绝对路径去获取图片,然后对图片进行数据转码、数据切割以及添加报头信息的操作,报头信息中添加文件类型、文件数据长度、数据分组数以及数据编号,接收端根据数据报头信息完成数据解码和重组,并校验是否有空数据,若有丢包,将校验信息回传并申请发送端对丢包信息根据报头数据编号重新发送。报头信息如图3所示。
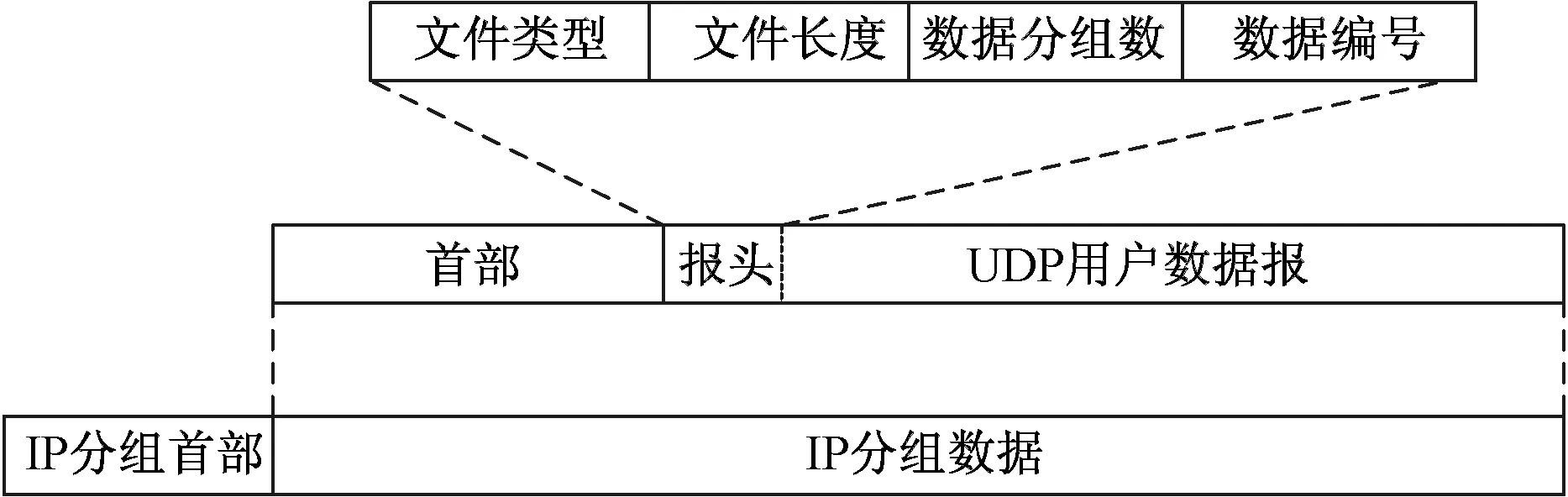
图3 报头信息Fig.3 Header information
1.1.3 人机交互
(1) 凝视识别是基于眼动追踪技术实现的,这种方法是用户和应用程序之间交互的最快方法,也是用户交互输入的第一种形式,用于跟踪和选定全息对象。凝视识别主要是依据用户头部的位置和方向发射Unity3D引擎的物理光线,在与全息对象碰撞后,得到碰撞结果的反馈,包括碰撞点的位置和碰撞对象的信息,从而实现场景中全息对象的跟踪和选定。系统可以通过凝视识别实现虚拟物体的选定和移动。
(2) 手势识别是识别并跟踪用户手的位置和状态的同时捕获输入手势,系统自动触发相应的反馈,从而操纵场景中的虚拟对象。系统识别3种手势:Air-tap(食指在空中点击)、Navigation gesture(食指与拇指相碰掌心向前,手向左或向右平移)和Bloom(手掌心朝上,手虚握拳,张开手掌)。
(3) 语音识别是用户以语音的方法与全息对象交互。语音识别是通过在应用程序中设置关键字和相应的反馈行为而实现的。当用户说出关键字时,响应预设的反馈行为。系统中,语音识别和手势识别的具体操作指令及响应行为如表1所示。
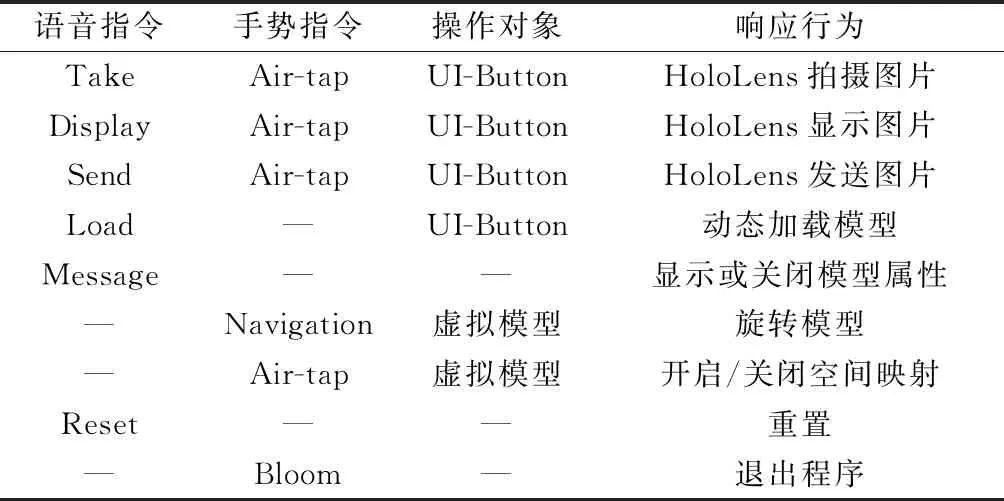
表1 操作指令及响应
(4) 空间映射可以将虚拟世界与现实世界相叠加。其实现包括两个步骤:第1步通过使用HoloLens配备的深度摄像头和环境感知摄像头,扫描用户周围的环境数据和内置三角测量,以实现现实世界的模型化和数字化;第2步实时计算数字物理空间是否可以放置虚拟全息对象。系统通过空间映射与凝视识别配合,实现将虚拟物体移动至用户凝视的现实世界中。借助空间映射,虚拟模型的空间位置不再受标识信息在现实世界中位置的约束。
1.1.4 模型的动态加载
