基于改进Mask R-CNN模型的电力场景目标检测方法
2020-05-07孔英会王维维戚银城
孔英会, 王维维, 张 珂, 戚银城
(华北电力大学电子与通信工程学院,保定 071003)
电力施工现场有严格的安全要求,其中设置危险禁入区域和佩戴安全帽是典型的防范措施。在可能引发火灾、爆炸、触电、高空坠落等事故的电力生产区域必须做好相关安全措施,严禁人员随意进出。根据《国家电网公司电力安全工作规程(变电站和发电厂电气部分)》规定:“任何人进入生产现场(办公室、控制室、值班室和检修班组除外)应戴安全帽”。针对佩戴安全帽和危险区域人员入侵情况进行有效监测是电力施工现场安全监管的重要任务。传统监控系统依赖人工监察存在重大隐患,很多历史经验表明,电力建设中安全事故很大程度上是对安全监管不力造成的。随着视频智能监控系统在电力系统的普及,针对未带安全帽和危险区域误入两种情况设计一种智能化的视频分析方法实现对异常情况及时警示,可有效提高电力施工现场的作业安全。
传统视频分析方法多依赖手工设计特征,存在大量错检、漏检情况,泛化能力较差。随着卷积神经网络的迅猛发展,基于深度学习的目标检测模型逐渐取代传统手工算法成为图像检测领域的主流趋势。毕林等[1]构建卷积神经网络(convolutional neural networks,CNNs)实现安全帽佩戴情况检测,但在背景复杂,光照和摄像头拍摄的视频质量较差情况下效果不理想。施辉等[2]基于YOLO V3[3]模型能够实现端到端的安全帽检测和识别,检测速度显著提高,但YOLO V3模型直接对图像进行划分,导致定位信息粗糙。徐守坤等[4]提出了基于改进Faster R-CNN[5]模型的多部件结合检测方法,剔除误检目标使精确度提升,但实验结果目标置信度较低,导致错检问题。实例分割框架Mask R-CNN[6]在Faster R-CNN模型基础上增加掩膜分支,定位信息精确,可以得到高质量的分割结果,同时置信度在90%以上,目标检测精度进一步提高,在目标特征提取方面表达能力更强。
针对电力施工场景下安全帽佩戴情况和危险区域行人禁入的问题,提出基于改进Mask R-CNN模型的目标检测方法。第一阶段通过采集样本建立电力施工场景数据集(person and helmet date,PHDate),结合迁移学习策略调取微软公共对象数据集(common objects in context,COCO)权重训练Mask R-CNN模型;第二阶段针对实际采集的视频数据存在距离远、目标尺寸差异较大情况造成的小目标无法检测问题,调整区域建议网络参数实现多尺度变换操作;第三阶段针对低质量监控视频引入拉普拉斯卷积层[7]做锐化处理,增强图像的边缘对比度,突出目标轮廓,用于改善低质量视频的检测效果。

图1 Mask R-CNN模型网络结构Fig.1 Network structure of Mask R-CNN
1 Mask R-CNN算法
Mask R-CNN是一种对象通用的目标检测算法,可以用于构建实例分割框架做“目标检测”“目标实例分割”“目标关键点检测”等研究,具有优异的目标检测性能,算法整体结构如图1所示。首先,采用残差网络(residual neural networks,ResNet)结合特征金字塔网络[8](feature pyramid networks,FPN)提取输入图像的深层卷积特征图。然后将特征图送入区域建议网络(region proposal networks,RPN)生成建议窗口,获得高质量的候选框,即预先找出图中目标可能出现的位置进行边框修正,把建议窗口映射到卷积特征图上[9]。接着利用RoiAlign区域对齐层将每个感兴趣区域(region of interest,ROI)生成固定尺寸,通过网络头部扩大输出特征图维度,实现输出和输入的感兴趣区域精准对齐,使目标定位信息更为精确。最后,通过全卷积网络[10](fully convolutional network,FCN)输出高质量二值分割掩膜,全连接层(fully connected layers,FC)输出预测框和类别。
Mask R-CNN算法关键技术如下。
1.1 ResNet+FPN检测算法
采用残差网络ResNet作为特征提取网络,结合FPN算法构建多尺度特征金字塔模型,主要解决多尺度融合问题,架构如图2所示。输入图片经过(C1,C2,C3,C4,C5)5层卷积层进行自下而上的特征图提取,再进行1×1的卷积操作改变特征图的维度,通过自上而下的2 倍上采样,与前层网络叠加融合,采用3×3的卷积对每个融合结果进行卷积以消除上采样的混叠效应[11]。融合特征层为(P2,P3,P4,P5),与顶层特征图P6组合输入RPN网络提取候选区域。特征金字塔架构使高层特征得到增强,每一层预测所用的特征图都融合了不同分辨率、不同语义强度的特征。
1.2 区域建议网络
区域建议网络的作用是在FPN输出的多层特征图上提取一定数量的带有目标置信度的建议区域,其原理如图3所示。RPN将卷积特征图矩阵作为输入,输出一系列矩形候选框以及概率值。采用了滑动窗口机制,在特征图(P2,P3,P4,P5,P6)每层上增加滑动窗口,每个滑动窗口对应k个初始建议区域,称为anchor,即为锚点。

