基于社交数据挖掘的心理健康预警建模与分析
2020-04-23林靖怡黎大坤吴平鑫王旭周燕
林靖怡 黎大坤 吴平鑫 王旭 周燕
(华南农业大学数学与信息学院 广东省广州市 510642)
1 问题背景
当今世界处于激烈竞争的时代,经济发展不断加速,生活方式急剧变化,人际关系日益复杂,从而造成了各种心理疾病发生率的日益增多。当代大学生作为具有较高智力、较髙文化和较髙自尊心的群体,有着不同于一般青年的更高抱负和追求,面临更多的机遇和挑战,因而也承受着更大的心理压力和冲突。据教育部门有关调查显示,较多的在校大学生存在着不同程度的心理问题,因心理健康问题引发的大学生一系列恶性事件。2017年,大学生自杀事件接连出现。1月11日,山东大学一名女生被发现在出租屋内上吊自杀,被发现时已身亡四天;2月27日,广西大学一名在读研究生烧炭自杀死亡;3月4日,渭南职业技术学院农学院一名大二学生在宿舍内上吊身亡;事件频发,心理健康是主因。因此,各大高等学校也越来越重视学生心理危机的监控和预防工作,并积极构建心理测评与筛查系统,建立心理数据档案。
我国许多大学新生在入学一个月内都进行人格问卷(UPI)调查或者心理健康测评(SCL-90)。然而,自编的问卷达不到广泛应用的标准程度,且大学生心理健康会随着环境变化和所面临的挫折而具有波动性。学生管理工作人员只保存这些静态的数据,而不及时更新以了解学生进入大学后的心理健康状态趋势,对大学生心理健康危机的预防起不到重要作用。而在2012年,一名昵称为“走饭”的微博用户在发布了一条遗言微博,引起轰动。她以往的微博内容中揭示出她有严重的心理问题,同时说明了大部分学生都会在社交网络上发泄更真实的情绪。所以,基于此背景下,本项目利用社交数据预测学生群体的抑郁倾向,具有较强的解决实际问题的意义。
2 数据分析
2.1 抑郁和非抑郁用户的选取
在2012年,有一名昵称为“走饭”的微博用户发了一条遗言微博,随后并自杀身亡。她的最后一条微博在当时引起轰动,众多网友相继转发。“走饭”是一名女生,自从她去世,许多抑郁症患者会在她的最后一条微博下评论诉说自己的痛苦。本文以此为突破口,在评论中及走饭超话中选取抑郁症状明显的微博用户作为抑郁用户。为确保数据来源的可靠性,人工筛选发言中有明确提到“确证抑郁症”等的用户。同时,本文在热搜评论中选取非抑郁用户。由于抑郁用户与非抑郁用户在语言上会有明显差异,人工筛选时仔细甄别微博用户多条微博的用词,保证非抑郁用户数据的真实性。最后确定了149 名抑郁用户和234 名非抑郁用户。
2.2 数据获取及预处理
2.2.1 数据获取
我们获取的数据主要为抑郁用户和非抑郁用户的一定数量的微博正文及基本信息,我们获取微博正文的方法为网络爬虫(网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF 社区中间,更经常的
称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫)。按照网络爬虫的步骤,我们首先分析了网页结构,然后发现分布规律并从中找到微博正文的位置,最后选择适当的爬虫工具爬取到对应的数据。网络爬虫最终生成对应用户微博内容的txt 文件,命名是昵称和ID 号的组合。
2.2.2 数据预处理
在预处理过程中,主要是数据清洗,去除一些不需要的数据,并添加标签。因此本文进行了以下处理:
(1)过滤掉微博话题的内容,如#微博热门话题动态#,微博话题并非用户表达出来的,为避免影响微博内容的分析,将其去除;
(2)过滤掉图片、链接的信息,本文针对的情感分析是文本内容,这些信息会影响分析,因此去除;
(3)过滤掉用户转发的内容,认为转发的内容不能准确描述用户的心理状态,如果过滤转发内容后仅剩“转发微博”,则过滤掉本条微博;
(4)将性别转换为独热编码,“男”为1,“女”为0;
(5)添加人工标签,“抑郁用户”为1,“非抑郁用户”为0。
2.2.3 情绪分析技术
情绪分析的步骤为:
(1)对将要进行分析的微博正文进行分词;
(2)用对应的抑郁词库和非抑郁词库对分好的词进行统计分析;
(3)计算该微博的情感值。
