汉维双语平行词汇语料库构建技术研究
2020-04-22祖力克尔江艾孜海尔江艾孜尔古丽
祖力克尔江 艾孜海尔江 艾孜尔古丽
摘要:该文主要研究双语平行词汇语料库为目的研究翻译插件技术及方法,并进行探讨。首先陈述双语平行语料库构建进展和研究技术及方法;其次介绍汉语语料形成方法;探索通过引入API翻译插件完成读取一翻译一写入的语料词汇翻译对齐工作,并通过人工校正后生成汉维词典;最后通过实验,分析方法的可行性和可靠性。
关键词:双语;词汇;翻译技术;双语词典
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2020)06-0202-03
在“人工智能”“大数据处理”领域开展自然语言处理工作对大量对双语资源库和语言知识库的需求越来越大,对资源知识库的构建工作越来越重视。在现实生活中语言成为我们交流发展之间最大的障碍,这个问题在社会交流过程中尤为突出,影响人们的生活、学习、工作。为解决语言沟通问题,就需要一个可靠的汉语一维吾尔语机器翻译系统,完成这样一个完整的汉语维吾尔语翻译系统就需要大量的基础工作作为支撑,汉语一维吾尔语双语资源构建对汉维机器翻译起了重要作用。本文的主要工作就是研究汉语一维吾尔语机器翻译系统的基础部分之一——汉语一维吾尔语双语资源库的构建。
目前国内随着统计机器翻译的发展,多种不同的翻译方法相继被提出:基于词的翻译模型,基于短语的翻译模型,基于形式句法的翻译模型,基于句法的翻译模型等。本文采用目前工业界和学术界中广泛使用的层次短语模型(基于形式句法)。在统计机器翻译过程中,词语对齐为机器翻译的关键。词语对齐利用大量双语平行句对,依靠无监督的统计信息,自动对双语平行句对进行词对齐。常用的工具为根据IBMmode实现的GIZAG++。不管使用什么方都法离不开词对齐资源的支持。真实语料需要经分析和处理,才能成为有用的资源。世界上第一个网络检索工具Web Crawler于1994年诞生,目前家喻户晓的主流搜索引擎有Google、Baidu、搜狗和LiveSearch等。为了获取双语平行语料,一个最重要的条件是有双语知识,也可以理解为双语互译词信息,双语互译词是一个宝贵的资源,因此本文重点研究双语词典的获取技术问题。
本研究采用网络爬虫技术、网页正文提取技术、文本预处理技术等文本采集和加工技术,开展双语语言资源获取。除了对齐技术、术语提取技术等外,还有文本分类技术、去重技术、句子边界识别等技术,服务于语言资源知识库建设。该成果将在自然语言理解、机器翻译、人工智能、大数据分析、语言模型构造等方面广泛应用。
本研究选择网络媒体语料作为汉语词汇资源库语料,使用Python编程工具快速有效地生成汉语一维吾尔语对照词表,并经过后期人工校对,形成汉语一维吾尔语双语词汇资源库。对后期的汉语维吾尔语机器翻译系统开发奠定基础,这对学习国语也有很大的帮助,提高其交流水平,以减少沟通障碍。因此,构建汉语维吾尔语词汇双语资源库具有重要意义,服务于决胜全面建成小康社会,实现最伟大的梦想。
1汉维双语文本语料获取技术研究
1.1语料获取
在双语平行词汇语料库构建过程中,为建设汉一维双语词汇资源库,利用Scrapy爬虫框架爬取“天山网”(网络媒体语料)中的汉语语料,通过汉语分词处理系统形成大量汉语词汇语料库。
1.2语料预处理
处理初始语料遇到以下几种问题,
(1)编码问题,根据不同情况会遇到汉语语料的编码格式问题,主要是uff-8与gbk直接的相互转换,这个问题读取和写入时用python代码来处理。
(2)替换某些特定字符,需要替换字符的时候使用自己编写脚本进行替换。
(3)去除数据中不是文本的部分,主要是针对爬虫收集的语料数据,由于爬下来的内容中有很多html的标签,需要删除这些标签。对爬取的页面用X-path来进行页面分析提取题目,作者,发布时间,正文。提取的文本里有少量的标点符号,这些多余的标点符号则用正则表达式删除。
2翻译插件技术研究
2.1研究思路