图2 ResNet+FPN结构Fig.2 Structure of ResNet+FPN
设n为滑动窗口边长,当n×n大小的滑动窗口在特征金字塔图层上遍历时,滑动的每个位置都在原始图像上对应k个不同的锚点,则一个全连接层输出2×k维向量,对应k个锚点目标的概率值;另一个全连接层输出4×k维向量,表示k个锚点的坐标值[12]。Mask R-CNN算法预设了5 种尺度大小(32,64,128,256,512),设置锚点长宽比为(1∶1,1∶2,2∶1),因此每个位置锚点数为15。

图3 RPN网络Fig.3 Network of RPN
由于锚点anchor经常重叠,导致建议框会在同一个目标上重叠多次。为了解决重复建议的问题,对生成的候选框采用非极大值抑制法[13](non-maximum suppression,NMS)。NMS算法生成按照概率值排序的建议列表,若概率值小于0.3则判断为背景,大于0.7判断为前景,并对已排序的列表进行迭代,然后以目标窗口和原来标记窗口的交叠率IoU作为衡量,筛选出具有更高交叠率得分的建议框。IoU的计算公式为

(1)
式(1)中:DR(detection result)为检测结果即最终生成的目标框;GT(ground truth)为真实值。
1.3 ROIAlign层
为了解决特征不对齐而产生的错位问题,提出ROIAlign层。错位问题对分类任务影响较小,但在预测像素级精度的掩模时会产生非常大的负面影响。ROIAlign层流程为:使用双线性插值在每个ROI块中2 个采样位置上计算输入特征的精确值,避免对ROI的边界作任何量化,最后将结果聚合。每个ROI的输出维度是i×m×m,其中m×m表示mask的大小,i表示i个类别。ROIAlign层不仅会提高检测的精度,同时也会有利于实例分割,实现精确定位。
1.4 损失函数
Mask R-CNN算法采用多任务损失函数,是分类、回归以及掩膜预测的损失之和,可用作衡量模型检测效果的依据,当损失函数Loss达到最低时,模型检测效果最好,计算公式为
L=Lcls+Lbbox+Lmask
(2)
式(2)中:Lcls为分类损失;Lbbox为预测框回归损失;Lmask为掩膜回归损失。
对于每一个感兴趣区域,掩膜分支定义i×m×m维的矩阵表示i个不同的分类对应m×m的区域。每一个像素都是用sigmod激活函数进行求相对熵,从而得到平均相对熵误差Lmask。
损失函数允许网络为每种类别生成掩膜而不用与其他类别之间相竞争,可以将掩膜和类别的预测分开进行。
2 算法
将Mask R-CNN算法应用到电力场景监控视频下目标检测中,直接使用Mask R-CNN模型出现如下问题:①原始模型采用COCO数据集训练,无法满足电力施工场景安全帽佩戴情况和行人入侵检测需求;②远近不同场景中目标尺寸差异较大,存在无法检测远处场景小目标的情况;③低质量监控视频漏检问题严重。重点针对以上问题展开研究,建立适应电力施工场景的改进Mask R-CNN模型目标检测模型。
2.1 迁移学习在小样本上的检测方法
深度学习需要海量数据样本训练,把信息转换成相应的权重。迁移学习策略是将权重提取出来迁移到其他的神经网络中,在预训练模型基础之上,以随机生成的权重为起点,利用该层次的输出作为输入特征来训练参数较少、规模更小的神经网络,这样可以大大减少标注样本工作量,同时可以解决Mask R-CNN模型掩膜覆盖不准确问题。
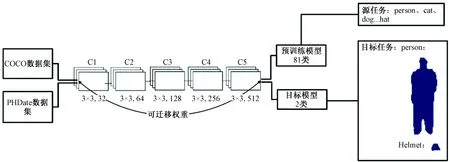
