基于半监督学习的命名实体识别的方法
2020-04-21刘一鸣
刘一鸣


摘要:命名实体识别是信息抽取中基础且关键的一项子任务。本文根据不同领域文本的特性,设置了通用的特征模板,利用半监督学习的方法,对新闻文本和桥梁文本分别进行了命名实体识别。实验表明,仅使用少量标注的语料也可以达到较好的识别效果。
关键词:命名实体识别;自学习方法;半监督学习
中图分类号:TP391.4 文献标识码:A 文章编号:1007-9416(2020)01-0207-02
命名实体识别概述
随着信息技术的发展,网络数据出现飞速增长的趋势,并呈现出多源异构等大数据特征。对其进行信息抽取,获得有效信息对于文本数据分析具有重要的研究意义。
命名实体识别是信息抽取过程中十分基础且关键的一项子任务。命名实体识别是指识别出文本中例如人名,地名,时间或组织名等具有特定意义的实体。
大多数命名实体识别的方法都是基于规则[1]的方法或基于监督学习[2]的方法。其中基于规则的方法需要专业人员去设置规则模板,但是规则之间可能会出现冲突,且可移植性和扩展性差。基于监督学习的方法十分依靠大量的标注文本,在通常情况下标注文本是极难获取的,且使用人工标注的成本較大。因此,只需要少量标注语料的基于半监督学习的命名实体识别方法成为了领域内研究的热门。
2 研究现状
命名实体识别一直是自然语言处理领域研究的基础性问题,其本质可看作序列化数据标记问题[3]。
早期的命名实体方法是在限定文本领域、限定语义单元类型的条件下进行的,采用的是基于规则与词典的方法。Rau等人采用启发式算法与人工编写规则相结合的方法,首次实现了从文本中自动抽取公司名,但扩展性差,规则制定费时费力。
Wang等人采用有监督的统计学习方法,针对于临床医学的记录进行命名实体识别,利用大量的标注样本进行条件随机场模型(conditional random fields,CRF)的学习,并最终取得了F值81.48%的成绩。
条件随机场是Lafferty等人于在隐马尔可夫模型(HMM)和最大熵模型(MEMM)的基础上提出的一种概率式判别模型。它可以充分结合观察序列中的多种特征信息,来克服HMM中严格的强独立性假设问题。以上的方法都需要大量的标注语料作为数据支撑,仅需少量语料的半监督学习方法[4]也取得一定成就。Jonnalagadda等人在医学领域采用了半监督CRF的方法对临床医学实体进行识别,并提出了分布式语义方法,最终实验F值为0.823%。Ke等人在少量标注语料的情况下, 结合大量的未标注语料,应用协同训练算法实现中文组织名的识别, 协同训练CRF模型和SVM模型,最终模型F值比单个模型F值高出10%。
设X与Y为随机变量,P(Y|X)是在给定X的条件下,Y的条件概率分布。设P(Y|X)为条件随机场,X取值为x的条件下,Y取值为y的条件概率如下公式:
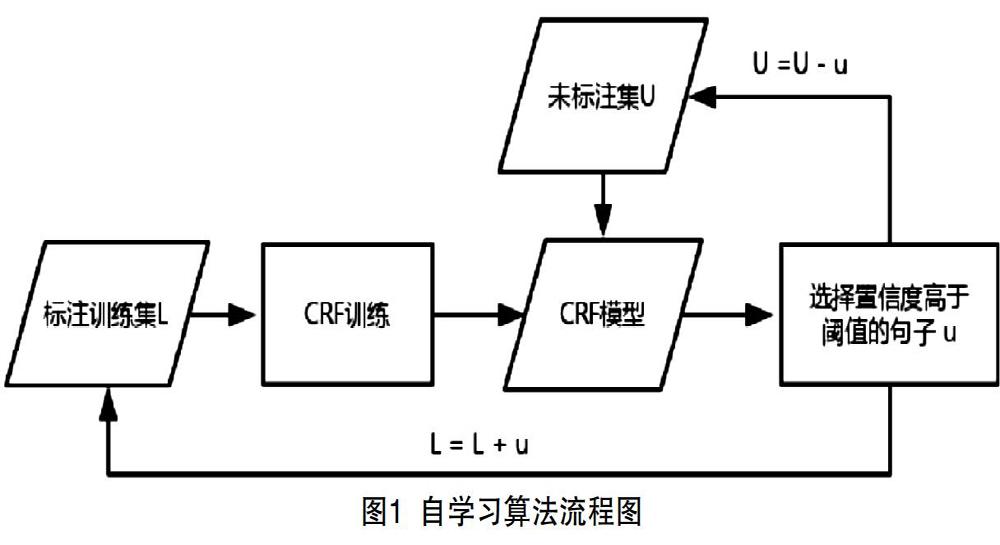