在此我们选择用Python 中的SnowNLP 第三方库进行分词和情绪分析,SnowNLP 是一个python 写的类库,可以方便的处理中文文本内容,是受到了TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob 不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。不过,SnowNLP中的情感分析主要是用于商品评价的分析,并不符合我们所需要的关于个人心理状态的分析,因此我们爬取抑郁超话和抑郁症超话中的内容作为抑郁词典,然后随机爬取微博内容作为非抑郁词典,因为我们认为抑郁用户仅占人群的一小部分,微博中普遍文本来自非抑郁用户的。我们对抑郁词典和非抑郁词典都进行了数据清洗,并保留了表情字符,以此提高对微博表情和网络热词的分析能力。然后用SnowNLP 库中本身带有的sentiment.train 和sentiment.save 方法进行新的训练,实现新训练集的生成和保存,最后实现对于微博正文的情绪分析。情感分析所获取得到的情感值的范围为0 到1,情感值越接近0,则表示用户发该条微博内容的心理状态接近抑郁,越接近1 的情况越接近正常。下面以用户“走饭”在上图中的微博内容为例,对其进行情绪分析,得出相应的情感值。
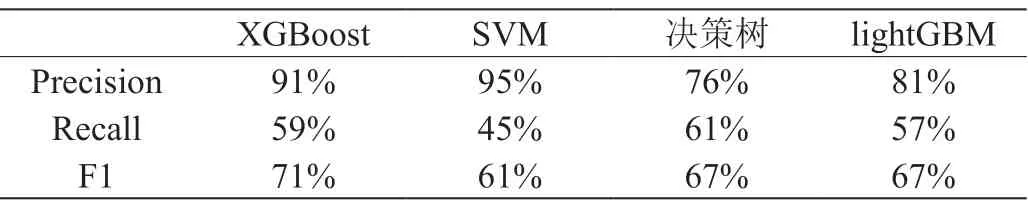
表1

图1:非抑郁用户的词云

图2:抑郁用户的词云
(0.0 11 8 3 3 3 9 9 5 8 7 3 4 0 0 8 8,6.5 8 8 5 1 4 7 8 0 3 1 4 6 3 6 e-0 5, 0.5806662157427955, 0.0036783454087553347,0.0264076 6065997402,0.1290528045904359,0.015297355613529295, 0.008188068840033536)
由此可以看出这些微博正文中大部分是比较消极的,与原本的微博正文较为吻合,本情感分析技术是可信的。
3 基于情绪词典的预测模型
3.1 特征选取
个人特征:性别、粉丝数、关注数、总转发数、总评论数、总点赞数。
在获取的数据中可以得到如性别、微博等级、微博说明、粉丝数、关注数等个人信息,从这些个人信息可以挖掘出用户的社交特点,并深入了解到用户的心理状态。本文最终选择了与社交状态密切相关的性别、粉丝数、关注数、总转发数、总评论数、总点赞数。
语言特征:多条微博内容的情感值的上、下四分位数及中位数。
个体的语言是带有个人色彩的,而在不同的心理状态下,用词也会有所不同。本文随机抽取抑郁用户和非抑郁用户的部分微博内容(如图1 和图2 所示),发现非抑郁用户的微博内容涉及方面很多,感情层次丰富,而抑郁用户的微博内容呈现出一种恐慌、脆弱的状态。因此极具用户语言特点的微博内容是情感分析的主要对象,因此为了更好地了解用户的心理状态,预处理过程中剔除了微博内容较少的用户,避免出现被较极端的微博影响分析结果的情况。利用前面构建的情感分析模型对微博内容进行分析,得出用户的情感值上、下四分位数及中位数,这里没有选用更常用的平均值和最值,因为我们并不了解抑郁用户的情感波动情况,中位数能比平均数更体现集中趋势,四分位区间也更能描述离散程度。
3.2 实验结果及分析
本文将数据集按7:3 的比例随机划分了训练集和测试集,选择了XGBoost、SVM、决策树、lightGBM 等算法构建了不同的分类器,分别得到如表1 结果。
其中,精确率反映了各分类器判定的抑郁用户中真正抑郁用户样本的比重,体现了分类器对非抑郁用户的区分能力;召回率反映了被正确判定的抑郁用户占总的抑郁用户的比重,体现了分类器对抑郁用户的识别能力。由于精确率和召回率是相互影响的,通常精确率高,则召回率低,或是精确率低,则召回率高。因此我们需要借助F1 值在这两者之间找到一个平衡点,F1 值越高,则说明模型越稳健。
综合各分类器,本文认为XGBoost 效果最好,其次是lightGBM和SVM,最后是决策树。
4 总结
本文实验结果表明,基于情绪词典的XGBoost 模型具有较好的识别效果。而本文利用社交数据来预测微博用户的抑郁倾向,具有一定的实际意义:可快速而及时地发现有抑郁倾向的人,能够及时发现目标,为有效的干预和帮助提供了非常好的基础;考虑到在线社会网络的用户规模和年轻的学生用户居多的特点,使用这种方法将能发现数以百万计受到抑郁症威胁的人群。尤其对于在线社会网络普及率很高的高校学生来说,用本文提出的方法进行抑郁症问题状况评估是合适的。本方法将极大地提升高校等机构应对学生抑郁症问题的能力,从而减少抑郁症对学生群体造成的伤害。
由于本文的情感分析技术仅针对文本内容,对图片内容无能为力,难以分析微博用户发布的图片中的情感。虽然在构建词典时保留了微博表情,但有时表情会被人们用来表达多重意思,给用于训练的词典提出了非常高的要求。同时在特征工程中,过少的特征向量也限制了分类模型的分类效果。以上种种都是本模型有待改进的地方。