图4 迁移训练过程Fig.4 Process of transfer training
迁移学习要求预训练模型与目标模型的网络结构一致,如图4所示。由于数据集小,数据相似度高(电力数据集PHData中类别Person(人)、Helmet(完全帽)相似于COCO预训练模型中person、hat(帽子)),迁移权重对网络参数进行初始化后,采用微调的方式进行权重训练。微调时进行反向传播算法,对所有层权重进行调整[14],可以使预训练模型更好地拟合目标模型的需求。
2.2 针对小目标检测的多尺度变换策略
在对施工现场安全帽佩戴情况检测时,由于需要检测出安全帽、人员等多个目标,施工现场监测目标尺寸差异较大,远近场景小目标总是存在的[4]。原始Mask R-CNN训练RPN层使用固定锚点,每个滑动窗口产生不同尺度和不同长宽比的候选区域,网络默认设置参数对区域较小的目标无法召回。
采用多尺度变换策略,相同尺度RPN网络在特征金字塔生成的特征图(P2,P3,P4,P5,P6)基础上进行卷积生成带有置信度的目标框,在训练RPN网络时对锚点尺寸大小进行调整,便于网络学习目标各种尺寸的特征,达到多尺度变换效果。低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,目标位置比较粗略。因此将RPN网络默认锚点尺寸(32,64,128,256,512)按照(1∶1,1∶2,1∶0.5,1∶0.25)4组参数做缩放处理,在此基础上设置多组纵横比实验,达到最优模型。
如图5所示,特征图送入RoiAlign层通过池化变为固定大小,使原图像素和特征图像素是完全对齐最终合成掩膜。对于多个锚点互相重叠,采用NMS算法保留拥有最高前景分数的锚点,与掩膜结合生成最终的结果。通过实验证明,使用多尺度变换策略能够让参与训练的目标大小分布更加均衡,最终获得的改进模型更具一定的鲁棒性。
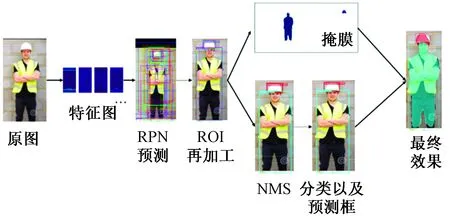
图5 Mask R-CNN检测过程演示Fig.5 Demonstration of Mask R-CNN detection process
2.3 针对低质量视频锐化处理
当采集视频像素过低、场景较远时,图像会过于模糊造成漏检。图像边缘是灰度发生跳变的区域,拉普拉斯锐化处理可提高边缘像素的灰度值差异性,增强图像边缘,使模糊的图像变得清晰,颜色鲜明突出,以便于模型更好地提取目标特征。
应用四邻接拉普拉斯算子确定边缘的位置。拉普拉斯算子是一种常见的二阶导数算子,可以增强图像中灰度值的不连续性,减少灰度区域的逐渐变化[15]。在连续二维的情况下,原始图像像素点的拉普拉斯掩膜重心系数为
(3)
式(3)中:f1=f(x+1,y)+f(x-1,y);f2=f(x,y+1)+f(x,y-1)。
四邻域矩阵的模板[16]如图6所示。
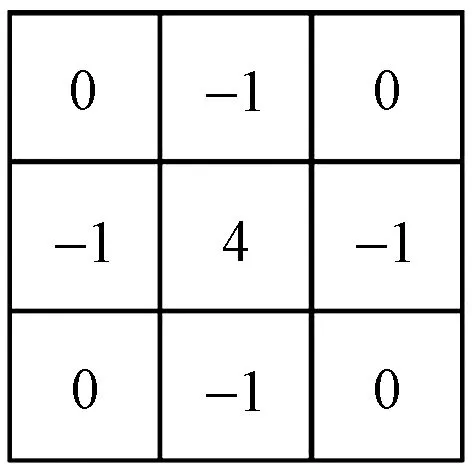
图6 拉普拉斯算子Fig.6 Laplace operator
四邻接矩阵遍历输入图像中的像素点,算出的值替换原处的像素值,以此作为卷积核构建拉普拉斯锐化层处理输入原始图像。当邻域中心像素灰度低于它所在的领域内其他像素的平均灰度时,此中心像素的灰度应被进一步降低,反之则灰度进一步提高。在保留图像原始信息的情况下,拉普拉斯锐化处理增强灰度突变边缘的对比度,应用于监控视频中,可以突出目标轮廓,使模糊的图像变得清晰,更容易检测。
3 模型建立与检测
模型建立工作过程分为预处理阶段、模型训练阶段和检测目标阶段3个部分。其流程如图7所示。

