基于百度网页的中文自动问答应用研究
2020-04-22石凤贵
石凤贵
(马鞍山师范高等专科学校软件工程系,马鞍山243041)
0 引言
互联网是一个庞大的知识库,在浩瀚的知识库中,我们如何索取所需知识?搜索引擎完成了这个任务。百度搜索是全球最大的中文搜索,拥有全球最大的中文网页库,网页数量每天以万级的速度增长。百度提供的服务包括百度网页、百度知道、百度贴吧等。搜索引擎大多以关键词的方式检索信息,不能清晰地理解用户的要表达的意图,返回结果是网页的集合,需要用户进行二次筛选。对于传统的自动问答系统需要建立一个非常庞大的知识库,这个成本相当大。我们可以充分发挥搜索引擎和自动问答的各自优点,有机结合。
本文结合自然语言处理技术和网络爬虫技术,利用百度网页搜索功能,构建自动问答系统。将互联网作为自动问答系统的知识库,通过爬虫技术利用百度搜索对用户问题进行检索,根据检索结果构建语料库,利用自然语言处理技术对检索结果进行答案提取,从而将答案返回给用户。
1 自动问答
自然语言处理(Natural Language Processing,简称NLP)是计算机科学领域与人工智能领域中的一个重要方向,研究人与计算机之间用自然语言进行有效通信,融语言学、计算机科学、数学于一体的科学。问答系统(Question Answering,简称QA)是自然语言处理领域的一个重要应用,具有非常高的使用价值。
1.1 问答系统模型
问答系统模型[1]分为四层,分别为用户层、问题理解层、检索层、数据层:
用户层:即UI 层,提供用户输入问题,显示系统返回的答案。
问题理解层:系统的核心层,负责问题的理解,包括分词、停用词处理、计算相似度。
检索层:负责内容爬取、答案检索,包括信息检索、答案抽取。
数据层:知识库,处理数据库,主要包括专业词典库、停用词库、同义词库、领域本体库、《知网》本体、QA集、互联网。
问答系统模型如图1 所示。
1.2 问答系统核心技术
(1)分词
词是表达句子意思的最小单位。中文语句结构复杂,相对于英文没有明显的标记,不像英文具有明显的分界符。分词是语句理解的基础和关键。常用的方法主要有:基于字典分词算法、向匹配法、基于统计的分词算法、基于理解的分词算法[2]。本文采用jieba 中文分词工具进行分词。
(2)FAQ
FAQ 库(Frequently Asked Question)是把用户经常提出的问题和对应的答案预先保存起来,检索时首先从FAQ 中检索与用户问题相关的问题,从而返回问题的答案。基于FAQ 的问答系统执行效率和准确度相对都比较高,同时也容易实现,比较适合应用于针对特定领域应用的问答系统。
本文为非特定领域应用,借助FAQ 思想,利用爬虫技术爬取标题和摘要,构造问题答案集。
(3)问题分析
问题分析是问题理解的基础,只有科学的分析用户提出的问题才能准确的理解用户问题。问题分析需要通过一定的算法分析,包括问题预处理、分词、关键词提取、消除停用词、词性标注等[3]。
(4)信息检索
信息检索方式包括搜索引擎检索、数据库检索。广泛使用的搜索引擎有百度、Google、360 搜索等。数据库检索需要通过人工整理建立特定数据库,建立索引,选择排序算法进行排序。信息检索的主要目的是通过搜索获取大量文档,返回与问题相关的数据集。
2 相似度计算
2.1 词语相似度计算
字是构成中文句子的最小单位,词语表达句子的含义,是句子语义和句法的基本单位。因此,需要通过计算词语的相似度来计算句子的相似度,词语的相似度也应结合其应用背景。词语相似度计算包含两类:一类是基于大规模语料库;一类是基于语义词典,如《知网》、《同义词词林》。
2.2 句子相似度计算
句子相似度由句子间语义上的匹配度反映,句子相似度计算就是计算两个句子在语义上的吻合度,值的大小决定相似程度,取值为[0,1],值越大说明越相似,反之越不相似。句子相似度计算可以分为:
(1)基于关键词计算:提取句子中的关键词,根据词的词频和词性对句子中的词进行处理。
(2)基于语义依存计算:深层次分析句子的句法结构,根据依存关系计算计算相似度。
(3)基于语义分析计算:构建语义知识库,利用知识库计算句子中词的相似度,从而计算句子的相似度。
(4)编辑距离的相似度计算:分析两个词语转变成相同词语需要的最小步骤。
本文根据句子的词向量的余弦值来计算句子的相似度。
3 问答系统实现关键技术
本文分词采用jieba 分词,相似度计算采用Word2Vec 词向量模型,答案语料库采用网络爬虫构建,系统开发工具采用Python。系统的实现引入了深度学习算法思想。

图1
3.1 网络爬虫
大数据时代,人类社会的数据正处于急速增长。数据蕴含了巨大的价值,无论是对个人工作和生活还是企业发展和创新商业模式都有着很大的帮助。数据从何而来?需要从网络获取。要获取全面、有效、准确的数据,不可能靠人工获取,应由程序从信息的海洋——互联网抓取。这个从互联网抓取数据的程序就是网络爬虫。爬虫爬取的数据,根据需要做进一步的分析挖掘[5]。
本文语料库直接利用网络爬虫通过百度网页搜索获取,同时为了有效应对网站反爬虫,使用Chrome 浏览器的headless 模式实现。Headless 模式就是在无界面模式下运行浏览器。
3.2 jieba分词
中文分词是中文自然语言处理的第一步,一个优秀的分词系统取决于足够的语料和完善的模型。很多机构都会开发和维护自己的分词系统,本文使用一款完全开源、简单易用的分词工具——jieba 中文分词。
中文分词的模型主要分为两大类:基于规则和基于统计,jieba 分词结合了基于规则和基于统计两类方法,同时jieba 提供了3 中分词模式。jieba 支持分词、关键词提取、词性标注、自定义分词词典和停用词词典。文本分词后就可以制作词向量[4]。
3.3 Word2Vec词向量
计算机只能识别和计算数字,传入模型计算的数据只能是数字或向量,处理自然语言时首先就要进行数据预处理即符号数学化。最初一般采用One-Hot 独热编码,但没有考虑词的含义和词之间的关系。最常见、效果比较好的就是词向量Word2Vec。
