基于类别划分的OSSEC报警数据聚合方法
2020-04-23陶晓玲龚昱鸣
陶晓玲, 龚昱鸣, 赵 峰
(1.桂林电子科技大学 广西高校云计算与复杂系统重点实验室,广西 桂林 541004;2.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;3.桂林电子科技大学 信息与通信学院,广西 桂林 541004)
0 引 言
在现有的入侵检测系统中,检测设备种类繁多,且设备间工作相互独立,对同一入侵行为会产生大量异构、多源的重复报警。安全管理员难以从海量的报警数据中捕获有价值的报警信息,无法快速地对入侵行为做出准确的决策。报警数据聚合是减少重复报警的重要手段,能有效降低无用报警信息对系统检测性能的影响。现有的数据聚合方法主要根据数据的几何距离相似度、语义相似度及密度分布等特性进行聚合。
基于数据的几何距离相似度,文献[1]提出了一种对同一个攻击步骤的不同报警进行聚合的方法,该方法通过将相似度和抽象性相结合来重构攻击场景。文献[2]提出了一种改进的K均值聚合算法,该算法通过优化初始聚类中心点减少迭代次数,并采用MapReduce编程模型将改进的算法并行化设计,提高计算效率。文献[3]提出了一种基于凝聚度与K均值的报警数据聚合方法,该方法虽然能提高聚合结果准确性,但未对误报警进行处理。
文献[4]提出了一种基于标签的报警数据聚合方法,该方法可以用标签对报警数据进行标记,按标签自动分类并聚合相似报警,从而降低误报,但不适用于不同设备数据聚合。文献[5]提出了一种Snort报警关联器,通过源端口、目的端口和报警ID将相似报警捆绑到单个聚合报警,有效地减少了冗余报警的数量,但在报警数据聚合时未考虑攻击类型对聚合率的影响。文献[6]提出一种基于Graph的报警关联方法,该方法设置属性相似度的阈值,然后计算源地址、源端口、目的地址和目的端口的属性相似度,并以此对报警数据进行聚合,在计算属性相似度时也未考虑报警数据攻击类型对相似度的影响。文献[7]提出一种基于相似半径的迭代自组织数据分析方法,该方法利用最优序列比较法计算报警数据的属性权重和相似度。
基于数据的语义相似度,文献[8]提出了一种自适应调整集群节点数目的语义数据聚合算法,该算法能够快速降低信道拥塞,即使在拥塞情况下也能提高数据精度。文献[9]提出了一个基于语义的数据聚合框架,该方法能够对聚合数据执行推理机制,从而推断出上下文内容。
针对数据密度分布,文献[10]提出了一种基于密度与近邻传播融合的数据流聚合算法,该算法能够根据数据流的时态特征变化,实时地对数据流进行聚合。文献[11]提出了一种基于密度增量的K均值聚合算法,该算法能有效地处理高维混合属性的数据,但该算法对于数据的密集噪声点处理存在局限性。文献[12]提出了一种抗噪声聚合算法,该算法基于空间密度和时间密度,可以减少重复报警并且降低误报率。
上述文献均未对原始报警数据作特殊处理,侧重聚合方法的研究。由于原始报警数据的类别属性存在差异,不同类别的报警数据具有较低的相似度,导致数据聚合受影响[12]。因此,本文充分考虑OSSEC报警数据类别属性的差异性,先借助MapReduce编程模型对数据进行合并,再以类别属性对数据进行划分,最后通过计算属性相似度对报警数据进行聚合。
1 类别属性划分方法设计