图7 模型训练和测试流程Fig.7 Model training and testing process
3.1 预处理阶段
收集电力施工现场图片,进行分割、旋转90°、镜像、平移等数据增强处理,建立电力施工场景训练数据集和测试数据集。
3.2 模型建立阶段
首先构建完整的特征提取网络,将训练数据集输入ResNet+FPN网络构架。接着利用迁移学习方式在COCO数据集已训练好的预训练模型基础之上进行模型训练,使用随机生成的权重作为训练的起点,解决标注掩膜覆盖不准确问题。最终计算损失函数Loss,将Mask R-CNN模型进行调参后重复训练,直到获得最小损失函数,此时模型检测效果最好。
3.3 检测目标阶段
调取测试数据集送入优化后的模型进行目标检测实验,得到图像中检测目标包含的信息:预测框、目标所属类别以及掩膜。
视频检测在静态图像检测工作上展开,流程如图8所示。获取电力施工现场视频流,将其转换成图像帧,若像素过低对其进行锐化操作。针对危险区域行人入侵目标检测任务,当输入图像帧检测到行人时发出警报提醒行人及时撤离危险区域;针对安全生产区域内安全帽佩戴目标检测任务,当工作人员要进入防护区域进行工作时,若未佩戴安全帽则输出报警信息,通知后台监控人员。

图8 监控视频下检测流程Fig.8 Detection flow under monitoring video
安全帽佩戴检测模型涉及多部件检测问题,比单目标行人检测模型更为复杂,需根据检测结果做后续处理判断安全帽和工作人员位置关系。引入归一化参数η作为判断安全帽与工作人员是否重叠的依据[4],计算公式为
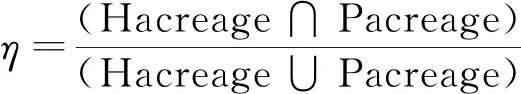
(4)
式(4)中:Hacreage是安全帽预测框区域;Pacreage是检测出的工作人员区域。当参数η不为零则表示佩戴安全帽,可以正常施工;当参数η为零表示安全帽与工人未有重叠,发出提示告知工作人员。
4 实验结果与分析
4.1 数据集建立
由于目前阶段并未公开关于安全帽检测实验的公共数据集资源,而基于卷积神经网络的模型训练依赖大量样本。为弥补训练样本数量的不足,人工采集施工现场图片,加入多段变电站视频,利用多媒体视频处理工具FFmpeg从视频中获取图像帧,分帧操作其主体为select函数作过滤语句,遍历输入视频获取固定时间间隔的图片。
在多媒体处理中,FFmpeg提供多种内置滤镜,可以用复杂命令将这些滤镜组合使用,将解码后的帧从一个滤镜引向另一个滤镜。这样处理减少了解码和编码操作,总体训练图片质量不会降低,防止数据损伤问题。
将样本进行预处理操作,最终PHDate训练数据集扩充为5 000 张,测试数据集为1 000 张,如图9所示。
使用深度学习图像标注工具VIA(VGG image annotator)标注图片分为安全帽Helmet,人员Person两类,如图10所示。采用多边形格式标注目标数据集,相对于矩形框标注得到掩膜效果更好。
4.2 实验结果
4.2.1 模型建立实验
Mask R-CNN原模型使用的COCO数据集约有80 000 张图片,81个类别,而电力场景PHDate数据集包含5 000 张图片,两种类别,相对于COCO数据集,PHDate背景较为简洁单一。在特征提取阶段,考虑到不同网络对实验结果的影响较大,选取ResNet50+FPN和ResNet101+FPN特征提取网络进行实验,网络结构参数如表1所示。

