融合边缘特征的高效光场深度信息估计算法
2020-04-24李学华
罗 灿,李学华
(北京信息科技大学 信息与通信工程学院,北京 100101)
0 引 言
光场成像通过标准全光相机来获取子孔径图像,这些图像代表了同一场景不同视角的视图。子孔径图像能用以进行光场的深度信息估计,获得的深度信息可以进行数字重聚焦、3D重建以及超分辨率等应用[1]。
传统的深度信息估计方法以基于立体匹配[2,3]的方式和基于EPI的斜率计算方式[4-6]为主,但是估计效果欠佳。目前机器学习技术在计算机视觉领域发展迅速,部分学者将其应用在EPI结构的学习理解上来估计深度信息并得到了优良的结果:Johannsen等[7]提出一种学习光场字典的方法,学习视点与差异值的映射关系,具有一定的估计效果;Hebe等[8]提出基于卷积神经网络的方法,学习水平及垂直EPI结构的特征,提升了估计精度;Luo等[9]提出的方法同样基于卷积神经网络,并且进行了基于能量函数的平滑优化处理,提升了估计平滑度。文献算法[7-9]的整体表现相较于传统方法有提升,这些算法都是以传统EPI结构作为网络学习对象,然而传统EPI存在两个问题:包含的像素极线信息少,执行效率低;不包含物体边缘部分信息,差异图边缘处估计精度低。
针对现有方法存在的问题,本文提出融合边缘特征的高效深度信息估计算法:设计IEPI结构改进传统EPI包含像素极线信息少的问题,设计边缘图改进传统EPI中未体现边缘信息的问题;相较于传统CNN,网络设计为深度多流全卷积神经网络(deep multi-stream fully-convolutional neural network,DM-FCNN)对IEPI结构及边缘图进行像素级的特征学习,由于IEPI及边缘图为网络提供了完整的像素极线信息及边缘信息,并且网络具有强学习能力,网络可以通过一次前向传播得到高精度的整体差异图。实验结果表明,本文算法相较于现有算法提高了算法执行效率和估计精度。
1 光场的传统EPI结构
将光场函数记为L(s,t,u,v), 其中 (s,t) 为空间坐标、 (u,v) 为角度坐标,记光场中心视角的坐标为 (u,v)=(0,0)。 传统的EPI结构通过固定一个空间坐标和一个角度坐标得到,记为m或者Lu′,s′(v,t), 从位置关系上看,两者称为水平EPI和垂直EPI。一般地,中心视角作为深度信息的参考视角,因此EPI记为Lv=0,t′(u,s) 或Lu=0,s′(v,t), 其可视化的图形结构如图1所示。

图1 传统EPI结构
EPI结构中极线的斜率可以计算该极线对应像素点的深度,关系式为
(1)
式中:Δu为基线长,f为焦距,Δs为差异值,由于基线长以及焦距由光场相机的参数确定,因此算法需要估计的是EPI中的差异值。
观察传统EPI结构,可以分析其缺点:①以水平EPI结构Lv=0,t′(u,s) 为例,其中只包含了{(s,t′)|s=0,1,2,…,n} 像素点的极线信息,缺少完整的像素极线信息;②由于EPI中像素点以极线形式呈现,完全失去了原物体的边缘轮廓描述,边缘信息完全丢失。
由于传统EPI结构的缺点,导致了以传统EPI结构作为学习对象的基于机器学习的算法执行效率低、边缘部分估计精度差,对此,本文提出融合边缘特征的高效深度信息估计算法。
2 融合边缘特征的高效深度信息估计算法
2.1 IEPI
现有的基于机器学习的算法[7-9]以水平及垂直方向的传统EPI结构作为输入来估计两者相同像素点处 (s′,t′) 的差异值,因此这些算法需要重复执行网络前向传播才能得到整体差异图。假设需要估计的图像分辨率为n×n, 那么这些算法(忽略其后处理)的时间复杂度为O(n2), 可见这些算法的计算效率低下。
造成上述问题的根本原因是传统EPI结构只包含部分像素极线信息,本文设计的IEPI包含了整个图像的像素极线信息。IEPI结构记为
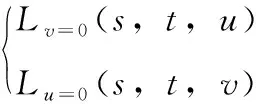
(2)
观察式(2),可以看出,IEPI结构通过只固定一个角度坐标获得,以水平方向的IEPI结构Lv=0(s,t,u) 为例,其可视化的图形结构如图2所示。