入侵检测系统会根据不同的攻击行为产生不同的报警数据,以至于采集到的OSSEC报警数据的属性存在差异。冗余属性增加了数据处理的复杂度并导致资源过多的消耗,同时对数据聚合准确性的影响也不容忽视。若对原始报警数据直接聚合,则报警数据对比的次数较大,同时也增加了类别属性查找的难度。通常相同类别的报警具有高度的相似性,且发生在同一攻击场景。攻击场景是一组具有某些共同特征的报警,根据攻击者采取的攻击方法定义了不同的攻击场景[13],同一攻击场景相同类别的报警数据通常具备以下特点之一:
(1)具有相同的攻击源,相同的攻击目标和相同的报警类型。如攻击者在一段连续的时间内对同一服务器进行一系列攻击。
(2)具有相同的攻击源,相同的报警类型和相同的用户访问。如攻击者不定时地对不同服务器发动分布式攻击。
(3)具有相同的报警类型,相同的攻击目标。如不同的攻击者协同对同一服务器发动攻击。
(4)具有相同的报警类型,相同的严重等级。如不同的攻击者同时对多个目标的同一漏洞发动攻击。
由此可以看出,相同类别的报警数据具有较多共同的特征。基于此,本文以OSSEC报警数据的类别属性作为标准对经过预处理的报警数据进行划分,然后对划分好的报警数据按类别存储。
本文方法中用到的相关参数符号见表1。

表1 参数符号说明
基于类别属性的OSSEC报警数据划分方法的过程分为4个阶段。
(1)首先,定义不同类别报警数据的集合和划分方法中用到的各个参数。
(2)然后,把精简过滤后的OSSEC报警数据加载到指定的集合,若加载到最后一行则直接跳出循环,否则将一一加载到集合。
(3)其次,对每条报警数据的类别属性逐一比较,将属于同一攻击场景中相同类别的报警数据放在同一个集合,并循环迭代逐层判别,生成不同类别的子集合。以类别属性的首字母升序将各个子集合的报警数据依次加载到新的集合中,从而实现类别属性划分。
(4)最后,把经过类别划分的数据写入文件中,并以指定格式进行保存输出。
基于类别属性的OSSEC报警数据划分方法:
Input: alert set in uniform format AlertProcessingByFilterC={n∈N|c1,c2,…,cn};
Output: AlertByCCAD={n∈N|d1,d2,…,dn}
(1) Begin
(2) New Arraylist dataList;
(3) for (j=0; j (4) ifC=∅ (5) dataList.add(C.get(j)) (6) else (7) break (8) New Arraylist (9) For(int i=0;i<9;i++) (10) { Lists[i].add(getClass) } (11) sortString(Alldata (12) Compare(data1,data2) (13) return sortList (14) } (15) convertData(sortList){ (16) for(String s: sortList){ (17) ossecs.add(s) (18) } (19) return ossecs (20) } (21) else (22) Q.add(ci),Q.add(ci+1) (23) return R(process_alert) (24) End 2.1.1 报警数据标准化 不同的IDS存在差异性和工作状态的相互独立,使得产生的报警数据格式不统一。本文基于消息交换格式IDMEF(intrusion detection message exchange format)的标准来对不同的入侵检测系统报警数据格式进行标准化。 目前IDMEF格式的报警数据对大多数的安全检测系统都是兼容的。属性的过多冗余使整体的处理复杂度增加,同时对准确性也会降低。属性的精简是非常有必要的。