基于深度信念网络的高光谱影像森林类型识别①
2020-04-24罗仙仙许松芽肖美龙陈正超
罗仙仙,许松芽,肖美龙,严 洪,陈正超
1(泉州师范学院 数学与计算机科学学院,泉州 362000)
2(福建省大数据管理新技术与知识工程重点实验室,泉州 362000)
3(泉州师范学院 教育科学学院,泉州 362000)
4(泉州市林业局森林资源管理站,泉州 362000)
5(福建省林业调查规划院,福州 350000)
6(中国科学院 遥感与数字地球研究所,北京 100094)
森林类型分类或树种识别是森林经营与管理的关键环节,高光谱遥感技术用于森林类型或树种识别取得一系列的成果[1-3].近20年来,以高光谱遥感图像为数据源的森林类型、树种类型的识别算法主要分为基于光谱特征[4]、基于光谱匹配[5]和基于统计分析方法[3,4].但由于高光谱图像数据量大且存在较高的谱间相关性和空间相关性,导致Hughes 现象[6],通常采取特征选择和特征提取两种方式进行降维处理.特征选择的目的是选择出对分类最有用的参数,压抑或限制无用信息,使选择后的特征参数尽可能大地反映类别之间的差异,并且彼此之间的相关性尽可能弱.王玲段等运用最佳指数法、波段指数法对HJ-1A 卫星HIS 影像进行波段选择,筛选出3 种波段组合(28-40-77、28-54-75、20-40-58)集中在红光和近红外波段,对3 种经济林识别精度达到70%以上[7].李俊明等用光谱混合距离判断出HJ-1A 影像中波长508.42 nm、696.85 nm、885.18 nm 为区分阔叶林和混交林的最佳波段组合[8].Koedsin 等采取遗传算法对EO-1Hyperion 高光谱数据进行波段选取7 波段(549、712、732、1034、1235、2073、2083 nm)的“染色体”获得最高树种可分性[9].特征提取是建立在各光谱波段间的重组和优化基础上的运算.通过数学变换的方式将原始数据矢量空间投影到维数低的新的空间中,从而实现降低空间维的目的,但改变了图像的原有特性.高光谱特征提取和特征压缩技术主要包括最小噪音分离变换、典范变量分析、独立成分分析ICA 以及主成分分析PCA.Ballanti等人与Zhang 等人均采用最小噪音分离变换方法对高光谱数据进行特征提取,并取得较好树种识别精度[3,4].
深度学习是当前机器学习与人工智能研究热点,是指超过三层的神经网络模型[10],模仿人类大脑的层次结构,是一组尝试通过使用体系结构的多个非线性变换组成模型中数据的高级抽象机器学习算法.深度学习由加拿大多伦多大学Hinton 教授于2006年提出的一种有效的特征提取及分类方法[11],被应用到语音识别、图像识别、计算机视觉等领域,并取得了良好的识别效果.深度学习典型方法包括限制玻尔兹曼机、深度信念网络、卷积神经网络和自动编码器等[12].深度学习新方法包括递归神经网络及其变种模型长短时记忆模型和生成对抗网络等.深度学习方法用于遥感图像处理取得快速发展[13-15],由于深度学习方法训练与测试需要大量样本数据,大多对现有标准数据集[16]进行研究,实际应用微乎其微[17,18],在林业遥感领域,只见李英杰等人利用线性稀疏自动编码器用于林业图像分类研究[19].目前,尚未见文献报道深度学习方法在林业高光谱遥感分类中应用.因此,论文将研究深度信念网络用于环境与灾害监测预报小卫星HJ-1A 高光谱影像森林类型识别研究,通过深层的学习,可以充分、自动、高效利用高光谱的各个波段进行特征提取,为高光谱林业遥感处理,乃至智慧林业等方向研究提供新的研究视角.
1 研究方法
1.1 受限玻尔兹曼机
1.1.1 受限玻尔兹曼机模型
一个受限制玻尔兹曼机有两层,如图1 所示,一层是输入层v(或说可见层),i 为任意一个节点;另一层是输出h(或隐藏层),j 是其中的一个节点,可见层与隐藏层为全连接关系.同一层的单元之间没有连接关系.RBM 是一个无向的生成能量模型,RBM 所具有能量如式(1)所示.