随着社会发展,特别是科学、互联网信息的快速增长,人们的生活、工作及学习方式逐步适应新的生活、工作、学习方式,现有的双语对照标准词汇资源库,靠人工处理不能满足人民生活、工作及学习需求。为了适应人民现代生活、工作及學习需求,为了利用好互联网资源,本文研究翻译插件技术,自动、动态的增加双语对照标准词汇资源库的词汇,满足人民不断产生的新时代生活、工作、学习需求。
首先使用自己开发的爬虫软件收集汉语网络媒体文本语料,再进行预处理,以文本形式保存,并构建汉语文本电子语料库;其次利用汉语通用的分词软件,对文本进行分词,构建汉语单语词汇表;通过翻译插件技术,构建汉维双语对照动态标准词汇资源库。
2.2翻译器模型
随着机器翻译技术的兴起,市面上出现了大量具有不同功能、适应不同环境、满足不同需求的词典或翻译软件,其中应用比较广泛的有谷歌翻译、有道翻译、百度翻译。三大主流翻译软件都为用户提供了免费或有偿的应用程序接口(API),这三种翻译工具除了应用环境不同以外,所包含的语言数量也不同。谷歌翻译包含语言种类有104种,有道翻译包含语言种类有23种,百度翻译包含语言种类28种,其中有道翻译和百度翻译所包含语种多为国际主流语言,而谷歌翻译除了主流语言以外还包括了许多非主流语言,这就为许多语言研究者提供了便利,研究者可以通过调用翻译插件快速处理问题。本文主要研究基于翻译插件的汉语一维吾尔语的双语词汇资源库构建技术。
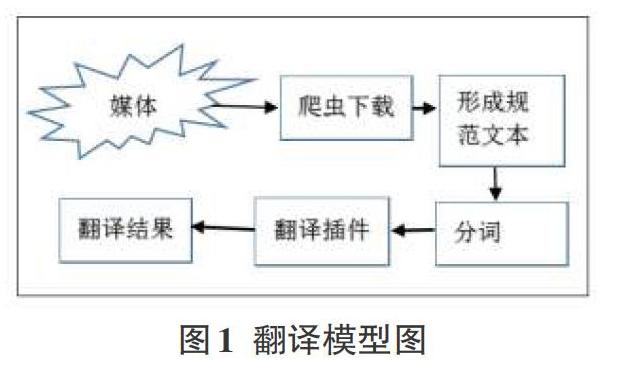
本次研究核心算法主要是通过循环依次读取语料词汇表中的已处理词汇;然后通过引入的互联网搜索引擎技术搜索符合翻译需求的资源;通过翻译插件翻译,对读取词汇依次翻译生成翻译结果,其中这一翻译过程,为防止出现因访问频繁而导致翻译失败或禁止翻译,采用词汇阶段方法,在每个阶段翻译结束后使翻译程序强制调整,调整结束后再进入下一个阶段的词汇翻译;最后将翻译生成结果,通过正则表达式获取正确翻译结果,并依次输入到其对应词汇的下一列单元格。其构建模型如图1所示。
2.3翻译器的实现
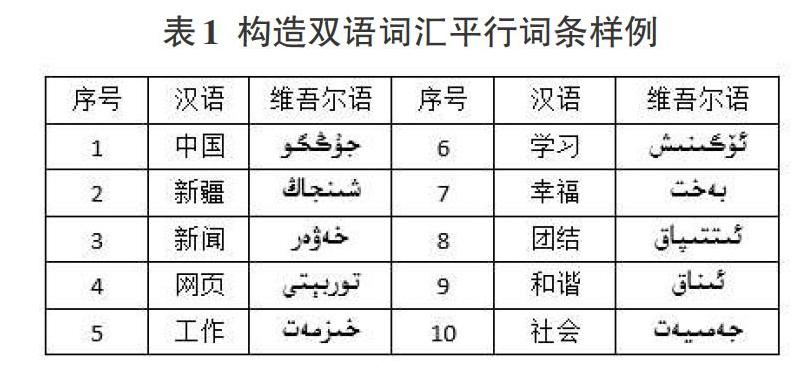
构建对齐双语词汇库流程:按顺序在汉语词汇表中读取词汇;将读取内容利用程序调用搜索引擎模块,搜索对应的API翻译插件对齐翻译;将翻译结果写入词汇表中与翻译内容对齐位置,构建对齐双语语料。由上述方法构建而成的对齐双语词汇库实例结果如表1所示。
在完成自动生成汉维对照词表的过程中,所遇到并需要解决的问题主要集中在数据从读到翻译再到写入方法的实现上。首先是对表格的读取,通过读取表格方法读取表格数据,写人数据到表格;其次是完成翻译过程,翻译过程主要采用的是引入搜索引擎找到需要的API翻译插件,通过编程模仿用户进行翻译行为,并获取翻译结果。具体实验中发现,翻译过程中出现翻译过于频繁导致翻译中断或主机被禁。针对这个问题,采用大规模词汇翻译时利用分段处理方法词汇翻译为一个阶段,每个阶段之间强制程序睡眠一段时间。通过反复实验,积累经验基础上,翻译过程中采用50个词汇为一个翻译阶段,每个阶段时间间隔为30秒的实验策略,可以达到快速稳定地自动生成对照词表的效果。
3实验分析
本文使用的语料来源主要是“网站新闻”媒体中爬取的汉语语料,经过公开的分词软件来进行分词,并构建词汇语料库。本文以20万种词汇作为实验对象,进行实验。词汇翻译率85%以上,翻译正确率75%左右,达到预期研究效果。在研究中发现了以下这个问题。
(1)语料来源的动态性。由于本文使用的语料来源“网站新闻”媒体,更新速度快,静态翻译平台无法适应产生的新词汇,影响翻译率的提高。
(2)翻译平台提供的资源有限。由于是从网络媒体上爬下来,会出现一定规模的未登录词,影响翻译率的提高。
(3)翻译平台提供的资源中具有一个词汇多种翻译的现象,导致翻译正确率不太高。
中英平行语料对齐技术以及机器翻译技术相对成熟。在进一步研究汉语一维吾尔语平行语料库以及机器翻译时,可以借鉴这些成果,采取多种方法,使用智能技术手段提升汉语一维吾尔语平行语料库及机器翻译质量。