模型的动态加载是HoloLens通过访问服务器加载虚拟模型来实现的。日常生活中物体的种类成千上万,在增强现实应用程序中很难将所有的物体提前置入;而HoloLens与高性能的计算机相比,其渲染能力、内存和性能都十分有限,所以HoloLens也不能携带大量的模型以供加载。针对该问题采用了从服务器上动态加载模型的方法,通过Unity3D引擎,将虚拟模型以及脚本打包为AssetBundle的压缩包,上传至服务器,而HoloLens根据服务端识别后的结果,访问服务器下载对应模型的AssetBundle压缩包并解压,从而实现模型的动态加载。
1.2 服务端(server)开发
服务端主要负责对接收到的信息识别分类以及提供虚拟模型。根据已有的装甲类模型包括坦克、装甲车以及歼击车等识别分类,并使用Apache搭建服务器,将已有的虚拟模型上传至服务器上。
采用深度学习技术中的卷积神经网络完成识别分类的任务。卷积神经网络是多层的有监督的神经网络,通过前向传播和反向传播的方式不断调整连接权值,并且相邻层神经元之间采用部分连接,通过局部感知和权值共享的方式降低网络结构复杂度。但与此同时,卷积神经网络训练需要大量的训练样本、训练时间长以及二次学习困难,所以采用迁移学习对传统网络模型进行迁移学习训练。
2 迁移学习
迁移学习是将源领域学习得到的模型应用到目标领域中去,其数学定义为一个域D由一个特征空间X和特征空间上的概率分布P(X)组成,即D={X,P(X)},其中X=x1,x2,x3,…,xn。而一个任务T由一个标签空间以及一个条件概率分布P(Y|X)组成,其中T={Y,P(Y|X)}。所以迁移学习可以理解为给定一个源域DS(source domain)和源任务TS(source task)以及目标域DT(target domain)和目标任务TT(target task),在DS≠DT或TS≠TD的情况下,具备DS和DT的信息时,学习得到目标域DT中的条件概率分布为P(YT|XT)。
根据源域DS、源任务TS、目标域DT和目标任务TT的相同、相似或不同的情况,迁移学习的基本方法可以分为4种,分别是:
(1)基于样本的迁移学习(instance based transfer learning)是依赖一定的权重生成规则,对数据样本进行重用,提高源域中与目标域相同或相似的样本权重。
