课程推荐预测模型优化方案及数据离散化算法①
2020-04-24张戈
张 戈
(中国社会科学院大学 计算机教研部,北京 102488)
在大学选课系统的“课程推荐预测”模块中,系统需要根据学生的选课要求预测出最适合他的课程,并给出课程推荐建议.本研究的目标是通过对预测模型的参数优化和算法改进,尽可能地提高模型评分即预测准确率,给出课程推荐的最优解.
机器学习的预测算法众多,根据样本数据特征值的特性,本研究选择 k 近邻算法(k-Nearest Neighbors algorithm,k-NN)拟合模型进行预测.k-NN算法主要靠周围有限的邻近样本,而不是靠判别类域的方法来确定目标点的所属类别.由于本研究中原始样本数据具有局部不均衡和数据叠交性,因此对于这种类域的交叉或重叠较多的样本集来说,k-NN算法较其他算法更为适合.但是在不进行任何参数调整和算法改进的情况下,推荐课程的预测结果不能够覆盖学生对所选课程的要求,模型预测结果不够准确.为了更好地解决这些问题,获得推荐和预测结果的最优解,本研究从k-NN算法类的选择入手,逐步探讨参数的调整方案,在分析了kd 树搜索最近邻算法之后,依据样本数据特点研究和设计了“数据离散化算法”[1-3].
1 k-NN算法基本原理和研究采用的机器学习方式
在模式识别中,k-NN算法是一种用于分类和回归的预测方法.在这两种情况下,输入由特征空间中k 个最邻近的训练实例组成.输出则取决于k-NN 是用于分类还是回归:在k-NN 分类中,搜索出和目标点最近邻的k 个样本点,按多数投票原则选出最多的分类作为目标点标签.在k-NN 做回归时,一般是用最邻近的k 个样本的分类标签的平均值作为预测结果.
本研究使用Python 语言机器学习工具包scikitlearn 中的KNeighborsClassifier 类建立课程推荐预测模型,我们将围绕预测模型参数优化和数据离散化展开研究工作.
2 预测模型优化方案和数据离散化算法设计
表1 列出了KNeighborsClassifier 类的主要参数.其中n_neighbors 是近邻值,即k 值,默认是5,分类器会选取5 个与新数据点最接近的样本.Weights 是分类器在进行预测时用来计算样本权重的函数.如果该参数为“uniform”,则表示每个邻域中的所有样本的权重都是相等的.如果该参数为“distance”,则样本的权重值与它距新数据点的距离成倒数关系.algorith 决定了k-N N 最近邻的核心算法,该参数可以是“a u t o”、“brute”、“ball_tree”和“kd_tree”,分别代表自动选取算法、暴力搜索、球树算法和kd 树算法.metric 参数表示距离度量公式,可以是曼哈顿距离或欧氏距离[4-7].
2.1 最优k 值选择算法
本研究首先对k-NN 的重要指标k 值进行优化.在优化之前,我们采用交叉验证方法对拟合模型进行准确性评估.图1 是使用测试集对训练样本模型的评分结果,可以看到,在没有任何参数调整和算法设计的情况下,拟合模型评分仅为0.67,即预测结果有67%的准确率,可以说模型的测评结果非常不理想.
k 值(即n_neighbors)的选择高度依赖于样本数据.一般来说如果k 值较大,则可以达到抑制噪声的作用.当然k 值过大会使分类边界不那么明显,模型过于简化,预测标签会产生多个结果均可的情况.比如我们设定k 值为30,那么KNeighborsClassifier 分类器会选取30 个与新数据最接近的训练样本点,并按照最多投票原则,选取它们中的最多分类标签作为预测标签.相反,如果k 值过小,分类线会竭尽全力的包含到每一个该类的点,即使是噪点,也会被包含,预测模型变得复杂,容易产生过拟合现象.当k 为1 时,就只有一个最邻近的样本点被选中,它的标签即为目标新数据的预测标签.一旦该样本点是个噪点,那么预测结果就是错误的,预测模型失去意义.

图1 默认参数下的拟合模型测评结果
本研究对k 值的选择不采取固定取值的方式,而是通过一个自定义函数完成k 值的自动选取,该函数的功能是在k 值的一定选取范围内对预测模型进行交叉验证,根据测评结果选出模型评分最高的k 值.图2为选取最优k 值的活动图.算法首先给出一个k 的取值范围,根据原始数据量设置为1 到50.使用交叉验证方法建立训练集和测试集,依次使用每个k 值建立拟合模型,比较它们的模型评分,将模型评分最高的k 值记录下来,用该k 值拟合的模型获取分类标签结果.实验数据可以证明k 值的选择尤为重要.

