时序数据库发展研究
2020-04-21
1 引言
随着5G商用正式启动,中国正式进入5G时代,物联网(IoT)也将迎来巨大的转变,5G技术带来的高速通信为物联网的数据传输速度带来更高效的运行。而物联网的发展中一项重要的技术就是时序数据库,物联网设备产生的大量数据,需要通过有效的时序数据库进行处理和存储,各大行业也对时序数据库投入关注,本文将针对时序数据库进行研究和介绍。
2 介绍
2.1 时序数据
时序数据,即时间序列数据,我们把按照时间戳的大小顺序排列的一系列记录值的数据称为时间序列数据(Time Series Data)[1]。在日常生活中,时序数据相当常见,比如,汽车的位置定位,在一段时间内某辆特定汽车的其他属性,包括型号、颜色、车牌号、所有者等都是不变的,但它的位置数据是随着时间变化不断在变化的,那么根据时间确定的位置值及其他属性所组成的一系列数据就是一组时序数据,当我们驾驶汽车开启导航时,就需要根据这一组时序数据判断接下来到达目的地的路线以及存储驾驶记录,在即将到来的无人驾驶中更是必不可少的。在互联网中,时序数据更是无处不在,比如,用户访问网站的记录、应用系统的系统日志数据等等。
近年来,时序数据的应用更为广泛,包括物联网(以前述汽车定位为例外还有各类传感器数据等)、经济金融领域、环境监控领域[2]、医学领域[3]、工业制造领域[4]、农业生产领域[5]、硬件和软件系统监控[6]等各方面,都在大量使用时序数据,揭示研究对象的趋势性、规律性、异常性,而在5G与人工智能的浪潮下,时序数据作为大数据、机器学习、实时预测、预警的基础数据的作用更加显著,因此,对时序数据的研究与应用更为深入。从前述汽车定位的例子可以看到,时序数据与关系型数据存在较大的差异:
(1)最明显的特征是时序数据都存在唯一的时间戳,并且以时间戳大小进行排序,以时间戳作为唯一标识进行区分,而关系型数据通常有其他字段作为标识,比如学生的数据通常使用学号作为唯一标识进行区分。
(2)时序数据并不关心关系,在汽车定位中,我们不需要了解这辆汽车的所有者的其他属性,例如年龄、职业等等,也就不存在对汽车所有者的表的关联。
(3)时序数据的数据量持续呈线性增长,每隔一定时间粒度就会产生新的数据,将会持续产生海量数据,因此数据量庞大。而关系型数据的增长通常不是随着时间持续增长的,比如一所学校的学生数据量在一段时间内都是相对稳定的。
(4)时序数据很少会有更新操作,在某个时刻的测量值产生将不会发生变化,所以几乎不需要对时序数据进行更新。对于关系型数据,则是已存在的数据经常发生更新,比如学生的个人信息,包括年龄、身高等属性。
2.2 时序数据库
基于快速增长的时序数据应用需求以及区别于传统关系型数据的特征,时序数据库应运而生,时序数据库一般具有以下特点[7]:
(1)高吞吐量数据高速写入能力。由于时序业务会持续产生海量数据,并且对写入的速度有很高的要求,写入的并发量大,这就要求时序数据库系统实现高吞吐量的数据高速写入功能。
(2)高压缩率。时序数据库需要存储大量的数据,并且有的监控数据可能需要存储很长时间,5年到10年都有需求,因此需要根据时序数据的特征对数据进行压缩。
(3)高效时间窗口查询能力。时序业务的查询需求分为两类,一是实时数据查询,反映当前监控对象的状态;二是主要是查询某个时间段的历史数据,历史数据的数据量非常大,这时候需要针对时间窗口大量数据查询进行优化。
(4)高效聚合能力。时序业务场景通常会关心数据的聚合值,比如count、mean等聚合值来反映某个时间段内的数据情况,因此时序数据库需要提供高效的聚合函数。
(5)批量删除能力。时序业务对于过期的数据需要进行批量删除操作。
(6)通常不需要具备事务的能力。
时序数据库与传统关系型数据库不同,传统关系型数据库注重增删改查和事务功能,而时序数据库针对海量数据写入,其读取查询多是一段时间段内的数据。传统关系型数据库都是采用的B tree,是随机读写的模式,会在寻道上消耗较多时间,对于90%以上场景是写入的时序数据库来说效率太低,所以时序数据库的主流是采用LSM Tree(Log-Structured Merge Tree,结构化合并树)[8]替换B Tree,比如KairosDB(底层使用Cassandra的单机模式)、openTSDB(底层使用Hbase)、LevelDB等,其核心思想是放弃部分读的能力换取写的能力最大化。当然,除了LSM Tree作为存储机制,时序数据库还有许多其他的尝试和改进,并且在不断发展,接下来在第三部分将简要介绍时序数据库的发展历史。
3 时序数据库的发展概况
3.1 时序数据库的发展历史
