基于模板匹配的三维人体语义特征提取算法
2020-04-23李灵杰步文瑜孙海舟陈正鸣
李灵杰,童 晶,2,步文瑜,孙海舟,陈正鸣,2
(1.河海大学物联网工程学院,江苏 常州 213022; 2.常州市图形图像与骨科植入物数字化技术重点实验室,江苏 常州 213022)
0 引 言
随着社会经济发展,生活水平的提高,人们对定制产品和定制服务的需求越来越多,例如人体工学设计、服装高级定制、健身计划定制和定量跟踪等。这些需求涉及了人体语义特征,人体语义特征是指人体的身高、胸围、腰围、腿长等一系列维度信息。
为获取人体语义特征,传统的方法是手工测量。测量者借助皮尺、测高计等传统工具对被测者各身体部位手工测量并记录数据[1-2]。手工测量方法灵活方便,简单易行,几乎可以获得所有的人体特征数据,因此得到了长期而又广泛的应用。但是测量结果的精确度与测量者的技术水平相关,测量时间与测量者的熟练程度相关。通常情况下,测量误差较大,测量时间长,而且极大地消耗测量者体力、精力,不适合大规模、快速获取语义特征的情形[3-4]。
基于三维人体模型提取语义特征提供了一种快速、精确、可大规模使用的解决方案,也促进了语义特征在各方面的应用。例如,我国总后勤军备研究所对全军进行了抽样测量,建立了我国军人服装尺寸数据库,并对我国军人的体型特征进行了深入研究,建立了比较完善的军服号型系统[5]。Body Labs公司采用三维可视化技术,扫描人体获取数字模型,提取人体参数,为消费者和生产者提供服务。Body Labs公司已与美国陆军Natick士兵研发和工程中心签订协议,扫描了一万多名士兵的全身数据来提取人体模型参数,制定统计模型,为防弹衣的设计提供参考依据[6]。
三维人体模型中的语义特征通常需要借助特征点或特征曲线表达。Wang等人[7-8]提出了从点云数据中提取特征点和特征曲线的算法,该方法从点云模型中提取尖点和拐点,结合相应的人体测量标准提取特征点。首先对点云数据去噪、调整点云模型的方向;然后重建点云模型为网格模型;最后结合人体测量标准构建特征曲线。Wang等人的方法只能测量特定姿势的人体模型参数,另外该方法提取的特征曲线与模型不贴合,测得的结果误差比较大。Azouz等人[9]提出了一种自动标记人体特征点(landmarks)的算法,该算法基于统计学习,分为学习阶段和匹配阶段。学习阶段基于所构建的三维特征描述子Spin Images统计特征点的分布和相对位置。匹配阶段指定一个特征点开始匹配。该算法需要统计大量的特征点数据。Leong等人[10]更进一步提出了少标记(mark-less)的特征点和特征曲线提取算法,从深度图中提取特征点映射至三维模型。其核心思想是特征点主要分布在深度图的阶跃点,特征曲线由系列属性相似的特征点确定。利用该方法,作者提取了21组特征点和35组特征曲线。该方法基于深度图提取,对噪声非常敏感。Probst等人[11]提出的基于随机森林的方法,是一种将局部预测累积为全局的、图像级的人体测量的方法,其目标函数依赖于图像预测和局部预测估计模型参数。Song等人[12]提出了一种有效的服装尺寸自动预测方法,以人的身高、前视图和侧视图中的穿着人体轮廓作为输入,采用数据驱动的方法估计三维人体语义特征。Xu等人[13]提出了一种在人们穿着衣服的情况下,从一个运动传感器上测量具有大规模运动的人体的精确参数,并采用时空分析方法来挖掘姿势变化的信息。ShapeMate[14]方法是一种为在线商店提供人体形状估计的方法,该方法利用单幅照片恢复人体模型并预测模型的特征信息。其中几种方法的特征曲线图和示意图如图1、图2所示。
针对上述问题,本文提出一种基于模板匹配的三维人体语义特征提取算法。首先将三维人体模型数据库拓展为人体语义特征数据库;然后将输入模型和模板模型配准,根据模板上标注的语义特征采样点扩充出输入模型的语义特征采样点,使用贝塞尔曲线拟合特征采样点,形成一系列特征曲线;最后计算特征曲线长度,得到输入模型的语义特征参数。实验表明本文算法提高了语义特征提取的准确性,自动化程度良好,并且具有优秀的扩展性。

