一种改进的LSTM模型在图像标题生成中的应用
2020-04-24王志平郑宝友刘仪伟
王志平,郑宝友,刘仪伟
(大连海事大学理学院,辽宁 大连 116000)
0 引 言
自然语言处理[1](NLP)是一个经久不衰的话题,进入21世纪之前,自然语言处理中最为经典的任务是文本分类[2],该任务涉及文本预处理及特征提取等过程,随着计算机技术的飞速发展,自然语言处理技术也变得越来越成熟,尤其是进入21世纪以来,人们在自然语言处理领域取得了一个又一个的重大突破,其中发展最为迅猛的当属图像标题生成和文本情感分析[3]这2个子领域,图像标题生成又可以称为“看图说话”,与文本情感分析相比,该子领域在现实生活中的应用更加广泛,但其涉及的内容也更加复杂,因为它不仅需要利用语言模型,而且需要依靠视觉模型的支持,这一领域的兴起要归功于互联网技术的飞速发展以及数码相机的广泛使用,由于现代人的生活节奏越来越快,而且人们每天都被大量的图像所包围,仅仅靠人工描述图片内容已经远远不能满足人们的需求,因此,人们开始考虑用计算机代替人来完成这项工作,这也激发了许多国内外专家学者[4-5]对图像标题生成这一领域的研究兴趣,从而使得图像标题生成任务成为计算机视觉和自然语言处理领域的研究热点。
1 相关研究
对于一幅图片,人们可以快速地指出并描述图片中的许多细节内容,但同样的工作对计算机来说并不容易,因为它既涉及理解图像的内容,又涉及如何将这种理解转换成自然语言。因此,对于一幅图片,如何快速准确地生成相应的描述是一项极具挑战性的任务,近年来,已经有许多成功的模型被提出来应对图像标题生成这一挑战。例如,Mao等人[6]早在2015年就提出了一种用于图像标题生成任务的多模态递归神经网络(m-RNN)模型,开创了这一研究领域的先河。在2017年,有学者提出了一种新的时变并行循环神经网络用于图像标题生成任务[7],该模型可以在每个时间步长中获得动态的视觉和文本表示,从而解决了现有方法中目前生成的单词与所获得的图像特征不匹配的问题。后来,Dong等人[8]提出了一种名为Word2VisualVec的深度神经网络结构,该网络能够从文本输入中精准地预测视觉特征表示。此外,还有学者将注意力机制[9]应用到图像标题生成任务后,发现注意力模型可以有效地提高图像标题生成任务的准确性。
