数据库中自动生成数据的存储过程设计
2020-04-22肖连
肖连


摘要:简要说明数据库中存储过程的作用,接着根据系统开发的需要和功能需求,主要从自动生成数据功能的角度,说明了在存储过程中个人信息注册时性别、出生年月、籍贯、工作地点等字段的生成方法。根据需要,设计数据自动生成的存储过程,将数据插入数据库中,并以个人信息的自动生成为例,给出了参考示例。通过三个存储过程的设计,将一个简单的聊天通信软件所需要的数据模拟出10万条账户信息,并建立他们之间的好友关系,从而为系统测试数据提供基础条件。通过示例,展现存储过程在基础数据自动生成方面的应用。
关键词:存储过程;自动生成;模拟数据;示例;sQLServer
中图分类号:TP311.1 文献标识码:A
文章编号:1009-3044(2020)06-0018-04
1背景
存储过程(Stored Procedure)是SQL语言编程。存储过程结合各数据库的特点,应用SQL语言编写的,能完成一定功能的程序。存储过程具有执行效率高,可重用性、可移植性、可维护性、提高安全性等功能。在知名的关系型数据库中,都设有存储过程的技术。存储过程分为三种:系统存储过程、扩展存储过程和用户自定义存储过程。系统存储过程在SQL Server中大多数以sp-或xp_開头,是系统预编译处理好的程序,它们执行时能完成一定的功能,供使用者调用。扩展存储过程是指在数据库环境之外,使用编程语言(如C++)创建的外部例程形成的动态链接库(DLL)。用户自定义存储过程,是由用户编写的完成用户所需要设计的一些功能。比如,用户开发的系统运行速度有待提高,跟数据库方面的连接有待及时响应,这时,往往需要利用存储过程来进行提高效率。
存储过程的作用一般是为了减少浏览器端与数据库服务器端的数据传输,具有提高系统运行效率的功能。存储过程对数据进行了预处理,减少了数据传输,并且,存储过程有一次编译,多次运行的特点。一个好的系统里往往会有多个存储过程的设计。存储过程和它们所在的数据库是一起存放的,而且存储过程使用灵活方便,由于在功能上的优势,往往一个系统中自定义函数设计没有存储过程使用多。
除了提高系绕性能的作用外,存储过程还能完成一些数据的预输入功能。在系统的开发和测试阶段,往往需要一些数据,较少的数据可以采用手动的输入方式,而系统在投入之前需要完善的测试,尤其是抗压能力的测试需要模拟大量的数据,此时,采用手工输入的方式是不太现实的。此时,我们可以利用存储过程生成一些系统需要的数据,进行数据库中数据的添加;在教学过程中,涉及数据库设计,也往往需要添加大量数据,如果采用手工添加方式,容易造成数据出错,操作疲劳等问题。可以在数据库中添加相应的存储过程,完成初始数据的添加工作,为系统的使用打下基础。文献[1][3—6]分别从不同的角度来叙述存储过程的功能和作用,但是未涉及实际应用中存储过程随机数据的生成。
2存储过程设计
在实际应用中,根据系统功能分析,进行E-R设计,根据转换的数据模型,建立相应的数据库系统,建立表结构。系统的运行中,表中需要大量的数据,我们就可以考虑采用编写存储过程的方式,在需要数据时,让系统自动生成数据。下面以添加个人注册信息为例进行分析。在各大网站进行信息注册时,我们往往需要提供注册者的籍贯,账号一般根据系统的自增字段来自动生成,籍贯信息,就涉及省、市、县,这些信息我们在注册时,往往由级联列表框来实现,个人注册时,由操作者按需寻找所需要的籍贯,选择即可,可是对于一个新开发的系统,当需要大量的数据去做测试时,这些数据的输入就是一个体力活了。那么,利用关系型数据库中存储过程的特点,我们可以编写一个自动生成一些测试数据的存储过程,完成系统数据的自动生成。