图2 选取最优k 值算法活动图
2.2 距离公式优化
预测模型的参数Weights 的默认值是“uniform”,表示邻域中的具有投票权利的各样本点的权重都是相等的.这显然是不合理的.目标新数据的标签应尽量依据距离它最近邻的样本点的标签给出,并且这些投票样本点的标签对最终结果的贡献应该和它们与目标新数据的距离有关.本研究将该参数调整为“distance”,表示投票样本点的权重和其距新数据点的距离相关(倒数关系),即距离越近的投票样本点影响力越大.
本研究中k-NN 最近邻使用的算法是kd_tree,kd_tree 中距离公式的选择至关重要.预测模型默认采用“闵可夫斯基”距离公式:

当式(1)中的p 为2 时,即为欧几里得距离,当p 为1 时,即为曼哈顿距离.
如果距离度量采用欧式距离(euclidean),分类器会计算样本点和新数据点之间的绝对距离.本研究中样本数据每个特征取值范围较小,均是0 到5 区域内的整数,那么新数据点距离每个特征的欧式距离值就非常相近,分类界线不明显,欧式距离无法完成更好地分类作用,分类边界模糊的情况仍旧没有得到改善.式(2)是曼哈顿距离公式:
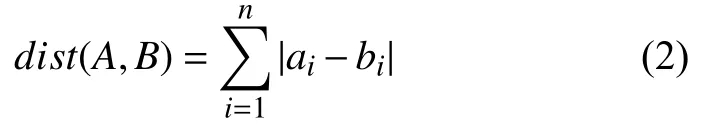
曼哈顿距离计算的是目标数据点和各个对应特征之间距离的总和.
我们从原始数据中随机抽取300 条数据对上述两种距离公式进行比较.图3(只显示部分样本数据)中分别计算了目标数据点和每个样本数据的欧式距离和曼哈顿距离,欧式距离的样本方差为1.4,曼哈顿距离的样本方差为3.4.可以看出使用欧式距离度量的训练集样本点分布较密集,样本点之间的差距不大,不利于分类.曼哈顿距离会分散样本点分布,分类时的界线识别会略好于欧式距离.实验数据验证了采用曼哈顿距离的预测模型评分略高于采用欧式距离的评分[8-10].
2.3 数据离散化算法设计
k-NN 邻近算法的核心规则在brute、kd_tree 和ball_tree 三种算法中进行选择.本研究中,特征的维度不会超过20 个,因此我们采用更高效、速度更快的kd_tree 搜索最邻近值.

图3 样本点两种距离度量比较
kd_tree 搜索最邻近算法首先会找出方差最大的特征向量,然后将其作为当前分割维度,按中位数分割该维度空间,在当前维度上小于中位数的数据集作为左子树的数据集,大于等于中位数的数据集作为右子树的数据集,依次重复递归直到建立一棵kd 树,从而可以搜索最近邻的点[11,12].
可以看出,特征向量的权重依据它们各自的数据方差.本研究中的6 个特征向量取值范围均为0~5.从收集的样本数据来看,“对课程通过率重视程度”和“对课程趣味性的重视程度”两个特征相比其他特征向量,其数据更集中在3~5 之间,数据更密集,方差更小.如果按照kd 树算法的空间分割依据,这两个特征向量会最后被分割,也就是它们的权重排序是最后两位.但实际上,我们希望上述两个特征向量的权重排序分别为第4 位和第5 位.因此我们设计了“数据离散化算法”,以期达到“人为”修改6 个特征向量方差的目标,从而让模型按我们希望的特征权重排序进行分类.如果采用传统的标准化数据的方法,可以将6 个特征向量数据统一映射到[0,1]区间上,但是它不能改变特征向量的权重,其特征向量方差的排序仍旧没有改变.
本研究建立了“数据离散化算法”的核心公式:
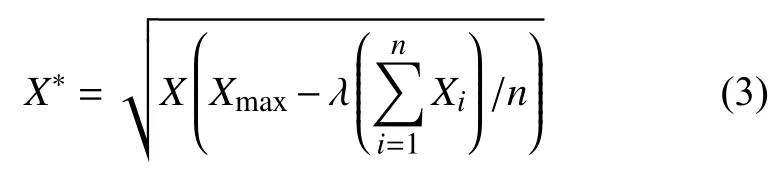
每个特征向量的所有样本数据均通过该公式进行预处理.在式(3)中,X 是原始数据,X*是离散化后的数据.原始数据X 乘以一个倍数后发生离散,该倍数等于样本数据最大值减去样本数据均值乘以系数λ.λ 系数为人工给出的期望权重值,取值范围在[0,1]之间,其作用是降低数据分布密集在[3,5]之间的两个特征的均值.经过该离散化公式的处理,原样本数据各个特征向量的方差排序变为了我们希望的排序顺序.但是如果考虑到分布区间内数据点的纯度对改变特征权重排序的影响,我们需要进一步引入信息熵并研究其对数据离散化的作用[13-15].
3 实验分析
本研究使用Python 语言工具包scikit-learn v0.21.3 对采集的Excel 格式的近千条样本数据拟合预测模型,按3:1 的比例抽取训练集train 和测试集test 数据,通过交叉验证方法评测预测模型,给出模型准确率评分.代码编辑和输出结果在jupyter notebook环境下完成.
3.1 最优k 值选择实验
本研究首先设计了最优化k 值的算法,功能通过自定义函数selectK()实现.图4 是函数的代码及模型测评结果,可以看到当k=7 时,模型评分最高,未进行任何优化前的模型评分为0.67,现在为0.76,提高了约13 个百分点.