自学习方法是有监督和无监督学习相结合的统计机器学习方法,其可通过大量未标注语料与少量已标注语料自行进行训练及分类,整个过程不需要人工来干预。而其中自举法(Bootstrapping)是自学习中常用的一种方法,具体的流程如图1所示。自学习算法流程如图1所示,首先,利用获得的少量标注语料L放入CRF模型中学习,用训练好的CRF模型c0对大量的未标注预料U进行预测,将置信度高于80%的句子u加入到标注集L中并在未标注集U中删除,重复此过程直到模型收敛,最终得到模型Cn。
在CRF模型的训练中,选取合适的特征并创建特征模板是影响模型性能的关键[5]。为了设置适合于多领域的文本特征模板,我们选取了以下5个特征。
(1)上下文特征:本文选择上下文2个词作为上下文特征,例如,“造就一支稳定的基础研究的队伍”这句话中,“研究”一词上文两个词特征为“的”和“基础”两个词。(2)位置特征:词语在句子的位置在命名实体识别中起到了关键的作用,在“开展各种形式的科学普及教育”一句中,“科学”一词位置为5。(3)长度特征:本文选取词语的长度作为基础特征之一,例如,“新年”词语的长度为2。(4)字符特征:在命名实体中,通常存在词语中包含数字、符号或者英文字母的实体。例如,“3#人行天桥”和“1994年”两词语中都包含数字,前者还包含了特殊符号。(5)词向量特征:利用词向量工具Word2Vec对大量未标注数据进行词向量训练并进行聚类,类别作为特征的一部分加入到模板中。例如,“辽宁省”聚类类别为64。
为测试自学习方法在不同领域语料的效果,我们选择了桥梁语料和新闻语料两个领域的语料,分别为1998年人民日报语料库和自标注的桥梁语料库。
本文使用爬虫技术,在网络上爬取了两个领域的大量未标注语料,利用分词工具jieba对其分词,并利用词向量工具Word2Vec进行词向量训练和聚类。
实验结果如表1所示,在使用特征模板后,模型的效果获得较大幅度提升,通过自学习算法,最终模型效果进一步加强,根据文本特性选取适合的特征和选取的学习方式同样重要,在仅有少量语料的情况下使用自学习方法可以提高模型的质量。
本文针对不同领域语料,采用CRF模型,选取上下文特征、位置特征、长度特征、字符特征,同时利用大规模的未标注数据,通过词向量训练和聚类获取词向量特征,并进行了对比实验。实验表明,利用半监督学习的方式,无论在桥梁领域还是新闻领域效果都有所提升,词向量特征能够从大规模的未标注数据集中获取词的语义信息,并且相比于人工选取和设置的特征,无监督学习可以减少大量的工作量,提高命名实体识别的性能。
[1] 闫丹辉,毕玉德.基于规则的越南语命名实体识别研究[J].中文信息学报,2014,28(05):198-205+214.
[2] 潘清清,周枫,余正涛,等.基于条件随机场的越南语命名实体识别方法[J].山东大学学报(理学版),2014,49(01):76-79.
[3] 张海楠,伍大勇,刘悦,等.基于深度神经网络的中文命名实体识别[J].中文信息学报,2017,31(04):28-35.
[4] 蔡月红,朱倩,程显毅.基于Tri-training半监督学习的中文组织机构名识别[J].计算机应用研究,2010,27(01):193-195.
[5] 邱泉清,苗夺谦,张志飞.中文微博命名实体识别[J].计算机科学,2013,40(06):196-198.