(2)基于模型的迁移学习(parameter/model based transfer learning)通过寻找源域与目标域中共享的参数信息,将源域训练好的模型应用到目标域,再使用目标域样本数据对模型中的参数进行微调(Fine-tune)。
(3)基于特征的迁移学习(feature based transfer learning)是将源域和目标域的数据特征变换为统一的特征空间,以特征变换的方式来减少源域和目标域之间的差距,从而进行分类识别任务。
(4)基于关系的迁移学习(relation based transfer learning)需要寻找源域和目标域样本之间的关系,根据挖掘出的不同领域之间关系的相似性,实现迁移学习。
2.1 模型选择
应用背景不仅要求所选的卷积神经网络迁移训练的时间短,还要求该网络可以高效完成多种分类任务。常见的卷积神经网络中AlexNet网络层数较少,可以极大减少迁移学习训练的时间,而且该网络识别精度高,在图像分类方面取得了显著效果,所以,选用AlexNet网络进行迁移学习训练。由于AlexNet网络模型的源领域分类数量较大,因此使用基于模型的迁移学习方法进行训练。
AlexNet网络模型共8层结构,分别是5个卷积层以及与其相对应的池化层和3个全连接层,采用重叠池化的方法提升精度,不容易产生过拟合。同时可以提升特征的丰富度,结合Dropout和Data Augmentation(数据扩充)方法避免过拟合。此外,AlexNet网络中采用ReLU作为激活函数,成功地解决了Sigmoid激活函数在网络较深时产生的梯度弥散问题,并且提出局部响应归一化(local response normalization,LRN),增加了网络模型的泛化能力。
2.2 样本数据集
良好的样本数据集是分类识别研究的基础。通过互联网途径收集了15类坦克及装甲车图像样本,经过整理和标注后,得到共计1 444张图像样本,样本种类及数量分布如图4所示。为了减轻和避免模型训练时出现过拟合现象,减小由于各类样本数据数量分布不均匀所带来的识别效果的影响,将样本图像按数量比例进行旋转90°、旋转180°、水平镜像和竖直镜像操作扩充数据集,如图5所示。经过扩充后,数据集总数量达到9 012张,最终制作为用于坦克装甲识别的数据集。

