RRDTool在铁路运维监控平台的应用
2020-04-24李井鑫陈文治
李井鑫 陈文治
RRDTool监控数据存储技术结合Open-Falcon开源监控平台,可以实现针对铁路云数据中心下大规模实时监控数据的有效处理,提高运维生产效率。
随着铁路的快速发展,铁路监控运维平台在处理大规模实时数据时所面对的任务也越来越艰巨。本文将以处理大规模实时监控数据为切入点,介绍RRDTool的基础概念与工作原理,简化大规模监控数据的存储、规整数据的格式,直观展示被监测对象随时间的变化趋势。同时结合Open-Falcon这一开源监控平台采集、存储和展示大规模实时数据,从而实现针对铁路云数据中心下大规模实时监控数据的有效处理,提高运维生产效率。
1 RRDTool介绍
RRDTool(Round Robin Database Tool)是一套基于RRD(Round Robin Database)数据库的监测工具。RRD数据库也就是环形数据库,主要用来存储对象随着时间变化的情况,Tool则用来取RRD存储的数据并展示数据,方便我们直观地了解被监测对象随时间变化的情况,比如常见的CPU、内存、磁盘等指标的使用情况。相较于传统的数据库,RRD更适用于高并发、实时变化、规模大的数据存储,结合对应的绘图工具,可以直观地展示数据的变化状况。
1.1 RRD
RRD(Round Robin Database)是一种循环使用以降低数据存储空间的数据库,十分适用于存储和时间序列相关的数据。RRD数据库在被创建的时候就已经定义好了大小,所以和其他线性增长的数据库不同,RRD的大小可控且不用维护。
1.1.1RRD数据库的数据源类型
RRD数据库的数据源类型主要有四种,以下分别作介绍:
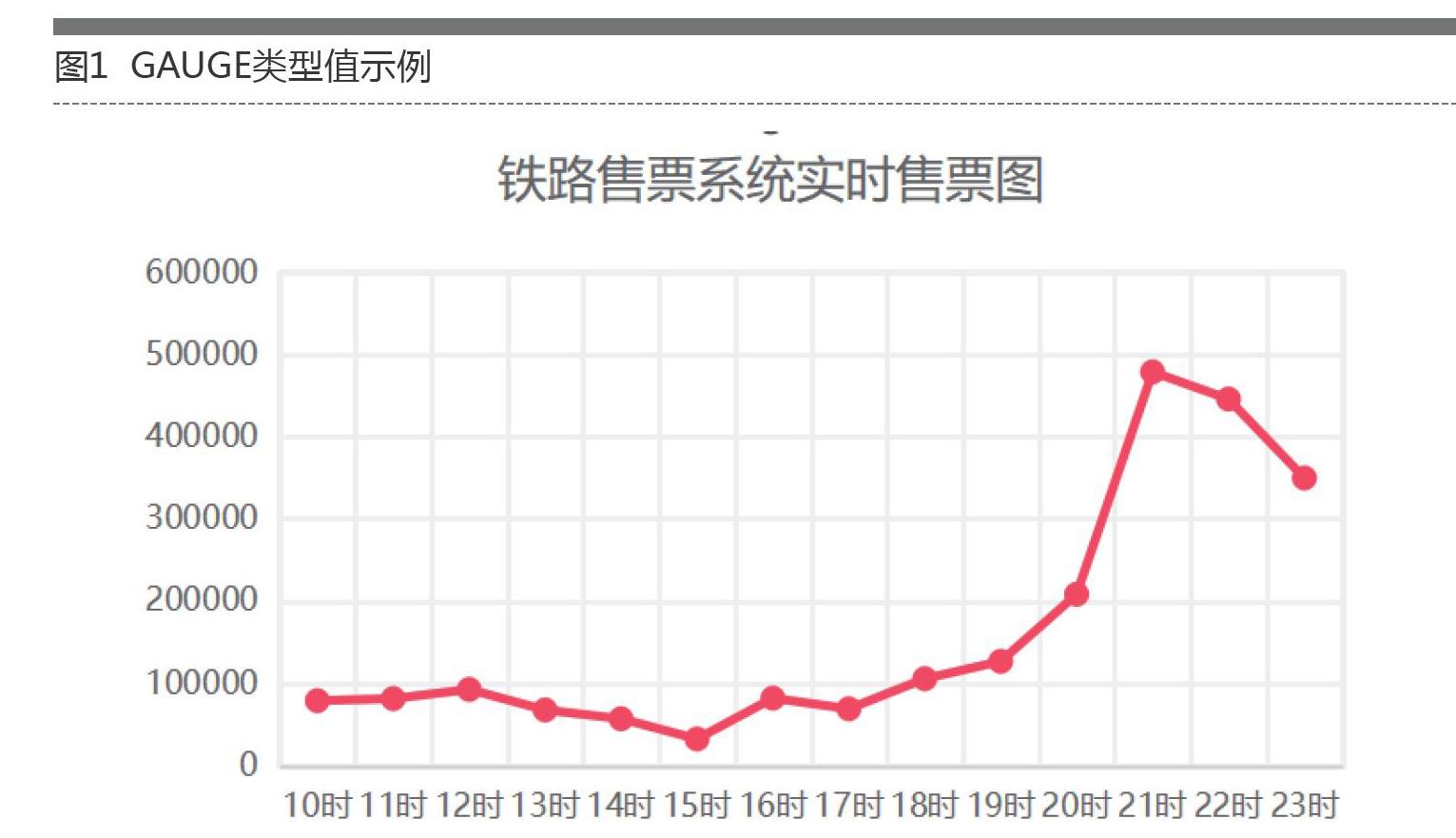
1)GAUGE:实际值,如图1所示,记录铁路售票系统售票量随时间的变化曲线。
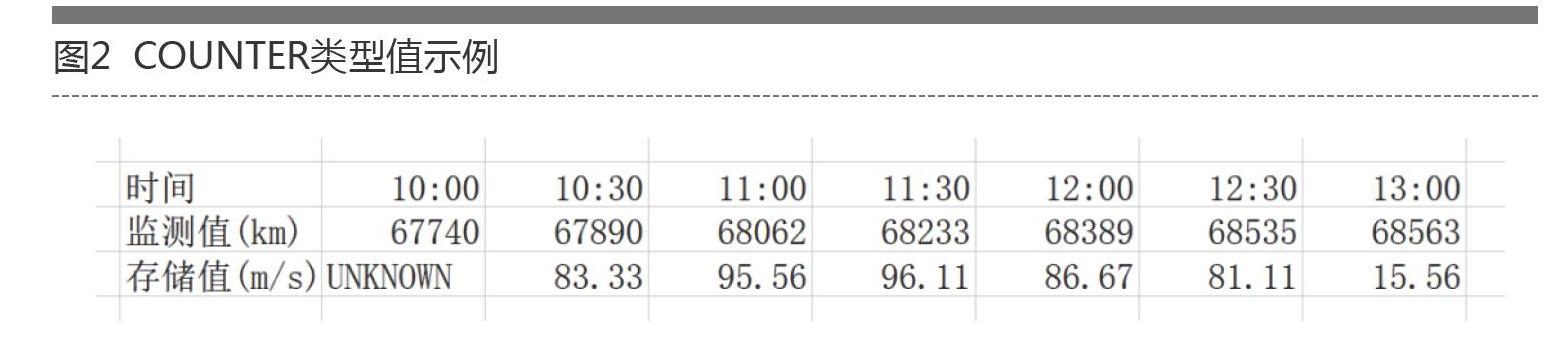
2)COUNTER:计数值,如图2所示。这是一个只增不减的正整数。比如,高铁行驶里程,从高铁开始运营,里程就从0开始不断增长。假设每隔30分钟监测一次高铁的里程,当RRD收到COUNTER类型的数据时,并不会像GAUGE类型那样直接存储,而是计算变化率。计算原理:(67890km-67740km)/(11:30-11:00)=5km/min,也就是说速度为5km/min,83.33m/s。RRD对于COUNTER类型的数据源存储的是变化率,对于上述里程表而言就是行驶速度。(注意:第一个存储值为UNKNOWN,因为没有更早的数据可用于计算,所以此时没有变化可言)。
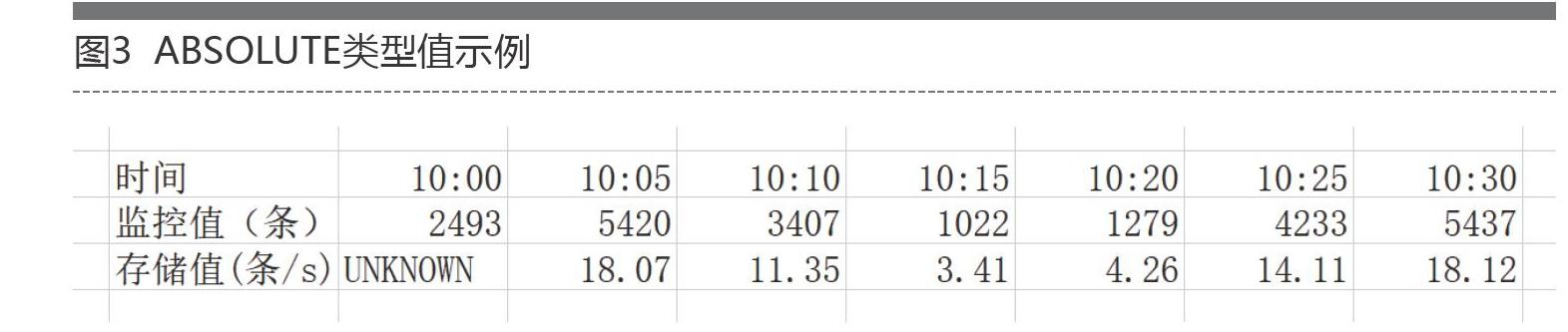