图9 PHDate数据集样本Fig.9 PHDate dataset sample

图10 标注图片数据Fig.10 Label image data

表1 ResNet网络参数配置Table 1 ResNet network parameter configuration
训练模型过程两种网络收敛曲线如图11所示,最终迭代次数为300×103次,曲线平滑度设置为0.6,ResNet50+FPN残差提取网络的最终损失率为7.654%,ResNet101+FPN为6.147%,随着网络层数增多,目标检测计算量越大,ResNet50结构更为轻巧简单,占用GPU内存更少,训练时间更短,所以选用ResNet50+FPN为基准网络结构。

图11 不同网络损失率与迭代次数关系Fig.11 The relationship between different network loss rates and iterations
采用COCO预训练模型加速收敛,在ResNet50+FPN结构中导入预训练模型的权值参数从而初始化网络,使用PHDate数据集进行微调,调参过程中权重衰减系数设为0.000 1,学习率为0.001,学习冲量为0.9。
使用交互式笔记本(jupyter notebook)对模型卷积层提取特征效果进行可视化分析,C1~C4四个阶段以及掩膜Mask生成权重分布如图12所示。初始化权重为小的随机数,每一层输出整体满足均值为0的高斯分布,这样可以将权重衰减到更小的值,在一定程度上减少模型过拟合的问题。
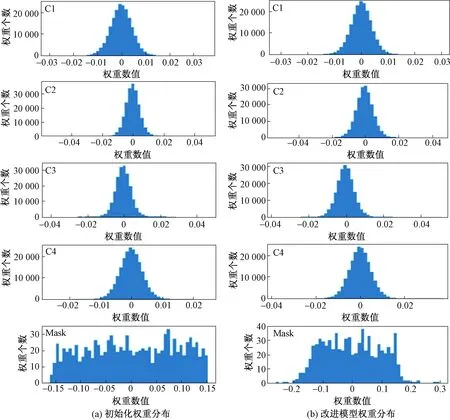