(1)语言模型
词向量是在训练词语言模型的同时得到的。要想从自然语言文本中学习有效信息,需要从自然语言文本中统计并建立一个语言模型。这里介绍的是从大量未标注的普通文本数据中无监督的学习出词向量。
(2)数据格式化处理
分词完成后,如果文本规模较大,分词结果应保存为文件,如果较小可以直接制作词向量。制作词向量前,需要将数据处理成gensim 可以处理的格式:
方法1:直接处理成列表嵌套的数据格式,如[[第一句分词],[第二句分词],…]。
方法2:利用gensim.models.word2vec 模块中Line-Sentence、PathLineSentences、Text8Corpus 类读取分词结果文件,生成一个迭代对象,封装的内容是分词后的词列表。
本文语料为动态语料,同时规模较小,因此采用方法1 格式化数据。
(3)训练词向量模型
word2vec.Word2Vec (sentences=None, size=100, window=5,min_count=5)
sentences:就是上面的准备好的数据,可以是简单的list 或这个是其他几个方法生成的可迭代对象。size:生成词向量的大小,也就是特征向量的维数。window:一个词上下文的最大关联距离,即上下文几个词对这个词有影响。
min_count:忽略词频小于这个值的词;还有一些学习率等参数。
4 问答系统实现算法
4.1 定义分词器
使用jieba 中文分词工具进行分词。
def tokenizer(sentence):
words_cut=jieba.cut(sentence,cut_all=False)
return list(words_cut)#返回分词结果
4.2 构建语料库
根据用户问题爬取相应资源,构建问题-答案语料。
Step1:爬虫打开百度首页,将用户问题输入到搜索框后执行搜索
def spider(driver,keyword_q): #driver:浏览器,keyword_q:用户输入的问题
#打开百度首页
driver.get("https://www.baidu.com")
time.sleep(2)
#获取输入框
inputKeyWord = driver.find_element_by_xpath('//*[@id="kw"]')
inputKeyWord.send_keys(keyword_q)#输入搜索内容
#获取”百度一下”按钮
submit_baidu = driver.find_element_by_xpath('//*[@id="su"]')
submit_baidu.click()#单击按钮
Step2:解析爬取结果首页,构建问题-答案语料
#driver:浏览器,wordlists_question_cut:保存问题-答案对中问题分词
def parse(driver,wordlists_question_cut):
#解析标题-摘要代码段,过滤搜索结果中关于广告的主题
内容
title_abstracts = driver.find_elements_by_xpath('//*[@class="result c-container"]')
title_abstracts.extend (driver.find_elements_by_xpath ('//*[@class="result-op c-container xpath-log"]'))
#解析keyword-abstract 对
for title_abstract in title_abstracts:
#解析出标题代码块
#解析出标题链接
#构造含有链接的标题即Q
#对标题内容即Q 进行分词并保存
#解析摘要代码块,然后解析文本内容
#保存问题-答案对
return 问题答案集
4.3 训练模型
def trainModel(modelname,train_corpus_words_cut):
#设置模型参数
size=400 #每个词的向量维度
window=5 #词向量训练时的上下文扫描窗口大小,窗口为5 就是考虑前5 个词和后5 个词
min_count=1 #设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃
workers = multiprocessing.cpu_count()# 训练的进程数,默认是当前运行机器的处理器核数。
model=word2vec.Word2Vec()#训练模型
return model
4.4 相似度计算
计算用户问题与问答答案集中问题的向量夹角余弦值来计算他们的相似度。
def calSimilarity_Q(model,wordlist_Qask_cut,wordlists_Q_cut):
similarity_Qs={} #保存Q 的相似度,便于后面检索答案
for wordlist_Q in wordlists_Q_cut:
similarity = model.n_similarity (wordlist_Qask_cut,wordlist_Q)
Q_text="".join(wordlist_Q)#将Q 分词结果还原为Q 内容
similarity_Qs[Q_text]=similarity
return similarity_Qs
4.5 检索答案
def search_A(similarity_Qs,Q_As):
#按照字典similarity_Qs 的value 值(相似度)降序,
#取Top5
#遍历问题答案集,如果检索到就返回检索结果
return 检索结果
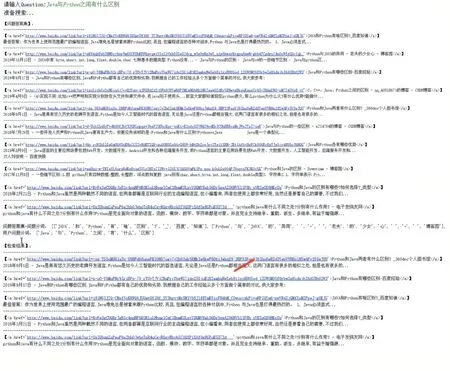
图2
5 问答系统原型

图3
6 结语
本文对问答系统相关技术进行了分析,构建了问答系统模型,介绍了系统实现所使用的网络爬虫、jieba中文分词、Word2Vec 词向量等关键技术,给出了系统实现的详细算法,最后提供了系统使用效果。从运行效果来看,能很好地满足用户的需求。