尽管上述模型各有其优点,并在图像标题生成任务中取得了良好的性能。但是,它们大多只考虑了网络模型外部结构的影响,即只改变描述与图片特征之间的对应关系,而没有考虑网络模型内部结构的变化,此前已有众多学者提出改进神经网络激活函数的策略来增强网络的性能,例如,Godin等人[10]提出了一种双整流线性单元(DReLUs)来替换传统的递归神经网络中的双曲正切激活函数,这在情绪分类和语言建模任务中取得了巨大的成功,受其启发,本文提出一种改进的长短时记忆(ITLSTM)神经网络模型来处理图像标题生成任务,该神经网络模型以反正切函数作为激活函数来更新细胞状态,有效地缓解传统长短时记忆神经网络模型的过早饱和问题,从而更充分地捕捉句子信息。最后在公共的Flickr8K数据集上验证本文方法的有效性。
2 模型引入
2.1 LSTM神经网络模型
在语言模型中,长短时记忆(LSTM)神经网络[11]的作用是先将句子的信息转换为一种可以被添加状态的细胞,然后通过包含sigmoid[12]激活层的输入门将新信息定义为单元状态。传统的LSTM神经网络模型中单元的状态更新过程如下:
(1)
(2)
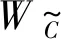
(3)
在完成以上细胞状态更新的基础上,传统LSTM的隐藏状态的更新可以用式(4)表示:
ht=ot·tanh (Ct)
(4)
其中,ot表示输出门向量,·为元素乘运算符。
2.2 改进的LSTM神经网络模型
在上述过程中,尽管以tanh (·)作为神经网络的激活函数解决了sigmoid激活函数的非0中心问题,但该函数仍然存在过早饱和的问题,因此,在建立ITLSTM神经网络模型时,为了克服该激活函数过早饱和的缺点,本文首先构造如下反正切函数:
F(x)=(2/π)·arctan (x·π/2),x∈R
(5)
与传统的LSTM神经网络不同,在本文提出的神经网络模型中,其激活函数使用式(5)来代替式(1)和式(4)中的双曲正切函数,进而将细胞状态从Ct-1更新到Ct,并将隐藏状态从ht-1更新到ht,从而式(1)和式(4)分别变为以下形式:
(6)
ht=ot·(2/π)·arctan [Ct·(π/2)]
(7)
为了使ITLSTM神经网络模型更加直观和更容易理解,图1展示了该神经网络模型的内部结构。

图1 ITLSTM神经网络模型内部结构