图1 RBM 模型示意图


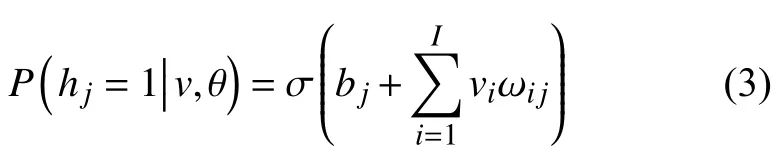
同理,给定隐藏层节点的参数时,可见层任一节点的激活概率为:
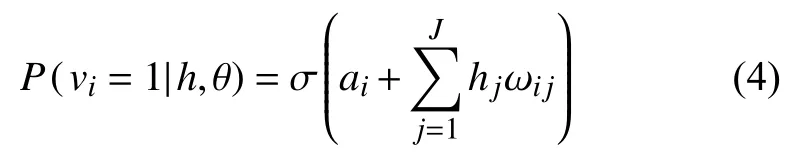
其中,σ (x)是由逻辑函数定义的S 型函数,Sigmoid 函数为:
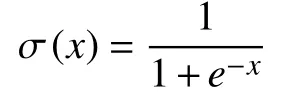
1.1.2 限玻尔兹曼机的训练

dk表示期输出或目标输出,ok表示响应于训练像素的实际输出,总共为K 个输出.为了最小化误差E,可计算E 相对于网络中每个权重和偏置值的偏导数,通过对比散度算法(Contrastive Divergence,CD)可以快速进行参数更新,更新规则为[20]:

式中,ε为学习率.〈 ·〉data是对数据分布的期望值,〈·〉recon是对模型分布的期望值.
1.2 深度信念网络(Deep Belief Network,DBN)
一个深度信念网络由多层RBM 构成,如图2 所示.DBN 有两个关键的训练步骤:一个是预训练,另一个是微调.

图2 深度信念网络的生成模型
1.2.1 预训练
预训练DBN 是无监督的过程.采用对比散度算法,自底向上逐层训练RBM,直到最后的隐藏层为止,这样使DBN 从原始的输入数据中提取更多的深层特征.
1.2.2 使用反向传播算法进行微调
反向传播算法最初是由Rumbelhart 提出的,是监督分类的过程.在预训练中,通过逐层训练,得到最终预测的分类结果.然而,真实的结果与实际预测结果存在误差,反向传播算法根据此误差向后微调DBN 的参数,并通过灵敏度 δk修正网络参数,对于某一输出层,若第k 个节点的实际预测为 ok,真实的结果为dk,其灵敏度定义为:


批处理的更新规则如下:

1.3 分类精度指标评价
1.3.1 总体精度
对分类结果质量的总体评价可以用总体精度来表示,总体精度等同于被正确分类的像素总数除以总像素个数的总和.在混淆矩阵的对角线上,分布着被正确分类的像素个数,它能够匹配正确分类的像素数与真实分类的个数.根据混淆矩阵计算总体精度的公式可以列出如下:

其中,C 表示分类的总体个数,mii表示混淆矩阵对角线上的元素,N 代表测试样本的总数.
1.3.2 Kappa 系数
Kappa 系数是采用多元离散分析技术来反映分类结果与参考数据之间的一致性的指标.由于它将混淆矩阵中的全部因子都考虑在内,因此将其视为一个更为客观的评价指标,其定义为:

其中,mi+,m+i分别代表混淆矩阵中第i 行与第i 列的总和,Kappa 系数与分类精度密切相关,呈正比关系.一般来说,Kappa 系数越高,分类精度越高.
2 实验
2.1 实验区域与高光谱数据
研究选用HJ-1A 星HSI 数据2 级产品,成像时间为2011年8月24日,共115 个波段,空间分辨率为100 m.研究区为福建省泉州市德化县西部8 个乡镇,其行政区范围及假彩色合成影像(第105、70、40 波段进行假彩色合成)如图3.该产品影像数据经过系统几何校正和辐射校正,校正误差不小于一个像元,校正后影像统一到指定的地图投影坐标系下(西安1980 坐标系).HSI 影像数据的部分波段存在明显的条纹,主要包括第1-29 波段,严重影响图像的质量和应用,因而本研究将前29 个波段剔除,剩余86 个波段,波长区间范围(529.6350-951.54 nm).
2.2 实验处理流程
实验总体处理流程如图4 所示,先进行数据准备,然后搭建好tensorflow1.11.0 框架开发环境,数据集转换成Python 程序容易处理的csv 文件,进行训练集与测试集划分,再进行实验对比.实验基于Windows 10 64 位操作系统,处理器型号为Intel(R)Core(TM)i5-8250U CPU @1.60 GHz 1.80 GHz,实验在PyCharm 2018.3x64 编辑器中进行编码与参数调优,加载Python 扩展库,包括深度学习TensorFlow、numpy、Pandas、Matplotlib 等[21].