(a) 文献[7]结合人体测量标准提取特征曲线

(b) 文献[9]基于统计学习提取特征点

(c) 文献[10]基于深度图提取特征曲线

(a) 文献[12]数据驱动的方法

(b) 文献[13]基于时空分析的方法

(c) ShapeMate基于单幅照片的方法
1 算法描述
1.1 主要概念
1)语义特征。语义特征是指人体的各种维度,例如身高、胸围、腰围、腿围等维度。
2)语义特征采样点。语义特征采样点是用来拟合语义特征曲线的采样点,这些采样点位于语义特征实际位置的附近,简称特征采样点。
3)语义特征曲线。语义特征曲线是用来定位语义特征的三次曲线,通过计算曲线的长度,得到模型的语义特征,简称特征曲线。
4)三维人体数据库。含有多个三维人体模型的数据集,模型采用多边形网格或点云表达,以下简称人体数据库。
5)三维人体分割数据库。是对三维人体数据库进行对象分割,以下简称分割数据库。
6)三维人体骨骼数据库。是对三维人体数据库进行骨骼抽取所得数据库,以下简称骨骼数据库。
7)三维人体语义特征数据库。是一种三维人体模型数据库,模型标记了语义特征采样点,简称特征数据库。
8)模板模型。预处理过的人体模型,包含语义特征、分割信息和骨骼。
9)参数化人体模型。指已标注特征曲线的人体模型,可通过计算特征曲线的长度得到人体模型的语义参数。
1.2 总体流程
算法的总体过程分为人体数据库扩展和语义特征提取2个步骤。首先介绍核心部分——语义特征提取。
1.2.1 语义特征提取
本文提出的方法基于模板匹配算法,总体流程分3个步骤:模型预处理、模型配准和拟合与计算。
1)模型预处理阶段。模板模型来源于三维人体语义特征数据库,数据库中有多个不同姿态、不同体型的人体模型,选择合适的人体模板模型是准确匹配输入模型和减少迭代次数的关键。为减少后续步骤的计算量,选取的模板模型应尽可能与输入模型相似。选取模型模板的主要依据是模型的姿势,需借助骨节点坐标衡量,因此需要对三维人体数据集中的模型进行骨架提取[1]。
2)模型配准阶段。为减少非刚体配准过程中迭代次数,先对模板模型和输入模型进行刚体配准。配准完成后,模板模型逼近输入模型且保持了拓扑结构。
3)拟合与计算阶段。使用NURBS曲线拟合配准后模板模型的特征采样点,形成特征曲线,计算特征曲线长度,得到输入模型的语义特征参数。整个提取过程的流程如图3所示。

图3 特征提取算法流程
1.2.2 人体数据库扩展
在1.2.1节中提到模板匹配阶段需要预先选择模板模型,而模板模型来自于特征数据库。特征数据库的构建基于开放数据集MPI[15]人体数据集。MPI数据集包含114个人体模型,使用时,从中剔除姿势过于复杂扭曲的人体模型。每个人体包含35个姿态,每个模型有6449个顶点和12894个三角面片,所有模型拓扑一致。样本数据如图4所示。

图4 MPI三维人体样本数据
人体数据库的扩展过程依次构建3个数据库:模型分割数据库、骨骼数据库和特征数据库。人体数据库中的所有网格模型拓扑一致,因此对其中一个模型操作即可将结果应用于整个数据库,此过程是半自动化的,流程如图5所示。

图5 人体数据库扩展过程总体流程
1)拓展分割信息和人体骨骼的过程。首先对人体模型进行形状分割;然后将相邻2个分割块的边界中心作为一个骨骼节点,按照一定的顺序连接这些节点,形成人体骨骼;最后,将这些分割扩展到整个数据库,并抽取骨骼,形成三维人体分割数据库和三维人体骨骼数据库。三维人体分割数据库是中间数据,骨骼数据库主要用于特征提取过程。
2)拓展语义特征的过程。首先,标记一个模型的语义特征采样点;然后将采样点扩展到整个数据库;最后,对每个模型的采样点使用非均匀有理B样条(Non-Uniform Rational B-Spline, NURBS)拟合,得到特征曲线。语义特征在样本上的示意图如图6所示。

(a) 特征采样点 (b) 特征曲线
1.3 核心算法
在数据库扩展阶段和特征提取阶段涉及形状分割、骨骼抽取、模型配准等算法。
1.3.1 形状分割
形状分割采用基于平面约束(Constrained Planar Cuts, CPC)[16]的算法,目标是分割出有意义的对象,例如人的肢体。算法的优点在于摒弃额外的训练过程,自底向上地将三维模型分割成有意义的部分。核心思想是生成附带凹凸信息的点云,并且在“凹”的点云上拟合出切割平面。针对出现“过分割”的情况,作者提出2种“修补”方法:权重引导方法和局部约束方法。权重引导方法中,垂直于凹边表面的点具有更高的权重;局部约束方法中先对凹点进行欧氏分割限制切割面的增长上限,再对子域进行分割。图7展示了分割算法的测试结果。图8是CPC算法在本文数据集上的测试结果。