图2 IEPI结构
比较传统EPI结构和本文的IEPI结构,可以发现,IEPI结构包含了所有的传统EPI结构,因此式(2)可以写为

(3)
基于IEPI结构的特点,本文算法的网络模型可以通过一次前向传播得到整个中心视角Lu=0,v=0(s,t) 的整体差异图。由此,可以降低算法时间复杂度为O(1), 提高了算法执行效率。
2.2 边缘图
场景中物体的边缘部分存在跳变,体现在深度图中就是不连续变化,无论是传统EPI还是本文的IEPI,由于像素以极线形式表示,边缘部分的跳变未能体现出来,这导致了估计的深度图在边缘部分估计精度低。文献[10]提出了一种针对EPI结构的边缘约束优化,但该约束方法十分复杂,且精度有限。本文算法设计的网络模型基于卷积神经网络,该网络最大优势在于图像理解十分突出,因此本文设计增加IEPI对应的边缘图作为网络输入,边缘图标注了边缘跳变处的像素点,利用卷积神经网络本身的理解能力来理解边缘图标注的边缘信息,提高边缘部分的估计精度,避免复杂的约束优化后处理。
首先,需要将图像的边缘信息检测出来,本文使用Canny边缘检测算法检测边缘,该算法的相较于其它的边缘检测算法有3个优势:①良好的信噪比,将非边缘点错误检测为边缘点的概率低;②定位精确,检测的边缘点位置与实际边缘点中心十分相近;③响应唯一,对于单个边缘只产生单个边缘点的响应,对其它虚假响应进行了非极大值抑制。由Canny算法得出的检测结果如图3所示。

图3 Canny边缘检测算法结果
然后,观察检测出的边缘图,可以发现,其中包含背景中由纹理以及文字带来的边缘,而本文算法只需要处理场景中物体的边缘跳变,所以需要对边缘图做进一步滤波处理,滤除背景中冗余的边缘信息。
对于边缘图的滤波,本文设计基于最大类间方差法的边缘信息滤波,通过对图像中的像素点进行前景与背景的分类,判别属于背景中的冗余边缘信息并将其滤除:假设图像包含N个像素点, {0,1,2,…,L} 表示图像中像素点的灰度等级,ni表示灰度等级为i的像素点个数,则有式(4)所示关系

(4)
按照灰度等级阈值t划分所有像素为目标类C0(灰度等级为 {0,1,…,t}) 和背景类C1(灰度等级为 {t+1,…,L}), 则两类的所占比例w0,w1及灰度均值μ0,μ1分别为
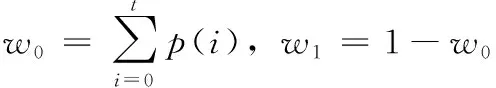
(5)
整个图像的灰度均值为

(6)
由此,定义背景类和目标类的类间方差为
(7)
遍历t并最大化式(7)所表示的类间方差,可以得到最优的目标类和背景类的分类阈值t=T, 大于该阈值的像素点为背景类,由此,定义滤波矩阵Ef为

(8)
其中,i(x,y) 表示原图像中像素点的灰度等级,像素归属于背景则滤波矩阵中对应元素为0,否则为1,得到的滤波矩阵与边缘图对应元素相乘即可滤除背景中的文字和纹理带来的边缘,记原边缘图为B,则滤波后的边缘图为
B′=Ef*B
(9)
图4表示基于最大类间方差法的边缘信息滤波后的结果。

图4 滤波后的边缘信息
最后,使用处理好的边缘图构成EPI结构如图5所示,由图可知,边缘图构成的EPI结构中标注了物体边缘像素点的极线,提供了场景中物体的边缘信息。