图12 权重可视化结果Fig.12 Weight visualization results
阶段(C1,C2,C3,C4,C5)以及特征金字塔(P2,P3,P4,P5,P6)生成的特征图层如图13所示。在C2阶段提取特征最为清晰,随着网络层数增加,ResNet网络提取特征逐渐流失,对小目标的提取不够精确,信息丢失严重。图13(b)为P2~P6随机生成的特征,加入特征金字塔后,融合C2~C5提取到的特征,生成不同层次的多尺度特征图,将低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息,越到高层区分前景背景能力越强,特征金字塔网络在一定程度上挽回丢失的信息。
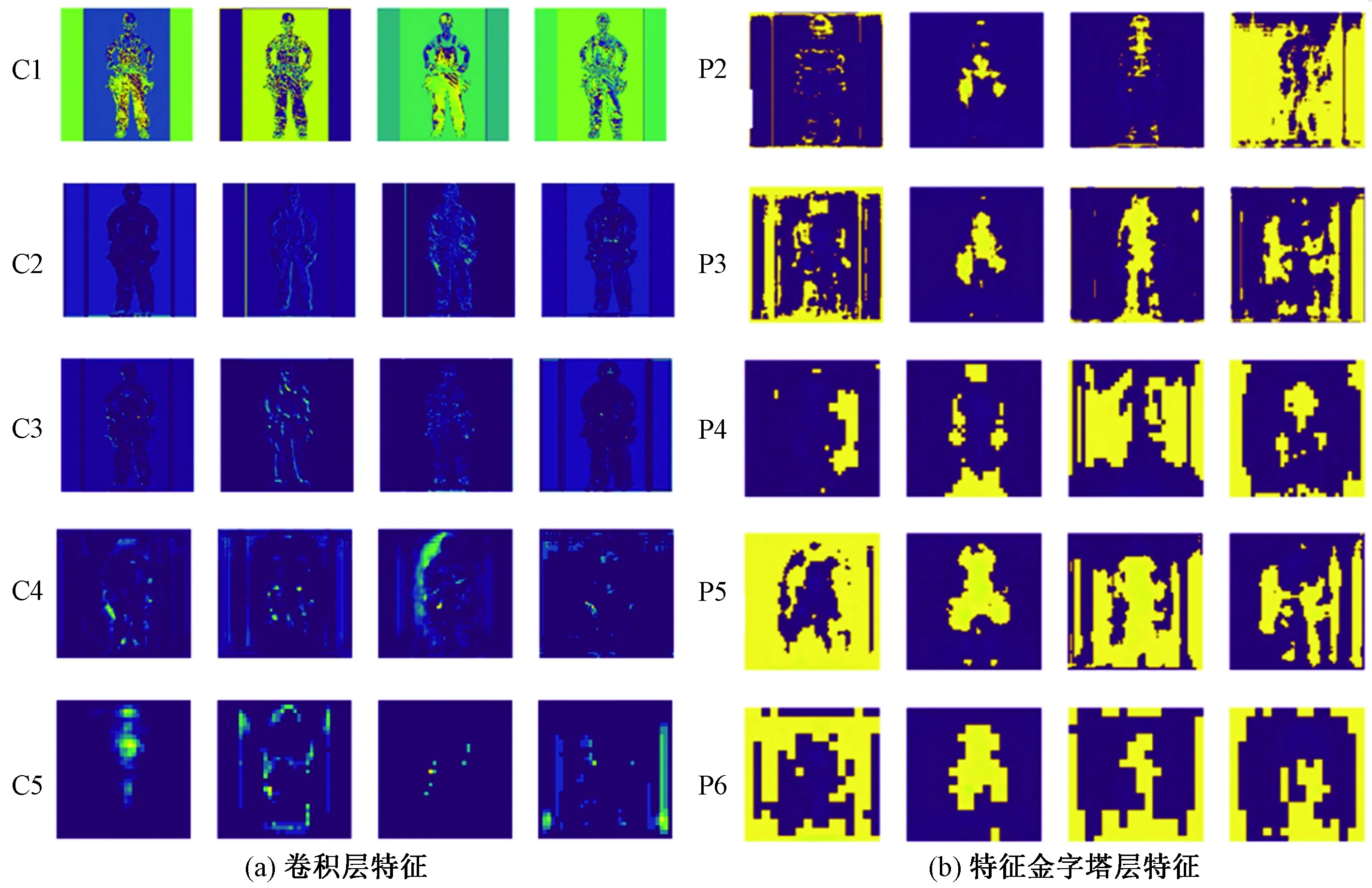
图13 各阶段生成特征图层示例Fig.13 Examples of generating feature layers in each stage
4.2.2 多尺度变换实验
为了评估算法检测目标的有效性,采用多目标平均准确率(mean average precision,mAP)指标来衡量模型的检测性能。RPN网络训练阶段对其尺度及纵横比做调整,完成多尺度变换。参数设定如表2所示。
在相同的环境下对原始Mask R-CNN模型和已经更改锚点尺度后获得的3组模型在测试集上进行目标检测实验(表3),可看出锚点尺寸缩小一半情况下,即尺寸大小为(16,32,64,128,256)检测效果最为理想。
获得最佳尺寸后,调整锚点纵横比,设置4组数据进行实验,结果如表4所示。
将结果与文献[2]、文献[4]实验结果进行对比,结果如表5所示。