3)ABSOLUTE:ABSOLUTE类型存储的也是变化率,假设铁路运维监控平台每五分钟都会有监控告警信息上报,如果在五分钟内存在告警信息10条,当我们看完这十条告警信息后未读提醒就会变为0,然后下一个五分钟后继续看未读新消息数。所以该数值越大,表示每5分钟内收到的未读消息越多,存在的问题也就越多,具体监测表如图3所示。这样我们就可以通过计算知道一段时间内铁路运维监控平台所收取到的警告条数,从而得知系统的整体运行情况,计算方式如下:100条/300秒=0.33条/秒。
4)DERIVE:DERIVE类型存储的也是变化率,和COUNTER类型不同的是,监测值可以增长也可以下降,其计算原理和COUNTER相同,例如某监控平台在一定时间收到的异常数据条数,如图4所示。
1.2 RRD的数据归档
1.2.1RRD的归档模型
RRD的归档模型RRA(Round Robin Archive)定义了怎样来存储数据而非直接存储原始数据,RRD提供的归档方法有如下4种:
1)计算最大值MAX(d1,d2,d3,...dn)=最大的那个监测值
2)计算最小值MIN(d1,d2,d3,...dn)=最小的那个监测值
3)计算最后值LAST(d1,d2,d3,...dn)=最后的那个监测值
4)计算平均值AVERAGE(d1,d2,d3,...dn)=(d1+d2+d3...dn)/n
四种归档模型适用于不同的场景,比如一定范围内的极大值、极小值监控、最终值监控等,其中最常使用的是平均值,展示数据在一定时间范围内的变化趋势。
1.2.2归档的意义
为什么要对数据进行归档?这得从监测场景的实际需求出发。通常我们会对最近一小时或一天的监测数据最关心,对于一个月或者更久的监测数据并不关心。
假设存在这样一个场景,我们每秒监测一次某台服务器CPU使用率,获取一个监测数据,那么一年后将获得:1×60秒×60分钟×24小时×365天=31536000个监测值。
如果这么多数据点在一张图表上展示,即使一个数据点只占一个像素,那么你也可以想象需要多大的图片才可以对图形进行展示,而且这样做将极大地增加绘图的时间,并且没有实际效益。但是,如果我们将每60秒监测的60个原始数据点计算出一个平均值,比如每60个点算一个平均值,这样数据量就比使用原始值降低了60倍!同理,如果我们把每小时监测的3600个原始数据点计算一个归档平均值的话,数据点就只有24×365=8760个。这就是绘图展示监测情况的时候要使用RRA归档数据的原因。
1.3 RRD的存储
RRD文件一般以.rrd结尾,文件格式大体分为两部分,其中文件头信息区包含一些版本信息和一些与数据存储区相关的信息。数据存储区存储了实际的数据。数据的类型是根据在创建RRD文件时定义的数据源(Data Source)属性和RRA来共同決定。
1.3.1 环形的rrd数据库
对于RRD我们可以把它的存储空间看成一个圆,具体如图5所示,上面有很多刻度和一根指向刻度的指针。这些刻度所在的位置就代表用于存储数据的位置。
