基于深度学习的极化码串行抵消译码优化算法
2020-05-07李桂萍慕建君
李桂萍, 慕建君
(1.西安工业大学计算机科学与工程学院,西安 710021; 2.西安电子科技大学计算机学院,西安 710126)
极化码(polar codes)[1]是理论上能够证明可达信道容量限的一种编码技术。与现有的低密度奇偶校验码(low density parity check code,LDPC)和Turbo码相比,极化码具有规则的编码结构、明确的构造方法以及低复杂的编译码算法。鉴于极化码的这些优秀特性,在即将到来的5G通信中,极化码于2016年成功地被选作5G增强移动宽带(enhance mobile broadband,eMBB)场景中控制信道的编码标准。极化码的基本译码算法主要有串行抵消(successive cancellation, SC)译码算法和置信度传播(belief propagation, BP)译码算法。尽管SC算法具有较低的译码复杂度,但其串行逐位译码机制限制了译码的吞吐量、产生较高的译码延迟,并且极化码在中短码长下的性能也无法满足5G通信要求。为了解决上述问题,文献[2]提出了针对SC算法的优化算法——SC列表 (SC list, SCL)译码算法,在列表宽度较大时极化码的性能可以逼近最大似然译码的性能;而在带循环冗余检测(cyclic redundancy check, CRC)的SCL译码算法下,极化码的性能甚至可达某些优化后的LDPC码的性能,这也是将其选作5G eMBB场景中控制信道传输标准的重要原因。然而,这些算法都是基于SC算法的,其串行输出的特性在低时延高吞吐的应用中仍有待进一步改进。而用于极化码的另一经典译码算法BP算法虽能够并行译码,但无法以较少的迭代次数达到理想的纠错性能。
随着神经网络发展的又一高潮的到来,深度学习及其应用得到了前所未有的关注。目前,深度学习在计算机视觉、自然语言处理、自动驾驶等众多领域都有非常出色的表现,其中数据分类是深度学习的一种典型应用,而通信领域中的信道译码可看作是一种分类问题,这就为通信领域设计高速低时延的信道译码器提供了新的研究方向。目前在极化码领域所提出的译码设计方法主要包括针对BP算法的神经网络译码[3-6]和基于SC算法的神经网络学习译码[7]两种。前者又分为两种思路:①用一个全连接神经网络彻底代替传统的BP算法[3-4]。这种思路下的结构化码在码长较短时可逼近最优译码性能,然而码长较大时会遭遇“维度灾难”问题,即训练复杂度随码长指数增加、需要更多的训练集以及对未知码字具有较差的泛化能等。针对该问题,文献[5-6]给出了思路②,即在给定编码函数和信道模型下,并不需要像其他领域那样提供大量标记好的训练数据,而是利用现的有BP译码算法设计了一种能够从有限码字训练学习中推断出未见过码字的学习译码方案。