(a) 邻接图 (b) 从邻接图中提取欧几里得边缘点云以及点权重 (c) 用第1个平面切割结果
图7 CPC算法测试结果

图8 CPC算法在本文数据集上的测试结果
1.3.2 骨骼抽取
从分割过的模型中抽取骨骼信息步骤:每2个分割部件交界中点构建一个骨节点,按照一定顺序连接这些骨节点,形成模型的骨骼。骨骼抽取示意图如图9所示。

图9 骨骼抽取示意图
1.3.3 模型配准
模型配准是将模板模型向输入模型变形的过程,让三维人体模板模型拓扑结构不变而使姿态和体型向输入模型逼近。在1.2.1节中提到,模板模型来源于语义特征数据库,而数据库中有多个人体模型,为提高算法的运行效率,本文采取了以下加速方法:
1)选取合适的模板模型,模板模型的姿态和输入模型尽可能相似,本文使用骨骼的相似性衡量模型的相似性,具体在1.3.3.1节详述。
2)进行刚体配准,变形之前调整模板模型的朝向、位置,让输入模型和模板模型在世界坐标空间中重叠。刚体配准过程在1.3.3.2节详述。
1.3.3.1 计算骨骼相似性
计算输入模型与特征数据库中的模型骨骼相似性,选取相似性误差最小的模型作为模板模型,本文定义相似性误差Se为:
(1)
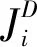
1.3.3.2 刚体配准
刚体配准分为2个步骤:1)方向包围盒对齐;2)采用迭代最近点算法[17]刚体配准的迭代配准。
1)方向包围盒对齐。

(2)
(3)

(a) 仿射变换前 (b) 仿射变换后图10 方向包围盒对齐
2)迭代最近点算法刚体配准。

(4)


(a) 配准前 (b) 配准后图11 迭代最近点配准
1.3.3.3 非刚体配准
非刚体配准的目标是让模板模型尽可能逼近输入模型,采用构造最小化能量函数的方法。采用Allen等人[18]的方法进行人体网格变形实验,当模板网格和目标网格差异比较大时,该方法失效,如图12所示。观察图12(c)可以发现,在手臂和小腿出现了破损的面。图13为本文算法在数据集上的测试结果,测试多个模型后,发现本文算法在数据集上表现良好。
(a) 模板网格 (b) 目标网格 (c) 采用文献[18]算法变形后的网格图12 文献[18]算法测试结果

(a) 目标三维模型

(b) 变形得到的三维模型图13 本文算法在数据集上的测试结果
1)拉普拉斯网格变形。
本文提出用拉普拉斯(Laplacian)网格编辑算法替代Allen等人[18]的标记点误差项,分别在模板网格和目标网格上选取56对一一对应的标记点,作为Laplacian网格编辑中的标记点。变形后,标记点从模板网格中的坐标位置变到目标网格中的坐标位置[19]。
本文使用Kwok等人[20]的选取特征点软件Add_FP,使用该软件可以手工选取顶点,并导出顶点的序号索引和坐标位置。顶点(关键点)示例如表1所示。

表1 关键点格式示例
在模板网格和目标网格中分别手工标记一一对应的标记点并尽量保持标记点的位置对应。例如在模板网格上,标记点在外腹斜肌中间位置,那么在目标网格上也应该标记在外腹斜肌的中间位置,如图14所示。
图14 关键点标记示意图
(5)
2)数据误差和光滑度误差。
在前面提到本文方法借鉴了Allen等人的方法,但是屏蔽了标记点误差,利用标记点进行了粗略的网格变形,变形后模板网格姿势与目标网格姿势相同。为了使模板网格的体型与目标网格也相同,本文引入数据误差和光滑度误差。
数据误差项表示的是变形后网格的顶点与目标网格顶点间的距离之和,当距离之和越小时,说明二者匹配得越好。数据误差目标函数Ed定义为变形后网格的顶点与目标网格顶点间的距离平方和,计算公式如下:
(6)
仅使用数据误差,会导致变形后的模型表面凹凸不平。为解决该问题,本文引入了光滑度误差。光滑度误差Es定义为模板网格上相邻顶点仿射变换之差的F范数,计算公式如下:
(7)
其中,‖·‖F为弗罗贝尼乌斯范数,弗罗贝尼乌斯范数定义为:
(8)
通过极小化邻接顶点变换的差异,保留了邻接顶点之间的光滑性。
3)合并误差项。
最终目标函数定义为:
E=αEd+βEs
(9)
其中,α、β是权重参数,求解该目标函数的最小值,就可使变形后的模板网格和目标网格贴近,并且使变形后的目标网格保持光滑。
(10)
对上式Ti中的每一个元素求偏导数,令偏导数的值为0,求解偏导函数,即为使目标函数极小的变换矩阵。然后对模板网格中的每个顶点施加对应的变换,就可以得到最终的变形结果。
1.3.4 非均匀有理B样条逼近
非均匀有理B样条的光顺和逼近技术是NURBS曲线曲面造型中应用最为广泛的技术,是根据一系列型值点通过一定算法得到满足逼近精度和光顺程度的NURBS曲线,如图15所示。本文采用的是兰浩等人[21]提出的算法,是基于能量优化的整体光顺逼近算法,在给定若干型值点坐标和逼近误差限ε的条件下,拟合出满足逼近误差限且光顺度较好的3次NURBS曲线[10]。