图4 样本种类及数量分布Fig.4 Sample type and quantity

图5 样本扩充Fig.5 Sample expansion
2.3 模型训练
在扩充后的数据集上进行训练,从不同类别中各随机挑选75%的样本数据为训练数据集,其余25%的样本数据作为测试数据集,迭代次数为100,进行训练。训练参数如表2所示,训练过程如下。
(1)AlexNet网络模型在ImageNet的数据集上进行预训练,通过该步骤将AlexNet网络模型的参数初始化。
(2)由于AlexNet网络模型的最后3层被配置为1 000个分类,所以将最后3层全连接层进行重新训练以适应新的分类,通过该步骤保留新的全连接层的参数,来适应新数据集的分类类别。
(3)将(1)中的前5层卷积层和其相应的池化层、激活函数以及模型参数与(2)中的全连接层及其参数相结合,进行微调从而完成模型的训练。
表2中,Softmax函数对网络最终的输出x1,x2,x3,…,xn进行归一化处理,使得到的值范围都在(0,1)之间,并且和为1,类似于概率分布,若某个类别的概率最大,则将样本归为该类别的可能性也就最高。网络结构如图6所示。

表2 训练参数
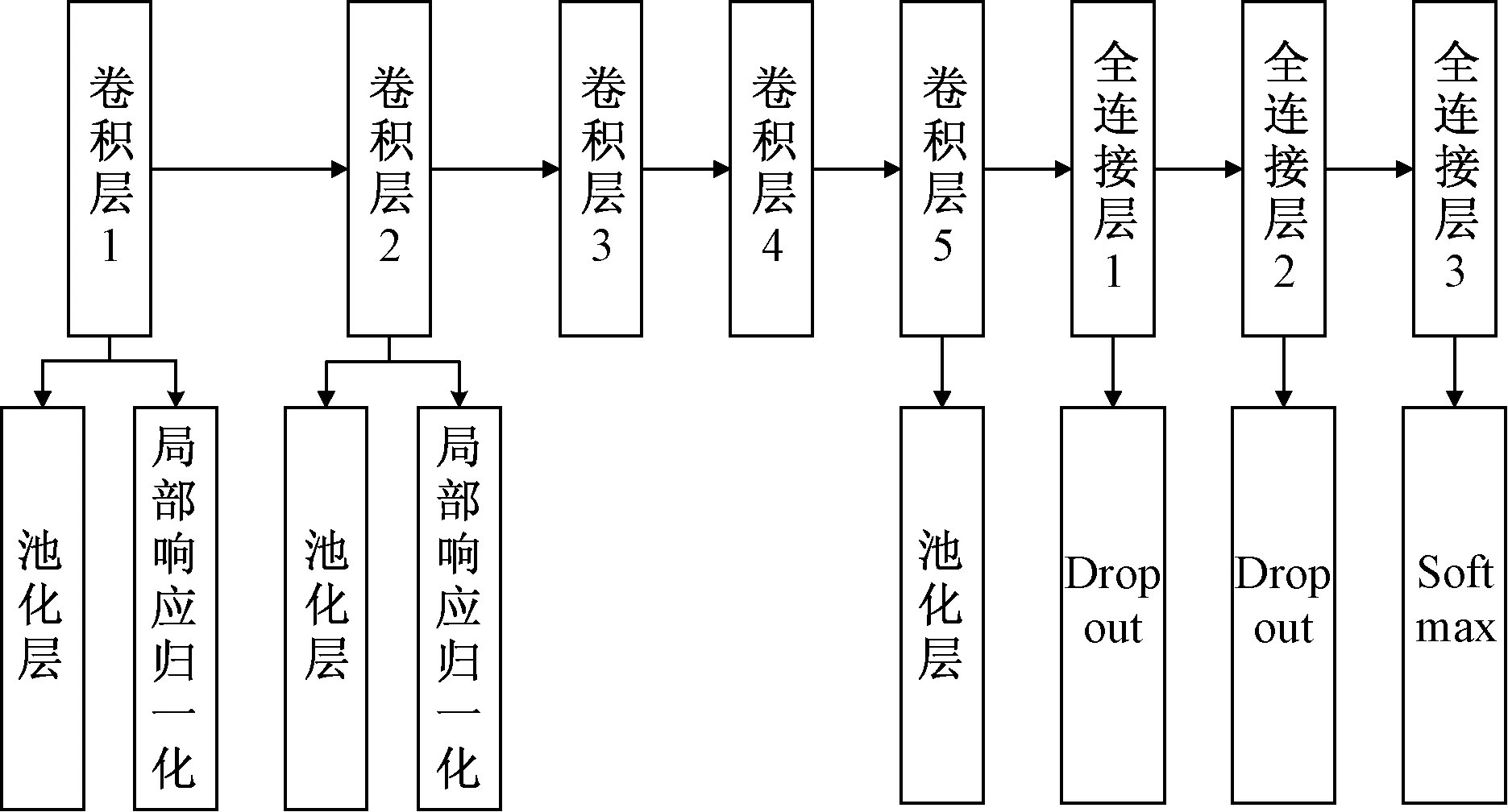
图6 网络结构Fig.6 Network structure
2.4 结果分析
通过损失值、过拟合比率以及测试数据分类的准确率来评判模型训练的效果。其中,测试数据分类的准确率定义为

(1)
式(1)中:ValidationExactQuantity表示测试数据分类结果正确的数量;ValidationTotalQuantity表示测试数据的总数量。测试数据分类的准确率越高,表示网络模型分类的效果越好。
Softmax的交叉熵损失函数为