该方案是把BP译码算法的每一轮迭代展开成神经网络的一个隐含层,而因子图上的权值则分别对应网络结构中的每一条连接。仿真结果表明,这种方案可以提高迭代算法的收敛速度,减少迭代次数,获得传统BP算法的译码性能。但是该方案学习过程中涉及到大量的权值,需要分配较多的内存。同时,需要执行很多的乘法操作对其进行更新,导致计算复杂度增加,不利于硬件实施[5-6]。为此,文献[8-11]分别提出了量化、权值共享等思想对思路②进行了改进,文献[7]则提出了用循环神经网络代替全连接网络结构的方法解决上述问题,均获得了较好的效果。
尽管针对BP算法的神经网络译码设计方法取得了很大的进步,但是要获得和原始BP译码算法相当的译码性能,仍需要较高的迭代次数,从而降低了译码速度。为了探究更快的神经网络译码方法,在第②种方法的基础上深入研究了深度学习中全连接神经网络的原理,在Tensorflow框架中使用python语言分析了深度学习下极化码SC译码算法的性能,基于文献[12]提出了优化算法。结果表明,优化后的基于深度学习的极化码SC译码算法不仅能够达到原SC译码算法相当的性能,而且具有更低的译码延迟。
1 极化码理论及其深度学习基本原理
1.1 极化码编码理论
极化码是基于信道极化现象而提出的一种编码技术,通过对N个相同的对称离散无记忆信道(symmetric discrete memoryless channels, B-DMCs)递归地执行logN次的极化变换,从而得到可靠性不同的一组N个子信道。发送端将要发送的K个信息位作为K个最可靠极化子信道(对应下标集合用I表示)的输入,而其余N-K个子信道(对应下标集合用Ic表示)的输入设置为译码器端已知的固定值0。极化码的编码过程可表示为
(1)
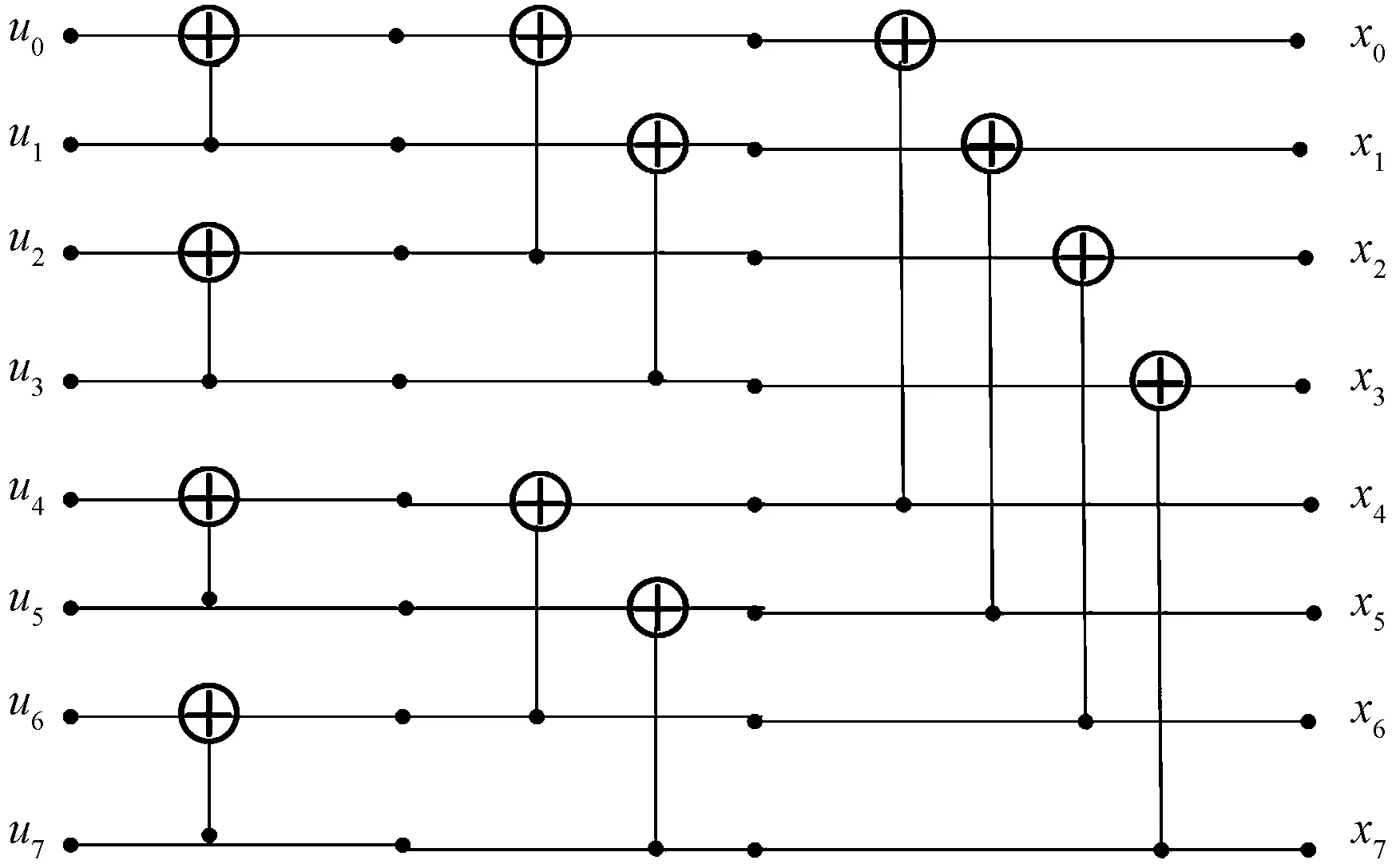
图1 码长为8的极化码编码图Fig.1 Encoding graph of polar codes with block length 8

1.2 串行抵消译码算法的原理

图2 (8,4)极化码SC译码二叉树表示Fig.2 The binary tree of SC decoding for (8,4) polar codes
译码时从最右边二叉树的根节点开始,首先以信道初始似然值作为原始信息,计算传递给左孩子节点的软信息。具体算法[13]如下。
(1)若节点v是非叶子节点。假设节点v处于第dv阶段,则传递给左孩子节点的软信息αvl为
αvl[i]=αv[2i]Δαv[2i+1]
(2)
式(2)中:i=0∶2logN-dv-1-1。
(2)左孩子节点根据αvl计算硬判决值βvl并传给父节点v,节点v计算传递右孩子节点的软信息αvr:
αvr[i]=αv[2i](1-2βvl[i])+αv[2i+1]
(3)
这里i=0∶2logN-dv-1-1,右孩子节点根据αvr计算硬判决值βvr并传给父节点v,节点v利用收到的信息计算本节点的硬判决值:
βv[2i+1]=βvr[i],βv[2i]=βvl[i]⊕βvr[i]
(4)
(3)若节点v是叶子节点。若该节点v对应的是固定位,则βv为0,否则
(5)
1.3 深层神经网络信道译码原理
深层神经网络(deep neural network, DNN)也称为深层前馈神经网络(deep feed-forward neural network),是一种典型的深度学习模型,具有很强的表达能力。该模型可视为一个通用函数f:y=f(x0;θ)的模拟器,其中网络输入x0∈R,输出y∈R,θ表示一组能以较高精度近似模拟函数f的参数。DNN的网络结构可分为输入层、多个隐藏层和输出层,如图3所示,每一层都包含有多个的神经元z。将DNN用于信道译码领域,则输入层(向量x)和输出层(向量y)的大小均为码字的长度。

图3 DNN的网络结构Fig.3 Network structure of DNN
若将具有T个隐藏层{L1,L2,…,LT}且每一层神经元数目为Lt(1≤t≤T)的DNN表示为{L0,L1,L2,…,LT,LT+1}(这里L0和LT+1分别表示输入层和输出层的大小),则DNN的全连接性决定了每一层t(1≤t≤T+1)都关联一个大小为Lt-1×Lt的权重矩阵ωt和1×Lt的偏置向量bt。权重表示神经元与神经元之间的影响程度,而偏置是神经元内部施加于自身的一个特殊权值,用于表示神经元是否更容易被激活。为了最小化损失函数,训练阶段可通过反向传播算法(back propagation, BP)或随机梯度下降(stochastic gradient descent, SGD)迭代地去调整这两类参数值,直到网络收敛稳定。DNN中每一层利用前一层的输出结果作为本层的输入,计算本层的输出结果,第t层的输出用向量Ot可表示为
Ot=ft(Ot-1)=φt(Ot-1ωt+bt)
(6)
式(6)中:输入层是信道初始似然值表示为O0={α0,α1,…,αN-1};φt是非线性激活函数,若φt设置如下:
(7)
(8)
上述训练过程用到的损失函数Λ可选择均方差(mean-squared-error, MSE)或二元交叉熵(binary-cross-entropy, BCE)函数:
(9)
或

(10)
2 极化码深度学习译码算法
2.1 极化码深度学习分段SC译码算法设计
基于NN的极化码SC译码算法基本策略[12]是将SC的译码树分为顶部和底部两块,处于顶部区域的节点仍采用SC算法进行译码,而底部区域的节点则分为若干部分,每部分均使用NN译码。对于码长为N的极化码,其SC译码过程可用一颗完全二叉树表示,自上而下分为(1+logN)个阶段,如图4所示。若将阶段3和阶段2看作顶部区域、阶段1和阶段0划为底部区域。顶部区域节点的译码过程同原SC译码算法,图4中NN1译码器将A节点提供的软信息αvl作为训练模型的输入,并将模型的输出硬判决值βvl返回给父节点A,A节点利用式(3)计算NN2的输入,其他节点和NN译码器的执行过程类似上述过程逐一执行。