除了反正切函数之外,softsign激活函数也是tanh (·)激活函数的一个有效的替代选择,与tanh (·)激活函数相比,softsign激活函数有着更平坦的曲线以及更慢的导数下降速度,这让它可以更加高效地学习,同时也能够更好地解决梯度消失问题,并且同tanh (·)激活函数一样,softsign激活函数也是反对称、去中心以及可微分的,其函数值介于-1和1之间,因此,在实践中,可以用softsign激活函数替代tanh (·)激活函数,但softsign激活函数的一个固有缺陷是其导数的计算比较复杂,从而大大增加了神经网络的计算复杂度,softsign激活函数的表达式如下:
(8)
为了更形象地突出以上3类激活函数的优劣,图2给出了式(3)、式(5)和式(8)所表示的激活函数及其各自的导数图像。
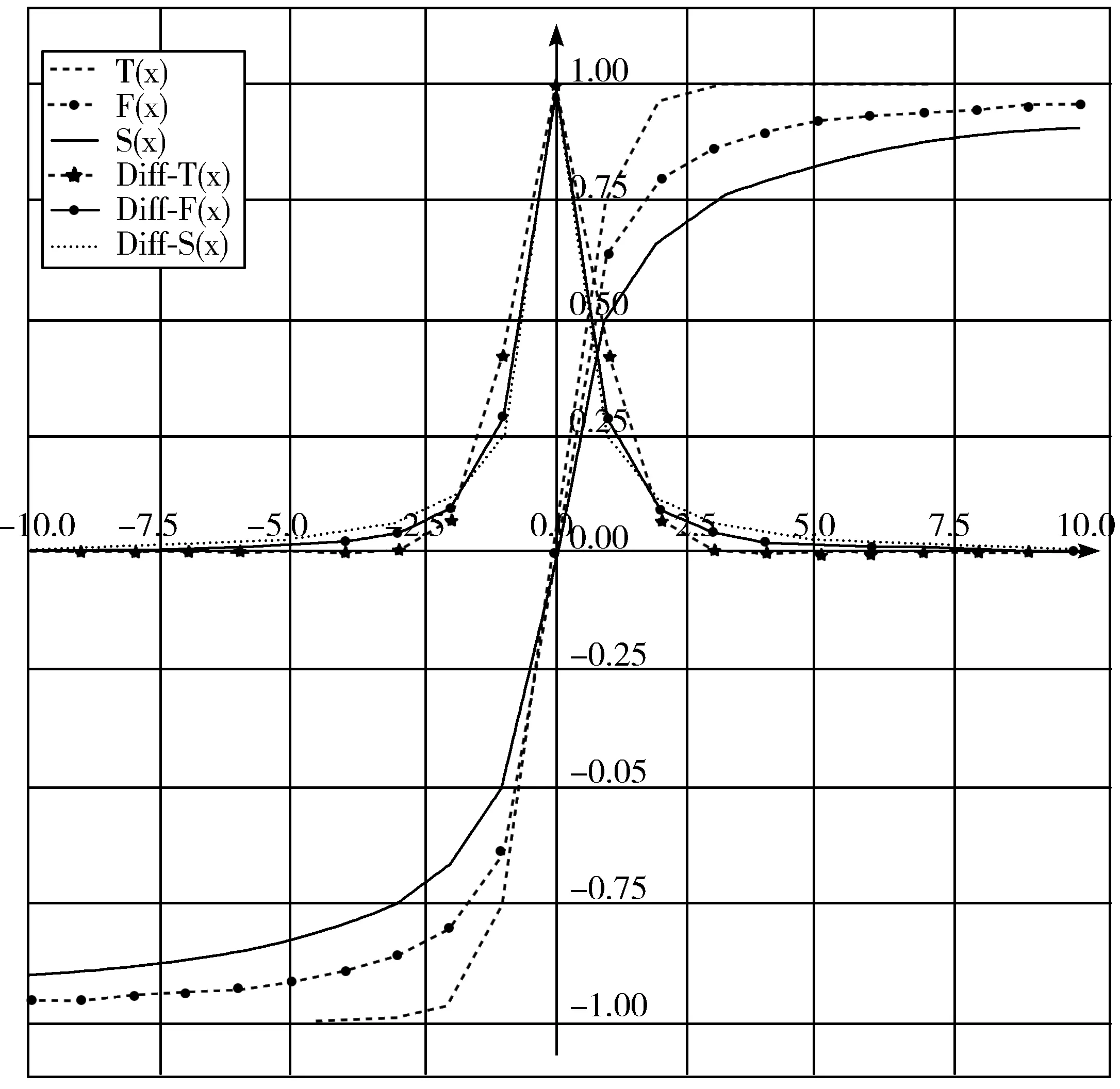
图2 各激活函数及其导数的图形化描述
由图2不难发现,构造的反正切函数不仅有着更加光滑的曲线,而且有着适当的导数下降速度,其导数的计算也相对简单,因此,在单词的稀疏性表示中其具有更强的鲁棒性并且能够在一定程度上节省模型训练所需的时间。
2.3 图像特征提取
图像特征提取模型是一种能够从给定图像中提取特征的神经网络模型,该模型提取的特征是图像内容的内部表示,是不能够直接理解的东西,通常是固定长度向量的形式。一般来说,图像特征提取最常用的模型是卷积神经网络模型,该网络被广泛地应用于图像检索[13]及手势识别[14]等计算机视觉领域,本文使用2个经典的卷积神经网络模型(Oxford VGGNet-16[15]和ResNet-152[16])来提取图像的特征。当使用VGGNet-16网络提取图像特征时,所得到的每幅图像的特征都由一个包含4096个元素的一维向量表示,而利用ResNet-152网络提取的图像特征则是一个包含2048个元素的一维向量。
2.4 句子表征
对于描述图像的每个句子,都需要对其进行清理,以减少训练过程中需要使用的词汇量。理想情况下,需要的词汇量既具有表现力又尽可能少,因为词汇量越少,模型训练的速度就越快。首先,需要将每个单词转换为小写,然后删除所有标点符号和所有带数字的单词,最后删除所有不超过一个字符的单词(例如“a”),在完成对每个句子的清理之后,就可以用以下向量表示每个句子:
X=(wstart,w1,…,wL,wend)
(9)