经过属性筛选之后的OSSEC报警数据包括时间戳、主机用户名、源IP、描述信息、规则编号、类别、严重程度等级等7种属性构成的七元组,形式化Alert={Timestamp, Rule_id, Description, User, Src_IP, Level, Classification }。 其每个属性的含义见表2。 2.1.2 报警数据合并 原始OSSEC报警数据是按天分开存储,同时每条报警数据占用了6行文件内容,在一定程度上增加了后续聚合处理的难度。针对文件数量比较多的问题,本文借助 MapReduce 编程模型对多个小文件进行合并,同时对数据内容合并和格式转换。 首先,对经过合并和转换后的报警数据进行封装定义。然后,顺序按行读取整个文本的内容,若读取到尾行则跳出循环,否则将读取到的每一条数据分别加载到集合。其次,在集合上设置一个大小为60 s的时间窗口进行移动,对于时间差小于设定窗口的报警数据进行检测。最后,对除时间属性以外的不同属性进行逐一比较,并且判断是否满足过滤条件,对字段User、Src_IP、Level和Rule_id采取逐个校验比对的方式,只要这4个字段存在差异,就把新传入的报警数据转入下一节点的验证过滤操作。可输出并存储的数据必须满足每个属性都符合过滤条件,否则,将会视作不过滤预处理操作。 表2 报警数据属性含义 2.2.1 属性相似度计算 通过对报警数据各个属性之间的几何距离进行数值运算来实现报警数据的聚会,同时这种运算也称为属性相似度计算。为了找到报警数据之间的关联性来生成高级报警,最终减少冗余报警的目的,本文需要对初级数据进行聚合。 下面给出各个OSSEC报警数据属性特征的相似度计算函数。 (1)报警标识相似度的计算 如果属性Rule_id,Description,User,Level相同,则设定相似度为1,如果不同,则设定相似度为0。 (2)IP地址相似度的计算 IP地址之间的相似度是通过对两条不同报警数据IP相同二进制位数r除以单个IP总长度32得到[14],该计算方法源自无类别域间路由法[15],其计算公式设置如下 (1) 其中,Resemip(OSSECai,OSSECaj) 是报警数据的IP相似度值,OSSECai和OSSECaj是报警数据。 (3)报警时间戳相似度的计算 报警数据的时间戳对相似度的全局计算有着重要的影响,同时是聚合中的一个很重要的因素。首先将最小和最大时间阈值分别定义为tmin和tmax, 将两条不同的报警数据之间的时间差Tinternal和时间阈值进行对比,当时间差小于最小时间阈值tmin时,则相似度为0,大于最大时间阈值tmax时,则相似度为1,当两条不同的报警数据之间的时间差Tinternal在最小时间阈值tmin和最大时间阈值tmax之间,则通过式(2)计算相应的时间相似度。关于如何来选取tmin和tmax, 不同参考文献给出不同的数值。本文根据实验的实际情况以及Long等[7]的结论,最大时间阈值和最小时间阈值的差为tmax-tmin=300 s, 将阈值计算公式设置如下 (2) 其中,Resemtimestamp(OSSECai,OSSECaj) 是OSSEC报警数据的时间相似度值,OSSECai和OSSECaj是两条不同的报警数据。 2.2.2 属性权重确定 对于属性权重的确定优先考虑客观的计算方法,不同属性的权重值对最终的相似度影响特别大,因此尽可能做到客观去评分是非常有必要的。当数据的获取比较难且存在多重共线问题才会考虑PCA算法,同时, PCA算法中每个主成分的作用难以从因变量和自变量之间的联系中体现出来,因此熵值法更加适用于确定各个指标的权重[14]。 