所谓指针,我们可以理解为是从圆心指向这些刻度的一条直线,指针会随着数据的读写自动移动,并且这个圆没有起点和终点的概念,也就是说指针随时间变化可以一直移动,在一段时间后,当所有的空间都存满了数据时,指针就又从它第一个存放数据的位置开始存放数据,并覆盖掉之前的数据。这样整个存储空间的大小就是一个固定的数值。
2 RRDTool与Open-Falcon的结合应用
2.1 Open-Falcon
2.1.1 Open-Falcon简介
Open-Falcon为社区开源的监控平台,由数据采集与告警判断两部分组成。主要负责监控数据的采集、上报、告警判定等,可以实现对服务器、操作系统、中间件、第三方应用等进行监控,结合RRDTool的归档与存储的优异性能,可以高效的对大规模的集群与复杂的应用实现高效的监控。
告警判断部分主要由judge、alarm等组成,其中judge负责判断数据采集组件所采集的数据与用户配置的告警策略是否符合,若符合告警策略则认为该条数据为异常数据,需要告警,便将该数据发送至alarm,由alarm来实现告警,从而帮助运维人员快速的定位问题。
数据采集部分主要由agent、transfer、graph组成,其中agent负责采集监控数据,是所有数据的源头,agent支持单周期内上亿次的数据采集,并且结合RRD可实现单服务器200万指标的上报、归档、存储。agent通过定时采集数据(默认每分钟一次),通过rpc调用将数据发送给transfer做数据规整,并做一致性hash分片,然后将数据发送给graph来存储,并由graph提供数据查询的接口。
2.2 Open-Falcon与RRDTool的结合应用
2.2.1 RRDTool结合Open-Falcon存储数据
Open-Falcon的agent模块将数据采集后通过transfer发送至graph,采集的数据示例如下:
Endpoint:ffeaee73-5f6d-49f0-9b0e-cf9c4e82ba34, Metric:df.bytes.used.percent,
Type:GAUGE,
Tags:dev=/dev/adf1,
Step:60,
Time:1570846812,
Value:20
Hostip:192.168.17.29
Endpoint:虚拟机的uuid或物理机的主机名称。Metric:指标名称。Type:指标类型。Tags:标签,可以为空,对指标进一步的分类。Step:采集周期。Time:当前时间时间戳。Value:指标值。Hostip:目标机ip。其中graph模块主要负责操作rrd数据库数据存储数据,并且每次存入的时候,会自动进行采样、归档。为了不丢失信息,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。接收到transfe发送的数据之后,graph会按rrd数据库解析数据的方式,计算出发送来的数据的UUID和MD5。
假设每条数据为一个item对象,则计算方式如下所示:
item.uuid=(item.endpoint+item.metric+item.tags+item.dstype+item.step)
item.md5=(item.endpoint+item.metric+item.tags)
计算出指标数据的uuid与md5值后,graph会将item进行处理。首先刷入本地缓存,即内存队列中,rrd文件命名规则为:RRDFileName=item.md5+item.dstype+item.step,然后会建立本地索引,此时会尝试先增量建立索引,当索引接收到数据后,通过计算数据的总条数值(checksum)来确定来自目标机(endpoint)的metric是否是第一次采集数据。
如果不是第一次采集数据,则在已经建索引的数据项的缓存(IndexedItemCache)中能够找到,并且如果uuid没变则只更新item;如果uuid变了则重新建立索引(index);如果是第一次数据采集,那么在IndexedItemCache中找不到,则把它添加到unindexeditemCache中,等待被索引。之后graph会定时在未建索引的数据项的缓存(unindexeditemCache)中创建索引,并将它保存到系统对应关联的项目数据库中,如PostgreSQL或Mysql数据库,以PostgreSQL为例,则会在PostgreSQL中新建三张表:
1)endpoint:该表记录了所有上报数据的endpoint,并且为每一个endpoint生成一个id,即endpoint_id。
2)tag_endpoint:拆解item的每一个tag。用tag和endpoint形成一个主键的表,记录每个endpoint包含的tag。每条记录生成一个id,为tagendpoint_id。
3)endpoint_counter:counter是metric+tags组合后的名词
最后将内存队列中的数据存入rrd数据库中。
2.2.2 RRDTool结合Open-Falcon查询数据
为指标数据建立索引的目的是为了更快定位rrd文件,而rrd文件命名是受endpoint、metric、tags、dstype、step決定的,所以当查询请求时,不可能去遍历所有的rrd文件,就会先读取数据表的数据,拼接出rrd文件路径,然后根据索引创建的时间范围进行获取数据。
查询数据时首先会根据endpoint和counter,从索引中获取数据的dsType和step从而生成md5:(endpoint + counter)计算md5,然后从indexedItemCache查找md5对应的item,如果没有找到的话,则从数据库中中进行查找,之后根据endpoint、counter、dsType、step,获取对应的RRD文件名,从而获取到数据。
当用户在查询某个metric在过去一个月或者一年的历史数据时,graph会依据RRD初始化时定义的采样频率,返回采样过后的数据,从而极大地提高数据查询速度。
3 RRDTool与Open-Falcon在铁路监控运维上的应用