表2 RPN网络参数Table 2 RPN network parameter
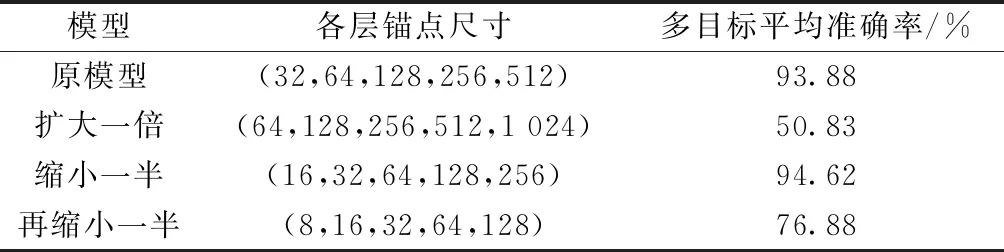
表3 尺度变换实验对比Table 3 Experimental comparison of anchor scale transformation

表4 纵横比实验对比Table 4 Experimental comparison of aspect ratio
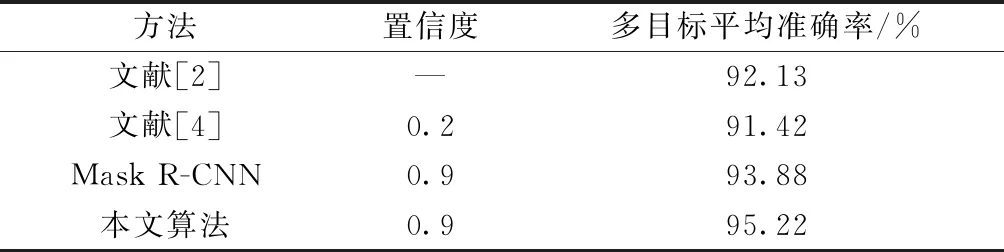
表5 实验结果对比Table 5 Comparison of experimental results
目标区域分类置信度代表模型测量的质量,由实验结果可知,改进算法在保证置信度情况下,多目标平均准确率可以达到最高,检测图片效果如图14所示。

图14 检测图片示例Fig.14 Example of detecting a picture
4.2.3 拉普拉斯锐化处理实验
Mask R-CNN检测算法实现粗糙的框级实例分类到精确像素级分类,测试阶段设置置信度阈值为0.9,即目标置信度大于90%才可输出检测结果。
实验过程中发现由于监控视频质量低、距离过远,导致目标边缘模糊,造成漏检。选取分辨率为203×257像素,目标占比2.48%的低质量监控视频为检测依据,在视频检测前加入拉普拉斯卷积模块进行锐化处理操作,实验效果如图15所示。图15(c)与原始样本相比对比度清晰,锐化效果明显。将图15(c)送入Mask R-CNN模型后得到图15(d),相对于结果显示拉普拉斯锐化处理可提高目标的置信度,使其达到90%以上。为了更好地说明锐化处理的有效性,统计视频检测精准率P,计算公式为
P=TP/(TP+FP)
(5)
式(5)中:TP表示被分类器正确分类的正例数据;FP表示被错误地标记为正例的负例数据。对实验结果进行统计分析,经过锐化处理后精准率为90.9%,提高了9.1%。

图15 锐化模型效果对比Fig.15 Comparison of the effects in sharpening model
5 结语
针对电力施工现场安全帽佩戴问题以及危险区域行人入侵检测问题,提出了一种基于Mask R-CNN模型的目标检测方法。通过迁移学习策略训练数据集获取电力场景检测模型,并采用多尺度变换方法优化系统,解决小目标错检和漏检问题,使多目标平均准确率提升到95.22%。结合拉普拉斯算法做锐化预处理,使模型在低质量监控视频下的精准度提升了9.1%。本文方法部署快捷、操作简单,可以扩展到其他应用场景中。在未来的工作中,将把工作重点放在解决模型压缩的问题上,以适应处理空间受限的嵌入式环境。