(2)
过拟合比率定义为

(3)
式(3)中:TrainAcc表示训练数据准确率;ValAcc为式(1)中测试数据准确率,TrainAcc定义为

(4)
式(4)中:TrainExactQuantity为训练数据分类结果正确的数量;TrainTotalQuantity为训练数据的总数量。通常来说,过拟合比率越接近于1,表示网络模型的泛化能力越好。
网络模型通过迁移学习训练,其训练集和测试集的准确率如图7所示,训练集和测试集的损失值如图8所示。
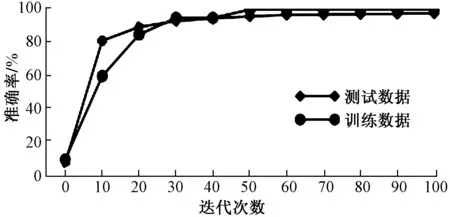
图7 训练集和测试集的准确率变化曲线Fig.7 Accuracy curve of training set and test set
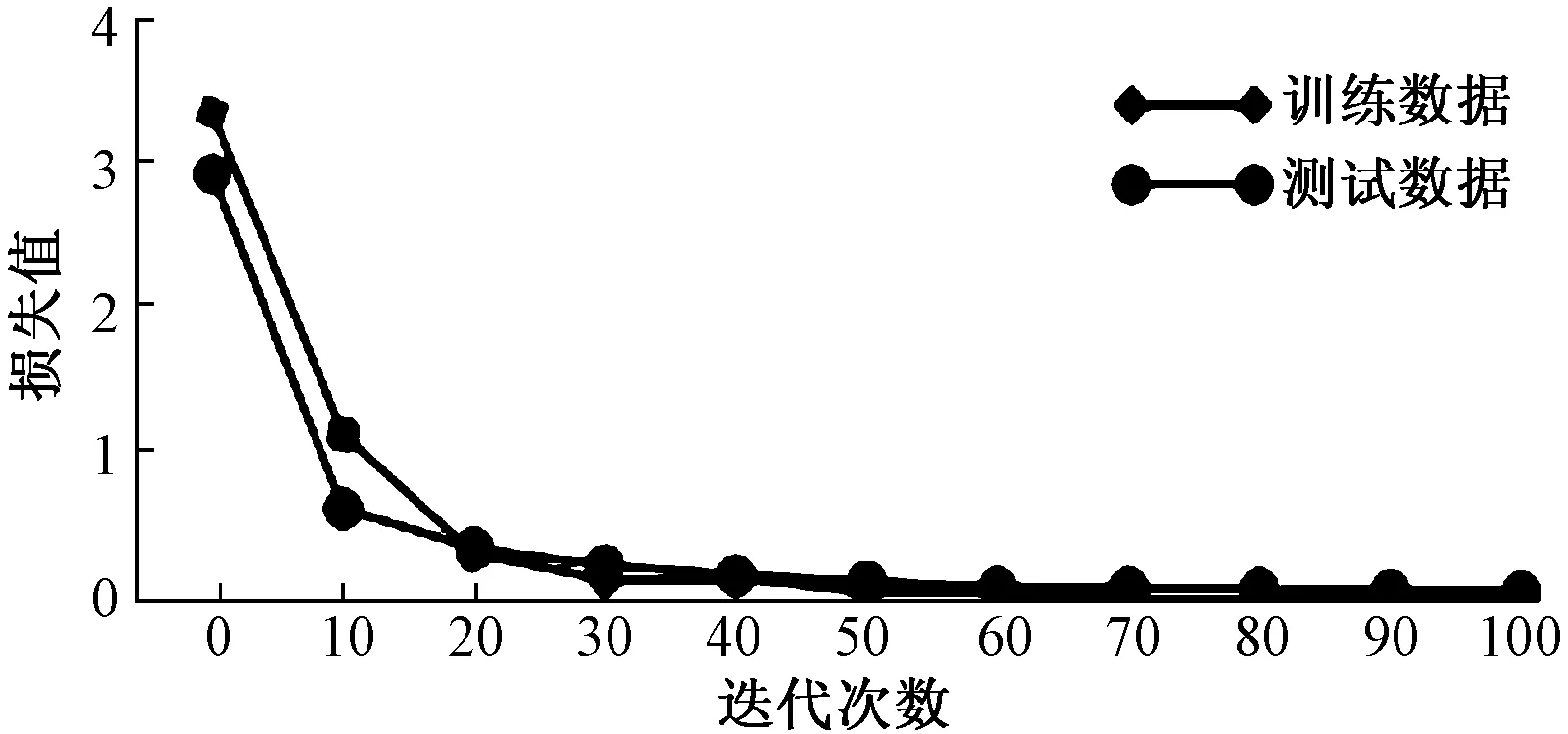
图8 训练集和测试集的损失值变化曲线Fig.8 Loss value curve of training set and test set
由图7可看出,采用迁移学习方法训练的网络模型收敛较快,在27次迭代时,训练数据中模型分类的准确率可以达到90%,经过100次迭代后,训练数据中模型分类的准确率可以提升至100%,随后使用测试集对网络模型的泛化能力进行测试,最终测试的准确率平均值为97.86%,而且模型的过拟合比率基本稳定在1.03左右,表明训练的网络模型具备良好的泛化能力。
3 系统测试与应用
将HoloLens连接Wifi,与服务端根据IP地址以及端口号实现信息传输,开始测试系统功能。HoloLens第一视角运行图如图9所示,用户通过语音或对图9中的Take、Show、Load和Send按钮进行Air-Tap手势操作,实现不同的功能。图9中按钮下方的图片是HoloLens对显示器中的一张ZTZ99式坦克拍照的结果,“发送完成”为发送任务的状态,图中Send按钮上的光圈为光标,以此判断用户视线是否与全息模型发生碰撞。