Open-Falcon在应对硬件、软件、操作系统等方面提供了多种监控指标和便捷的自定义监控插件与指标的方式,为运维监控提供了很大的灵活性。
除此以外,强大的性能如单机200万的指标采集与周期内上亿次的指标上报,结合RRDTool的归档存储与动态展示能力,便捷地解决了铁路行业在运维监控上的难题。
3.1 基础监控
agent内置许多监控指标,应用到铁路行业,可以实现对基础的如服务器的CPU、Load、内存、磁盘、IO、网络相关、内核参数、ss统计输出、端口、核心服务的进程存活信息、关键业务进程资源消耗、NTP offset、DNS解析等指标进行采集。
以磁盘io写入速率为例,agent定期采集目标机的io写入速率的监控数据并将数据发送至graph写入数据库中,当我们想了解最近一小时的磁盘io写入速率,则可以利用RRDTool绘制最近一小时内磁盘的写入速率情况,此时使用的数据为agent定期上报的监控数据,我们可以清楚地看见具体某个时间点的具体数值,如图6所示。
当我们想了解最近一个月的磁盘io写入速率时,我们并不会在意具体哪一天的哪个时间点的使用情况,而是关注这一个月内的整体变化情况,此时就可以利用RRD的归档数据,绘制最近月内磁盘的写入速率情况,重点了解一个月内的整体变化情况。
利用RRD的归档数据绘制过去一个月内的数据变化图,这种方式不仅不影响我们了解某些指标的变化趋势;而且利用归档数据可以节省大量的数据存储空间,节约系统资源;并且相较于利用一个月内的所有的监控数据绘图,利用归档数据时间更短效率更高。
3.2 自定义监控
agent也可以采集第三方应用的监控数据,比如Mysql、云集群与云服务、RabbitMQ、大数据集群与大数据服务等实现监控数据采集,还可以通过自定义各种插件实现对Linux、Windows、交换机等设备进行监控数据的采集。
以目前应用在铁路行业最广的云集群为例,我们可以通过自定义agent插件,以监测云集群的状态。比如我们想了解最近一小时内云集群的nova.api服务的存活状态时就可以通过自定义插件的形式,并同样将监控数据发送至graph并存入RRD数据库中,假设采集数据的指标名称为service.openstack.nova.api.up,并规定指标的值(value)为1时代表服务运行正常,为0时服务异常。
此时我们便可以通过RRDTool绘制该服务的运行状态图,可以很直观地了解该服务的整体运行状况。
4 结束语
本文对以RRDTool监控数据存储技术为基础的铁路运维监控平台在处理大规模的实时数据方面进行了详细分析,介绍了RRDTool的有关概念与简单使用,以及结合Open-Falcon在铁路监控平台上的具体应用。从RRDTool对数据的归档结构以及存储方式,论证了使用它的必要性。
當然,运维监控平台的优化是无止境的,所需解决的问题也远不止于此,需要不断面对问题、解决问题从而优化系统,才能始终保证系统的高效与优异。