图4 码长为8的极化码基于NN的SC译码树结构Fig.4 Structure of SC decoding tree for (8,4) polar codes based on NN
上述过程主要涉及下述几个关键算法。
2.1.1 训练数据获取算法
随机生成信息位序列,根据固定位下标值在信息序列中插入固定值(一般为0),从二叉树叶子节点向上到根节点,利用SC算法的式(4)逐一计算并保存每个节点的硬判决序列βv;再由根节点向下利用每个节点的硬判决值计算其软信息αv值。通过该算法获得了二叉树上每个节点的一组软信息值和对应的一组硬判决序列。算法设计流程如下。
算法1计算二叉树上非叶子节点的软信息值和硬判决序列
二叉树的深度nBase(=logN+1)
初始化:指示变量m=0,
节点在二叉树的深度d_v=1,
stage_index:NN译码器开始层号
While(d_v≤nBase){ //根据叶子节点的硬判决值向上计算父节点对应的硬判决序列
m=0;
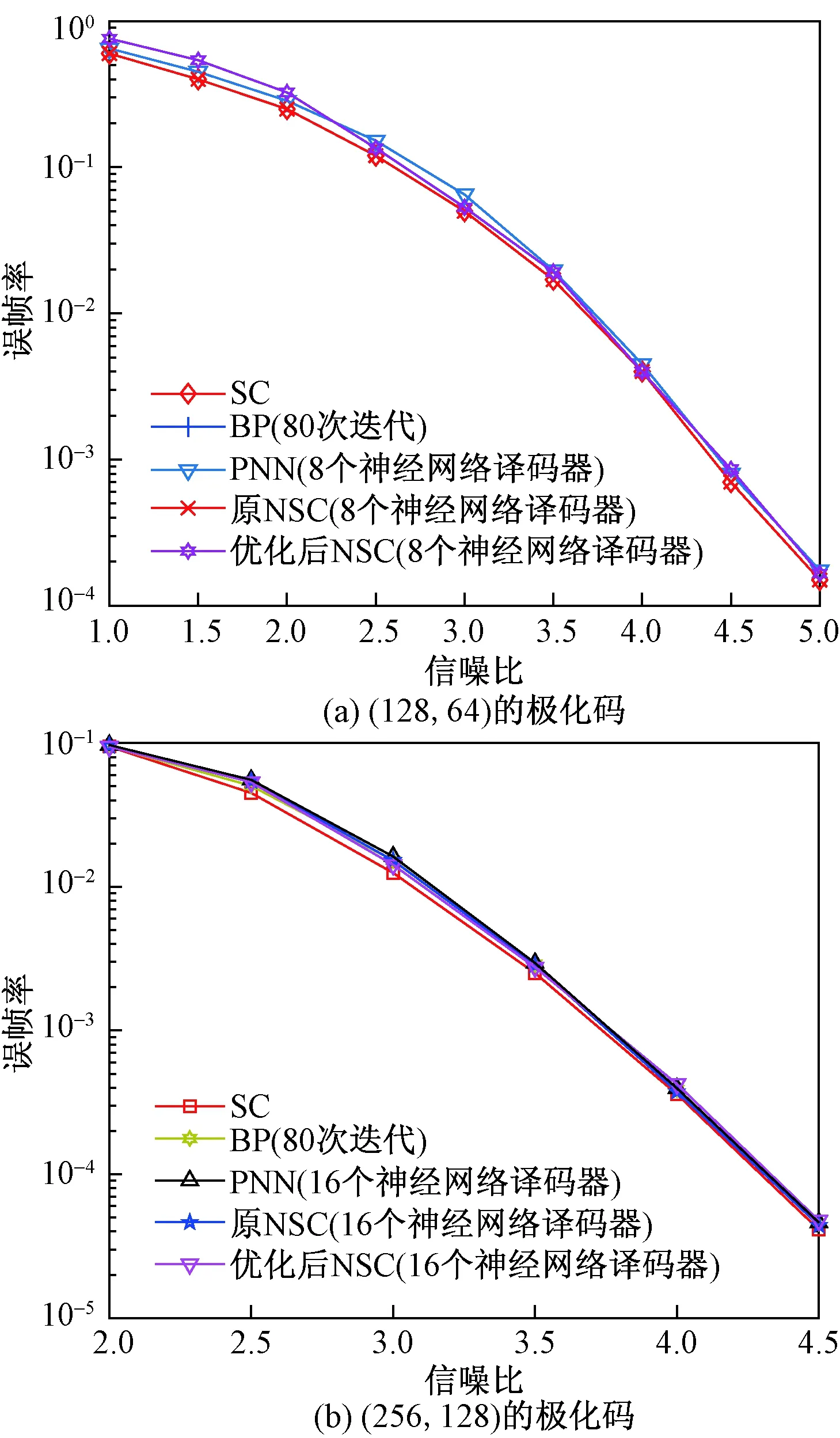
while(m 计算参与计算的子节点下标和相应父节点下标; 利用公式(4)计算父节点奇数下标和偶数下标的硬判决序列; end for m++; end while d_v++; end while d_v= nBase; while(d_v>=stage_index){ //由根节点开始算 深度大于stage_index的各节点软信息序列 m=0 ; while(m for(inti_1=0;i_1 利用公式(2)和式(3)父节点分别计算两个子节点的软信息序列; end for m++; end while d_v--; end while 利用上述算法得到底部区域每个NN译码器的输入软信息序列值和输出的硬判决序列,保存成文本文件,为深度学习这一过程提供训练和验证数据。 2.1.2 深度学习DNN 利用上述算法得到两组多样本训练数据,其中软信息值作为网络输入,输入层节点数取决于二叉树上从哪个阶段开始划入底部区域,即若该阶段为j,则输入层节点数为2j。隐含层数为n(1≤n),隐含层的节点数根据实际码长结合不同的仿真结果并兼顾复杂度设定。隐含层采用relu()激活函数来增强层与层之间的非线性关系,而输出层采用Sigmoid()激活函数将网络输出值归一化到区间(0,1)内,表示相应硬判决值的概率。考虑到函数的凹凸性,仿真过程使用对数损失函数,以避免梯度下降优化时出现局部震荡。具体算法如下。 