图5 边缘图构成的EPI结构
2.3 DM-FCNN
将光场数据处理为IEPI以及对应边缘图后,本文提出DM-FCNN学习二者的像素极线特征得到差异图估计,设计DM-FCNN的意义在于其具有较强的特征学习能力,能够进行像素级的特征学习,保证高精度的差异图估计。
DM-FCNN模型整体结构如图6所示,网络架构以全卷积神经网络[11]为基础,从网络模型上看,不同于经典卷积神经网络在若干卷积层后使用全连接层得到输出,全卷积网络的隐藏层单元只包含卷积层。全卷积网络架构的优点:①结构化输出,本文算法实现端到端的深度信息估计,配合IEPI结构,网络执行一次前向传播就能得到整个中心视角的差异图,因此需要网络可以维持输出的3维结构,而全卷积操作可以实现这个目的;②不限制输入图片尺寸,不同的全光相机其分辨率不一致,若网络只接受固定大小的图片输入,则网络的普适性很差,全卷积网络基于卷积操作稀疏连接的特点,实现了接受任意尺寸输入的目的;③深度网络,卷积层具有参数共享的特点,这允许了网络即使构建比较深,也不会出现参数爆炸的现象,而更深层的网络可以获得更好的泛化性能。
网络的整体结构:网络具有4部分的输入,因此设计网络前部分为4流分别对IEPI及对应边缘图进行低阶特征提取,提取的低阶特征需要作信息综合,因此设计网络后部分为单流,将4部分的低阶特征按通道方向进行级联形成综合信息输入到单流中,综合信息在单流中被语义化最终得到差异图。
网络层级结构设计:根据全卷积网络的设计理念,网络中只包含有卷积层和规范层,本文以“卷积层-规范层-ReLU”为基本模块构建网络(除输出层部分为“卷积层-ReLU-卷积层”),下一小节介绍网络中卷积层具体的参数设计。

图6 DM-FCNN模型结构
2.3.1 卷积层
卷积层基本工作原理为:卷积层包含多个卷积核,卷积核是一个包含权重系数的矩阵,卷积核的大小可以理解为“感受野”,卷积核执行计算时,会规律地扫描输入特征,对感受野内的特征作矩阵元素乘法并求和,计算式为

(10)
式中:Zl,Zl+1分别代表输入和输出特征, (i,j)∈{0,1,…,Ll+1} 代表输出像素的坐标位置,wl+1为卷积核,卷积核的相关参数:卷积核尺寸为f(默认长宽相同),步长为s, 填充层数为p。
假设输入特征尺寸长宽相同为Ll,那么输出特征的长宽为
(11)
若卷积层包含N个卷积核,则输出特征的通道数为N, 即输出特征的尺寸为Ll+1×Ll+1×N。
如图6所示,本文设计所有卷积层的卷积核尺寸为2,步长为1,不带有填充,卷积核的数量多流部分统一为90,单流部分除输出层为1(差异图是单通道图像)以外其余统一为360。参数的设计基于两点考虑:①网络需要学习的是IEPI中像素在不同视角的差异值,而全光相机短基线的特点导致了差异是像素级甚至是亚像素级的,为了实现像素级的特征学习,设计卷积核大小为2,步长为1;②卷积操作中填充会引入与图像数据无关的冗余信息,这会导致填充部分估计的差异值误差大,因此卷积操作中不带有填充。
经典卷积神经网络都会带有池化层,主流的池化为最大池化和均值池化,其表达式为