图3 研究区及假彩色合成影像
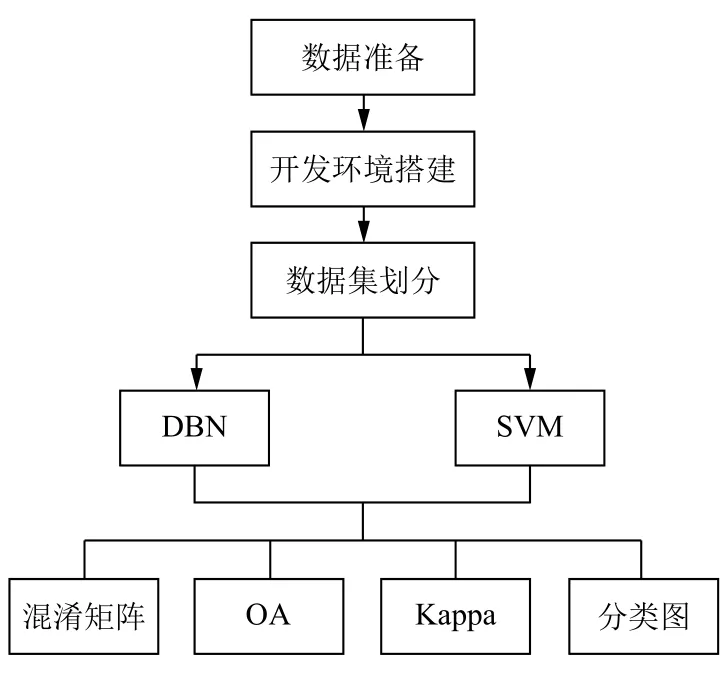
图4 实验处理流程
实验中,依据二类调查数据,选取带标签样本,同时对86 个波段数据作为DBN 的输入,并进行归一化处理,同时对标签进行独热编码(One-hot 编码),再对数据集进行随机打乱,选取训练、测试两部分数据.将训练好的参数保存在Tensorboar 中,对整体数据加载、混淆矩阵输出,绘制图像,并将结果与SVM 对比.
2.3 训练样本与测试样本分配
研究区域共97 258 个像素点被分类,为提高DBN 分类效果,通过多次预实验,选取28 000 个已知类别的像素点作为训练样本与测试样本,其中51 989 个像素点是针叶林,6142 个像素点是阔叶林,16 283 个像素点是混交林,其余28 986 个像素点为非林地.在训练过程中,针叶林类有10 000 个训练样本,其他每个子类有6000 个训练样本.如表1.
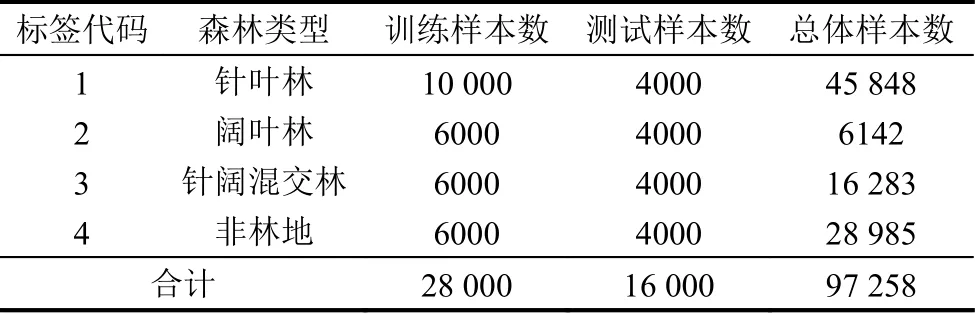
表1 数据集标签分类
3 结果与分析
3.1 隐藏层层数对分类结果的影响
目前,由于对于DBN 结构的选择尚且没有完善的理论基础,基本靠实验调参,给出最优参数.合适的网络深度影响最终分类结果与运行时间.当DBN 的层数过多,容易过拟合现象.反之,容易产生欠拟合现象.实验中,首先固定其它超参数,如学习率为0.001,激活函数为Sigmoid,批处理量100,梯度下降方式采取rmsp,迭代次数1000,cd-k 为1.每个隐藏层节点数均采用256.对DBN 的层数是从{3,4,5,6,7}中选取,采用网络搜索方式进行参数调优,不同隐藏层层数对分类结果影响见图5.当隐藏层层数为3 时,总体精度与Kappa 系数最大.