图9 HoloLens第一视角运行图Fig.9 HoloLens first perspective operation diagram
为了检验训练好的卷积神经网络模型的泛化能力,使用HoloLens对显示器中另一张99式坦克的图片进行拍照,原图如图10(b)所示,而图9中HoloLens拍摄的图片和图10(a)中原图对比,HoloLens所拍图片可以保留原图的所有特征。图11所示为服务端接收到HoloLens端发送的图片并显示,图9中HoloLens拍摄的图片与图11中服务器接收到的图片相对比,采用的传输方法可以有效地解决丢包问题。图12所示为分类结果,由图12可看出,迁移训练的模型不仅可以准确对目标进行分类,且不局限于某一特定的标识图,而本次训练时间仅为80 min左右,训练出的模型可以对15类坦克标识进行识别分类,相较于传统AR开发的标识信息提前注册和只能识别注册的标识,效率更高。

图10 ZTZ99式坦克原图Fig.10 ZTZ99 tank original picture

图11 服务端接收图片Fig.11 The server receives the picture

图12 分类结果Fig.12 Classification result
服务端将图12中的分类结果发送给HoloLens端,HoloLens根据“99式坦克”的关键字,从服务器中获取到该坦克模型,图13所示为HoloLens加载模型的第一视角。HoloLens加载的模型初始位置在用户视线前端2 m处,可以通过凝视识别选定模型,并结合手势与模型进行交互。

图13 HoloLens加载模型Fig.13 HoloLens loading model

图14 HoloLens空间映射图Fig.14 HoloLens space map
图14所示为HoloLens开启空间映射,其中的三角面片为HoloLens的空间映射对周围环境进行扫描,并在现实空间的物体表面生成三角面片,而全息模型可以放在任何一个扫描到的位置上。

图15 HoloLens操作全息模型第一视角图Fig.15 HoloLens operation holographic model first perspective
图15所示为HoloLens操作全息模型的第一视角,通过手势Air-Tap选定全息模型、空间映射扫描地形并结合凝视识别来选定位置,将全息模型放置在地上和桌面上,并使用手势Navigation Gesture控制全息模型顺时针旋转90°。图16所示为传统AR开发效果图。

图16 传统AR效果图Fig.16 Traditional AR renderings
由图16可以看出,传统AR应用中模型的显示必须借助特定的标识信息,而更换标识信息、标识信息受到外界环境干扰或无法一直跟踪标识都会导致AR应用无法加载模型。由图15可以看出,本文方法中全息模型不需要依赖标识而显示,所以不会受到外界环境的影响和目标信息的限制,用户可以在任意角度和位置观察全息模型或与模型交互,而结合空间映射功能,也可以使全息模型更加准确、合理地与现实世界相结合。客户端负责采集信息,而服务端通过训练好的卷积神经网络模型识别分类所采集的信息,客户端根据分类的结果从服务器动态加载模型,所以系统可以在不更新客户端,只需要对服务端的卷积神经网络模型重新训练,客户端便可以从服务器加载新的模型,从而更好地适应各种场景需求。
4 结论
针对传统增强现实对新场景适应性差、对标识依赖高以及开发要求高的问题,提出一种免注册标识的增强现实方法,经测试得到以下结论。
(1)将虚拟物体模型上传服务端并由客户端动态加载,在降低客户端应用所需的内存的同时,还可以在不更新客户端的情况下实现多种模型的加载以及交互。
(2)使用迁移学习训练的卷积神经网络取代人工标识和自然特征识别进行识别,训练时间短,识别分类精度高、速度快,其较高的泛化能力使得识别对象也不再局限于特定标识。
(3)采用空间映射的方法替代标识跟踪,可以摆脱标识的实际位置限制,使虚拟信息可以更加准确、合理地与现实世界相结合。
(4)在人机交互方面,以方便快捷的手势、语音和凝视的方式与模型进行交互,用户操作舒适自然。