算法2深度学习DNN算法流程 导入所需要的各种包 读取文本文件转换后的CSV文件到数据集 设置参数:输入出层参数、隐含层参数 def multilayer_perceptron(_X,_weights, _biases): 根据公式(6)利用修正线性激活函数relu()计算隐含层的输出值; 根据公式(7)用激活函数sigmoid()计算输出层值; 将输出层的值作为译码为0或1的概率; pred=multilayer_perceptron(x,weights,biases) cross_entropy= -(y*tf.log(pred)+(1-y)*tf.log(1-pred)) loss=tf.reduce_mean(cross_entropy) train_1=tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss) training_epochs=100 minibatchSize=100 with tf.Session() as sess: 初始化所有变量; saver=tf.train.Saver() for epoch in range(training_epochs): for i in range(np.int32(len(L_result)/minibatchSize)): x1=L_result[i*minibatchSize:(i+1)*minibatchSize] y1=b_result[i*minibatchSize:(i+1)*minibatchSize] _,lossval,errval= sess.run([train_1,loss,pred],feed_dict={x:x1,y:y1}) sumerr=sumerr+lossval ...... 保存模型; 2.1.3 基于深度学习的SC整体译码算法NSC 顶部区域的节点执行SC算法,并为执行NN译码的底部区域的父节点提供软信息序列值αv,加载训练好的深度学习网络模型预测得到相应叶子节点的比特估值αv,再利用SC算法计算该NN译码器向顶部区域父节点提供的硬判决序列βv,上述步骤迭代执行直到二叉树上根节点得到N位的硬判决序列βv。算法如下。 算法3基于深度学习的SC整体译码算法NSC 二叉树的深度nBase(=logN+1) 初始化:指示数组A, 节点在二叉树的深度d_v=nBase, stage_index:NN译码器开始层号 while(a[nBase]≤2){ while(d_v>stage_index) //顶部区域的节点执行原SC算法 if(A[d_v]==0) //根据公式(2)计算当前节点ν传递给左孩子节点的软信息αvl αvl[i]=αv[2i]Δαv[2i+1] ; A[d_v]++; d_v--; else if(A[d_v]==1) //根据公式(3)计算传递给右孩子节点的软信息αvr αvr[i]=αv[2i](1-2βvl[i])+αv[2i+1] (i=0:2logN-dv-1-1); A[d_v]++; d_v--; else