其中,wstart和wend都是人造的单词,分别置于句首和句末,相当于每个句子的开始和结束标志,L表示句子的长度,即一个句子中单词的数量,wi(i=1,2,…,L)是该句子中的第i个单词。接下来,需要将X编码为一个词向量,这样做的目的是便于将句子输入到网络模型中进行训练,与一些学者[17]所用到的方法相同,本文将句子中的每个单词都表示为一个热编码向量,该向量中元素的个数等于所有句子的最大长度,最后,再将编码后的词向量输入到网络模型中进行训练。
2.5 模型训练
图3概括了本文提出的ITLSTM神经网络模型的完整训练流程。
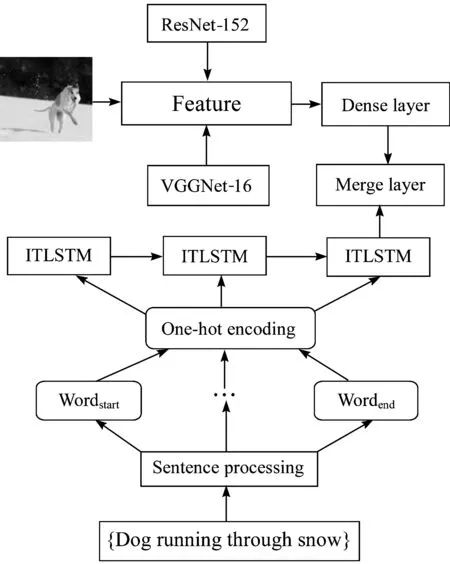
图3 ITLSTM神经网络训练流程
该网络系统由3个部分组成,分别是:用于句子表示的ITLSTM神经网络模型,用于图像特征提取的卷积神经网络模型,以及连接上述2个部分的合并层。
在训练过程中,本文根据经验将初始学习率设置为0.0005,并使用Adam[18]优化函数对模型进行优化,考虑到训练速度及计算机性能,batch_size被设置为512,且权重衰减率被设置为1×10-5,为了尽量降低训练数据集过拟合的风险,本文在模型中添加了批标准化层,并在每一层之后使用了Dropout正则化层[19],最后本文将最大迭代周期设置为20,利用标准交叉熵损失函数来记录模型的训练损失,当验证集精度在连续的3个迭代周期内不再增加时,训练将提前停止。本文中整个的实验过程都是在基于Keras神经网络框架的Python 3.6.0环境下进行的。
3 实验结果及分析
3.1 实验数据及评价指标
本文在公共可用的Flickr8k数据集上验证ITLSTM神经网络模型的性能,该数据集由8000幅图像组成,每幅图像都有5个基本的事实描述。在实验过程中,本文使用6000幅图像作为训练集,1000幅图像作为测试集,剩下的1000幅图像用于验证集,并使用2个经典的卷积神经网络模型VGGNet-16和ResNet-152来提取这些图像的特征,使用4个评价标准进行评价,这4个评价标准统称为BLEU评分(B_1、B_2、B_3和B_4)[20],这4个评价指标都是越高越好。
3.2 实验结果分析
本文首先比较ITLSTM (LSTM+F(x))神经网络模型与传统的LSTM(LSTM+T(x))神经网络模型以及以softsign作为激活函数的LSTM(LSTM+S(x))神经网络模型的性能,表1给出了3种模型的各个评价指标的得分情况。从表1可以看出,传统的LSTM网络模型和以softsign作为激活函数的LSTM网络模型所得到的BLEU评分相差不大,后者稍占优势,而本文提出的ITLSTM网络模型几乎在所有情况下的BLEU得分都优于其他2种LSTM神经网络模型,由此可见,本文提出的模型的确能够有效地缓解过早饱和现象,从而能够更加充分地利用句子的语义,因而对于给定的一幅图片,其生成的相应描述也会更加准确。