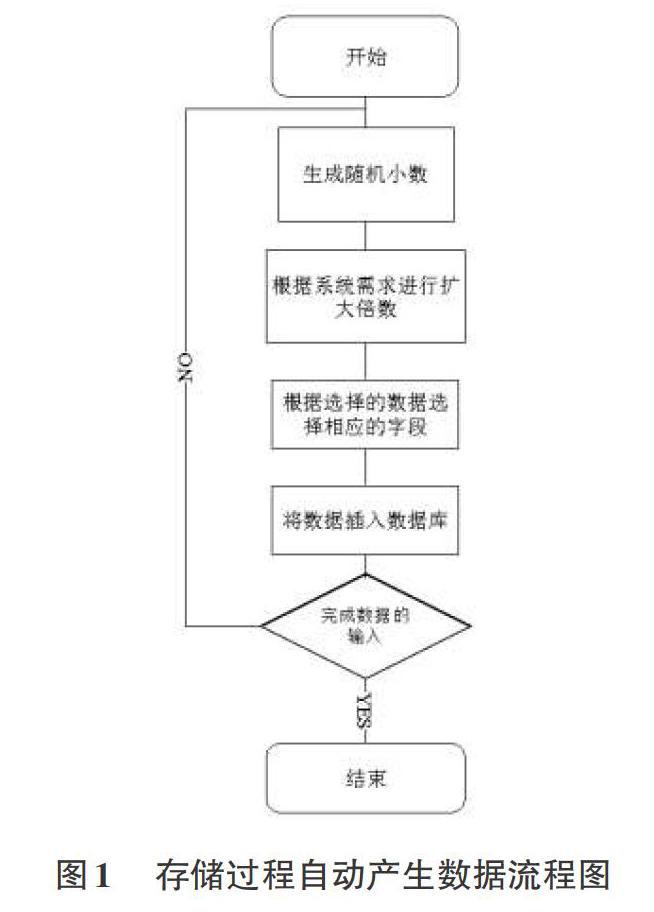
系统设计存储过程采用一个随机数的值,可以根据随机数的特点,来生成数据。数据表的主键字段,采用数据信息插入的先后顺序,最小值从10000开始;第二个字段是性别字段,由于只有“男”、“女”两个值,那么我们就可以将生成的随机数直接截取两段进行赋值;第三个是籍贯字段,就需要先根据随机数选择省,然后再选择市。根据所得,最后进行数据的自动插入操作。具体流程图如图1所示。3存储过程示例
根据上面的分析,设计不带参数的存储过程my_procl如下,该存储过程随机产生数据100万条,在基于x64的操作系统windowsl0,主频2.4GHz,内存为8GB,SQL Server2008企业版的环境下,执行时间约400秒。其中的一些参数是根据需求反复调试确定的,对于某些因子不能太小,小了就影响表示效果,也不能过大,过大了还需要求余处理。比如生成出生年月的时候,将一个浮点型值用cast函数转换为日期型数据时,日期型数据必须符合系统的实际需求,系统经过多次测试确定了50000这个因数。示例代码如下所示:
其中省市的自动生成流程为:
1)生成随机小数;
2)根据生成的随机小数,产生1-34之间的随机整数,根据此值确定省的值;
3)根据生成的随机小数,和确定的省份的值,产生相对应的随机整数,根据此值确定市区值。
采用此种方式生成的省市值类似于注册时生成的自动联动的下拉式菜单确定数据的方式,若需要进一步确定城区,县,镇,村等信息,可以继续采用随机数进行联动的方式。
存储过程编写完毕,可以直接执行:
exec my-proc 1
生成数据。此处举例为不带参数的存储过程,具体应用时,可是选择参数的设置,比如,产生的数据量大小可以以参数的形式传进去,对数据的某些要求也可以以参数的形式进行设置。
根据上面生成的用户注册的信息,通过下面的存储过程rny-proc2可以生成每个用户所对应的表,用来记录,用户下面的好友信息,具体代码如下所示:
通过语句exec my_proc2对用户表中的所有账号建立了相应的用户账号表,采用游标,对用户表进行读取,由于存储过程能直接使用DDL语言,因此,可以顺序创建用户账号表,用来记录用户里面的好友信息。
基本的用户表生成完毕,下面还可以利用存储过程生成好友信息表,让用户之间建立联系。模拟聊天通信软件中的互加好友的功能。部分代码示例如下所示:
执行exec my_proc3.就可以自动随机建立好友关系。以上模拟聊天通信软件的数据库,通过3个存储过程就建立起来所需要的数据,在此基础上就可以进行数据库中数据的应用了。
4结束语
本文首先说明存储过程的作用,基于系统开发的需要,往往需要模拟数据,这些数据靠人工方式输人一方面数据量大,需要周期长,另一方面容易造成数据错误。根据系统功能需求,主要从生成模拟数据功能的角度,说明了存储过程生成个人信息注册时性别,出生年月,籍贯,工作地点等字段的生成方法。然后根据需要,设计数据自动生成的存储过程,并以个人信息的自动生成为例,给出了参考示例。通过三个存储过程的设计,将一个初步的聊天通信软件所需要的数据模拟出10万条账户信息,并建立他们之间的好友关系,从而为系统测试数据提供基础条件。