if(A[d_v]==2)//根据公式(4)计算传给当前节点父节点的硬判决序列βv βv[2i+1]=βvr[i]βv[2i]=βvl[i]⊕βvr[i] if(d_v==nBase) A[d_v]++; else A[d_v]=0; endif d_v++; end if end while if(d_v=stage_index){//进入二叉树的底部区域. 加载训练模型,根据顶部区域的相应父节点提供的软信息值进行预测; d_v++; end if end while 由于顶部区域的节点进行的操作主要涉及3种:计算左子节点的软信息序列、右子节点软信息序列值和父节点硬判决序列值,因而可设置大小为3的一维指示数组a用于说明当前节点应该执行的操作。上述算法同原SC算法都是逐位译码,考虑到信道极化后传输固定位的信道下标都集中在低位,因此在算法2中可以对二叉树上需要计算的节点进行优化:若下标为0的叶子节点开始至下标为2m-1(m≥0)的连续2m个节点均为固定节点位,则二叉树上对应这些节点的从深度为m处开始的子二叉树是不需加载NN译码模型的。如图5所示,在码长为16的极化码中,序号为0~3的子信道均为固定位信道,因此虚线框起的子二叉树在整体译码过程中可直接剪掉。 图5 码长为16的极化码深度学习下SC译码优化Fig.5 The optimized process of (16,8)polar codes for SC decoding based on deep learning 算法4基于深度学习的SC整体译码优化算法 二叉树的深度nBase(=logN+1) 初始化:指示数组A, 节点在二叉树的深度d_v=nBase, stage_index:NN译码器开始层号 while(A[nBase]≤2) while(d_v>stage_index) //顶部区域的节点执行原SC算法 if (节点为R_0节点?)//根据公式(3)计算传递给右孩子节点的软信息αvr αvr[i]=αv[2i](1-2βvl[i])+αv[2i+1] ;A[d_v]++;d_v--; else if(A[d_v]==0) //根据式(2)计算当前节点ν传递给左孩子节点的软信息αvl αvl[i]=αv[2i]Δαv[2i+1] ; A[d_v]++; d_v--; else if(A[d_v]==1) //根据式(3)计算传递给右孩子节点的软信息αvr αvr[i]=αv[2i](1-2βvl[i])+αv[2i+1]; A[d_v]++; d_v--; else if(A[d_v]==2)//根据式(4)计算传给当前节点父节点的硬判决序列βv βv[2i+1]=βvr[i]βv[2i]=βvl[i]⊕βvr[i]; if(d_v==nBase) A[d_v]++; else A[d_v]=0; endif d_v++; end if end if end while if(d_v=stage_index){//进二叉树底部区域 加载训练模型,根据顶部区域的相应父节点提供的软信息值进行预测; d_v++; end if end while 上述算法中,称二叉树上所有后继叶子节点均为固定节点的为R_0节点。 