报警数据之间的全局相似度对数据之间能否聚合起到决定性的作用,在全局相似度的计算中,为了衡量每个不同属性的重要性,需为每个属性设定相应的权重W。通过计算得知,权重矩阵为[0.0120 0.0362 0.0125 0.1622 0.3692 0.4204] (3) 其中,数据的总数通过Resemsum(OSSECai,OSSECaj) 来表示,i和j分别表示计算权重时不同属性的行号和列号,各个属性的权重通过Wj来表示。 面对收集到的数据中存在大量的冗余,针对如何去冗余和进一步精简报警数据,较高的期望值的设定能比较有效地解决这些问题。OSSEC聚合计算用到的相关参数符号见表3。 表3 参数符号说明 OSSEC报警数据聚合方法分为4个阶段。 (1)首先,把经过相似度计算的OSSEC报警数据进行封装。 (2)然后,对整个数据文件进行逐行内容读取,若读取到尾行则跳出循环,否则将读取到的每一条数据分别加载到集合。 (3)其次,用期望阈值集合跟每条报警数据的总相识度比较,并记录下满足条件的报警数据的条数。 (4)最后,进行聚合函数计算。 OSSEC报警数据聚合方法: Input: OSSEC_AlertSWSW={n∈N|Sw1,Sw2,…,Swn}; Output: OSSEC_AlertSADAAE={n∈N|e1,e2,…,en}; (1) Begin (2) for (i=0;i (3) ifSW=∅ (4) break (5) else (6) for(i=0;i (7) for(H=0.1;H<0.9;H=H+0.1) (8) if OSSEC_SumSim((SS(i)) >H)a++; (9) elseb++; (10) Com_Aggregation(); (11) End 为了验证本文所提聚合方法可行性,在OSSIM开源平台下搭建了OSSEC报警分布式入侵检测系统[14]。报警数据的采集环境如图1所示。 图1 数据采集平台拓扑图 将采集到的数据通过输出插件Barnyard2,输出到关系型数据库MySQL中。在OSSIM环境下部署一个服务端ossec-server作为主节点,4个数据采集端ossec-agent1到ossec-agent4作为从节点。总共采集OSSEC报警数据 150 283 条。本文以每条OSSEC报警数据的类别属性作为分析标准来细化,分类结果进一步细分见表4。 表4 原始OSSEC类 本文采用了数据内容合并、格式转换和属性匹配固定时间阈值的方式来对报警数据进行预处理,把经过预处理后的多个数据文件进行合并,对合并后的文件做属性的起始字符识别转换,将log文本文件转换成txt文本文件输出,并每一行代表一条OSSEC报警数据。 通过实验分析,定义数据的精简率来衡量预处理后的效果。src_n为原始报警的个数,dst_n为精简后报警的个数,报警数据的精简率计算公式如下 (4) 其中, ReduceRate反映了聚合方法对重复和冗余报警数据的消除效果,当原始报警的个数src_n一定的情况下,要想提高ReduceRate, 就必须降低dst_n。 图2给出了各类别的报警数量精简前后占比情况。 图2 OSSEC报警数据精简前后对比 通过实验得到,src_n为150 283条,dst_n为31 268条,总的报警精简率为79.19%。 通过与文献[16]的方法进行对比来验证本文提出的方法的有效性,通过取不同的期望值H对数据集进行训练来对比聚合效果,结果如图3所示。