图15 NURBS曲线逼近示意图(胸围曲线)
为拟合出符合要求的NURBS曲线,并且具有较高的逼近精度和光顺度,兰浩等人[21]定义了目标构造函数:
f=α·f1+β·f2+γ·f3
(11)
其中,f1为逼近项,用来使曲线尽量靠近型值点;f2为光顺项,用于控制曲线的光顺度,通过限制离散点的“曲率和”使整条曲线和趋于最小;f3也是光顺项,但是其作用是使整条曲线的曲率变化均匀。α、β、γ是加权系数,合理的设置加权系数可以使得f1、f2、f3取得协调的组合,从而得到拟合精度、光顺度都较好的曲线拟合效果。
2 实验研究
2.1 实验数据
本文的实验材料一部分来源于MPI数据集,另一部分来源于自行扫描所得人体模型。
自行扫描的实验数据采用精迪非接触式三维人体扫描设备扫描,扫描精度>1 mm。扫描模型有165525个顶点和331054个三角面片。扫描模型比MPI数据库模型顶点密度高、精度大,但是由于扫描角度问题,扫描人体头顶和脚底存在数据缺失,在网格模型上呈现破洞,在进行特征提取前,需要将数据补齐。图16展示了未经数据补齐的模型和补齐后的模型,这些补齐后的模型将作为测试数据。

图16 未经数据补齐的模型和补齐后的模型展示
注:①自行扫描人体数据 ②头部数据缺失 ③头部数据补齐 ④其他实验数据
在MPI数据集中选取7个人体模型作为测试数据,真实语义特征由MPI数据集提供。将3个自行扫描模型作为测试数据,真实语义特征由专业量体师提供,将10个模型编号,模型编号采用S+试验者号+P+姿态模型的格式表示,例如S1P1模型和S1P3模型分别表示1号试验者的1号姿势模型和3号姿势模型,S2P2和S3P2分别表示2号试验者和3号试验者的2号姿势模型。实验模型由表2列出。

表2 实验模型数据
2.2 实验设计

(12)
(13)

使用标准差函数sl刻画单个特征误差的标准差:
(14)
其中,μl为算术平均值。
2.3 实验结果和分析
按照上述实验模型数据设计进行实验,对10个实验模型提取语义特征,S1P1模型的原始数据及误差如表3所示,实验数据的测量值与真实值的误差及时间如表4所示。从图17的实验数据可知,本文算法提取的语义特征准确度较高,误差在[-2.1%,+2.1%]内,标准差在2%以内。

表3 S1P1模型原始数据及误差

表4 测量值与真实值的误差及计算时间

图17 误差分析
根据近年来国内外对特征提取的相关研究,对各个特征的平均误差和整体计算时间进行了对比,如图18所示。文献[11]给出的基于图像和局部的随机森林预测方法的准确性小于本文方法,但在时间上更快;文献[12]给出的是一种基于二维图像的方法,这种方法计算速度快,计算时间在0.1 s内,效果与本文方法相当,文献[13-14]所提出的方法误差较大。经比较可见,本文方法在效率上较好,误差较小,综合水平好。另外,本文提出的基于模板匹配的方法能够提取多种姿态下的语义特征信息,相对其他方法应用更加广泛,具有更高的灵活性并能为人体动画、服装定制等提供更多参考数据。
3 结束语
本文提出了一种新颖的基于模板匹配的语义特征提取算法,首先构建了模板数据库,然后选取合适的模板和输入模型配准,利用模板的拓扑一致性,拓展语义特征采样点,最后使用NURBS曲线拟合采样点,计算曲线长度,得到特征信息。经过实验验证,本文算法提取的特征误差在2%以内,准确度高,效率较高,满足了大多数情况下对语义特征的需求。后续工作将在实时性方面做进一步完善,在目前的数据积累基础上对人体语义特征的统计特性做进一步分析。

图18 多种方法在各特征平均误差及计算时间的比较