图4 选取最优k 值实验及测评结果
3.2 距离公式优化实验
经过分析后,距离度量公式采用曼哈顿距离,即p=1,weights 改为“distance”,从图5 可以看出调整距离公式参数后,模型评分从0.76 变为0.79,提高了约4 个百分点.使用曼哈顿距离度量提高了kd 树搜索算法在建树过程中分割特征空间时的辨识度,一定程度地提高了预测分类的准确度.但是它对模型测评分提升效果并不明显.从实验结果可以看出,样本数据的特征维度在20 以内、样本数据量较大时,采用欧式距离还是曼哈顿距离对最终模型预测结果的影响力没有参数k 值最优化的影响力大.
3.3 数据离散化算法实验
到目前为止模型的评分并没有超过0.8,在模型优化工作之后,我们的重点转到对样本数据的离散化上.表2 是数据离散化前后的各个特征向量方差及其排序对比.可以看到我们最为关心的两个分布较密集的特征,其方差排序由之前的第6 位和第5 位,变为现在的第4 位和第5 位,特征向量的权重排序也因此而变为了我们希望的权重排序.

图5 采用曼哈顿距离公式实验测评结果
图6 是数据离散化后的模型测评得分,以及对新数据点[2,4,5,2,0,2]进行预测的结果.可以看到此时的预测模型得分为0.85,即预测准确率为85%.而且模型给出了正确的课程预测结果,推荐课程准确.

表2 数据离散化实验前后方差和特征权重对比

图6 数据离散化实验结果
表3 是本研究在模型未优化时和经过最优化k 值、距离公式优化、数据离散化几个过程的预测模型测评分对比.可以看到k 值的自动选取函数对预测准确率的提升贡献最大.其次是数据的离散化处理使模型测评准确率提高了7.4%.那么可以看到距离公式的优化对提高模型准确率只贡献了不到4 个百分点,这个和样本数据的特征维度个数有关.在经过了预测模型参数优化和数据离散化过程后,模型预测准确率由0.67 提高到了最后的0.85,效果非常显著.

表3 各个优化过程模型测评分对比
4 结论与展望
为了在学生选课时给他们推荐更适合他们的课程,本研究建立了课程推荐预测模型.在对样本数据的特点进行详细分析之后,本研究设计了一套预测模型优化方案和数据离散化算法,使预测模型的准确率评分提高了约26.8%.
本研究在进行过程中发现了一些问题和需要进一步探讨的内容.首先,距离公式参数调整对提高模型准确率效果不显著,随着数据量和特征的增加,距离公式的影响权重需做进一步的研究.第二,实验证明了数据离散化对模型优化的显著效果,但是还有一些问题需要做进一步的思考.例如两个分布较密集的特征向量其区间明显被分割为[0,2]和[3,5]两个分布.相对于区间[3,5]的数据来说,区间[0,2]的数据点是否可以看做异常点被“抛弃”? 区间数据的纯度对数据有什么影响?如何改进“数据离散化”公式,用一个新的算法自动给出合理的λ 值,而不是人工给出λ 值.第三,样本数据本身是否合理是本研究进行过程中最困扰研究者的一个问题.从实验结果能够看到,在做出了预测模型优化和离散化数据处理之后,模型的评分仍没有达到0.9 以上,更不要说接近1 的高模型评分.究其原因,原始样本数据在特征向量设计上存在优先级不明确、课程的特征属性相互叠交的情况,一条含糊不清的特征数据,可能对应1 到2 个标签结果,并且这两个结果均合理.如何让样本数据更可用是下一步要进行的研究.