图1展示了时序数据库的发展时间轴,从时间轴中可以看到,虽然时序数据库近几年才进入大众视野,但其发展可以追溯到20世纪90年代,在监控领域产生了时序数据存储的需求,由此出现的第一代时序数据库,以RRDtool(Round Robin Database Tool) 和 Whisper 为代表,使用固定大小的数据库,可以随时间变化快速存储数值型数据,但是其读性能还是比较弱,缺乏针对时间的特殊优化,并且处理的数据模型单一,通常是内嵌在监控系统中。

图1 时序数据库发展时间轴
随着大数据的发展,时序数据爆发式增长,不只是监控系统,其他系统也有更多处理时序数据的需求,在2011年开始出现了以OpenTSDB、KairosDB为代表的基于分布式存储的时序数据库,这类时序数据库在继承通用存储优势的基础上,针对时间进行优化。比如OpenTSDB底层依赖于HBase集群存储,根据时序的特征对数据进行压缩,节省存储空间;用TSD(Time Series Daemon)进行读写,对时序数据的常用查询进行封装,提供数据聚合、过滤等操作。这类专用于时序数据的数据库相比第一代时序数据库在存储和查询性能有明显的提高,但是这类数据库也有许多不足,比如低效的全局UID机制,依赖Hadoop和HBase环境,部署及维护成本高。
随着微服务的发展,时序数据库在高速发展,OpenTSDB存在的不足和部署复杂性促进了低成本的垂直型时序数据库的诞生。以IfluxDB为代表的垂直型时序数据库成为时序数据库市场的主流,针对时序数据具备更高效的存储读取等数据处理能力和高效的压缩算法。InfluxDB的单机版本采用类似LSM Tree的TSM Tree(Timestamp-Structure Merge Tree)存储结构,引入了series-key的概念,根据时间特征对数据实现了很好的分类,减少冗余存储,提高数据压缩率。相对于OpenTSDB需要配置Java环境和HBase环境,InfluxDB基于Goland,无依赖,部署简单,并且使用类SQL语言的InfluxQL,易于开发。
3.2 时序数据库的发展现状
近5年来,时序数据库发展十分迅猛,各大互联网企业包括Google、阿里、Amazon都推出自己的时序数据库,DB-Engines从2014年起也把时序数据库作为独立的目录进行分类统计。
图2为DB-Engines统计的2019年12月为止24月各类数据库的关注度趋势,可以看到时序数据库关注度同比2017年12月上涨77.3%,相比第二名的图形数据库上涨近两倍。
图3为DB-Engines统计的2019年12月为止5年来业内流行的时序数据库的关注度和使用度排名。从图中可以看到,从2015年开始,各种时序数据库如雨后春笋般涌现:2017年,Facebook开源基于内存的Gorilla时序数据库(2015年发布)原型项目beringei,基于PostgreSQL设计的TimescaleDB开源,阿里发布时序数据库TSDB;2018年Amazon推出完全托管的Timestream;其中,2013年发布的开源InfluxDB,在各种时序数据库中脱颖而出,独占鳌头,直到目前为止都是时序数据库关注度排名第一并且其人气仍在增长,由于其开源特性,InfluxDB使用类SQL的InfluxQL查询语言的易用性,基于Go语言编写的无环境依赖等优势,InfluxDB的版本正在飞快的迭代更新,2019年就发布了7个版本,并且推出了云服务版本。
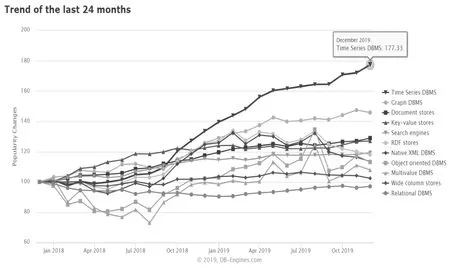
图2 DB-Engines统计不同类别数据库关注度趋势

图3 DB-Engines统计时序数据库关注度趋势
4 未来与展望
时序数据库正处于高速发展阶段,时序数据技术逐步走向成熟,但是这绝不是终点,时序数据技术还面临各种新的需求和挑战。各大厂商在提高时序数据库性能的同时,针对新需求正在提出更多解决方案:
(1)云服务。除了单机版本,许多厂商还发布了分布式版本、云服务版本,特别是云服务,已经成为必不可挡的发展趋势。
(2)可视化服务。随着万物互联的到来,用户对信息的全面掌握的需求在增长,时序数据的可视化展示成为一大趋势,这就对时序数据库的查询能力提出更高的要求。
(3)边缘计算服务。在万物互联的时代,更多的传感器带来的庞大数据量是集中化处理方式难以负荷的,这就使得数据计算向边缘化发展,设备将数据通过边缘设备进行实时处理分析反馈后再集中存储,能够提高设备的实时响应能力,提升时效性数据的价值,因此,时序数据库对边缘计算的支持将成为其一个重要的功能。
面对这些挑战与机遇,相信时序数据库将会有更深的发展,未来可期。