(12)
分析式(12),池化工作原理是在池化的“感受野”内对特征矩阵进行取最大值或取均值的操作,但这两种操作都会造成特征矩阵的信息缺失,本文算法需要估计出所有像素点的差异值,信息缺失会带来很大的误差,因此本文网络模型中不采用池化层。
对于卷积层的激活函数,本文选择整流线性单元,其表达式为
g(z)=max{0,z}
(13)
式中:z为卷积层的输出,整流线性单元虽然用以产生非线性变换来满足整个网络函数的非线性性质,但是该函数几乎接近线性,从某种意义上说它是分段线性函数,因此使用该函数可以保留网络部分优良的线性性质:①易于进行基于梯度下降的优化;②保留了线性模型的良好泛化性能。
2.3.2 规范层
如图6所示,由于本文算法网络的层数较深,深层的网络会导致过拟合以及梯度爆炸的问题,所以本文采用规范层处理该问题。规范层对隐藏层输出进行标准化,设H为需要规范的输出,将其替换为
(14)
式中:μ为输出的均值,σ为输出的标准差,标准化隐藏层输出可以解除隐藏层之间的强耦合关系,令每层隐藏层输出的分布保持单位高斯,使得网络更易于学习,解决了梯度爆炸问题,也起到了正则化的作用。对于本文基于全卷积神经网络的网络模型,因为卷积操作是对不同的感受野区域进行的,使用规范层标准化不同感受野区域的输出,使得特征映射的统计量在不同感受野区域保持相同可以有效降低泛化误差。
2.4 基于尺度不变误差的代价函数
DM-FCNN需要在数据的驱动下正确地更新参数,以达到将IEPI及边缘图中的像素极线信息正确地语义化为差异图的目的,而损失函数指导了参数更新的方向,因此设计正确的损失函数尤为重要,本文设计基于尺度不变误差的损失函数。
首先定义尺度不变误差
(15)

(16)
将式(16)的尺度系数定义代入式(15),有

(17)
由式(17)的推导结果来看,相较于传统的均方误差,该误差不仅衡量了估计值与真实值之间的距离,还衡量了两者之间的尺度一致性。
对式(17)进行继续推导,定义基于尺度不变误差的损失函数

(18)
在该损失函数的指导下训练网络,即基于尺度不变特性更新网络参数,可以使网络估计的差异图更平滑,误差更小。
3 实验与结果分析
3.1 实验环境与训练过程
本文实验环境所用的GPU为NVIDIA Titan X,操作系统为Ubuntu 16.04,深度学习框架为Tensorflow作为后端的Keras框架。
实验的训练数据和测试数据来自HCI光场数据集[12],该数据集包含有20组不同场景的光场图像,光场图像的空间分辨率为512×512,视角分辨率为9×9,意味着每组光场图像有81张子孔径图像,并且提供了中心视角的真实差异图作为标签,本文按照场景的复杂度划分16组光场场景为训练集、4组场景为测试集。由于训练集的数据量太小,因此需要进行数据增强处理,在不破坏IEPI中像素位置关系的前提下,本文选用的数据增强方式为旋转、翻转、灰度化、调整对比度、缩放、切割,训练时使用小批量梯度下降方式,每个批次的数据进行数据增强的参数都是随机的,最终的训练数据约为原来的500倍。训练前需要对网络进行参数初始化,本文对截断的高斯正态分布进行抽样初始化网络参数。训练时优化器选择的是Rmsprop,该优化器作为自适应学习率下降算法可以根据历史梯度值自适应调整学习速率,在非凸优化问题中有良好的表现,设置初始学习速率为10-5。网络在训练约7天后收敛。
3.2 算法实验结果与分析
由于图像的像素点过多,所以算法的差异值估计结果以差异图的形式表示,差异图中像素点颜色的深浅代表了对应差异值的大小。
本文算法在测试集上的差异图估计如图7所示(图中的场景命名从左至右:Cotton、Dino、Sideboard、Boxes),直接观察算法结果,可以看到本文算法估计差异图的大体轮廓、形状、强弱与真实差异图有部分出入,但没有明显的缺失、噪点和变形,说明了本文算法的有效性。

图7 算法结果
实验在均方误差(MSE)、坏像素率(BadPix)和执行时间3个评价指标上分别评估算法的估计平滑度、估计精度以及算法执行效率,其中MSE以及BadPix的定义如下
(19)
(20)
式中:d(x) 代表估计值,gt(x) 代表真实值。3个指标的值越小说明算法性能越好,下面通过与现有方法的对比实验结果说明本文算法的性能。
本文与文献[7-9]算法进行比较,分别为EPIdictionary[7]、Conv5[8]、Conv8+EF[9],各指标比较结果见表1、2。