除此之外,通过对表1观察分析后不难发现:与VGGNet-16网络模型相比,采用ResNet-152网络模型来提取特征的图像标题生成模型均具有更好的性能,这说明增强图像表示的鲁棒性可以提高模型的性能。
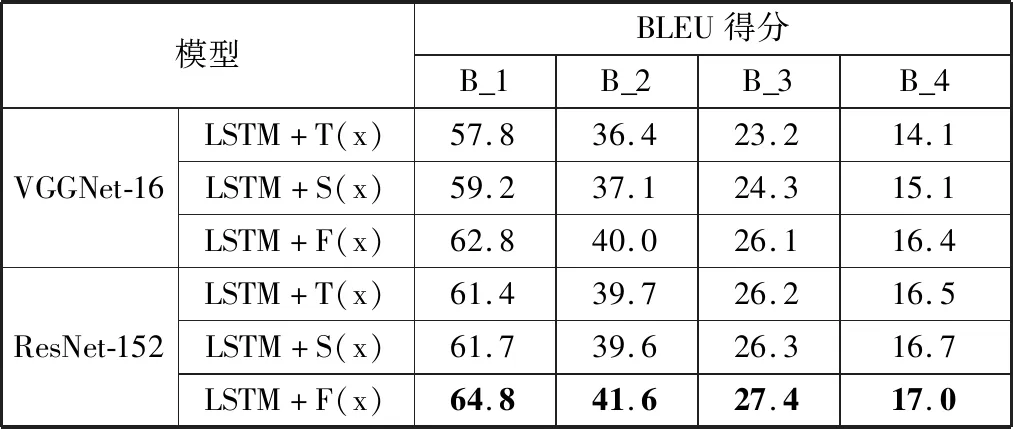
表1 3种LSTM模型获得的BLEU得分比较
为了更全面地验证ITLSTM网络模型在图像标题生成任务中的性能,本文接下来将这种改进的LSTM网络模型与一些经典的图像标题生成模型[7,10]进行比较,表2列出了不同模型的BLEU得分情况。通过对表2观察分析后仍然不难发现,ITLSTM网络模型在几乎所有的评价指标得分上都与这些经典方法持平或更好,这再次表明了本文构造的反正切函数在缓解过早饱和问题中的有效性。
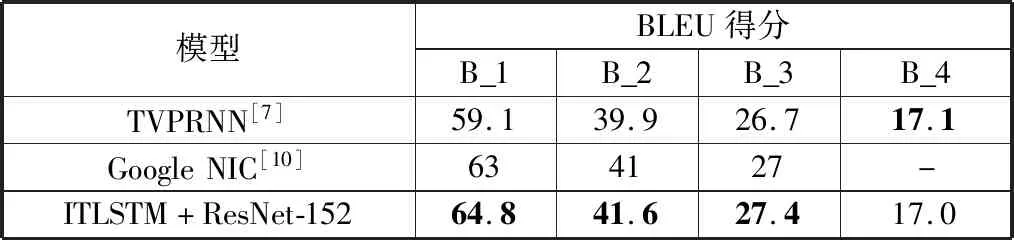
表2 与一些经典模型相比BLEU得分比较
最后,图4给出了ITLSTM网络模型和Google NIC模型在Flickr8k数据集上生成的图像描述的一些示例,尽管ITLSTM网络模型在这些示例图片上生成的标题中有一些错误,如主语的数量、动作和更具体的对象所执行动作的疏忽等,但它所生成的关于某一图像的描述仍然要比Google NIC模型所生成的描述更准确。

(a) ITLSTM: Two people are walking in the snow

(b) ITLSTM:White dog is running in the grass

(c) ITLSTM:Man in green shirt and backpack stands in front of skyscraper
4 结束语
本文提出了一种改进的用于图像标题生成任务的ITLSTM神经网络模型,该模型以反正切函数作为激活函数来更新细胞状态及隐藏状态,这有效地缓解了传统LSTM网络模型中双曲正切激活函数的过早饱和现象,与Google NIC等一些经典的图像标题生成方法相比,ITLSTM神经网络模型能够更全面地捕获句子信息,在公共可用的Flickr8k数据集上的实验结果表明,本文提出的ITLSTM神经网络模型在图像标题生成任务中的表现十分出色。