可以看出,在0.1≤H≤0.2时,聚合率呈现上升趋势并且两者的差距逐渐减少,在0.2≤H≤0.6时,两者聚合率的浮动都不大且均低于50%,在0.6≤H≤0.8时,两者的聚合率都发生明显的增长,在0.8≤H≤0.9时两者都趋于稳定。由此可见,本文提出的以类别属性作为划分标准然后通过计算报警数据属性相似度和权重来进行聚合的方法,相比常规手段的顺序聚合而言,更能使得聚合率提高并维持平稳。 图3 不同期望值下OSSEC报警数据聚合率对比 同时,本文还通过系统误报率和检测率进一步验证所提出方法的有效性,并且以这两个指标作为系统的检测性能。基于此,对收集到的报警数据根据以下规则进行标定。 当报警数据满足以下条件时: (1)报警数据的源IP与模拟发动攻击的IP具有相同的地址; (2)报警数据的目标IP与模拟的被攻击IP具有相同的地址; (3)报警数据的时间属性和模拟攻防环境产生的时间在预先设计的时间阈值内。 则认为是真报警,否则为误报警。 经标定后,真报警和误报警分别是23 236条和8032条。本文中随机抽取70%的数据作为训练集,剩下的30%数据作为测试。通过给出了一个混合矩阵A定义的指标来反映报警处理性能,如表5所示,表5中“+”代表真报警,“-”代表误报警。 表5 混合矩阵A 基于此,定义如下的一组反映报警处理性能的指标。 检测率(TP)计算公式如下所示 TP=A11+A12/(A11+A12+A21+A22) (5) 误报率(FP)计算公式如下所示 FP=A21/(A21+A22) (6) 通过对比本文提出的基于主机的OSSEC报警数据聚合方法(方法1)和文献[16]提出的聚合方法(方法2),两种方法的检测率和误报率见表6。 表6 系统检测率与误报率对比/% 由表6可知,方法1的检测率为88.92%,高出方法2的检测率10%左右,可以看出来本文提出来的方法对真报警的检测率有所提高,同时降低了误报率。 同时,通过定义系统检测的平均运行时间(Taverage)来对比两种方法的运行效率,如下所示 Taverage=Ttotal/n (7) 其中,运行总的消耗时间用Ttotal表示(ms),样本总数用n表示,两种不同方法的单位样本平均运行时间见表7。 表7 平均运行时间对比 从表7可以得出结论,本文提出的聚合方法在时间效率上优于文献[16]提出的聚合方法,提高了系统检测运行效率。 针对基于主机的OSSEC原始报警数据类别属性不统一且冗余量大,最终导致数据聚合率低的问题。本文提出了一种基于类别属性划分的OSSEC报警数据聚合方法。该方法通过类别属性划分来减少相邻报警数据对比的次数,减少数据聚合的运行时间,并借助MapReduce编程模型对大量分散的数据文件进行合并,最后通过属性相似度和权重来确定报警数据之间的几何距离进行聚合。实验结果表明,该方法有效地提高了OSSEC报警数据的聚合率,而且在降低系统误报率的同时提高了系统检测率。本文采用固定时间阈值的方式计算报警数据的属性相似度,在数据聚合时存在一定的时间局限性,后续可考虑采用动态时间阈值的方式计算属性相似度,能更加灵活地聚合不同时段的报警数据。2 OSSEC报警数据聚合方法
2.1 OSSEC报警数据预处理

2.2 属性相似度和权重确定


2.3 数据聚合

3 相关工作实验及结果分析
3.1 实验环境


3.2 预处理结果及分析
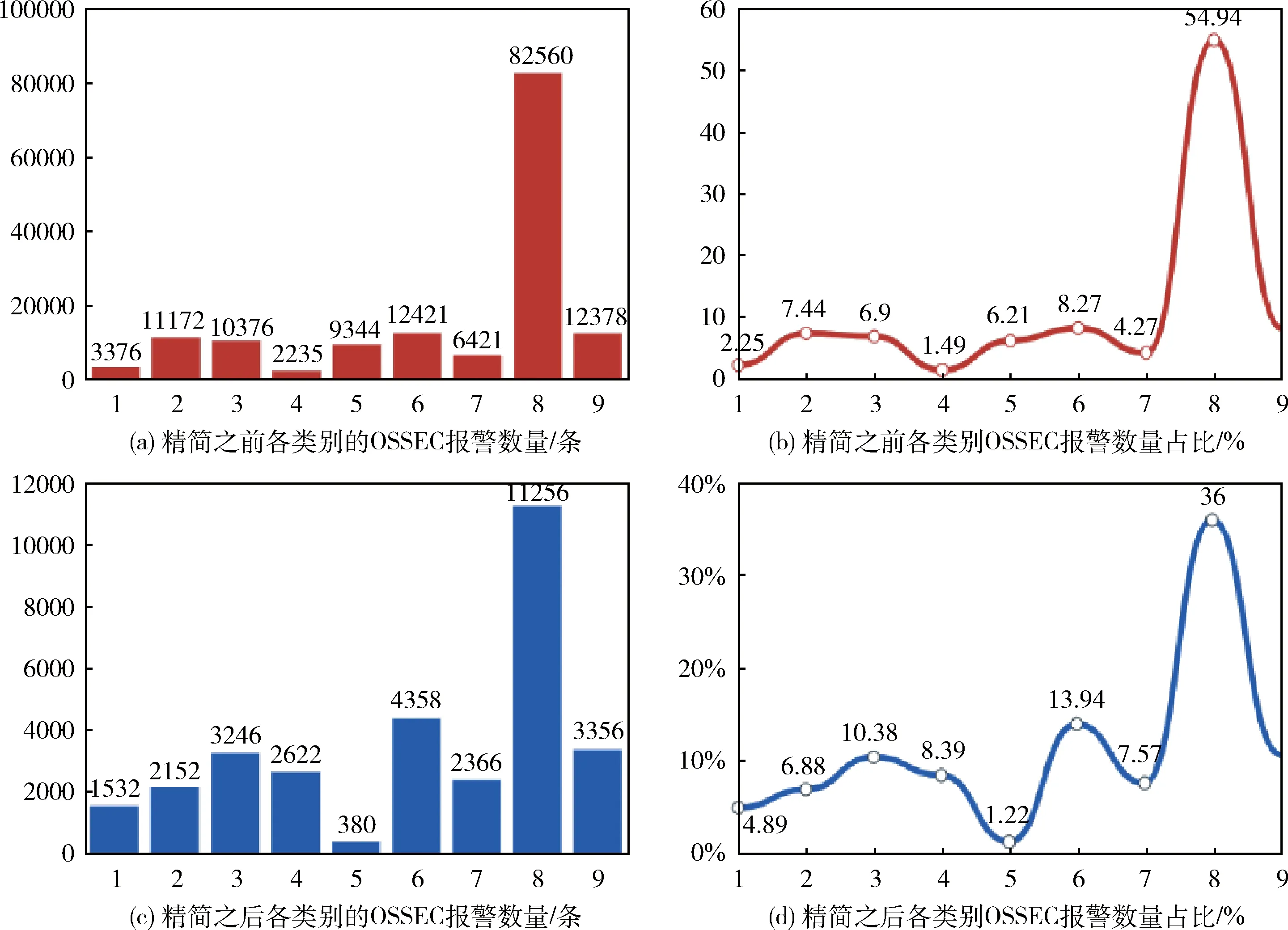
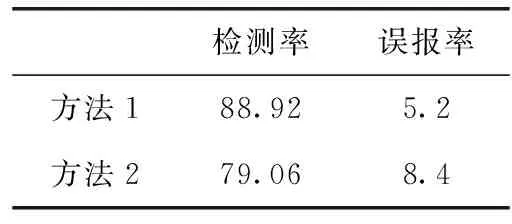
3.3 聚合结果及分析



4 结束语