图5 不同隐藏层层数对分类结果的影响
3.2 隐藏层节点数对分类结果的影响
隐藏层节点数量选择不当常常造成训练出现“过拟合”现象.隐藏节点过少时,网络对数据的拟合性能很差,甚至无法有效的完成分类任务;过多时,会造成训练时间增加,寻找最优解过程中陷入局部最优的机率提高.实验中,固定DBN 的层数为3,其它超参数也不变,隐藏层的节点数量依次从{16,32,64,128,256,512}中选取,实验结果如图6 所示,当隐藏层节点数为256 时,总体精度和Kappa 系数最大.

图6 隐藏层节点数对分类结果的影响
3.3 与支持向量机分类方法的比较
支持向量机方法采用的核函数为径向基函数(RBF),惩罚因子C 的范围在[1,0.1,0.001]上寻找,训练样本与测试样本与DBN 方式保持一致.采用5 折交叉验证与网络搜索方法对SVM 进行参数调优,当C 值取1 时获得最高总体精度,达到73%,Kappa 系数为0.6447.深度信念网络与支持向量机分类结果比较,见表2 与图7.图7 中,绿色为针叶林,阔叶林为黄色,粉红色为混交林,蓝色为非林地.

表2 不同方法分类效果比较

图7 不同方法分类结果
从表2 可知,DBN 在各森林类型的分类精度以及总体精度、Kappa 系数都略高于SVM.究其原因,深度信念网络方法将高光谱所有波段特征全部作为输入,通过受限玻尔兹曼机的无监督学习,自底向上进行预训练,获取初始特征参数,对各种森林类型进行深层特征提取;同时,通过自顶向下的有监督学习进行参数调优,更有效挖掘出森林类型地物特征,提高分类效果.
当隐藏层层数为3,隐藏层节点数为256 时,是深度信念网络的最优参数,此时,DBN 分类结果的混淆矩阵见表3.由表3 可知,阔叶林精度最低,仅为83.0%.混交林精度最高,达到95.4%.
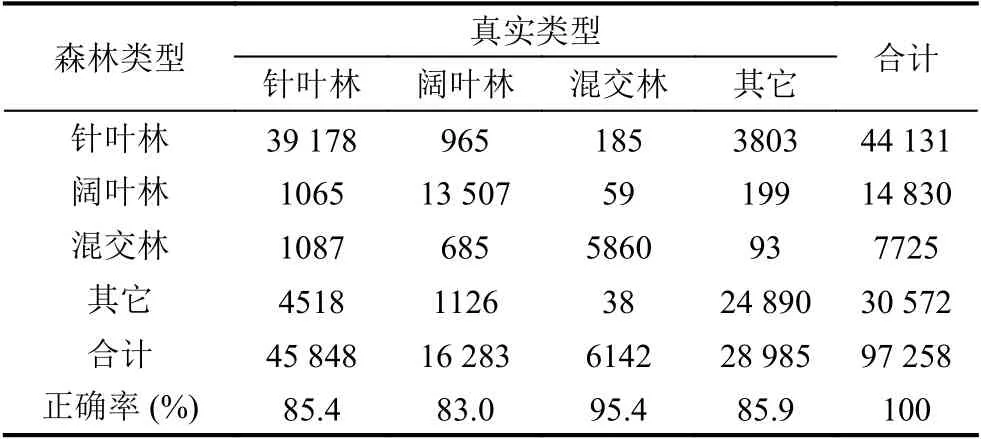
表3 最优参数的DBN 分类方法混淆矩阵
4 结论与讨论
4.1 结论
本文借助DBN 模型与HJ/1A 高光谱影像,通过无监督的预训练和有监督的微调对泉州市德化县西部8 个乡镇进行森林类型识别研究,通过大量实验调参,层数为3,每层节点数为256 的网络结构对森林类型识别效果最好,总体精度达85.8%,Kappa 系数为0.785,好于支持向量机的分类结果,证明了深度信念网络用于森林类型分类的优越性.
4.2 讨论
(1)本文利用深度信念网络方法进行森林类型识别研究,具有研究方法创新,该方法分类结果好于传统决策向量机,但该方法如何解决“同物异谱”和“同谱异物”的机理尚不明确.
(2)结合二类调查数据,选取近1/3 的样本作为训练与测试样本,才提高了分类效果,但现实研究中,如果样本量较少,或没有样本,如何利用对抗生成网络进行扩展样本将是下步研究重点.
(3)本文仅从光谱特征出发,没有利用空间特征,以及光谱特征与空间特征(空谱联合特征),而这些特征可以深层次的挖掘数据的内部特征,是否可以提高分类效果值得进一步研究.
(4)最优的网络结构只是针对森林类型识别而言,二级、三级地类识别的最优网络结构需要进一步研究,同时,迫切需要建立适用于林业遥感的深度学习分类方法的标准与规范.