分别选取(128,64)和(256,128)的极化码。利用算法1,在二元AWGN信道下采集训练数据和验证数据,各包括两组5 000 000条样本:软信息序列和硬判决序列。训练时将80%的样本作为训练数据,20%作为验证集。训练集分成若干组,每组10 000条样本,共训练4 000组,迭代2 000次。 根据仿真结果可知参数stage_index的值对极化码在NSC以及PNN译码下的性能和延迟是有影响的。随着参数stage_index的增大,性能提高延迟降低,但是对码长为128的极化码,当stage_index大于3时,对性能和延迟的影响都微乎其微。因此对(128,64)的极化码进行仿真时设定参数stage_index为4,需要27/24即8个NN译码器;而在(256.128)的极化码中,参数stage_index设定为4,需要16个NN译码器。对这两种码均采用包含3层隐含层的DNN网络,即T=3,网络结构为{Linput,L1,L2,L3,Loutput}={16, 512, 256, 128, 16}。图6分别给出了这两种极化码在不同译码算法下的性能曲线图,说明优化后的算法与优化前的算法、PNN、原SC算法以及BP译码算法性能相当。 图6 不同码长极化码在SC、BP、PNN、NSC、优化后NSC算法下的性能Fig.6 Performance of different block length of polar codes under SC,BP,BNN,NSC and optimized NSC 图7 不同码长极化码在SC、BP、PNN、NSC、优化后NSC算法下的译码延迟Fig.7 Comparsion of different block length polar codes under SC,BP,BNN,NSC and optimized NSC 研究了极化码串行抵消译码算法在深度学习下的译码方法,并给出了详细的实现过程。通过深入分析二元有限域下串行抵消译码算法的二叉树,提出了对深度学习译码器的优化算法,仿真结果表明,所提出的方法不仅具有和原SC译码算法相同的性能,而且减小了基于深度学习的SC译码算法的时间复杂度。
2.2 深度学习分段SC译码算法优化设计

3 仿真结果
3.1 性能比较
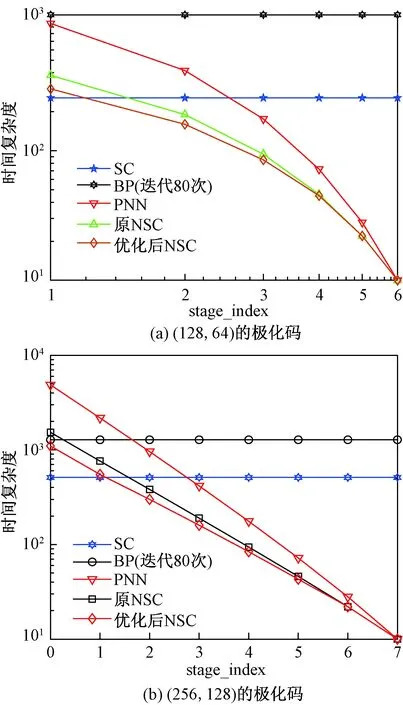
3.2 复杂度比较
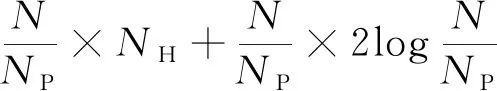
4 结论