表1 算法比较实验结果
表1列举了本文算法与文献算法整体差异图估计的MSE和BadPix,可以看出,本文算法的估计平滑度和估计精度普遍高于文献算法。与文献算法中结果最好的Conv8+EF[9]算法比较,平均所有场景下的MSE值和BadPix值,本文算法的估计平滑度和估计精度分别提升约15.9%和2.1%,其中估计平滑度的提升较大,而估计精度的提升不太大。实验结果说明本文算法的网络在基于尺度不变误差的代价函数的训练下获得了较强的平滑估计性能;而本文算法设计的DM-FCNN相较于Conv8+EF[9]算法的经典卷积神经网络,其特征学习能力略强于后者。
表2列举了本文算法与文献算法执行整个差异图估计(包括后处理)的执行时间,由表可知,本文算法的执行效率远高于文献算法,尤其与文献算法中估计结果最好的Conv8+EF[9]算法比较,本文算法的执行时间下降约98.6%,说明了算法得益于IEPI结构的优点,提升了执行效率。
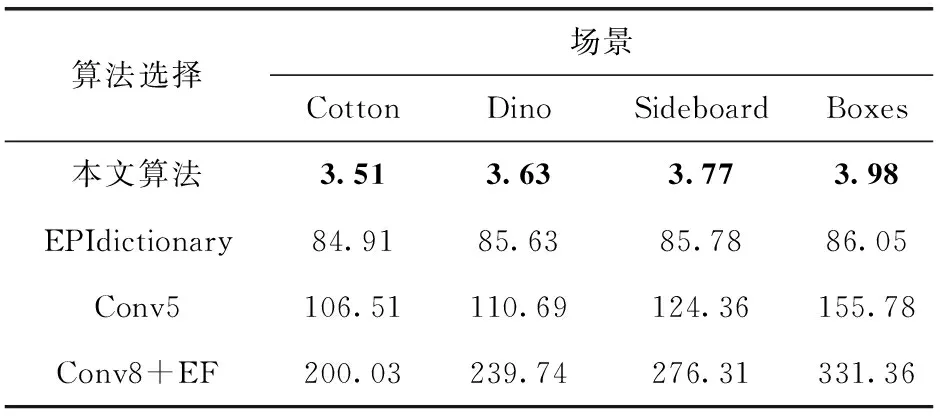
表2 算法执行时间/s
为了说明边缘图优化边缘部分估计精度的有效性,本文设计了不加入边缘图的模型与原模型进行对比实验,比较二者在cotton场景的差异图估计,实验计算二者在每个像素点的BadPix值,结果如图8所示,由图可知,加入了边缘图优化后,边缘部分像素点的估计精度明显提升,说明了边缘图所强调的边缘信息能被网络理解学习,优化边缘估计。同时,实验比较了本文算法和文献算法在边缘部分像素点的估计精度,结果如图9所示,由图可知,本文在边缘部分的估计精度相较于其它算法有较大提升,进一步说明了本文边缘图优化边缘估计精度的性能。

图8 边缘优化前后对比

图9 算法边缘部分估计结果比较
4 结束语
本文对目前基于机器学习的光场深度信息估计方法所存在的问题进行了讨论,针对传统EPI结构缺少完整像素极线信息以及边缘信息的不足,本文提出了融合边缘特征的高效光场深度信息估计方法。该方法设计了包含完整像素极线信息的IEPI结构及对应包含边缘信息的边缘图,并且设计了多流全卷积神经网络对二者进行像素级的特征学习,结合IEPI和边缘图的优点,网络可以高效率地得到高精度的差异图估计。通过实验与现有算法的比较,验证了本文算法的高估计精度和高执行效率的性能。今后的工作中,将面向包含更复杂场景更大规模的数据集进行研究,尝试设计其它的神经网络架构,进一步提高估计的精度和效率。
